引言
在并发编程中,我们不仅需要考虑如何合理分配任务以提高程序的执行效率,而且还需要关心如何将分配的任务结果合理汇总起来,以便得到我们最终想要的结果。这就需要我们使用一种特殊的并发设计模式——分而治之。在Java中,这种模式被抽象化为了Fork/Join框架。通过Fork/Join框架,我们能够将大任务分解成小任务并行处理,然后再将小任务的结果合并得到最终结果。这大大提高了任务处理的效率,使得并发编程在处理大量数据时变得更加简单有效。在本文中,我们将深入探讨Fork/Join框架,理解其工作原理,并通过实例学习如何在实际项目中使用它。
Fork/Join框架的作用?
在CPU密集型任务中,利用现代多核处理器的性能,通过并行的方式来执行任务
Fork/Join框架在并发编程中处于什么位置?
一个专门用于解决可以被分解并且可以并行执行的任务的工具,它在利用多核处理器,提高程序性能方面起到了关键作用。
搞懂这两个问题, 我们接着往下看
入门 | 理解Fork/Join框架
Fork/Join框架的工作原理
Fork/Join框架是为了充分利用多核CPU,通过分治策略将大任务分解为小任务并行执行。它使用"ForkJoinPool",一个专门为Fork/Join任务设计的线程池,里面的每个工作线程都有一个"双端队列"维护任务。当线程执行自身任务时,从队头获取;当窃取其他线程任务时,从队尾获取,以避免任务冲突。这个基于"工作窃取算法"的设计使得CPU资源可以高效利用。所有的任务都是"ForkJoinTask"的子类,任务完成后,结果通过"join"步骤进行递归合并。这样,Fork/Join框架实现了任务的并行处理,提高了执行效率。
为了方便你理解,我画了一张图:
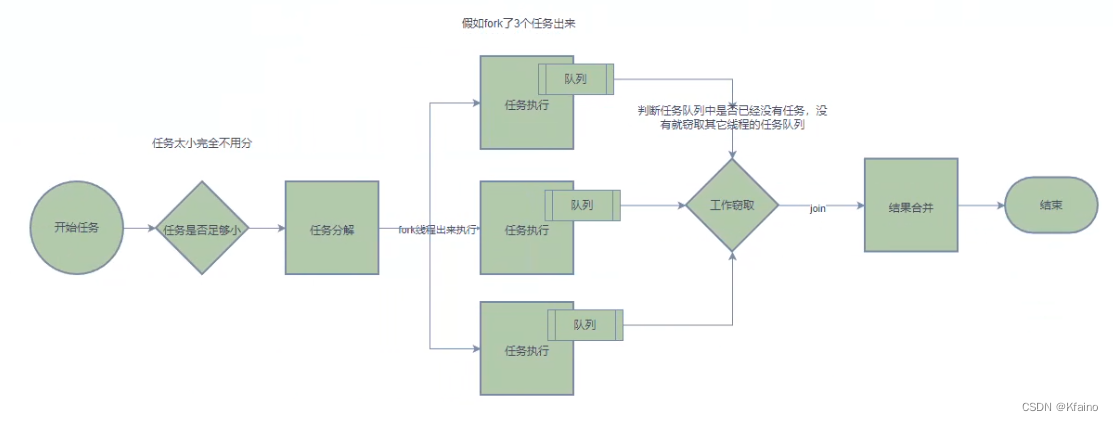
分治策略在Fork/Join框架中的体现
从名字你也可以看出来:
任务分解(Fork)
对于一个大的任务,Fork/Join框架通过fork操作将其分解为一系列更小的子任务,这些子任务可以更容易地并行处理。这是分治策略的“分”的部分。分解任务通常是递归进行的,也就是说,一个任务可能被分解为一些子任务,然后这些子任务又可以被进一步分解为更小的子任务,直到任务足够小可以直接处理为止。
结果合并(Join)
当所有的子任务都被处理完毕后,Fork/Join框架通过join操作将这些子任务的结果合并,得到原任务的结果。这是分治策略的“治”的部分。这个过程通常是递归进行的,也就是说,每个任务在完成自己的工作后,还要等待其所有的子任务完成,并将子任务的结果合并到自己的结果中。
Fork/Join框架的核心组件:ForkJoinPool和ForkJoinTask
至此,理论部分已经铺垫完了,我们来看下源码中这两个重要的组件:
ForkJoinPool
ForkJoinPool是Fork/Join框架的核心,它是一个专门为Fork/Join任务设计的线程池。它管理着一组工作线程,每个工作线程都有一个双端队列(Deque)来存储待执行的任务。这些工作线程会尽可能地执行提交到线程池的任务。
在ForkJoinPool的源码中,execute()方法用于提交任务到线程池:
public void execute(ForkJoinTask<?> task) {
if (task == null)
throw new NullPointerException();
if (threadLocalRandom == null) {
// 线程外部提交的任务
externalPush(task);
}
}这段代码表示,如果任务是由线程外部提交的,那么调用externalPush()方法将任务添加到队列;
ForkJoinTask
ForkJoinTask是所有Fork/Join任务的父类。它有两个主要的子类:RecursiveAction和RecursiveTask,分别表示没有返回值和有返回值的任务。在ForkJoinTask的源码中,fork()方法用于将任务提交到线程池:
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}这段代码表示,如果当前线程是一个ForkJoinWorkerThread(即Fork/Join线程池的工作线程),那么直接将任务添加到工作队列;否则,调用ForkJoinPool.common.externalPush()方法将任务添加到公共线程池。
进阶 | 深入Fork/Join框架
ForkJoinPool详解:工作窃取算法和并行级别
工作窃取算法
上面已经讲解了工作窃取算法的工作原理以及作用,我在这里就不赘述了,现在让我们从源码的视角来进行分析。
工作窃取算法的源码主要体现在Java类库的ForkJoinPool中。我们可以分析一下ForkJoinPool类的runWorker(WorkQueue w)方法,这个方法在每个ForkJoinWorkerThread线程中被调用,用于处理任务和执行窃取:
final void runWorker(WorkQueue w) {
w.growArray(); // 为工作队列初始化或扩容
int seed = w.hint; // 随机种子
int r = (seed == 0) ? 1 : seed; // avoid 0 for xorShift - 为了防止在随后的异或移位运算中产生全零的结果
for (ForkJoinTask<?> t;;) {
// 调用scan()方法扫描工作队列和其他线程的工作队列,尝试获取一个任务。如果获取到了任务,执行该任务
if ((t = scan(w, r)) != null)
w.runTask(t);
// 如果没有获取到任务,调用awaitWork()方法使线程进入等待状态,等待新的任务的到来。如果线程应该终止,awaitWork()方法会返回false,从而跳出循环。
else if (!awaitWork(w, r))
break;
// 生成新的随机值
r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // xorshift - 异或移位运算
}
}在scan()方法中,工作线程尝试窃取其他线程的任务:
private ForkJoinTask<?> scan(WorkQueue w, int r) {
WorkQueue[] ws; int m;
if ((ws = workQueues) != null && (m = ws.length - 1) > 0 && w != null) {
int ss = w.scanState; // initially non-negative
for (int origin = r & m, k = origin, oldSum = 0, checkSum = 0;;) {
WorkQueue q; ForkJoinTask<?>[] a; ForkJoinTask<?> t;
int b, n; long c;
if ((q = ws[k]) != null) {
if ((n = (b = q.base) - q.top) < 0 && // 当前工作队列q不为空并且其包含任务,就尝试获取任务
(a = q.array) != null) { // non-empty
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
// 如果成功获取到了任务
if ((t = ((ForkJoinTask<?>)
// 原子性地获取并移除任务
U.getObjectVolatile(a, i))) != null &&
q.base == b) {
if (ss >= 0) {
if (U.compareAndSwapObject(a, i, t, null)) {
q.base = b + 1;
if (n < -1) // signal others
signalWork(ws, q);
return t;
}
}
else if (oldSum == 0 && // try to activate
w.scanState < 0)
tryRelease(c = ctl, ws[m & (int)c], AC_UNIT);
}
if (ss < 0) // refresh
ss = w.scanState;
r ^= r << 1; r ^= r >>> 3; r ^= r << 10;
origin = k = r & m; // move and rescan
oldSum = checkSum = 0;
continue;
}
checkSum += b;
}
if ((k = (k + 1) & m) == origin) { // continue until stable
if ((ss >= 0 || (ss == (ss = w.scanState))) &&
oldSum == (oldSum = checkSum)) {
if (ss < 0 || w.qlock < 0) // already inactive
break;
int ns = ss | INACTIVE; // try to inactivate
long nc = ((SP_MASK & ns) |
(UC_MASK & ((c = ctl) - AC_UNIT)));
w.stackPred = (int)c; // hold prev stack top
U.putInt(w, QSCANSTATE, ns);
if (U.compareAndSwapLong(this, CTL, c, nc))
ss = ns;
else
w.scanState = ss; // back out
}
checkSum = 0;
}
}
}
return null;
}工作线程会遍历其他所有工作线程的队列,并尝试从队列尾部窃取任务。如果窃取成功,那么跳出循环并执行窃取到的任务;如果窃取失败(即队列为空),那么进入下一个工作线程的队列并尝试窃取。
并行级别
Fork/Join框架的并行级别通常与处理器的核心数相关。在创建ForkJoinPool时,可以指定并行级别。这个并行级别就是线程池的线程数量,它决定了同时可以执行的任务数量。如果不指定并行级别,那么默认的并行级别将等于处理器的核心数。
