1. 视频分布式转码
网络流量分析机构Sandvine 2018年10月的《全球互联网现象报告》中显示,在全球整体的互联网下行流量中,视频占到了近58%。现在原始视频的分辨率越来越高,但是在互联网带宽有限的情况下,大部分视频提供商都需要将原始视频转码成多种清晰度的视频,便于用户在不同的网络环境中选择不同清晰度的视频进行观看。因此,视频转码成了必不可少的技术环节。
目前视频转码系统一般的架构形式如下图所示:

转码系统中各个角色的功能如下:
转码中心控制节点:负责调度和分发转码任务,原始视频切片和转码后视频合并等工作。
转码机: 从中心控制节点接收转码任务,完成转码工作,高CPU消耗。
存储系统:存储源视频供转码机机型下载,以及转码后的视频供用户下载。
而为了加快转码速度,多采用分片转码,具体流程如下图所示:

若从零开始搭建这套转码系统需要开发的服务器角色多、交互多、任务管理调度复杂。一般转码机都是高CPU消耗,这就需要提高硬件配置,而在没有转码任务时,系统中的服务器实际是处于空闲状态,这也是一种很大的资源浪费。
使用腾讯云的批量计算产品,只需要调用一个API-SubmitJob 就能自动完成上述复杂的调度和交互流程。并且批量计算只在提交转码任务时才创建腾讯云服务器,在转码任务完成后自动释放云服务器,做到按量按需使用,极大地节约资源。同时批量计算结合了腾讯云的竞价实例,更是能让云服务器使用成本减少90%以上。
本文将介绍一种使用腾讯云批量计算完成分布式转码的方法。
2. 使用腾讯云批量计算转码
2.1. 批量计算简介
腾讯云批量计算-Batch Compute,动态创建服务器资源以响应提交的作业,可以免除用户配置维护云服务器的工作,按需使用。同时批量计算利用自身的调度功能,能有效地处理作业内部任务之间的先后关系,免去复杂的调度逻辑,让使用者将更多的精力集中于数据的处理和分析上。
2.2. 批量计算与分布式转码
批量计算中有三个重要的概念:
作业:用户提交批处理工作的最小单位,它由单个或多个有前后依赖关系的任务组成。可以通过非常易用的 DAG 语法,来给多个批处理任务设置依赖关系,共同组成一个作业,然后依次执行各个任务,直到所有任务完成。
任务:作业的基本组成单位,包含了实际在一台云服务器上执行的应用程序的相关信息。
任务实例: 批量计算调度和执行的最小单元,负责执行具体的计算任务。
现在我们在分布式转码这个场景上,具化批量计算这三个重要的概念。
转码作业中包含三个任务:视频分片任务,视频转码任务和视频合并任务。
而视频转码任务中又包含多个分片视频转码的任务实例。
具体的对应关系如下图所示:
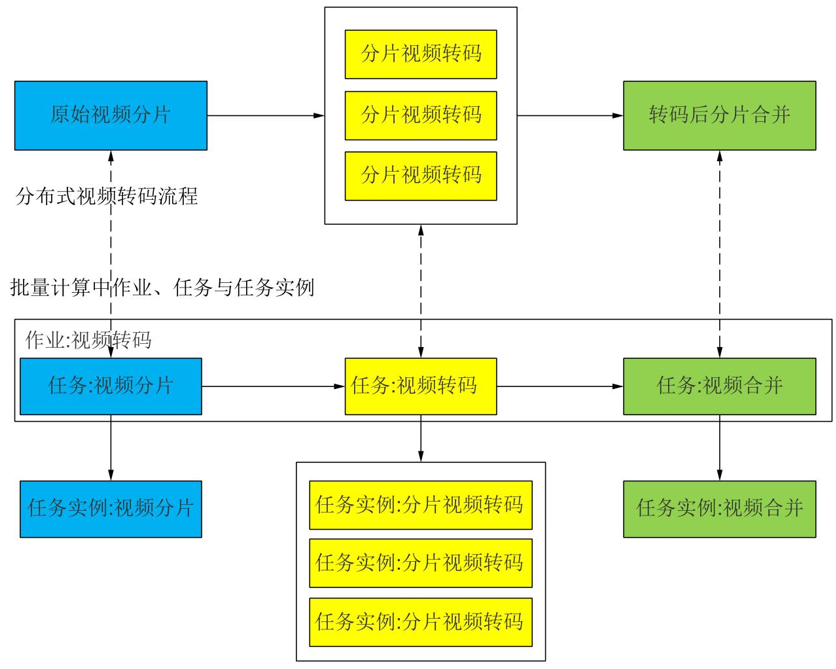
批量计算通过作业、任务和任务实例这种内在的逻辑关系,就可以帮助我们在视频分片结束后,多机器并行执行转码工作,当全部分片转码结束后,执行视频合并工作。这与传统转码系统相比,就少去了中心节点服务器与转码机之间复杂的交互和调度逻辑。
2.3. 批量计算与存储系统
批量计算提供的存储映射功能,可以将腾讯云对象存储 COS 或文件存储 CFS映射到云服务器的本地文件系统,这样转码程序就可以以操作本地文件系统的方式来读写远程存储。便于转码服务器下载源视频文件和上传转码后的视频文件。这与传统转码系统相比,只需要添加存储映射配置路径,省却了搭建存储服务器的工作。另外如果使用COS存储转码后的文件,则可以作为CDN的源站,使得视频分发工作更容易。
3. 批量计算进行转码示例
3.1. 整体架构

