原文链接: http://tecdat.cn/?p=8585
了解如何在Python中使用WordCloud对自然语言处理执行探索性数据分析。
什么是WordCloud?

很多时候,您可能会看到一片云,上面堆满了许多大小不同的单词,这些单词代表了每个单词的出现频率或重要性。这称为标签云或词云。对于本教程,您将学习如何在Python中创建自己的WordCloud并根据需要自定义它。
先决条件
该numpy库是最流行和最有用的库之一,用于处理多维数组和矩阵。它还与Pandas库结合使用以执行数据分析。
wordcloud安装可能有些棘手。如果您只需要它来绘制基本的wordcloud,则pip install wordcloud或conda install -c conda-forge wordcloud就足够了。
git clone https://github.com/amueller/word_cloud.gitcd word_cloudpip install .资料集:
首先,您加载所有必需的库:
# Start with loading all necessary librariesimport numpy as npimport pandas as pdfrom os import pathfrom PIL import Imagefrom wordcloud import WordCloud, STOPWORDS, ImageColorGeneratorimport matplotlib.pyplot as plt% matplotlib inlinec:\intelpython3\lib\site-packages\matplotlib\__init__.py:import warningswarnings.filterwarnings("ignore")
加载数据框。请注意,index_col=0我们没有将行名(索引)作为单独的列读入。
# Load in the dataframedf = pd.read_csv("data/winemag-data-130k-v2.csv", index_col=0)# Looking at first 5 rows of the datasetdf.head()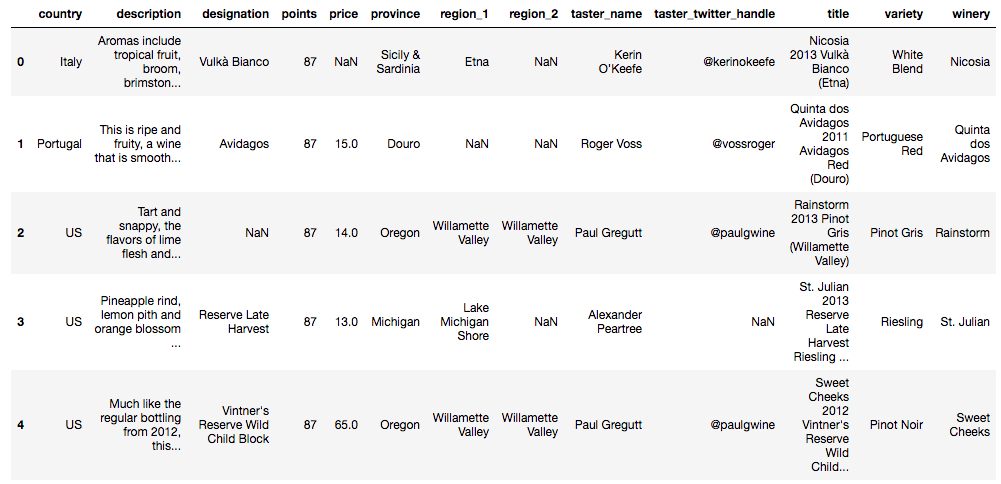
得到打印输出。
print("There are {} observations and {} features in this dataset. \n".format(df.shape[0],df.shape[1]))print("There are {} types of wine in this dataset such as {}... \n".format(len(df.variety.unique()), ", ".join(df.variety.unique()[0:5])))print("There