在ForkJoinPool的构造函数中,有一个参数parallelism用于指定并行级别:
public ForkJoinPool(int parallelism) {
//...
}在实际使用中,应根据具体的硬件环境和任务特性来选择合适的并行级别。如果并行级别过高,可能会导致线程之间的竞争过于激烈,反而降低性能;如果并行级别过低,可能无法充分利用多核处理器的性能。一般来说,对于计算密集型的任务,最佳的并行级别应接近于处理器的核心数。
ForkJoinTask详解:RecursiveAction和RecursiveTask
它们的区别主要在于是否有返回值了,我们接着往下看:
RecursiveAction
RecursiveAction 表示没有返回值的任务。这种类型的任务通常会执行一些改变状态的操作,以下是一个简单的例子:
class MyRecursiveAction extends RecursiveAction {private final int[] array; private final int start; private final int end; public MyRecursiveAction(int[] array, int start, int end) { this.array = array; this.start = start; this.end = end; } @Override protected void compute() { if (end - start < THRESHOLD) { // 直接处理任务 Arrays.sort(array, start, end); } else { // 将任务分解,非常舒服的写法 int mid = (start + end) >>> 1; invokeAll(new MyRecursiveAction(array, start, mid), new MyRecursiveAction(array, mid, end)); } }
}
在这个例子中,我们定义了一个排序数组的任务。当数组的长度小于一定阈值时,我们直接对数组进行排序;否则,我们将数组分成两部分,然后创建两个新的任务来分别排序这两部分。
RecursiveTask
RecursiveTask 表示有返回值的任务。这种类型的任务通常会执行一些计算操作,以下是一个简单的例子:
class MyRecursiveTask extends RecursiveTask<Integer> {private final int[] array; private final int start; private final int end; public MyRecursiveTask(int[] array, int start, int end) { this.array = array; this.start = start; this.end = end; } @Override protected Integer compute() { if (end - start < THRESHOLD) { // 直接处理任务 int sum = 0; for (int i = start; i < end; i++) { sum += array[i]; } return sum; } else { // 将任务分解 int mid = (start + end) >>> 1; MyRecursiveTask leftTask = new MyRecursiveTask(array, start, mid); MyRecursiveTask rightTask = new MyRecursiveTask(array, mid, end); leftTask.fork(); // 异步执行左边的任务 Integer rightResult = rightTask.compute(); // 同步执行右边的任务 Integer leftResult = leftTask.join(); // 获取左边任务的结果 return leftResult + rightResult; } }
}
在这个例子中,我们定义了一个计算数组总和的任务。当数组的长度小于一定阈值时,我们直接计算数组的总和;否则,我们将数组分成两部分,然后创建两个新的任务来分别计算这两部分的总和。
入门 | 如何完整使用Fork/Join框架
我们来做一个累加运算,步骤如下如下:
创建ForkJoinPool
ForkJoinPool pool = new ForkJoinPool();创建ForkJoinTask
这里我们需要返回计算结果,所以继承RecursiveTask对象
public class SumTask extends RecursiveTask<Long> {
private final long[] array;
private final int start;
