背景
近期,改编自金宇澄同名小说,知名导演王家卫执导的电视剧《繁花》的热播引起剧烈反响。原著小说以其细腻的笔触和丰富的上海风情,描绘了 20 世纪 60 年代至 90 年代上海市民的生活图景,是一部具有浓厚地域特色和时代感的作品。王家卫的影视作品以其独特的美学风格和深刻的情感表达著称。沪语版剧中使用上海话配音,字证腔圆让人耳目一新,相信后面肯定会有更多、更好的沪语影视作品呈现给观众,也会有更多的优秀专家深度参与,用沪语来叙述上海故事。
这其中,现代技术的不断发展为方言配音提供了新的可能性,尤其是语音合成技术的进步,彻底改变了传统配音的方式。过去,方言配音需要大量的人力和时间投入,特别是在多语言和多方言的影视作品中,寻找合适的配音演员并进行专业的录音是一项极其繁琐的工作。现在,随着人工智能和深度学习技术的成熟,语音合成技术可以高效、准确地模拟出各种方言的语音,不仅节省了成本和时间,还能够实现前所未有的灵活性和定制化。通过大规模的语音数据训练和先进的神经网络模型,合成语音不仅在发音上更加自然,还能表达丰富的情感和语调变化。
下面我们简单利用腾讯云语音技术来重塑银幕声音,通过实践来认识腾讯云语音如何实现视频智能化配音。
腾讯云语音实践
我们先看下 腾讯云语音合成 官方的介绍
语音合成(Text To Speech,TTS)满足将文本转化成拟人化语音的需求,打通人机交互闭环。 提供多场景、多语言的音色选择,支持 SSML 标记语言,支持自定义音量、语速等参数,让发音更专业、更符合场景需求。语音合成广泛适用于智能客服、有声阅读、新闻播报、人机交互等业务场景,提升人机交互体验,提高语音类应用构建效率。
本文我们将结合腾讯云语音合成以及语音转文字服务,制作一段自动配音并且生成国际化字幕的视频。并简要分析其背后蕴含的技术原理以及难点挑战。
获取云服务
在我们实践开始前,我们需要获取基础的云服务,其中主要包含以下流程,注册腾讯云账号,开通云服务,获取 api 密钥。
打开浏览器,访问腾讯云控制台,填写注册信息,按照提示完成验证和其他必要步骤,完成账号注册。
使用注册的账号信息登录腾讯云控制台,在控制台首页,可以看到各种云服务的分类,根据需求选择语音合成服务,点击“立即开通”按钮。
我们按照上面流程依次开通“语音识别”,“语音合成”云服务。
开通云服务之后,我们按照页面提示创建需要调用的 api 密钥,在腾讯云控制台首页,点击右上角的账户名称,选择“访问管理”。在访问管理页面中,选择“API密钥管理”,如果没有已创建的API密钥,点击“新建密钥”按钮。根据需要,可以在访问管理页面中设置密钥的权限,确保密钥有调用语音合成服务的权限。这里我直接使用的是主账户的 api 密钥,为了安全起见,也可以创建子账户,并且给子账户授权使用相应的云服务权限。
以上,我们就完成了这次实践基本的准备工作。
系统开发
准备好以上云服务基础后,我们就可以开始利用 api 或者 sdk 调用云服务,并实现我们的系统功能了。
系统流程图
在实践开始前,我们先对系统流程时序图进行梳理
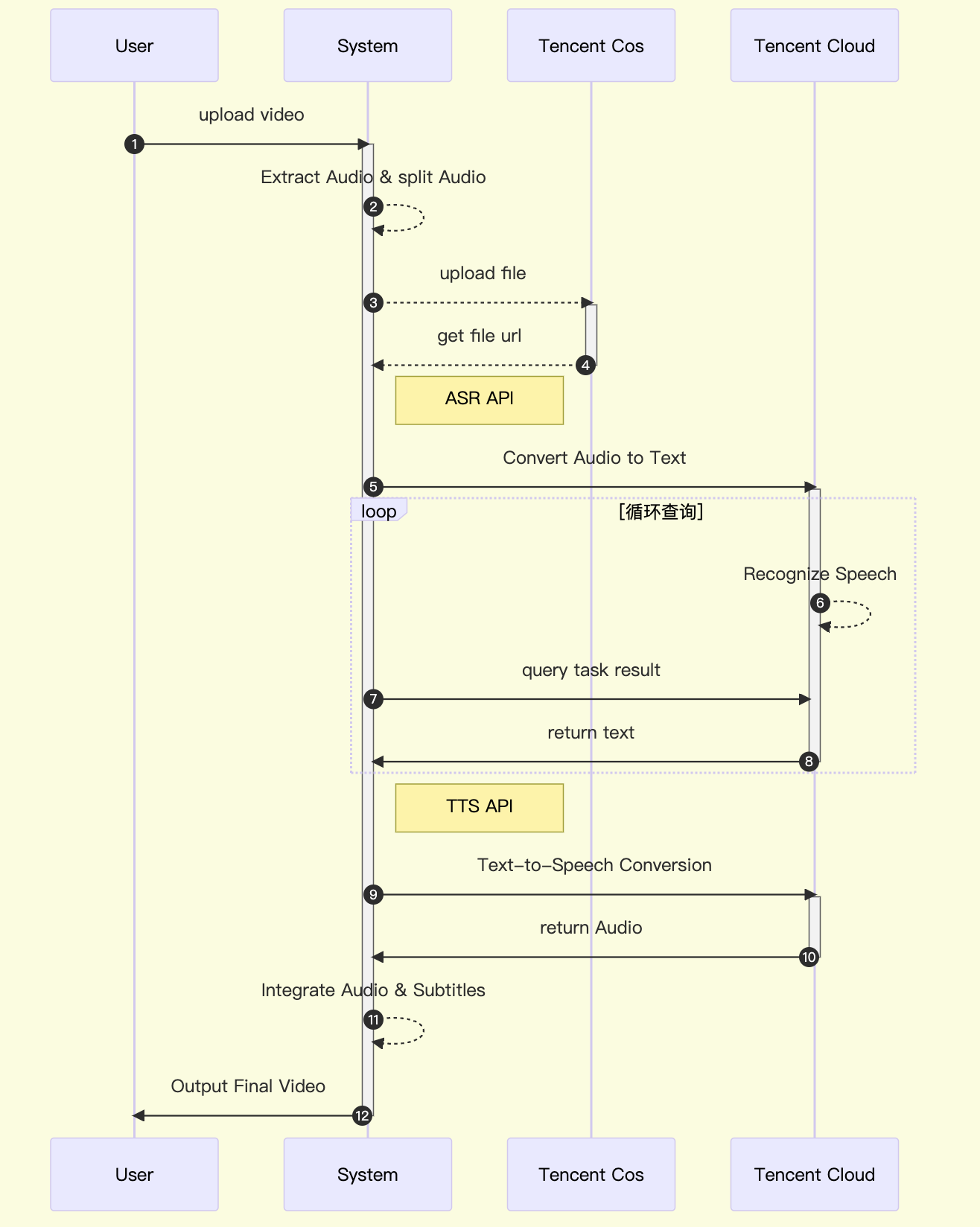
以上就是一个简单的音视频处理时序图,主要包括提取音频文件,语音转文字,文字合成语音,最终集成到原视频中,实现视频原音重塑。当然,这只是简单演示,为了系统可用性我们考虑增加云对象存储服务,存储我们的视频以及音频文件。以下我们使用 python 来实现我们的示例。
提取音频
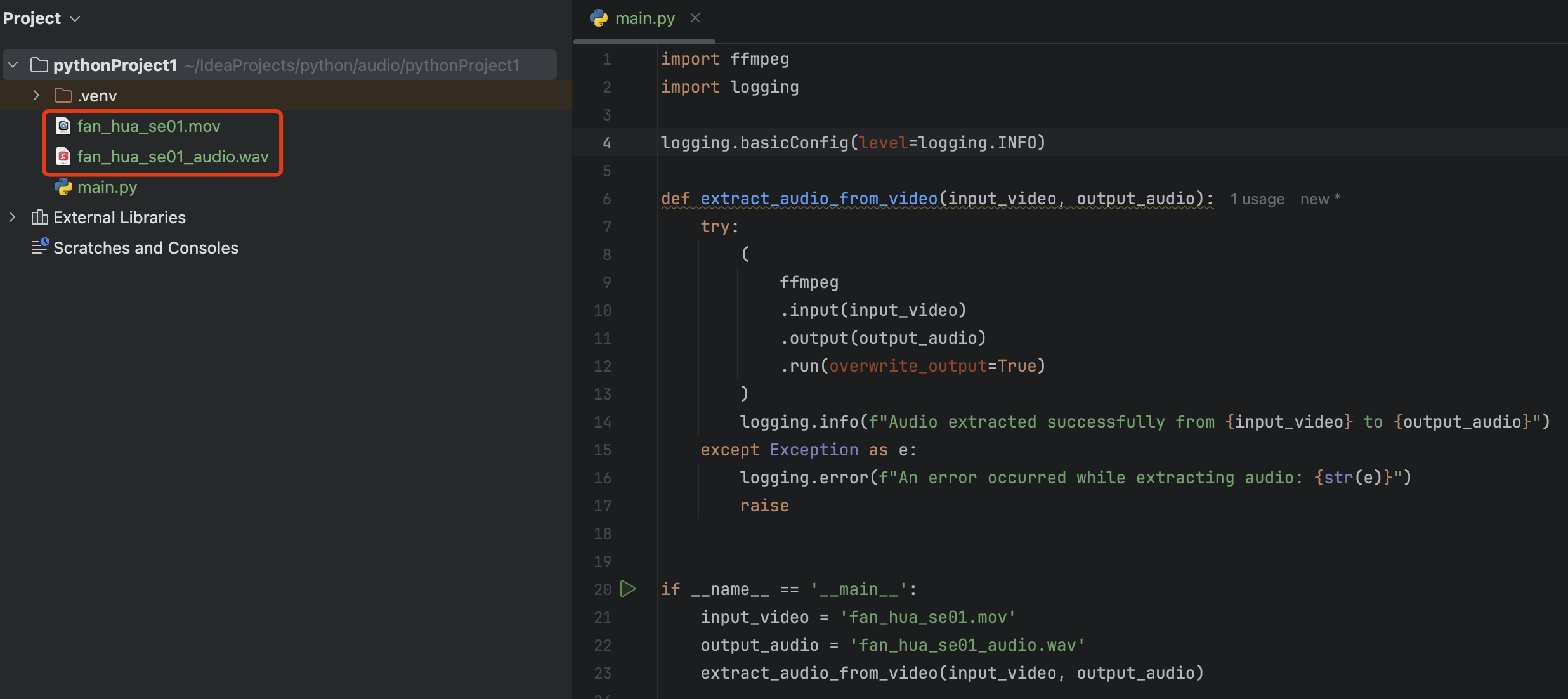
安装基础的 Python 依赖,如 ffmpeg-python、requests、pydub、moviepy、tencentcloud-sdk-python 等