3.2. 视频文件存储目录结构
批量计算使用CFS或者COS来存储视频文件方式都是一样的,只是在作业中配置的存储映射地址不同而已。本示例,使用CFS存储。
下面我们来介绍视频存储目录结构:
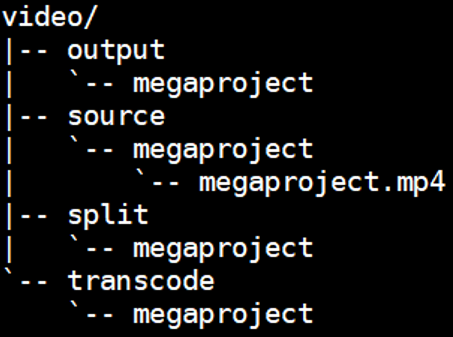
video/source:存放原始视频文件。
video/split:存放切片后的文件。
video/transcode:存放转码后的切片文件。
video/output:存放合并后的完整转码文件。
每个视频以视频名作为目录存放到上述各个目录中。
3.3. 转码方法介绍
转码工具使用音视频行业最常使用的ffmpeg。
3.3.1. 视频切片命令
ffmpeg -y -i /data/video/source/megaproject/megaproject.mp4 -acodec copy -vcodec copy -f segment -segment_time 120 -reset_timestamps 1 -segment_list /data/video/transcode/megaproject/filelist.txt -segment_list_type ffconcat -map 0:0 -map 0:1 /data/video/split/megaproject/%d.mp4主要参数介绍:
-f segment :按照关键帧进行视频切片,这样可以防止视频合并后有重叠的现象发生。
-segment_time 120 :按照每段视频120秒来切片。时间可以自行设置。
-reset_timestamps 1: 每个切片的视频时间戳从0开始。
-segment_list : 存放切片视频名的列表文件。
-segment_list_type ffconcat: 指定存放切片视频名列表文件的格式,ffconat表示可以使用ffmpeg conat 解复用器来使用的文件格式。
/data/video/split/megaproject/%d.mp4 :表示切片后视频命名路径和格式,%d表示从0开始一直到N-1,表示N个切片。
3.3.2. 分片后视频转码命令
ffmpeg -y -i /data/video/split/megaproject/${BATCH_TASK_INSTANCE_INDEX}.mp4 -vcodec libx264 -acodec aac -b:a 128k -strict -2 -s 640x480 /data/video/transcode/megaproject/${BATCH_TASK_INSTANCE_INDEX}.mp4主要参数介绍:
-vcodec libx264:视频编码格式。
-strict -2: aac :ffmpeg中aac音频为experimental,为了使用该格式,需要加上此参数。
-s 640x480: 转码后视频分辨率。
${BATCH_TASK_INSTANCE_INDEX}这个环境变量为批量计算任务实例的编号,与实例个数N相关。取值范围为[0, N-1],这正好对应ffmpeg分片出来的视频名称序号。
3.3.3. 视频合并命令
ffmpeg -y -f concat -i /data/video/transcode/megaproject/filelist.txt -c copy /data/video/output/megaproject/480P_megaproject.mp4主要参数介绍:
-f concat: 表示合并视频
-i /data/video/transcode/megaproject/filelist.txt:表示根据filelist.txt文件中的视频来合并。
-c copy: 表示对音视频流只进行简单复制。
3.4. 构造批量计算提交作业API
使用批量计算转码,只需要使用SubmitJob API,填入作业、任务、任务实例,云服务器和挂载存储映像的参数即可。
本次示例我们将一个720P时长50分钟的视频,转码为480P的视频为例,每个转码分片为2分钟,共25个分片。转码后视频编码为libx264,音频编码为aac。
下面介绍构建的SubmitJob API的主要参数:
全部参数可以参考API文档:https://cloud.tencent.com/document/product/599/15907
完整的API请求参数,请见附件submitjob.json。
3.4.1. 作业参数
创建一个Job:video-transcode
Job中包含为三个Task:split,transcode和join。
Task split:任务实例数TaskInstanceNum=1。
Task transcode:任务实例数TaskInstanceNum=N=25,N为视频分片的数量。
Task join:任务实例数TaskInstanceNum=1。
{
"Job": {
"JobName": "video-transcode",
"Tasks": [
{
"TaskName": "split",
"TaskInstanceNum": 1,
"Application": {
"Command": "/data/code/split.sh megaproject"
}
},
{
"TaskName": "transcode",
"TaskInstanceNum": 25,
"Application": {
"Command": "/data/code/transcode.sh megaproject"
}
},
{
"TaskName": "join",
"TaskInstanceNum": 1,
"Application": {
"Command": "/data/code/join.sh megaproject"
}
}
]
}
}其中Command为云服务器中执行的命令,split.sh,transcode.sh,join.sh中存放的内容对应于3.3节中介绍的使用ffmpeg进行视频切片,转码和合并的命令。
作业中任务执行顺序:

使用Dependences参数表示任务之间的关系
"Dependences": [ { "StartTask": "split", "EndTask": "transcode"}, { "StartTask": "transcode", "EndTask": "join" }
]
3.4.2. 云服务器参数
"ComputeEnv": {
"EnvData": {
"InstanceType": "S2.SMALL2",
"ImageId": "img-hmxop735",
}
}InstanceType:”S2.SMALL2” ,表示使用云服务器机型为1核CPU,2G内存。
ImageId: “img-hmxop735”,表示云服务器操作系统镜像,具体为centos7.4 预装了ffmpeg2.8.6的操作系统。
3.4.3. 存储映射路径参数
"InputMappings": [
{
"SourcePath": "cifs://10.10.10.10/8lzib3st/",
"DestinationPath": "/data/"
}
]SourcePath:cifs://10.10.10.10/8lzib3st/,表示CFS远端路径。
DestinationPath: /data/,表示本地挂载路径。
3.5. 转码结果
视频分片后多机并行转码,每个视频分片转码任务耗时3分钟左右。
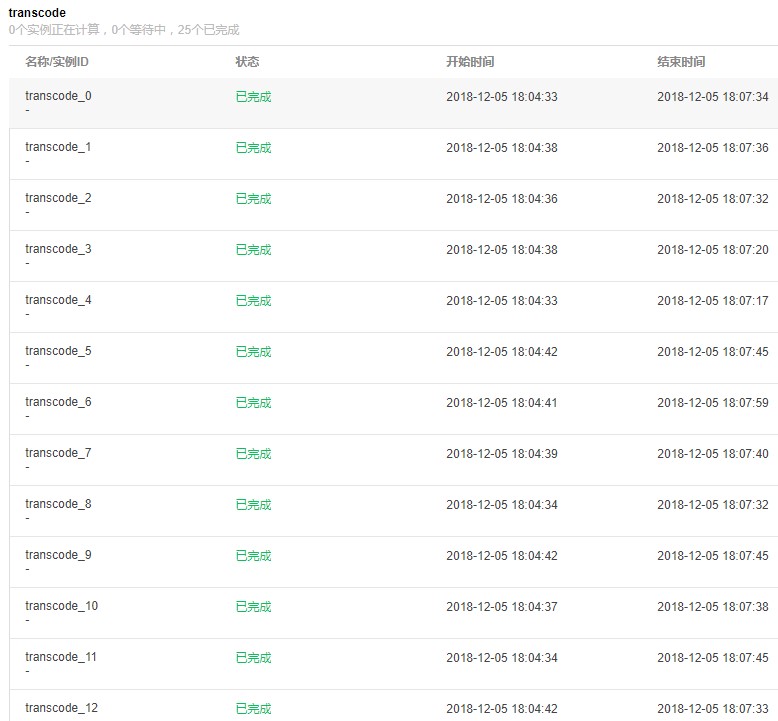
批量计算分布式转码整体耗时12分钟11秒

单机转码整体耗时32分钟23秒

4. 总结
根据上述对传统转码系统的分析和批量计算的介绍,我们对比一下两者在完成分布式转码功能上的差异。
对比点 | 传统转码系统 | 批量计算 |
|---|---|---|
服务器硬件数量 | 数量固定,空闲时资源浪费 | 动态扩缩容,按需使用与释放。 |
服务器硬件配置级别与使用 | 多转码任务共享,配置高,价格贵 | 转码任务独占,配置低,价格低,使用竞价实例云服务器,更是能减少90%以上成本。 |
转码任务调度 | 自行开发程序,中心节点和转码机交互逻辑多,调度复杂。 | 调用一个API,批量计算作业,内部自动支持任务先后顺序的调度。 |
文件存储 | 自行开发,业务逻辑复杂 | 无缝对接腾讯云COS或者CFS存储。 |
文件分发 | 转码文件需上传源站后,自行分发,对接CDN分发。 | 转码后文件自动上传腾讯云COS后,可无缝对接腾讯云CDN分发。 |
批量计算为分布式转码提供了一个新的解决方案,只需要一个API调用,即可省却开发复杂转码系统的工作。不仅能提高转码速度,还可以免去维护服务器资源和转码程序的工作。
5. 参考资料
1.《全球互联网现象报告》
https://www.sandvine.com/hubfs/downloads/phenomena/2018-phenomena-report.pdf
2.ffmpeg https://www.ffmpeg.org/ffmpeg.html
3.腾讯云批量计算 https://cloud.tencent.com/document/product/599
4.腾讯云云服务器 https://cloud.tencent.com/document/product/213