private final int end;private static final int THRESHOLD = 10000; //任务分解的阈值 public SumTask(long[] array, int start, int end) { this.array = array; this.start = start; this.end = end; } @Override protected Long compute() { // 计算核心 // 将大任务分解成小任务 if (end - start <= THRESHOLD) { // 当前计算任务足够小,则直接计算 long sum = 0; for (int i = start; i < end; i++) { sum += array[i]; } return sum; } else { // 当前计算任务较大,则分解计算 int mid = (start + end) / 2; SumTask task1 = new SumTask(array, start, mid); SumTask task2 = new SumTask(array, mid, end); task1.fork(); task2.fork(); return task1.join() + task2.join(); } }
}
我们来测试一下:
public static void main(String[] args) {
long start = System.currentTimeMillis();
long[] array = new long[100000000];
// 模拟从 0+1+2...+49的结果
for (int i = 0; i < array.length; i++) {
array[i] = i;
}ForkJoinPool pool = new ForkJoinPool(); SumTask task = new SumTask(array, 0, array.length); Long result = pool.invoke(task); System.out.println("总数是: " + result); long end = System.currentTimeMillis(); System.out.println("花费时间为:" + (end - start) + "ms"); }</code></pre></div></div><p>运行结果如下:</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>css</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-css"><code class="language-css" style="margin-left:0">Connected to the target VM, address: '127.0.0.1:6144', transport: 'socket'总数是: 1225
花费时间为:4ms
Disconnected from the target VM, address: '127.0.0.1:6144', transport: 'socket'
Process finished with exit code 0
非常快,只需要4ms就计算完成,当然你可以把数组大小调整到10000依然只需要4ms
Connected to the target VM, address: '127.0.0.1:6551', transport: 'socket'
总数是: 49995000
花费时间为:4ms
Disconnected from the target VM, address: '127.0.0.1:6551', transport: 'socket'
Process finished with exit code 0
这就是并行计算的魅力!
Fork/Join框架的优点和局限性
优点
- 充分利用多核处理器:Fork/Join框架通过将任务划分为更小的子任务,允许并行处理,从而最大程度地利用了多核处理器。
- 工作窃取:Fork/Join框架采用工作窃取算法,可以有效地利用线程。当一个线程的任务队列为空时,它会从其他线程的队列中窃取任务来执行。
- 易于使用:Fork/Join框架相对容易使用。你只需要继承RecursiveTask或RecursiveAction,然后实现其compute方法,就可以将任务划分为子任务。
局限性
- 不适用于IO密集型任务:由于Fork/Join框架主要设计用于CPU密集型任务,因此在IO密集型任务中使用可能无法获得理想的性能。
- 任务划分开销:大任务被划分为小任务会产生一定的开销。如果任务划分的粒度过细,可能会导致任务划分的开销大于任务执行的开销。
- 调试困难:由于Fork/Join框架的并行性,调试Fork/Join任务可能会比较困难。
- 异常处理:Fork/Join任务中的异常必须在任务内部捕获处理,因为由于任务的并行性,不能在任务外部有效捕获任务内部的异常。
其它并发模型
如果任务是CPU密集型的,可以并行处理,并且任务划分的开销相对较小,那么Fork/Join框架可能是一个好的选择。除了Fork/Join还有哪些模型?