pip install ffmpeg-python requests pydub moviepy tencentcloud-sdk-python- 使用
ffmpeg-python库从视频中提取音频。
import ffmpeg import logginglogging.basicConfig(level=logging.INFO)
def extract_audio_from_video(input_video, output_audio):
try:
(
ffmpeg
.input(input_video)
.output(output_audio)
.run(overwrite_output=True)
)
logging.info(f"Audio extracted successfully from {input_video} to {output_audio}")
except Exception as e:
logging.error(f"An error occurred while extracting audio: {str(e)}")
raise
if name == 'main':
input_video = 'fan_hua_se01.mov'
output_audio = 'fan_hua_se01_audio.wav'
extract_audio_from_video(input_video, output_audio)
运行代码之前需要安装 ffmpeg,并设置好环境变量。通过以上代码,我们的音频就提取好了,可以看到目录下已经生成了 fan_hua_se01_audio.wav 文件。
使用腾讯云 SDK 调用语音识别服务(ASR),因为 ASR 服务请求有最大限制,所以这里需要对我们的音频文件进行预处理。我们有两种处理方式,一种是分割提取好的音频文件。另外一种就是将整个音频文件上传到腾讯云对象存储 COS 服务中,创建音频识别任务,并且异步查询任务结果。这里为了简便,就直接将整个音频上传到 COS 服务,并获取带签名可公网下载的 url 链接。
from qcloud_cos import CosS3Client, CosClientError, CosServiceError, CosConfig将音频文件上传到 COS,并返回上传后的文件路径列表
def upload_to_cos(local_file, bucket, cos_path):
secret_id = 'your_secret_id'
secret_key = 'your_secret_key'
region = 'ap-nanjing' # 替换为你的 COS 存储桶的地域
token = None # 使用临时密钥需要传入 Token,默认为空,可不填写
scheme = 'https' # 指定使用 http/https 协议来访问 COS,默认为 https,可不填写# 设置 COS 配置 config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=token, Scheme=scheme) # 获取客户端对象 client = CosS3Client(config) # 上传文件 client.upload_file( Bucket=bucket, # 存储桶名称 LocalFilePath=local_file, # 本地文件路径 Key=cos_path, # COS 上的文件路径 PartSize=10, # 分片大小设置为10MB,默认为 20MB MAXThread=10, # 