are {} countries producing wine in this dataset such as {}... \n".format(len(df.country.unique()), ", ".join(df.country.unique()[0:5])))There are 129971 observations and 13 features in this dataset.There are 708 types of wine in this dataset such as White Blend, Portuguese Red, Pinot Gris, Riesling, Pinot Noir...There are 44 countries producing wine in this dataset such as Italy, Portugal, US, Spain, France...df[["country", "description","points"]].head()国家 | 描述 | 点数 | |
|---|---|---|---|
0 | 意大利 | 香气包括热带水果,扫帚,brimston ... | 87 |
1个 | 葡萄牙 | 这是成熟果香,柔滑的酒... | 87 |
2 | 我们 | 酸和活泼,酸橙果肉的味道和... | 87 |
3 | 我们 | 菠萝皮,柠檬髓和橙花... | 87 |
4 | 我们 | 就像2012年以来的常规装瓶一样,这... | 87 |
使用groupby()和计算摘要统计信息。
使用葡萄酒数据集,您可以按国家/地区分组并查看所有国家/地区的价格。
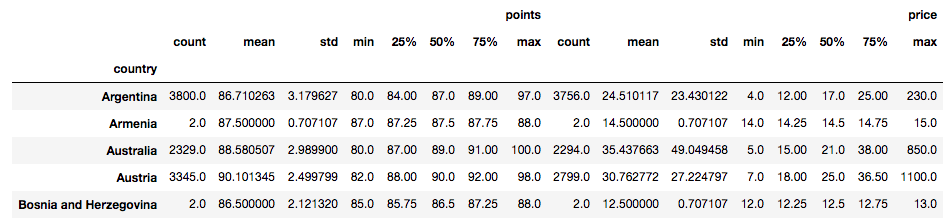
这将在所有44个国家/地区中选择前5个最高平均分:
点数 | 价钱 | |
|---|---|---|
国家 | ||
英国 | 91.581081 | 51.681159 |
印度 | 90.222222 | 13.333333 |
奥地利 | 90.101345 | 30.762772 |
德国 | 89.851732 | 42.257547 |
加拿大 | 89.369650 | 35.712598 |
您可以使用Pandas DataFrame和Matplotlib的plot方法按国家/地区对葡萄酒的数量进行绘制。
plt.ylabel("Number of Wines")plt.show()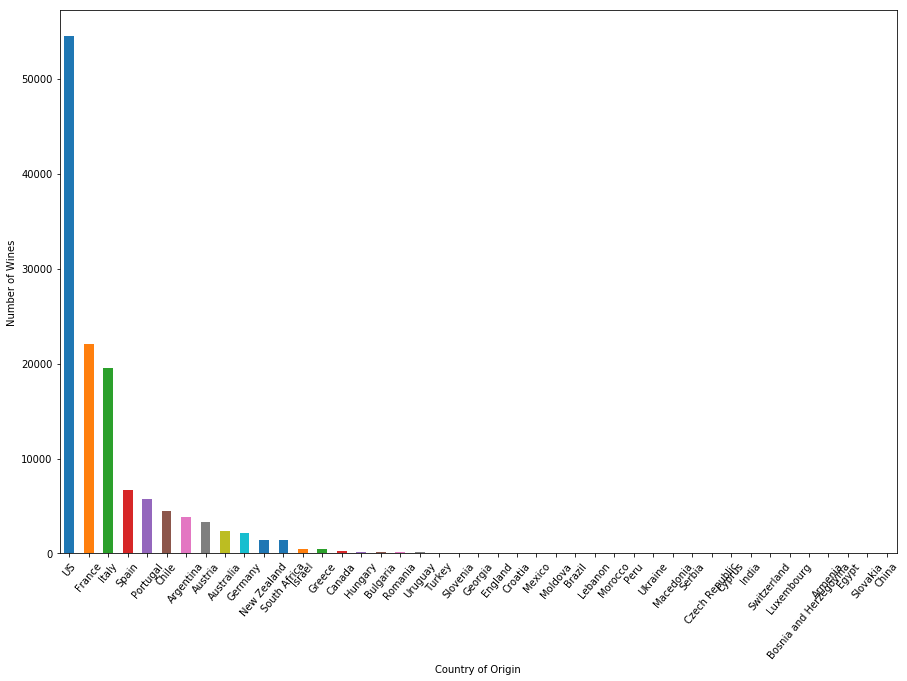
在44个生产葡萄酒的国家中,美国的葡萄酒评论数据集中有50,000多种葡萄酒,是排名第二的国家的两倍:法国-以其葡萄酒而闻名的国家。意大利还生产大量优质葡萄酒,有近20,000种葡萄酒可供审查。
数量超过质量吗?
