运算单元
基本信息
名称 | 参数 |
|---|---|
数据输入位宽 | bit |
权值输入位宽 | bit |
数据输出位宽 | bit |
功能 | 矩阵乘法、最大值池化、平均值池化 |
乘法器数量 | |
加法器数量 |
结构

strutrue.png
NFU的整体结构如上所示,该部分分为三个部分,分别是NFU-1、NFU-2和NFU-3三个部分,分别是乘法器阵列,加法或最大值树和非线性函数部分。NFU-1由一些乘法器阵列构成,如下图所示。一个单元具有一个输入数据

和

个输入权值,一个单元中共有

个乘法器,分别计算

的值,具有

个输出。
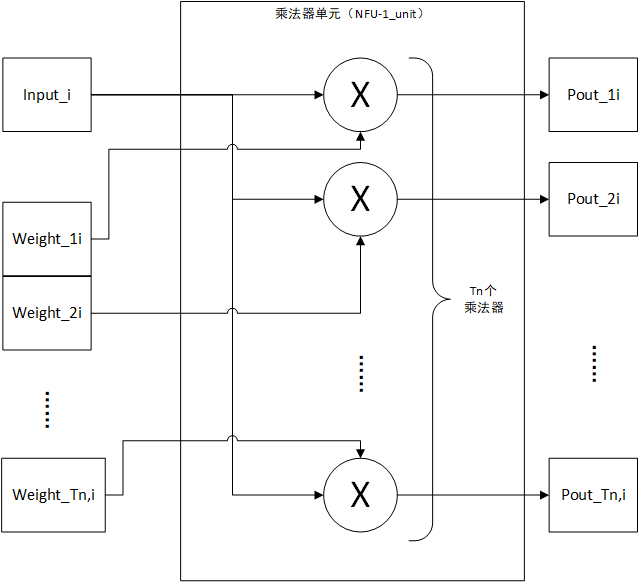
nfu1_unit.png

个输入数据和

输入权值经过NFU-1处理后,变为

个部分积,第i个乘法器单元的第j个输出为

。所有部分积经过route分配给

NFU-2单元,分配规则如下所示,第i个NFU-2单元的输入是所有NFU-1单元的第i个输出。

NFU-2单元为加法/平均值(加法树前添加位移单元)/最大值(加法树的加法器可配置为取最大值)树,用于计算

个输入的和/平均值或最大值,如下所示:

NFU-2单元的输出为一个数据,整个NFU-2部分输出为

个部分操作数据。该输出可以流向NFU-3部分作为NFU-2的输出,也可以流向D-Reg作为部分和临时保存以节约带宽。NFU-3为一个加法器和一个非线性单元。非线性单元使用分段线性逼近非线性函数,分段线性逼近参数保存在RAM中,可通过更改该参数使该单元实现任意非线性函数。
运算映射
矩阵乘法/卷积
映射以下矩阵乘法:

有以下配置:
- 数据输入:第i个NFU-1单元数据输入为

- 权值输入:第i个NFU-1单元的第j个权值输入为

,即第i个NFU-1单元输入的数据为W矩阵的第i列
- NFU-2:配置和实现加法树功能
池化
映射以下最大值操作:

有以下配置:
- 数据输入:第i个NFU-1单元数据输入为

- 权值输入:所有权值配置为1
- NFU-2:配置实现最大值树功能(若为求平均值,配置为平均值树)
对于x的维度小于

时,推测可以将权值部分设置为1部分设置为0作为掩码,同时计算多个最大值/平均值操作
系统结构
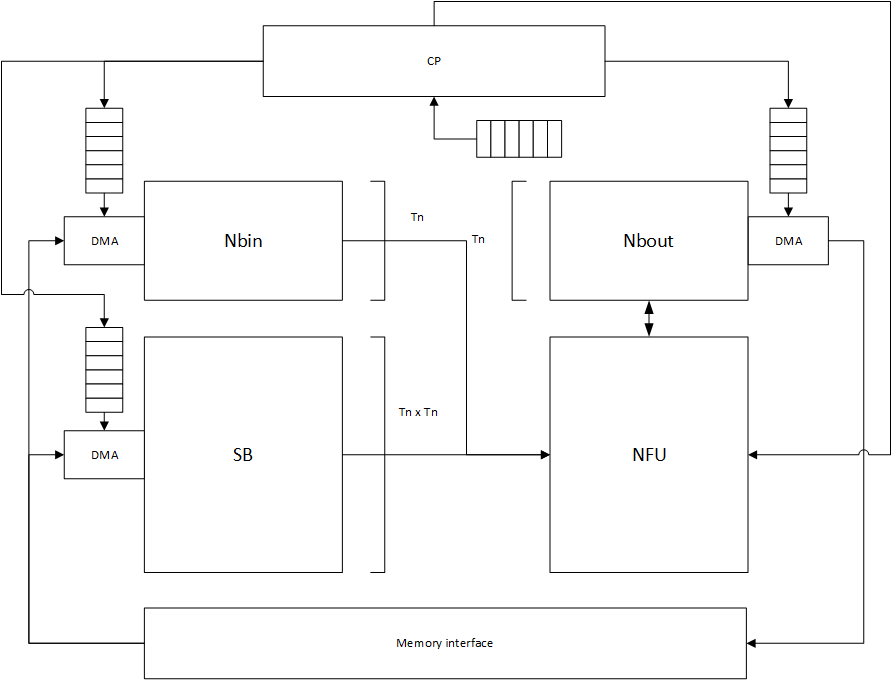
DianNao.png
系统结构如上所述,各部分:
- NFU:神经计算单元,已经加入compute_unit的pool中
- 分裂缓存:按功能分裂为三个的缓存,已经加入memory的pool中
- 控制模块CP:指令使控制,每个指令分为四个部分,分别是NBin指令,NBout指令,SB指令和NFU指令
系统使用指令控制,每条指令可以实现一次矩阵-向量乘法运算,每个指令的四个部分被解耦后发送给四个部分,因此存储器的load指令不需要等待NFU运算完成,对于三个缓存,执行完当前步骤后立刻执行下一个指令中对应部分的指令,可以实现数据的预取,但是考虑计算正确性,NFU必须等待运算所需要的数据预存完成后才能执行。
计算映射
对于一个矩阵乘法:

首先进行矩阵分块,参数矩阵W分块为

的矩阵,输入向量x分块为

,再进行计算,如下图所示:
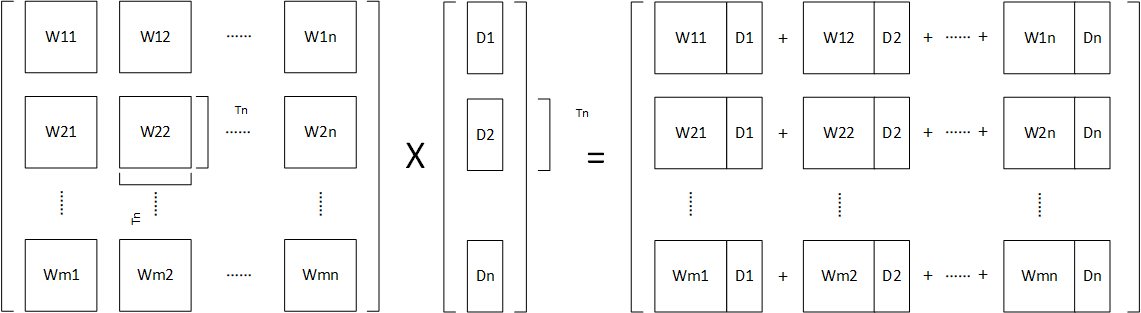
mul.png
分块后,原论文给出的加速器参数为

,计算需要的权值矩阵有

,数据向量有

,缓存载入的规则为:
- Nbin:数据向量分块为

块,每一块数据大小为2KB=

,每次载入一块。即每次载入的输入数据包括64个逻辑块。
- SB:每次载入32768B=

,即每次载入的数据包括64个逻辑块。
映射一个矩阵乘法,步骤为:
- Nbin载入前四个逻辑块D1,D2,~,D64。SB载入与前四个输入逻辑块运算相关的64个数据块W11、W12、W13~W64,1(分块后W的前4列,前16行的块)。NFU计算对应乘法(例如