最大并发上传线程数设置为 10,默认为 5 EnableMD5=False # 是否启用 MD5 校验,默认为 False ) # logging.info(f"upload to cos resp:{response}") # 生成带签名的 URL,设置过期时间为1小时 signed_url = client.get_presigned_url( Bucket=bucket, Key=cos_path, Method='GET', Expired=time.time() + 3600 # 1小时后过期 ) return signed_url
if name == 'main':
input_audio = 'fan_hua_se01_audio.wav'
bucket_name = 'your-bucket' # COS 桶的名称
file_url = upload_to_cos(input_audio, bucket_name, input_audio)
logging.info(f"file_url:{file_url}")
以上,完成了文件上传以及获取文件 url 链接。我们可以通过控制台查看音频文件。
下面我们将调用 ASR api,识别上传的音频文件,这里我们主要依赖这两个接口, 录音文件识别请求 , 录音文件识别结果查询 。
# 初始化 client
def create_asr_client(key_id, key_secret):
try:
cred = credential.Credential(key_id, key_secret)
http_profile = HttpProfile()
http_profile.endpoint = "asr.tencentcloudapi.com"
client_profile = ClientProfile()
client_profile.httpProfile = http_profile
client_profile.signMethod = "TC3-HMAC-SHA256"
client = asr_client.AsrClient(cred, "ap-shanghai", client_profile)
return client
except TencentCloudSDKException as err:
logging.error(err)
return None创建语音识别任务
def create_recon_task(engine_type, file_url):
client = create_asr_client('your_secret_id', 'your_secret_key')
req = models.CreateRecTaskRequest()
params = {"ChannelNum": 1, "ResTextFormat": 3, "SourceType": 0, "ConvertNumMode": 1}
req._deserialize(params)
req.EngineModelType = engine_type
req.Url = file_url
try:
resp = client.CreateRecTask(req)
logging.info(resp)
requesid = resp.RequestId
taskid = resp.Data.TaskId
return requesid, taskid
except Exception as err:
logging.error(traceback.format_exc())
return None, None查询识别结果
