上篇博客我们讲解了计算机汇编语言是如何实现循环结构的。本篇博客我们将介绍汇编语言中过程的实现方式。
过程在高级语言中也称为函数,方法。一个过程的调用包括将数据(以过程参数和返回值的形式)和控制从代码的一部分传递到另一部分。此外,它还必须在进入时为过程的局部变量分配空间,并在退出时释放空间。大多数机器,包括我们一直讲的 IA32,只提供转移控制到过程和从过程中转移出控制这种简单指令。数据传递和局部变量的分配释放都是通过操纵程序栈来实现。
合理的构建方法并调用,能大大增加代码的复用性,也能使代码结构更加清晰,接下来我们就来详细的介绍。
1、栈帧结构
IA32 程序用程序栈来支持过程调用。机器用栈来传递过程参数、存储返回信息、保存寄存器用于以后恢复,以及本地存储。而为单个过程分配的那部分栈称为帧栈(stack frame)。
帧栈可以认为是程序栈的一段,它有两个端点,一个标识着起始地址,一个标识着结束地址,而这两个地址,则分别存储在固定的寄存器当中,即起始地址存在%ebp寄存器当中,结束地址存在%esp寄存器当中。也就是说寄存器 %ebp 为帧指针,寄存器 %esp 为栈指针。
当程序执行时,栈指针可以移动,因此大多数信息的访问都是相对于帧指针的。
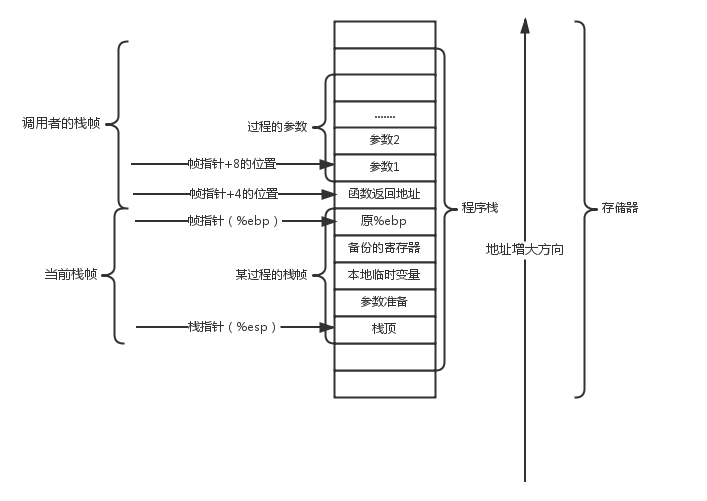
这个图基本上已经包括了程序栈的构成,它由一系列栈帧构成,这些栈帧每一个都对应一个过程,而且每一个帧指针+4的位置都存储着函数的返回地址,每一个帧指针指向的存储器位置当中都备份着调用者的帧指针。各位需要知道的是,每一个栈帧都建立在调用者的下方(也就是地址递减的方向),当被调用者执行完毕时,这一段栈帧会被释放。还有一点很重要的是,%ebp和%esp的值指示着栈帧的两端,而栈指针会在运行时移动,所以大部分时候,在访问存储器的时候会基于帧指针访问,因为在一直移动的栈指针无法根据偏移量准确的定位一个存储器位置。
还有一点比较重要的内容,就是栈帧当中内存的分配和释放。由于栈帧是向地址递减的方向延伸,因此如果我们将栈指针减去一定的值,就相当于给栈帧分配了一定空间的内存。这个理解起来很简单,因为在栈指针向下移动以后(也就是变小了),帧指针和栈指针中间的区域会变长,这就是给栈帧分配了更多的内存。相反,如果将栈指针加上一定的值,也就是向上移动,那么就相当于压缩了栈帧的长度,也就是说内存被释放了。需要注意的是,上面的一切内容,都基于一个前提,那就是帧指针在过程调用当中是不会移动的。
2、过程的实现
过程的实现主要就是在于数据如何在调用者和被调用者之间传递,以及在被调用者当中局部变量内存的分配以及释放。
而过程实现当中,参数传递以及局部变量内存的分配和释放都是通过以上介绍的栈帧来实现的,大部分情况下,我们认为过程调用当中做了以下几个操作。
①、备份原来的帧指针,调整当前的帧指针到栈指针的位置,这个过程就是我们经常看到的如下两句汇编代码做的事情。
pushl %ebp
movl %esp, %ebp②、建立起来的栈帧就是为被调用者准备的,当被调用者使用栈帧时,需要给临时变量分配预留内存,这一步一般是经过下面这样的汇编代码处理的。
subl $16,%esp③、备份被调用者保存的寄存器当中的值,如果有值的话,备份的方式就是压入栈顶。因此会采用如下的汇编代码处理。
pushl %ebx④、使用建立好的栈帧,比如读取和写入,一般使用mov,push以及pop指令等等。
⑤、恢复被调用者寄存器当中的值,这一过程其实是从栈帧中将备份的值再恢复到寄存器,不过此时这些值可能已经不在栈顶了。因此在恢复时,大多数会使用pop指令,但也并非一定如此。
⑥、释放被调用者的栈帧,释放就意味着将栈指针加大,而具体的做法一般是直接将栈指针指向帧指针,因此会采用类似下面的汇编代码处理(也可能是addl)。