现在,按照评分最高的葡萄酒查看所有44个国家/地区的地块:
plt.ylabel("Highest point of Wines")plt.show()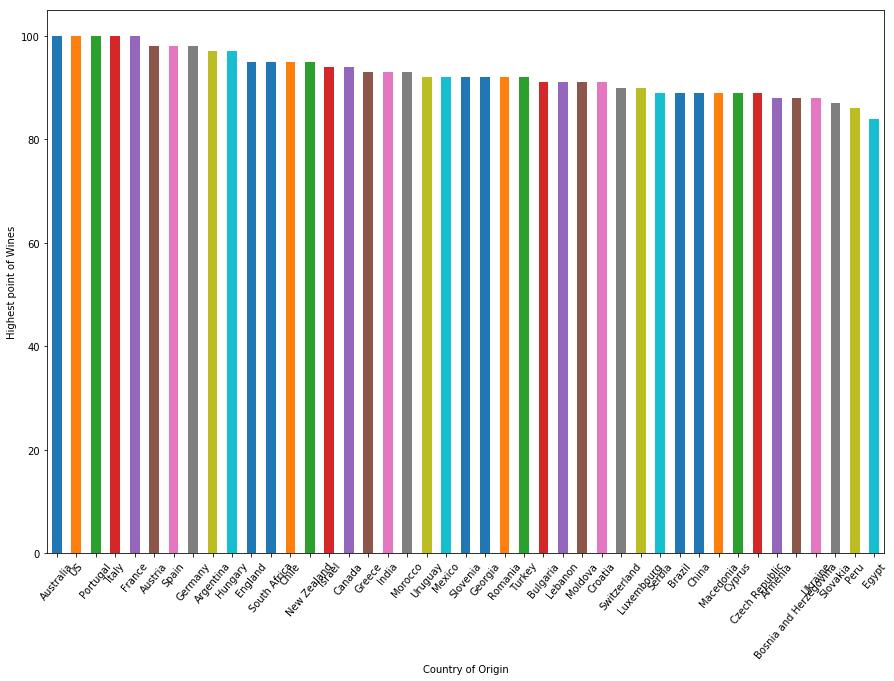
澳洲,美国,葡萄牙,意大利和法国都有100分的葡萄酒。如果您注意到,在数据集中生产的葡萄酒数量上,葡萄牙排名第5,澳大利亚排名第9,这两个国家/地区的葡萄酒种类少于8000。
设置基本的WordCloud
使用任何函数之前,您可能要做的第一件事是检出函数的文档字符串,并查看所有必需和可选参数。为此,键入?function并运行它以获取所有信息。
?WordCloud/*
* 提示:该行代码过长,系统自动注释不进行高亮。一键复制会移除系统注释
* [1;31mInit signature:[0m [0mWordCloud[0m[1;33m([0m[0mfont_path[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mwidth[0m[1;33m=[0m[1;36m400[0m[1;33m,[0m [0mheight[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmargin[0m[1;33m=[0m[1;36m2[0m[1;33m,[0m [0mranks_only[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mprefer_horizontal[0m[1;33m=[0m[1;36m0.9[0m[1;33m,[0m [0mmask[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mscale[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mcolor_func[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mmax_words[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmin_font_size[0m[1;33m=[0m[1;36m4[0m[1;33m,[0m [0mstopwords[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mrandom_state[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mbackground_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m,[0m [0mmax_font_size[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mfont_step[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mmode[0m[1;33m=[0m[1;34m'RGB'[0m[1;33m,[0m [0mrelative_scaling[0m[1;33m=[0m[1;36m0.5[0m[1;33m,[0m [0mregexp[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mcollocations[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcolormap[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mnormalize_plurals[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcontour_width[0m[1;33m=[0m[1;36m0[0m[1;33m,[0m [0mcontour_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m)[0m[1;33m[0m[0m[1;31mDocstring:[0m Word cloud object for generating and drawing.Parameters----------font_path : string Font path to the font that will be used (OTF or TTF). Defaults to DroidSansMono path on a Linux machine. If you are on another OS or don't have this font; you need to adjust this path.width : int (default=400) Width of the canvas.height : int (default=200) Height of the canvas.prefer_horizontal : float (default=0.90) The ratio of times to try horizontal fitting as opposed to vertical. If prefer_horizontal < 1, the algorithm will try rotating the word if it doesn't fit. (There is currently no built-in way to get only vertical words.)mask : nd-array or None (default=None) If not None, gives a binary mask on where to draw words. If mask is not None, width and height will be ignored, and the shape of mask will be used instead. All white (#FF or #FFFFFF) entries will be considered "masked out" while other entries will be free to draw on. [This changed in the most recent version!]contour_width: float (default=0) If mask is not None and contour_width > 0, draw the mask contour.contour_color: color value (default="black") Mask contour color.scale : float (default=1) Scaling between computation and drawing. For large word-cloud images, using scale instead of larger canvas size is significantly faster, but might lead to a coarser fit for the words.min_font_size : int (default=4) Smallest font size to use. Will stop when there is no more room in this size.font_step : int (default=1) Step size for the font. font_step > 1 might speed up computation but give a worse fit.max_words : number (default=200) The maximum number of words.stopwords : set of strings or None The words that