(译者补充:随着每个云提供商都提供了数十种数据服务,为您的需求选择合适的云数据服务比以往任何时候都更重要,更不用说为了省钱了。这文章就是教你如何选择适合自己的服务。)
传统的数据管理没有提供大数据或NoSQL中的可扩展性,但现在事情变得简单了。你可以从所选择的供应商购买存储,在上面添加数据库,并把你所有的工作负载放到上面。
然而,在新的世界里,每个应用程序都需要数据服务。目标服务可能听起来不错,但是多个工作负载意味着复杂的数据管道,跨不同存储库的多个数据副本以及复杂的数据移动和ETL(提取,转换,加载)过程。所有这些面向批处理的数据操作都无法实现实时分析。
随着单一用途的数据仓库增多,存储和计算成本迅速增长。像亚马逊和谷歌这样的公司纷纷涌入,出售有针对性的服务 ,从而以大量资金掠夺,利润更高,而且往往采用很坑的定价方案。
虽然这一切都很复杂,但现在是企业确实需要统一数据服务,这些数据服务应该具有更好的API多样性以及体积和速度的融合平衡性。对于如此复杂的数据管道或ETL,不需要这么多重复的副本。
以AWS为例子进行分析
亚马逊网络服务(AWS)提供10个以上的数据服务。每个服务都针对特定的访问模式和数据“temperature”进行了优化(参见下面的图1)。每种服务都有不同的(专有)API,以及基于容量,请求数量和类型,吞吐量等等的不同定价方案。
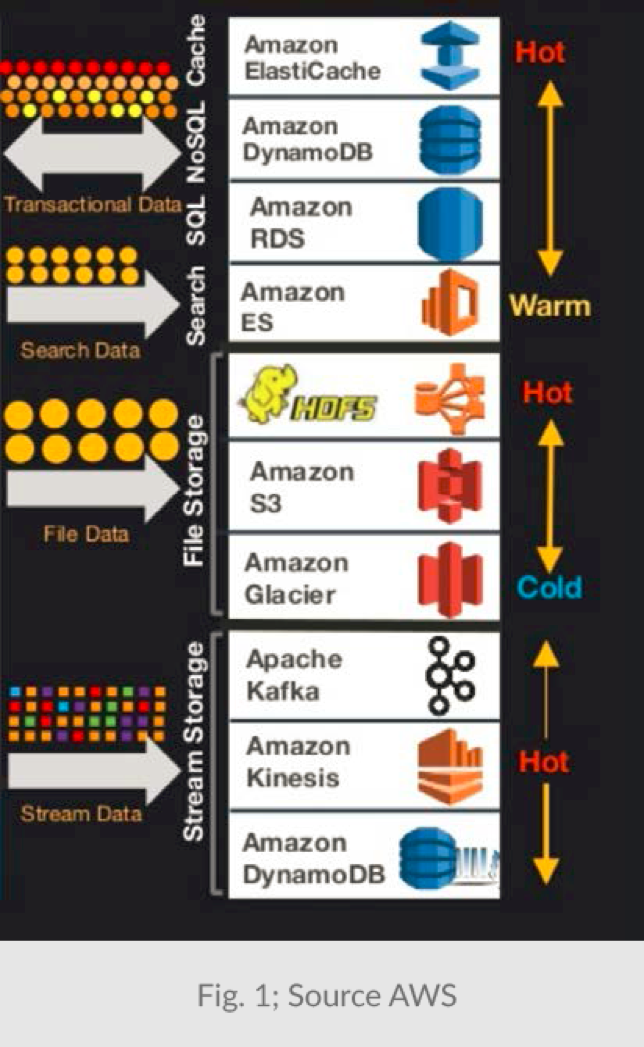
在大多数应用程序中,可以通过几种模式访问数据。例如,它可以写成流式,可以通过Hadoop读取为文件,或者由Spark读取。或者,当单个项目被更新,修改列表被视为流。通常的做法是将数据存储在多个存储库中,或将它们从一个存储位置到另一个存储位置,如图2所示。

图2显示了用于移动和存储SAME数据的六个服务(DynamoDB,DynamoDB Streams,S3,Lambda Redshift和Kinesis)。其中每个服务扮演一个小部分的功能角色,这种组合服务与支持多种工作负载类型的整体服务相比,应用程序耗费的容量和处理能力都高出很多。
AWS和其他服务商使用的流水线方法都具有一个主要缺点——太复杂了。例如,当数据在不同阶段之间漫游时,跟踪数据安全性和数据世系是非常困难的,因为上下文或身份可能在翻译中丢失。长管道也意味着结果会延迟很多,因为它们需要在被分析之前遍历多个阶段。
下面的图表可以指导:如何为每一个特定的工作选择合适的服务。
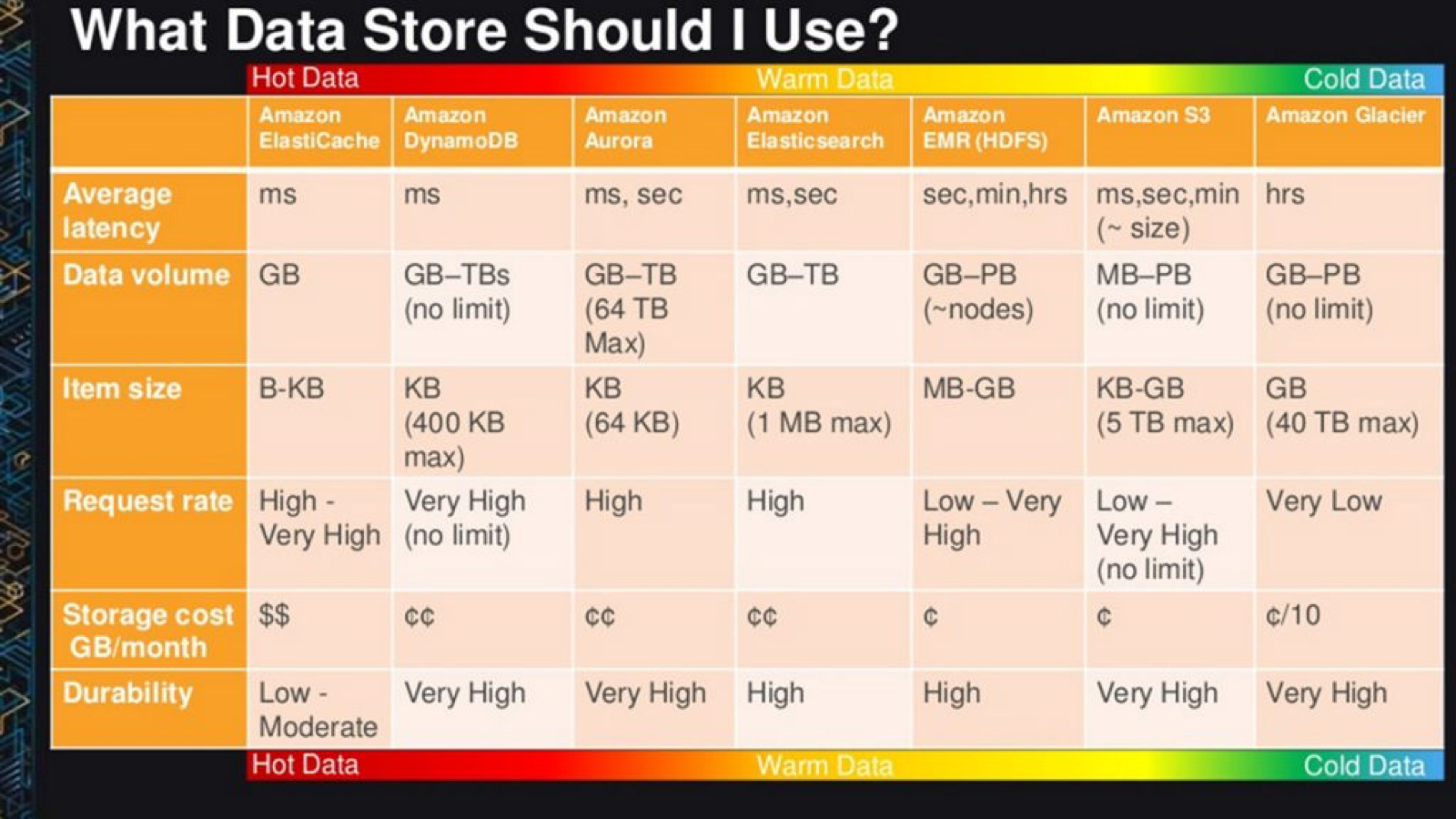

错误选择的代价很大