movl %ebp,%esp⑦、恢复调用者的栈帧,恢复其实就是调整栈帧两端,使得当前栈帧的区域又回到了原始的位置。因为栈指针已经在第六步调整好了,因此此时只需要将备份的原帧指针弹出到%ebp即可。类似的汇编代码如下。
popl %ebp⑧、弹出返回地址,跳出当前过程,继续执行调用者的代码。此时会将栈顶的返回地址弹出到PC,然后程序将按照弹出的返回地址继续执行。这个过程一般使用ret指令完成。
过程的实现大概就是以上八个步骤组成的,不过这些步骤并不都是必须的(大部分时候,开启编译器的优化会优化掉很多步骤),而且第6和第7步有时会使用leave指令代替。下面会详细讲解这些步骤。
3、过程调用和返回指令
下图是支持过程调用和返回的指令:

①、call指令:call 指令有一个目标,即指明被调用过程起始的指令地址。直接调用的目标可以是一个标号,间接调用的目标是 * 后面跟一个操作符。它一共做两件事,第一件是将返回地址(也就是call指令执行时PC的值)压入栈顶,第二件是将程序跳转到当前调用的方法的起始地址。第一件事是为了为过程的返回做准备,而第二件事则是真正的指令跳转。
②、leave指令:它也是一共做两件事,第一件是将栈指针指向帧指针,第二件是弹出备份的原帧指针到%ebp。第一件事是为了释放当前栈帧,第二件事是为了恢复调用者的栈帧。
③、ret指令:它同样也是做两件事,第一件是将栈顶的返回地址弹出到PC,第二件事则是按照PC此时指示的指令地址继续执行程序。这两件事其实也可以认为是一件事,因为第二件事是系统自己保证的,系统总是按照PC的指令地址执行程序。
可以看出,除了call指令之外,leave和ret指令都与上面8个步骤有些不可分割的关系。call指令没有在8个步骤当中体现,是因为它发生在进入过程之前,因此在第1步发生的时候,call指令往往已经被执行了,并且已经为ret指令准备好了返回地址。
4、寄存器使用惯例
程序寄存器组是唯一能够被所有过程共享的资源。虽然在给定时刻只能有一个过程是活动的,但是我们必须保证当一个过程(调用者)调用另一个过程(被调用者)时,被调用者不会覆盖某个调用者稍后会使用的寄存器的值。为此必须采用一组统一的寄存器使用惯例,所有的过程都必须遵守,包括程序库的过程。
假如没有这些规矩,比如在调用一个过程时,无论是调用者还是被调用者,都可能更新寄存器的值。假设调用者在%edx中存了一个整数值100,而被调用者也使用这个寄存器,并更新成了1000,于是悲剧就发生了。当过程调用完毕返回后,调用者再使用%edx的时候,值已经从100变成了1000,这几乎必将导致程序会错误的执行下去。所以便有如下规矩:
在 IA32 中,寄存器%eax,%edx和%ecx被划分为调用者保存寄存器。当过程 P 调用 Q 时,Q可以覆盖这些寄存器,而不会破坏 P 所需的数据。
寄存器%ebx,%esi和%edi被划分为被调用者保存寄存器。这里 Q 必须在覆盖这些寄存器的值之前,先把他们保存到栈中,并在返回前恢复它们,因为 P(或某个更高层次的过程)可能会在今后的计算中需要这些值。上面所说的过程实现的8个步骤中第三步便是如此。
考虑如下代码:
int P(int x)
{
int y = x*x;
int z = Q(y);
return y+z;
}过程 P 在调用 Q 之前会先计算 y 的值,而且它必须保证 y 的值在 Q 返回后是可用的。这里有两种方法实现:
①、可以在调用 Q 之前,将 y 的值保存在自己的帧栈中;当 Q 返回时,过程 P 就可以从栈中取出y 的值。换句话说就是调用者 P 自己保存这个值。
②、可以将 y 保存在被调用者保存寄存器中。如果 Q ,或者其它 Q 调用的程序想使用这个寄存器,它必须将这个寄存器的值保存在帧栈中,并在返回前恢复该值。换句话说就是被调用者保存这个值。当 Q 返回到 P 时,y 的值会在被调用者保存寄存器中,或者是因为寄存器根本就没有改变,或者是因为它被保存并恢复了。