事件循环模型
事件循环模型基于事件驱动编程。在这个模型中,有一个循环(即事件循环)不断地监听事件,并将它们派发给相应的处理函数。这种模型适合于I/O密集型应用,因为它可以在等待I/O操作完成时处理其他事件,从而使CPU得到充分利用。
这种模型的优点是可以处理大量并发连接,而且编程模型相对简单。然而,对于CPU密集型的任务,事件循环模型可能不太适用,因为一个耗时的任务可能会阻塞整个事件循环。
在Java世界中,Netty也实现了类似的模型。
Actor模型
Actor模型是一种并发模型,它把并发单元看作是互不共享状态的实体(称为Actor)。Actor之间通过发送和接收消息进行通信。这种模型可以避免传统多线程编程中的许多并发问题,例如竞态条件、死锁等。
Actor模型的优点是它可以简化并发编程的复杂性,并且能够很好地进行横向扩展。然而,对于一些需要共享状态的场景,使用Actor模型可能会有些麻烦。
Java的Akka框架就实现了Actor模型。
基于线程的模型
基于线程的模型是最传统的并发模型。在这个模型中,我们创建多个线程来执行不同的任务。线程之间可能会共享内存,因此我们需要使用某种机制(如锁)来协调线程对共享资源的访问。
基于线程的模型的优点是可以直接利用多核处理器。然而,管理线程和协调共享资源的访问可能会非常复杂,容易引发并发问题。
Java的内置并发API(如java.util.concurrent包)提供了许多基于线程的并发工具,如Executor框架、并发集合类等。
使用Fork/Join框架的最佳实践和常见问题解答
如何选择合适的任务分割策略?
利用Fork/Join框架,最关键的部分就是如何将大任务分割成足够小的子任务。这个“足够小”通常需要根据具体的应用场景来决定。一般来说,子任务的大小应该能够在一个很小的时间内完成。如果子任务仍然很大,那么你应该继续将其分割。否则,如果任务太小,任务分割和任务调度的开销可能就会超过任务执行的时间,导致效率降低。
一个常用的策略是设置一个阈值,当任务的大小小于这个阈值时,直接进行计算,否则继续分割。这个阈值的设定需要根据实际的应用场景来调整。
如何处理并发编程中的异常?
并发编程中的异常处理是一个比较复杂的问题。在Fork/Join框架中,如果一个子任务抛出了异常,那么这个异常会被ForkJoinPool捕获,并保存在对应的ForkJoinTask对象中。你可以通过ForkJoinTask的getException()方法获取到这个异常。
一种常见的做法是在主任务中,对所有的子任务调用join()方法。如果某个子任务抛出了异常,那么join()方法会重新抛出这个异常。这样,你就可以在主任务中统一处理所有的异常。
如何避免常见的性能问题?
Fork/Join框架的性能问题通常出现在以下几个方面:
任务分割的粒度不合适
如果任务分割得太细,那么任务分割和任务调度的开销可能会超过任务执行的时间,导致效率降低。如果任务分割得太粗,那么可能无法充分利用多核处理器。你需要找到一个合适的阈值,以实现任务大小和任务数量的平衡。
没有充分利用Fork/Join框架的并行性
在Fork/Join框架中,如果一个任务分割成了多个子任务,那么这些子任务可以并行执行。你应该尽量将大任务分割成独立的子任务,以充分利用并行性。
过多的对象创建和垃圾回收
在分割任务和合并结果时,可能会创建大量的临时对象。这可能会导致频繁的垃圾回收,影响性能。你应该尽量避免不必要的对象创建。
数据竞争和内存一致性问题
如果多个任务需要访问共享数据,那么可能会出现数据竞争和内存一致性问题。你应该尽量避免共享数据,或者使用合适的同步机制来保护共享数据。
总结
我们来回顾一下,我们首先深入探讨了Fork/Join框架的本质,然后详细阐述了其核心概念并进行了源码分析。接着,我们通过实际操作深化了对Fork/Join框架的理解。最后,我们对该框架的优点与局限进行了全面评估,并探索了其他可选的并发模型。在这个过程中,我们还解答了一些常见的关于Fork/Join框架使用中的问题,希望对你有所帮助。
附录:相关资源和进一步阅读
- Java并发编程实战
- Java并发编程图册