,

,...,

),并将部分和存储在Nbout中
- Nbin载入第二块输入数据,包括D65~D128,SB继续载入与D1~D64运算相关的权值块W2,1~W2,64。NFU继续计算D1~D64对应乘法。直到将D1~D64相关的乘法计算完成以后,才进行D65~D128相关的乘法。
- ...
- 当某个输出的计算完成后,Nbout将其输出到外部缓存中
复用策略为仅复用输入,仅当这一块输入数据需要参与的所有运算完成后才开始进行下一块输入相关的计算。对于每一块输入映射过程如下图所示:
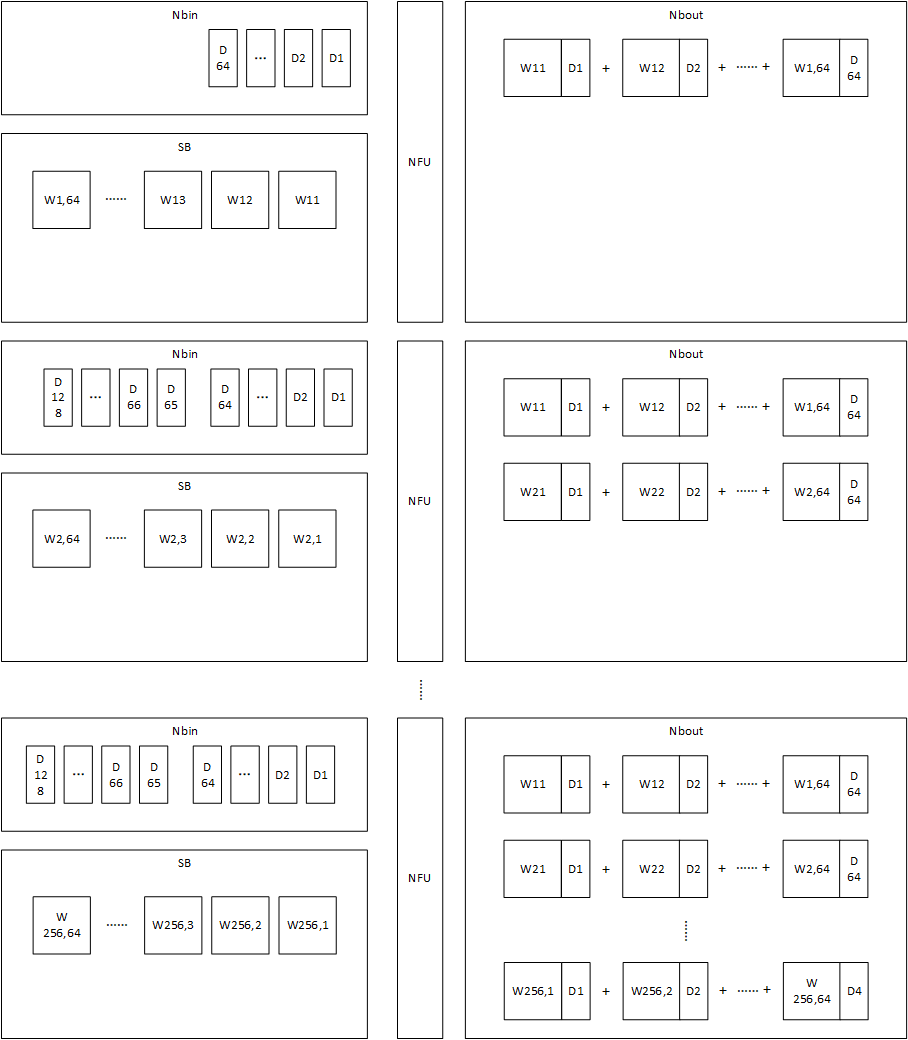
map.png