def query_recon_task(taskid):
client = create_asr_client('your_secret_id', 'your_secret_key')
req = models.DescribeTaskStatusRequest()
params = '{"TaskId":' + str(taskid) + '}'
req.from_json_string(params)
result = ""
while True:
try:
resp = client.DescribeTaskStatus(req)
resp_json = resp.to_json_string()
logging.info(resp_json)
resp_obj = json.loads(resp_json)
if not resp_obj["Data"]:
return False, ""
if resp_obj["Data"]["StatusStr"] == "success":
result = resp_obj["Data"]["ResultDetail"]
break
if resp_obj["Data"]["Status"] == 3:
return False, ""time.sleep(1) except TencentCloudSDKException as err: logging.info(err) return False, "" return True, result创建并获取语音识别结果
def creat_audio_task(engine_type, audio_url):
request_id, task_id = create_recon_task(engine_type, audio_url)
ret, result = query_recon_task(task_id)
if ret:
return result
return ""
if name == 'main':
result = creat_audio_task('16k_zh', file_url)
if result:
logging.info(f'result:{result}')
else:
logging.error("result is none")
通过以上逻辑,我们就获取到了音频识别的结果。
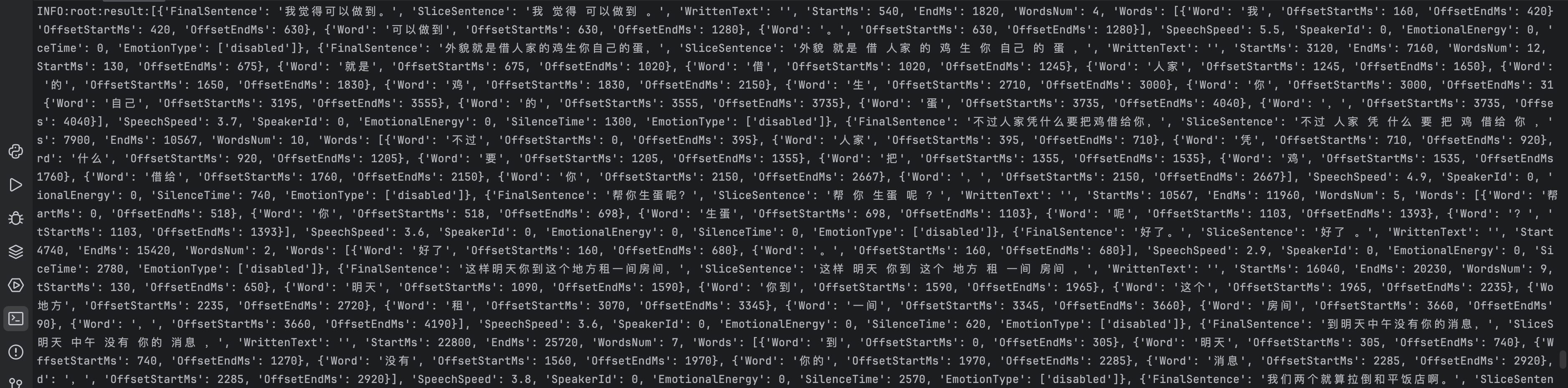
音频合成,获取完成音频识别之后的文本,我们可以通过文本合成新的音频文件。这里也依赖两个接口,长文本语音合成请求,长文本语音合成结果查询 接口。
创建语音合成任务
def create_tts_client(key_id, key_secret):
try:
cred = credential.Credential(key_id, key_secret)
http_profile = HttpProfile()
http_profile.endpoint = "tts.tencentcloudapi.com"
client_profile = ClientProfile()
client_profile.httpProfile = http_profile
client_profile.signMethod = "TC3-HMAC-SHA256"
client = tts_client.TtsClient(cred, "ap-shanghai", client_profile)
return client
except TencentCloudSDKException as err:
logging.error(err)
return None
创建语音合成任务
def create_tts_task(text):
client = create_tts_client('your_secret_id', 'your_secret_key')
tts_req = tts_models.CreateTtsTaskRequest()
tts_req.Text = text
tts_req.VoiceType = 101019
tts_req.Codec = 'wav'
try:
resp = client.CreateTtsTask(tts_req)
logging.info(resp)
request_id = resp.RequestId
taskid = resp.Data.TaskId
return request_id, taskid
except Exception as err:
logging.error(traceback.format_exc())
return None, None
查询合成结果
def query_tts_task(taskid, timeout=600):
client = create_tts_client('your_secret_id', 'your_secret_key')
req = tts_models.DescribeTtsTaskStatusRequest()
req.TaskId = taskid
start_time = time.time()
while True:
try:
resp = client.DescribeTtsTaskStatus(req)
resp_json = resp.to_json_string()
logging.info(resp_json)
resp_obj = json.loads(resp_json)
if not resp_obj["Data"]:
return False, ""
if resp_obj["Data"]["StatusStr"] == "success":
result = resp_obj["Data"]["ResultUrl"]
break
if resp_obj["Data"]["Status"] == 3:
return False, ""
if time.time() - start_time > timeout:
logging.error("Timeout while waiting for TTS task to complete.")
return False, ""
time.sleep(1)
except TencentCloudSDKException as err:
logging.info(err)
return False, ""
return True, result
def new_audio_tts(text):
request_id, task_id = create_tts_task(text)
ret, result = query_tts_task(task_id)
if ret:
return result
return ""
if name == 'main':
audio_url = new_audio_tts(result)
if audio_url:
print(f"Audio URL: {audio_url}")
try:
# 发送 HTTP GET 请求获取文件内容
local_path = 'fan_hua_se01_audio_new.wav'
response = requests.get(audio_url, stream=True)