对于需要存储中等大小对象的应用程序,选择可能包括S3和DynamoDB(直观的决定是采取S3,因为它“更简单,更便宜”)。真的简单?… 太天真啦。
让我们来看看几个用例的数学运算分析:
使用AWS价格计算器,结果显示,对于案例1,使用DynamoDB显然成本较低,而对于案例2,S3更便宜。
这表明,即使传输率低(每秒低于1000个请求),S3的 IO和带宽成本远远超过通常所说的S3容量成本(每GB 3美分)。
对象大小 | 写入/秒 | 读取/秒 | 总容量 | |
|---|---|---|---|---|
情况1 | 2KB | 500 | 500 | 10 TB |
案例2 | 64KB | 50 | 50 | 10 TB |
S3 | DynamoDB | |||
情况1 | 案例2 | 情况1 | 案例2 | |
容量成本 | 236 | 236 | 2,679 | 2,557 |
请求成本 | 6,997 | 700 | 497 | 799 |
转出成本 | 221 | 711 | 222 | 712 |
总成本 | 7,552 | 1,786 | 3,398 | 4,068 |
$ / GB每月 | 0.76 | 0.18 | 0.34 | 0.41 |
请注意,对于一个公司使用20K请求/秒和10TB数据存储空间(零转出)的DynamoD。当所有NoSQL解决方案都可以放入一个主流服务器节点 ,公司将每年支付172,000美元(三年将超过50万美元,三年是服务器的平均寿命)。想象一下,用这些费用公司可以购买多少台本地服务器。
如果还是太慢,多交点钱呀!
关于AWS等云提供商的有趣之处在于,他们总是找到为同样的服务收费更多的方法。因为DynamoDB速度相当慢,所以如果您需要更快的访问速度,又不想修复它并使速度更快,那您现在可以购买专用的DynamoDB高速缓存加速器DAX,它将每月要我们多花$ 600- $ 10,000(还只是使用最低3节点的DAX)
概要
总的来说,现在是时候使用更智能的统一数据平台来处理不同形式的数据(数据流,文件,对象和记录),并将它们全部映射到可以一致地读写数据的通用数据模型中,不用管所要用的API。
随着高性能存储器(如快速闪存和非易失性存储器)的最新进展和商品化,不需要为“hot”和“cold”数据分离产品。分层逻辑应该在数据服务层面实现,而不是强迫应用程序开发人员编写不同的API去实现。
通过在通用平台上统一数据服务,我们可以节省成本,降低复杂性,提高安全性,缩短项目部署时间,缩短数据分析的时间(从第二天开始直到数据挖掘开始进行的时间)。