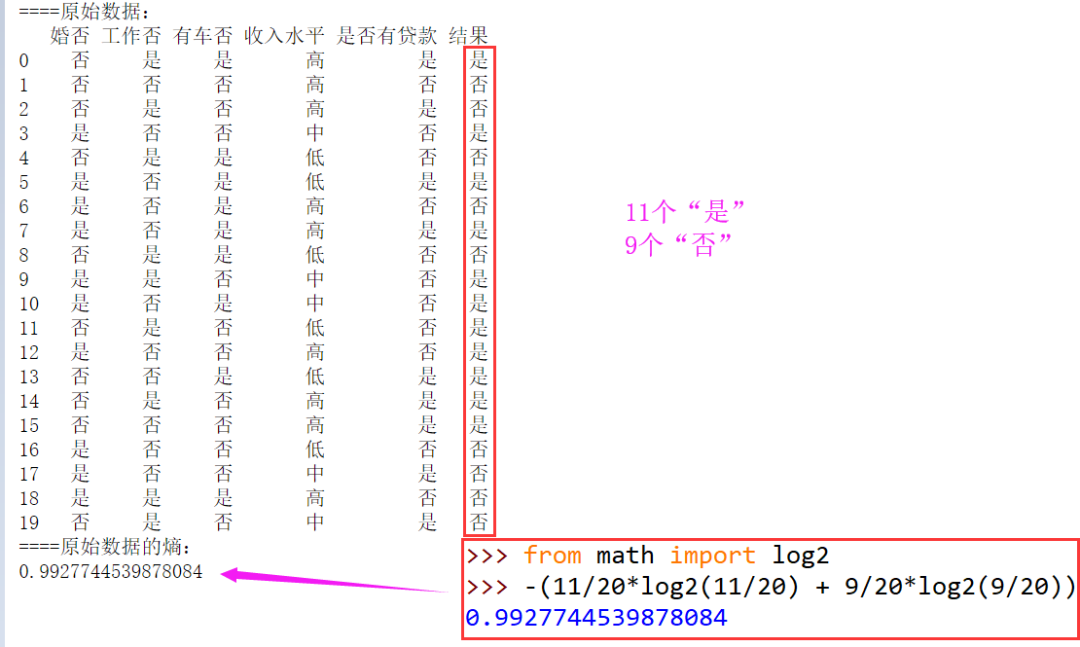
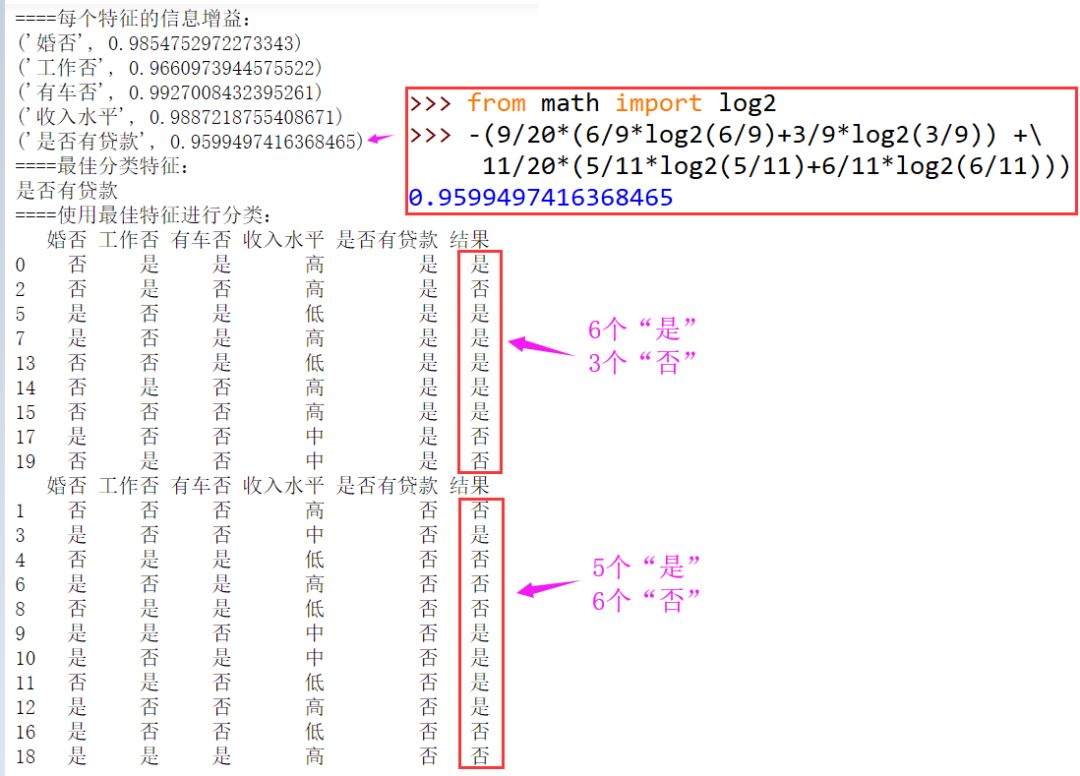
问题描述:
信息熵可以用来衡量事件不确定性的大小,熵越大表示不确定性越大。对于特定的随机变量,信息熵定义为每个事件的概率与概率的2-对数的乘积的相反数之和,即
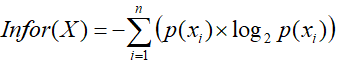
信息增益表示使用某个特征进行分类时不确定性减少的程度,在使用该特征进行分类后,每个子类中该特征的值都是固定的。信息增益的值为分类前信息熵与分类后每个子类的信息熵加权平均的差,即
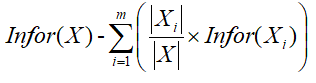
其中,Xi表示每个子类,|Xi|表示该子类中样本的数量。
如果根据某个特征的值对原始数据进行分类后,信息增益最大,那么该特征为最重要的特征。这种方法会有误差,如果某列特征的唯一值数量非常多,会得到很大的信息增益,可以使用信息增益率进行纠正,本文不考虑这个问题。
参考代码:

运行结果: