推荐:Python爬虫&可视化之舌尖上的“小龙虾”

下载网易云音乐.
1.寻找目标请求
打开网易云主页 ,打开开发者工具,点击搜索
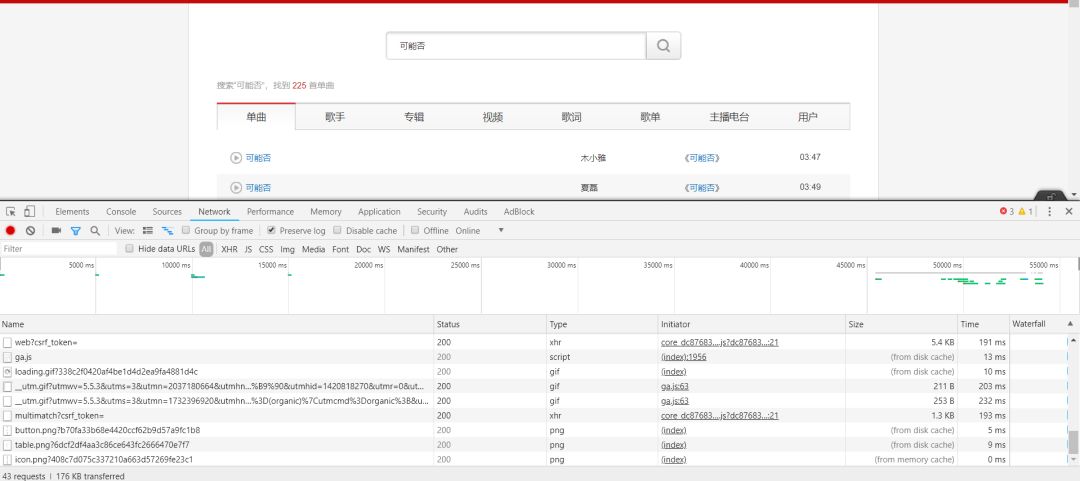
是不是看到很多请求,不要慌,慢慢找。找了之后你会发现下面这个链接
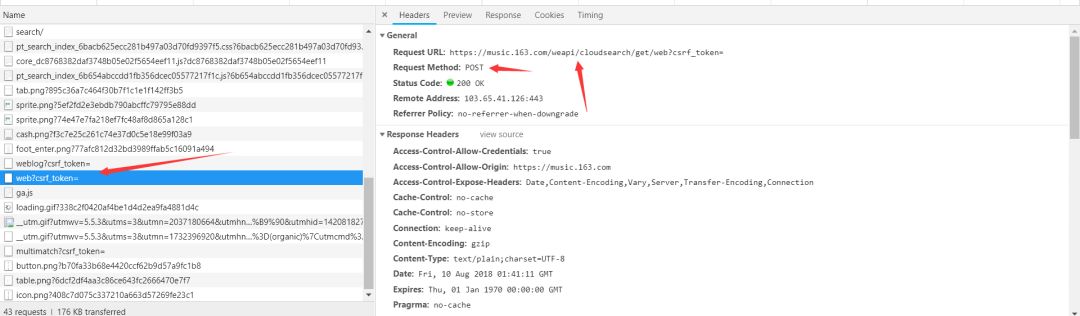

这个链接返回的是json,里面包含的是歌曲的信息,但是没有MP3播放链接,这个或许有用,因为有歌曲的id,先放着。
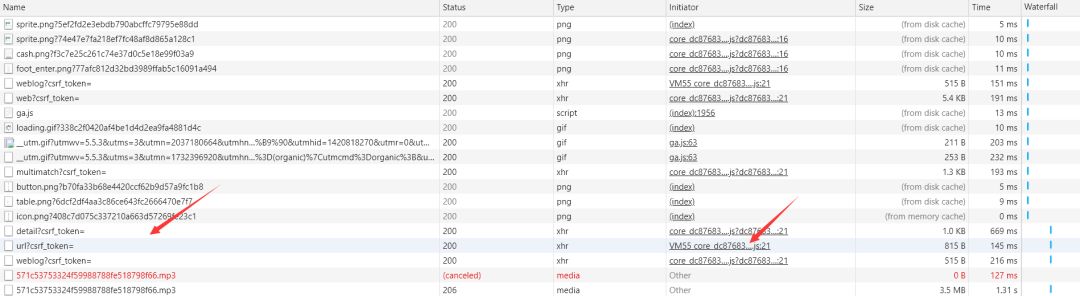
我试着点击歌曲播放,又增加了几个请求。一看,里面就有我想要的MP3链接。

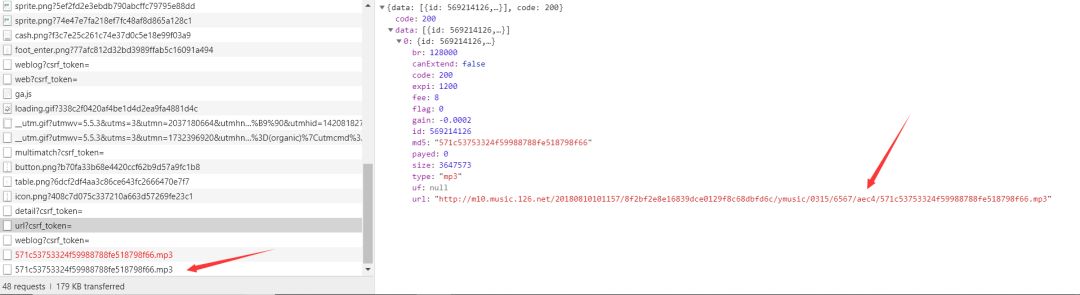
这样子,获取mp3请求的链接出来了,https://music.163.com/weapi/song/enhance/player/url?csrf_token=
可以看到是个post请求,状态码为200,我们接着往下看fromdata是什么数据。

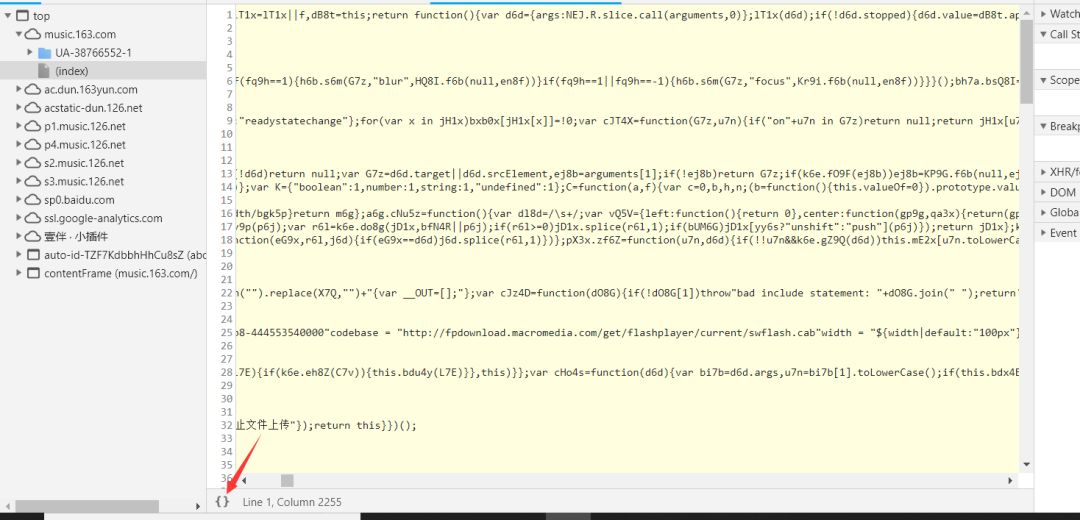
是两个加密了的参数,不过不怕,如果你看过我之前写的利用python爬取网易云音乐,并把数据存入mysql你会发现fromdata参数是一样的,所以破解加密参数思路是一样的,不过这次我不用fiddler了,只用开发者工具来调试,看好了!!!我们看看这个请求的来源是什么。
点进去看看,是个混淆的js,点左下角可以格式化,这样好看点。
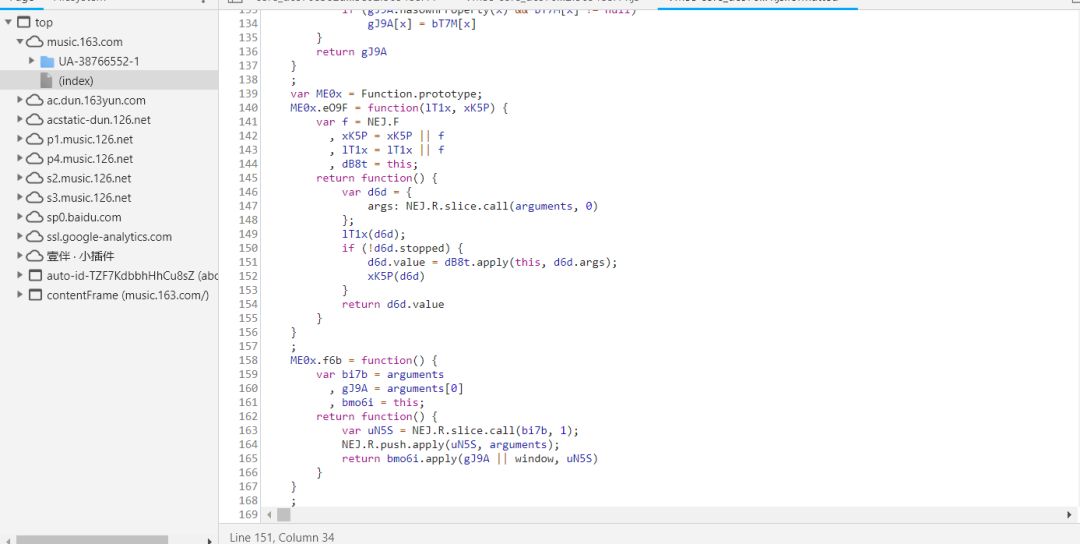
进行搜索params,你会发现这个:

可以看到,加密的方式都没有改变,还是和之前一样,只是变量名字改变了。window.asrsea()有四个参数,先看看后面三个参数,因为都很相似。继续进行搜索定位。
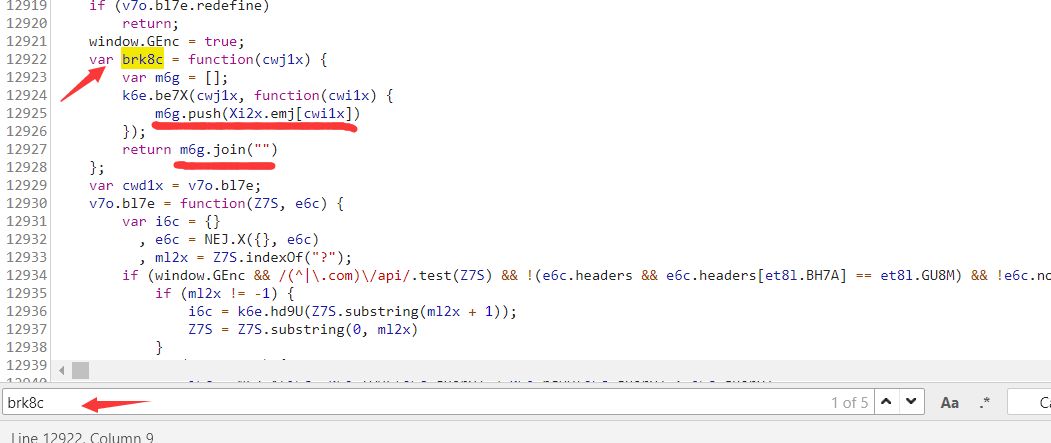
可以看出,返回的是一个固定的内容,所以不用管了,等下可以进行调试抓出来。再看看第一个参数。是一个json。我们可以进行断点调试进行获取。

进行刷新,你会看到下面这些内容。
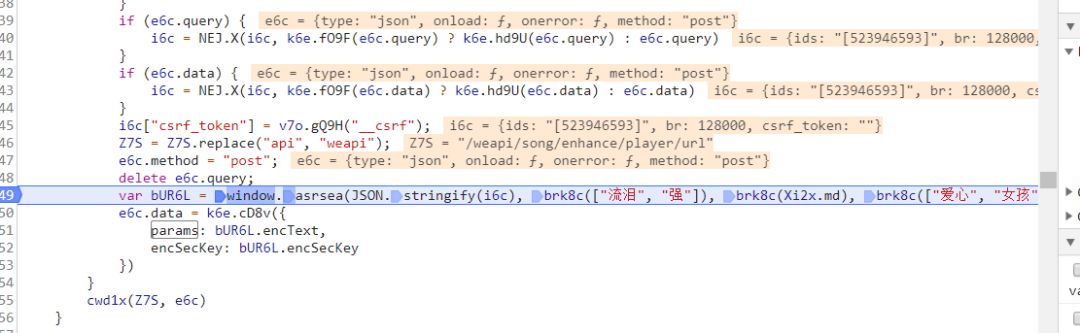
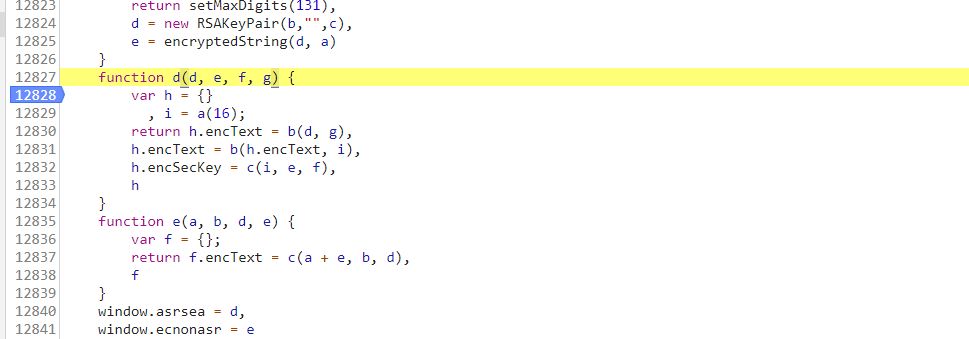
可以看到window.asrsea()是一个d函数,定位过去看看,然后又给个断点。
点击去往下一个断点,你会看到
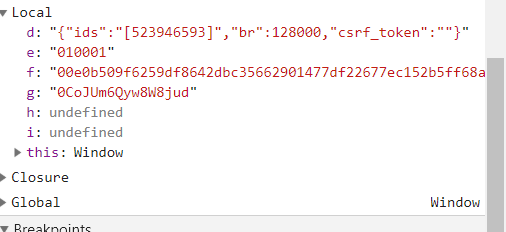
四个参数都出来了,我直接贴出来这里吧:
d:"{"ids":"[523946593]","br":128000,"csrf_token":""}"
e:"010001"
f:"00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
g:"0CoJUm6Qyw8W8jud"参数都出来了,很容易就知道d参数里面的ids对应的就是歌曲id,所以说刚才找的链接有用了。br是个固定值,对应的可能是歌曲的质量之类的,不需要管的。
下面再看看d函数是如何加密的:

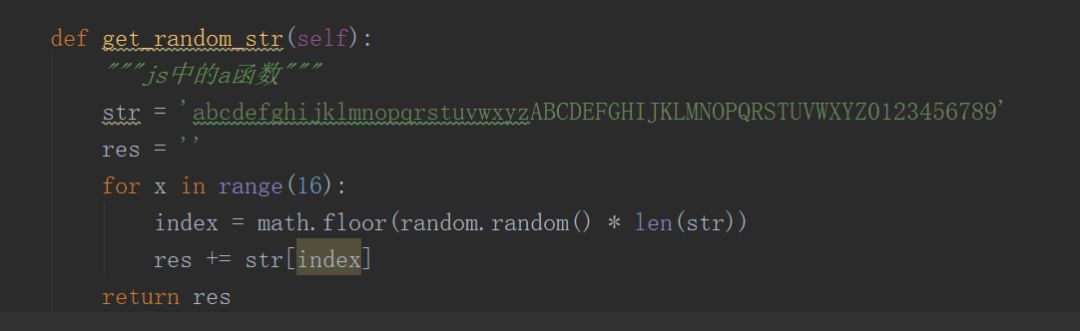
里面又包含了很多 a , b ,c 的三个函数,先看看 a 函数

这个 a 函数是在一堆字符串中随机找出16个字符串。ok,下一个。

b 函数采用了 aes 加密, 加密的密文是 e ,也就是参数的 a 内容,c是密钥,第三个参数中有偏移量 d 和加密模式 CBC 。再看看 c 函数。

c 函数是采用 rsa 加密,b 为加密指数, 空字符串为解密参数,c 为加密系数。
好了,三个函数分析完毕,再回头看看 d 函数。

可以看到params参数是经过两次 b 函数生成的,也就是用 aes 加密两次,encSecKey参数是通过 c 函数生成的,也就是通过 rsa 加密方式生成的。
废话不多说,Talk is cheap, show me the code
2.代码部分
先把随机生成16个字符串的展示下
为了让大家好看点,代码以后都用照片代替
接下来是aes加密的
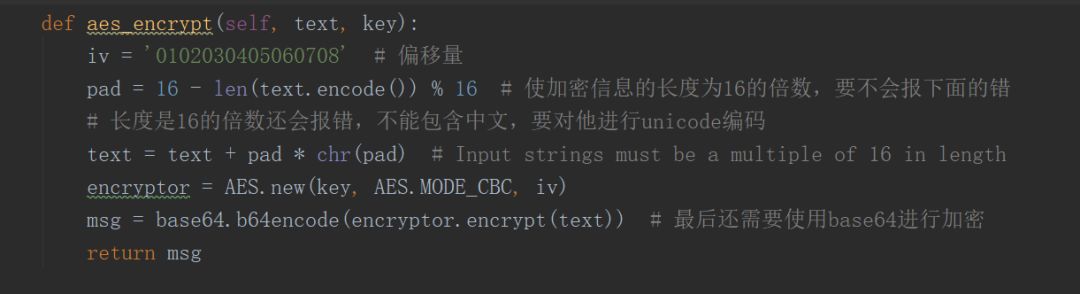
这里有一个巨坑,谷歌了也没发现有谁遇到过,就是用python进行aes加密的时候,只能加密数字和字母,不能对中文进行加密,会报错
Input strings must be a multiple of 16 in length解决方方法是在cbc加密的模式下,在对字符串补齐为长度为16的倍数时,长度指标不能用中文,要先把他转为unicode编码的长度才可以。比如上面的,下面的就是错误示范
pad = 16 - len(text) % 16此坑爬过去了,接着下一个rsa加密

还有需要注意一下的是,在生成随机16个字符串的时候,需要保证params和encSecKey两个参数是对应的这个随机字符串是一致的。要不然加密之后还是会出错,获取不了正确信息。好了,最后一个是获取两个加密参数。

代码写完了,那还等什么,运行一下装逼啊!
{'code': -460, 'msg': 'Cheating'}这下好了,装逼失败,被网易云认出来我是爬虫的,那我试试加下请求头?结果加了还是一个样,这个也算是个巨坑吧。解决方法还是加请求头,只需要加两个,一个是浏览器识别 user-agent ,另一个是 cookie ,想不到吧?我也想不到,居然还有在cookie上面做反爬的,但是我用了 session 来保持cookie还是不行,需要自己复制浏览的cookie就行保存才可以。
歌曲现在能下载了,可我要的是任意歌曲啊。那好,我们再去看看这个请求https://music.163.com/weapi/cloudsearch/get/web?csrf_token=,因为返回的是歌曲id。
3.寻找歌曲id
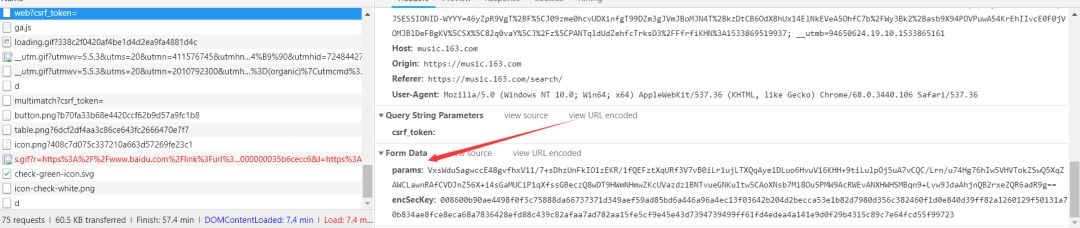
可以看到,参数还是和上面的那个请求的参数一样,但是我们知道的是那个 d 函数,后三个参数是不变的,所以我们只需要找前面那个变化的参数就可以了,还是同样的操作,断点调试。
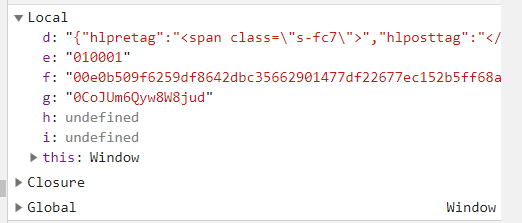
也是很容易就找到的,d 参数就是下面这个
d = '{"hlpretag":"<span class=\\"s-fc7\\">","hlposttag":"</span>","s":"可能否","type":"1","offset":"0","total":"true","limit":"30","csrf_token":""}'这个分析就可以说完毕了。
4.搜索歌曲代码

这个是获取歌曲 id 的代码,其他的没什么问题了。
最后
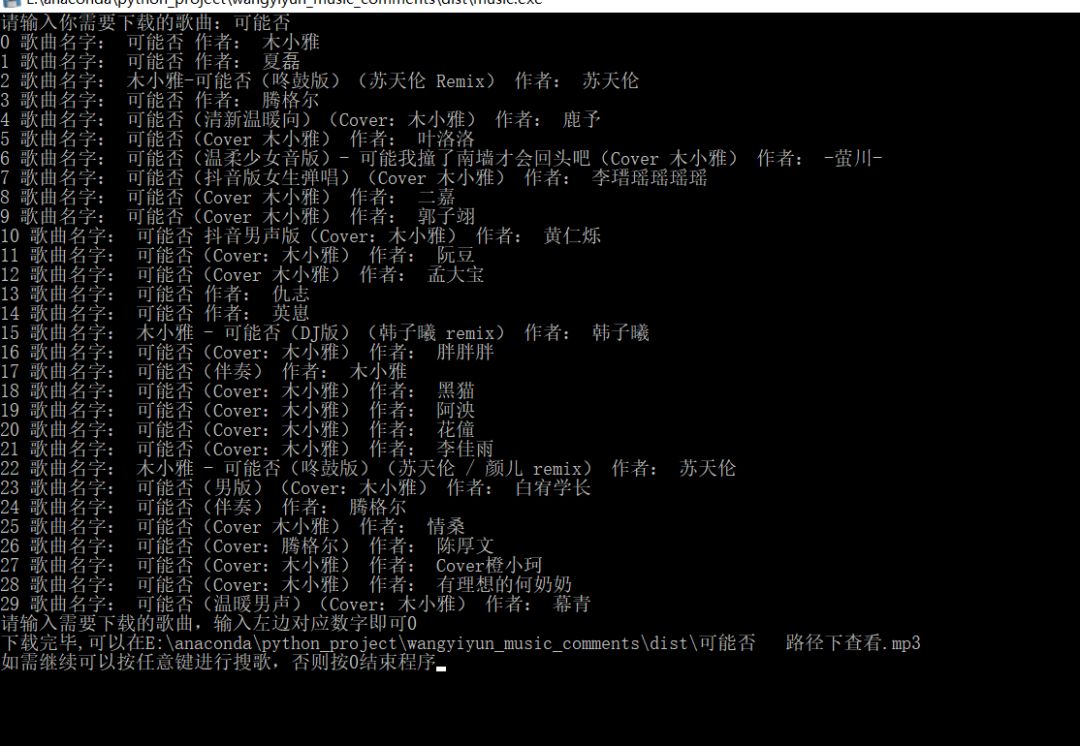
我还将程序打包了,遇到了喜欢的歌曲都可以下载下来,虽然可以直接用网易云下载,不用那么麻烦,但是我们学编程的是要干什么的?装逼啊,能用代码绝不用其他的东西。
推荐阅读
Python爬虫实战题荟萃
「从0到1」Python爬虫专题完结版