will be eliminated. If None, the build-in STOPWORDS list will be used.background_color : color value (default="black") Background color for the word cloud image.max_font_size : int or None (default=None) Maximum font size for the largest word. If None, the height of the image is used.mode : string (default="RGB") Transparent background will be generated when mode is "RGBA" and background_color is None.relative_scaling : float (default=.5) Importance of relative word frequencies for font-size. With relative_scaling=0, only word-ranks are considered. With relative_scaling=1, a word that is twice as frequent will have twice the size. If you want to consider the word frequencies and not only their rank, relative_scaling around .5 often looks good. .. versionchanged: 2.0 Default is now 0.5.color_func : callable, default=None Callable with parameters word, font_size, position, orientation, font_path, random_state that returns a PIL color for each word. Overwrites "colormap". See colormap for specifying a matplotlib colormap instead.regexp : string or None (optional) Regular expression to split the input text into tokens in process_text. If None is specified, ``r"\w[\w']+"`` is used.collocations : bool, default=True Whether to include collocations (bigrams) of two words. .. versionadded: 2.0colormap : string or matplotlib colormap, default="viridis" Matplotlib colormap to randomly draw colors from for each word. Ignored if "color_func" is specified. .. versionadded: 2.0normalize_plurals : bool, default=True Whether to remove trailing 's' from words. If True and a word appears with and without a trailing 's', the one with trailing 's' is removed and its counts are added to the version without trailing 's' -- unless the word ends with 'ss'.Attributes----------``words_`` : dict of string to float Word tokens with associated frequency. .. versionchanged: 2.0 ``words_`` is now a dictionary``layout_`` : list of tuples (string, int, (int, int), int, color)) Encodes the fitted word cloud. Encodes for each word the string, font size, position, orientation, and color.Notes-----Larger canvases will make the code significantly slower. If you need alarge word cloud, try a lower canvas size, and set the scale parameter.The algorithm might give more weight to the ranking of the wordsthen their actual frequencies, depending on the ``max_font_size`` and thescaling heuristic.[1;31mFile:[0m c:\intelpython3\lib\site-packages\wordcloud\wordcloud.py[1;31mType:[0m type
*/您可以看到WordCloud对象唯一需要的参数是text,而所有其他参数都是可选的。
因此,让我们从一个简单的示例开始:使用第一个观察描述作为wordcloud的输入。三个步骤是:
- 提取评论(文本文件)
- 创建并生成wordcloud图像
- 使用matplotlib显示云
# Display the generated image:plt.imshow(wordcloud, interpolation='bilinear')plt.axis("off")plt.show()
您可以看到第一篇评论提到了很多关于葡萄酒的香气。
现在,改变WordCloud像一些可选参数max_font_size,max_word和background_color。
plt.imshow(wordcloud, interpolation="bilinear")plt.axis("off")plt.show()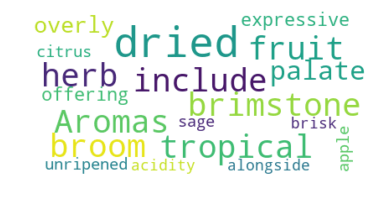
如果要保存图像,WordCloud提供了一个功能 to_file
# Save the image in the img folder:wordcloud.to_file("img/first_review.png")<wordcloud.wordcloud.WordCloud at 0x16f1d704978>将它们加载到其中时,结果将如下所示:

因此,现在您将所有葡萄酒评论合并为一个大文本,并创建一个巨大的胖云,以查看这些葡萄酒中最常见的特征。
print ("There are {} words in the combination of all review.".format(len(text)))There are 31661073 words in the combination of all review.# Display the generated image:# the matplotlib way:plt.imshow(wordcloud, interpolation='bilinear')plt.axis("off")plt.show()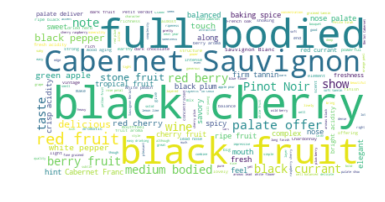
哦,似乎黑樱桃和浓郁的醇厚是最受欢迎的特征,而赤霞珠则是最受欢迎的特征。这与赤霞珠“是世界上最广为人知的红酒葡萄品种之一。
现在,让我们将这些话倒入一杯葡萄酒中!