response.raise_for_status() # 检查请求是否成功
# 将内容写入本地文件
with open(local_path, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print(f"File downloaded successfully: {local_path}")
except requests.exceptions.RequestException as e:
print(f"An error occurred while downloading the file: {e}")
else:
print("Failed to retrieve TTS task result.")</code></pre></div></div><p>通过以上逻辑,我们就实现了语音合成 tts 的调用,最终将合成好的音频文件写入到本地文件。</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:84.19%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723321141467737662.png" /></div><div class="figure-desc">图 6. 合成音频文件</div></div></div></figure><p>这里的音色有多种可选,目前选用的是“粤语女声”,具体可以查看这里的 音色列表。最终我们可以将字幕以及新生成的音频集成到原视频中,生成新的配音视频。</p><h2 id="6bak5" name="%E8%85%BE%E8%AE%AF%E4%BA%91%E8%AF%AD%E9%9F%B3%E6%8A%80%E6%9C%AF%E8%A7%A3%E6%9E%90">腾讯云语音技术解析</h2><p>完成以上实践,我们简要分析腾讯云语音服务背后的技术原理</p><h3 id="fdoqe" name="%E6%8A%80%E6%9C%AF%E5%8E%9F%E7%90%86">技术原理</h3><p> <strong>语音识别</strong> </p><p>首先,语音识别 (Automatic Speech Recognition, ASR) 是将人类的语音信号转换成相应的文本的过程。一个看似简单基本的语音转文字功能,通常需要经过以下几个流程处理。</p><p> <strong>流程</strong> </p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:84.19%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723321141751721683.png" /></div><div class="figure-desc">图 7. 语音转文本流程</div></div></div></figure><p>从最初的音频文件输入,我们需要对输入的音频文件进行信号预处理,以提高信号质量并提取有用的信息,其中包括通过滤波函数去除杂乱无章的噪音,将连续的语音信号分成若干帧,每帧通常为 20-30 ms,帧与帧之间有一定的重叠(通常为10ms),以捕捉瞬时变化的语音特征。</p><p>紧接着就是提取音频文件中的特征,将音频语音信号转变成模型可处理的特征向量(也就是特征矩阵),这其中用到的特征工程通常有短时傅里叶变换 (STFT),将语音信号转换到频域,得到频谱图。倒谱分析,通过离散余弦变换 (DCT) 提取倒谱系数,得到MFCC特征向量。