这两种方法在 IA32 中是都采用的。
5、过程实例
考虑如下代码 function.c
#include <stdio.h>int add(int a,int b){
register int c = a + b;
return c;
}
int main(){
int a = 100;
int b = 101;
int c = add(a,b);
return c;
}
相信上面的代码没有什么难度,在 main过程中调用 add过程。我们通过如下指令编译成汇编代码:
gcc -O0 -S function.c为了完整的展现那8个步骤,因此给变量c加了register关键字修饰,这将会将c送入寄存器,从而更改被调用者保存寄存器,就会导致步骤3的发生。以下是main函数以及add函数各自的栈帧情况:
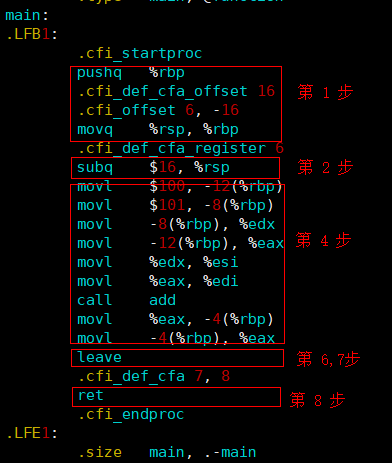
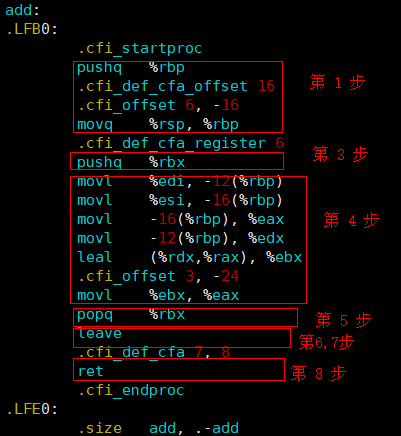
上面的汇编代码是我们没有使用优化级别编译出来的,所以完整的呈现了前面所讲的8个步骤。这里我们需要注意两点:
①、add函数会将返回结果存入%eax(前提是返回值可以使用整数来表示),在main函数中,call指令之后,默认将%eax作为返回结果来使用。
②、所有函数(包括main函数)都必须有第1步和第6、7、8步,这是必须的4步。我们的栈指针和帧指针有固定的大小关系,即栈指针永远小于等于帧指针,当二者相等时,当前栈帧被认为没有分配内存空间。
5、递归过程
前面我们讲的都是一个过程能调用其它的过程,但是其实一个过程也能调用自己本身的,也就是递归调用。因为每个调用在栈中都有它自己的私人空间,多个未完成调用的局部变量不会互相影响,此外,栈的原则也提供了适当的策略,当过程被调用时分布局部存储空间,当过程执行完毕返回时释放存储空间。
下面是一段求 n 的阶乘的递归调用代码:
int rfact(int n){
int result;
if(n<=1){
result = 1;
}else{
result = n * rfact(n-1);
}
return result;
}我们还是用 -O0 -S 来编译得到汇编代码:

上面的汇编代码,当用参数 n 来调用时,首先代码 25 行会创建一个帧栈,其中包含 %ebp 的旧值、保存的被调用者保存的寄存器 %ebx 的值,以及当递归调用自身的时候保存参数的四个字节。
如下图所示,它用寄存器 %ebx 来保存过程参数 n 的值(第 6 行代码)。它将寄存器 %ebx 中的返回值设置为 1,预期 n<=1 的情况,它就会跳转到完成代码。
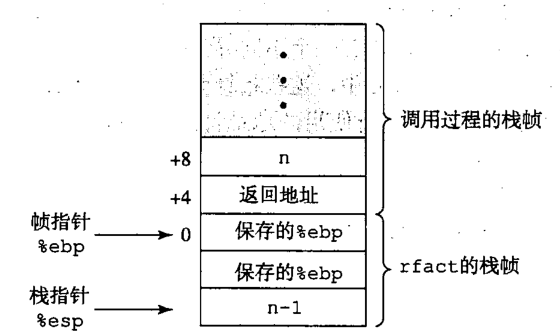
对于递归的情况,计算 n-1,将这个值存储在栈上,然后调用函数自身(第1012行),在代码的完成部分,我们可以假设:
①、寄存器%eax保存这(n-1)!的值
②、被调用保存寄存器%ebx保存着参数n
因此将这两个值相乘(第 13 行)得到该函数的返回值。对于终止条件和递归调用,代码都会继续到完成部分(第15~17行),恢复栈和被调用者保存寄存器,然后在返回。
所以我们看到递归调用一个函数本身与调用其它函数是一样的。栈规则提供了一种机制,每次函数调用都有它自己的私有状态信息(保存的返回值、栈指针和被调用者保存寄存器的值)存储。如果需要,它还可以提供局部变量的存储。分配和释放的栈规则很自然的就与函数调用——返回的顺序匹配。
6、总结
本章对于函数的汇编实现做了详细的讲解,主要是栈规则的机制,帮我们解决了数据如何在调用者和被调用者之间传递,以及在被调用者当中局部变量内存的分配以及释放。那么下篇博客我们将介绍数组的分配和访问,我们知道比如Java语言中的集合很多都是在数组的基础上实现的。弄懂下一章的内容后,你会对定长数组与不定长数组(集合)有更深刻的了解。