为了为您的wordcloud创建形状,首先,您需要找到一个PNG文件以成为遮罩。以下是一个不错的网站,可以在Internet上找到它:

为了确保遮罩能够正常工作,让我们以numpy数组形式对其进行查看:
array([[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], dtype=uint8)首先,使用该transform_format()函数将数字0交换为255。
def transform_format(val): if val == 0: return 255 else: return val然后,创建一个形状与您现有的蒙版相同的新蒙版,并将该功能transform_format()应用于上一个蒙版的每一行中的每个值。
现在,您将以正确的形式创建一个新的蒙版。array([[255, 255, 255, ..., 255, 255, 255], [255, 255, 255, ..., 255, 255, 255], [255, 255, 255, ..., 255, 255, 255], ..., [255, 255, 255, ..., 255, 255, 255], [255, 255, 255, ..., 255, 255, 255], [255, 255, 255, ..., 255, 255, 255]])好的!使用正确的蒙版,您可以开始使用选定的形状制作wordcloud。
# showplt.figure(figsize=[20,10])plt.imshow(wc, interpolation='bilinear')plt.axis("off")plt.show()
创建了一个酒瓶形状的wordcloud!似乎葡萄酒描述中最常提及的是黑樱桃,水果风味和葡萄酒的浓郁特性。现在,让我们仔细看看每个国家/地区的评论:

按照颜色图案创建wordcloud
可以合并五个拥有最多葡萄酒的国家的所有评论。要查找这些国家/地区,可以查看地块国家/地区与上方的葡萄酒数量的关系,也可以使用上方的组来查找每个国家/地区(每个组)的观察数量,并sort_values()使用参数ascending=False降序排列。
countryUS 54504France 22093Italy 19540Spain 6645Portugal 5691dtype: int64因此,现在您有5个热门国家/地区:美国,法国,意大利,西班牙和葡萄牙。
countryUS 54504France 22093Italy 19540Spain 6645Portugal 5691Chile 4472Argentina 3800Austria 3345Australia 2329Germany 2165dtype: int64目前,仅5个国家就足够了。
要获得每个国家/地区的所有评论,您可以使用" ".join(list)语法将所有评论连接起来,该语法将所有元素合并在以空格分隔的列表中。
然后,如上所述创建wordcloud。
# store to fileplt.savefig("img/us_wine.png", format="png")plt.show()
看起来不错!现在,让我们再重复一次法国的评论。
# store to fileplt.savefig("img/fra_wine.png", format="png")#plt.show()请注意,绘图后应保存图像,以使单词云具有所需的颜色模式。

# store to fileplt.savefig("img/ita_wine.png", format="png")#plt.show()
继意大利之后是西班牙:
# store to fileplt.savefig("img/spa_wine.png", format="png")#plt.show()
最后,葡萄牙:
# store to fileplt.savefig("img/por_wine.png", format="png")#plt.show()
最终结果在下表中。