</p><p>音频文件转成特征向量后,就是模型处理发挥作用的时候了,这个阶段主要用到的模型是深度神经网络 (DNN),同时,结合语言模型,循环神经网络 (RNN) 和长短期记忆网络 (LSTM),分析语音上下文的信息,包括词性分析,情感词分析等等。</p><p>最终,我们通过解码算法将声学模型和语言模型的输出结合起来,找到最可能的文本序列,然后输出。这样,一个语音转文本的云服务就完成了。</p><p><strong>语音合成</strong></p><p>语音合成 (Text-to-Speech, TTS) 是将文本合成为音频的技术。其主要技术原理包括以下几个步骤</p><p> <strong>流程</strong> </p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:84.19%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723321142035287472.png" /></div><div class="figure-desc">图 8. 语音合成流程图</div></div></div></figure><p>用户输入需要合成的文本,可以是任何自然语言的句子。我们需要对输入的文本进行自然语言处理(NLP),以提取出合成语音所需的语言学信息。NLP处理主要包括分词、词性标注、句法分析等。</p><p>通过文本清洗处理标点符号、缩写、数字等,转换为标准文本。最后进行分词和词性标注,将文本分解成单独的词语或音节,并标注每个词的词性。</p><p>声学模型负责将预处理后的文本转换为对应的声学特征参数。在模型处理之前我们需要数据准备,收集和整理大规模的标注语料库。模型训练,使用深度神经网络(如Tacotron、FastSpeech)训练声学模型,将文本转换为声学特征。目前主流的声学模型包括基于深度学习的神经网络模型和基于统计学习的隐马尔可夫模型(HMM)。模型优化迭代,通过不断的模型训练和优化,提高模型的准确性和生成质量。</p><p>声码器将声学模型生成的特征参数转换为波形信号,生成最终的合成语音。需要进行特征提取,从声学模型输出中提取必要的声学特征参数,如梅尔频谱、基频等。波形合成,使用声码器(如WaveNet、WaveGlow、HiFi-GAN)合成语音波形。波形优化,对合成的语音波形进行后处理,以提高语音质量。</p><h3 id="3gsdp" name="%E9%9A%BE%E7%82%B9%E4%B8%8E%E6%8C%91%E6%88%98">难点与挑战</h3><p> <strong>语音识别</strong></p><p>语音识别中的主要技术难点在于,在音频预处理方面,音频降噪技术需要先进的信号处理技术来过滤噪声,提高语音信号的质量。简单的音频处理可以通过一些低通滤波函数,还可以使用一些开源的语音增强工具,例如:FunASR 是阿里巴巴达摩院开源的语音增强工具,复杂的可能需要使用到 RNN 循环卷积神经网络。</p><p>另外的难点就是多样化口音,不同地区和背景的用户可能有不同的口音,这会影响识别的准确性。方言和地方语言的多样性使得统一的ASR系统难以处理所有语言变种。我们需要大量包含不同口音和方言的训练数据来训练模型,以提高其普适性,需要在语言模型中加入多种口音和方言的语料库。</p><p>还有就是上下文处理,需要先进的上下文理解能力,能够根据前后文正确识别连读或省略的音节。</p><p> <strong>语音合成</strong> </p><p>语音合成技术在不断发展和进步,但在数据标注、自然度与情感表达、以及版权问题上仍然面临诸多挑战。</p><p>语音标注,高质量的语音合成系统需要大量的标注数据,收集和标注这些数据既费时又费力。通常,这种高质量的标注数据由专门的数据平台和团队合作完成。腾讯数据厨房致力于为全球客户提供语音数据采集,标注和语音识别,模型测评等服务,帮助客户提升模型研发。</p><p>自然度与情感表达,合成语音的自然度是评价 TTS 系统的重要指标。如何使合成语音听起来像真人说话一样自然,是一个重要的技术难点。在合成语音中准确传达情感,如高兴、悲伤、愤怒等,是一项复杂的任务。情感表达需要细腻的声学特征和丰富的训练数据。不同的语调和语速会影响语音的自然度和情感表达。如何控制和调整这些因素以达到最佳效果是一个难点。</p><p>最后是版权问题,用于训练 TTS 模型的语音数据通常涉及版权问题,特别是从公开渠道收集的语音数据,需要合法授权和版权保护。在合成语音中模仿特定人物或声音时,可能会涉及肖像权和声音版权的侵权风险,需要谨慎处理。</p><p>近期,美国演员和歌手斯嘉丽发布声明称,OpenAI ChatGPT 的声音之一 Sky 与她本人声音极为相似,并透露此前她已经拒绝了 CEO 山姆·阿尔特曼(Sam Altman)邀请配音。在斯嘉丽的法律代表联系 OpenAI 之后,OpenAI 暂时下线了 ChatGPT 中的 Sky 声音。</p><h2 id="a29kc" name="%E6%9C%AA%E6%9D%A5%E5%BA%94%E7%94%A8">未来应用</h2><ol class="ol-level-0"><li>语音云服务在方言配音上有极大的优势,主要的方言可能有粤语和沪语。通过语音合成技术,实现多种方言的精准配音,满足地方文化和语言的传承与发展需求。让影视作品、教育资源和公共服务内容更加本地化和亲民。</li><li>视频出海,近期视频出海也极其火热,语音合成技术可以为视频内容提供多语言配音支持,助力短视频和影视剧的国际化传播。通过精准且自然的语音合成,使观众能够无障碍地享受来自不同文化背景的视频内容。</li><li>在智能客服、智能音箱和虚拟人直播等场景中,语音合成技术可以实现高效的自动朗读和交互,为用户提供更自然、更流畅的体验。智能客服可以借助此技术提供 24 小时不间断服务,智能音箱则可以用更加拟人化的声音与用户互动,虚拟人直播更是能够通过合成语音,实现更加生动和个性化的直播效果。</li><li>无障碍音视频,自动朗读,语音合成技术可以在智能化场景中实现高效的自动朗读,为视觉障碍人士提供无障碍的音视频内容,增强信息的可及性。</li></ol><h2 id="crad9" name="%E6%80%BB%E7%BB%93">总结</h2><p>本文通过详细的语音识别和语音合成实践,展示了如何利用腾讯云语音服务对音视频进行高效处理。从音频提取、分割、上传至云端,到语音转文字和文字转语音的完整流程,提供了详细的代码实现和操作指南,帮助读者掌握这两项技术的实际应用。此外,本文还对语音识别和语音合成背后的技术原理进行了简要分析,深入探讨了其涉及的自然语言处理、声学模型、声码器合成等关键技术环节。</p><p>通过这些实践和理论的结合,相信大家不仅能够了解具体的实现步骤,还能对语音技术的核心原理有更全面的理解。最后,文章分析了语音识别和语音合成未来可能的应用场景,包括智能助手、语音翻译、虚拟客服、个性化教育等。这些应用场景展示了语音技术在不同领域的广泛前景,预示着其在推动人机交互、提升用户体验和促进产业升级方面的巨大潜力。通过不断创新和优化,语音技术将为我们的生活带来更多便捷和可能性。</p><p>注:以上使用的音视频均来源于互联网,仅用于实践演示,未做商业用途,如有侵权,请联系本人删除。</p>