近日,由 VMware 联合Intel、PingCAP、EMQ、灵雀云等合作伙伴联合主办的大型开源活动——2021智能云边开源峰会(2021 Open Source AceCon)成功落下帷幕。作为开源技术生态的年度盛会,大会邀请了多位来自开源领域的技术领导者及重要贡献者,分享“云原生、边缘计算、人工智能”三大热门技术趋势及洞察。
灵雀云DevOps团队工程师张晨宇在云原生分论坛分享了《Harbor企业级落地实践》主题演讲,下面是演讲视频及实录。
想了解更多Harbor企业级实践干货,可添加小助手微信:alaudacloudnative,(备注:Harbor)拉您进入交流群。
视频回顾
演讲实录
大家好,我叫张晨宇,来自灵雀云,今天我给大家分享Harbor云原生制品仓库的企业级落地实践。
主要从以下6个部分来介绍:
- Harbor在企业内部承担的角色
- Harbor从1.x到2.x版本的演进过程
- 企业内部的Harbor治理维护规范
- Harbor和灵雀云ACP产品的融合
- 灵雀云对Harbor社区的开源贡献
- Harbor企业版
Harbor在企业内部承担的角色
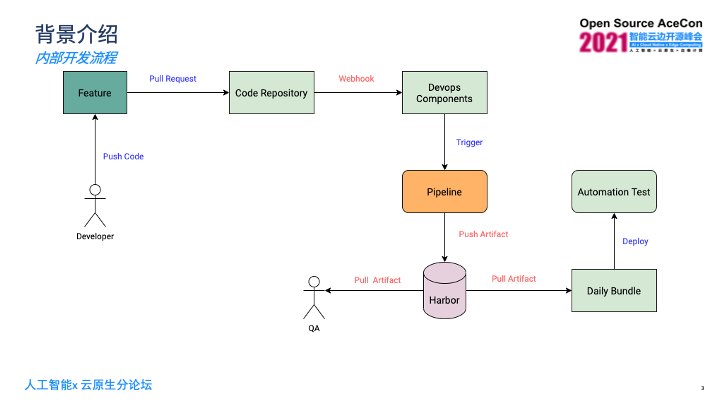
在企业内部的开发流程里,开发人员在开发某一个特性时,会将代码推送到自己的功能分支,然后这个分支需要给Master分支提一个Pull Request。之后通过代码仓库的事件机制,发送Webhook通知到企业内部的DevOps内部组件上,然后这些组件会负责去触发对应的流水线。在这个过程里,Harbor主要承担镜像仓库的角色。流水线里面会去构建镜像,之后会推送到Harbor上, Harbor上的镜像会有测试人员去拉取,还有一些自动化构建或者打包的脚本去从Harbor上拉取镜像,之后去做一些自动化的部署以及测试等。
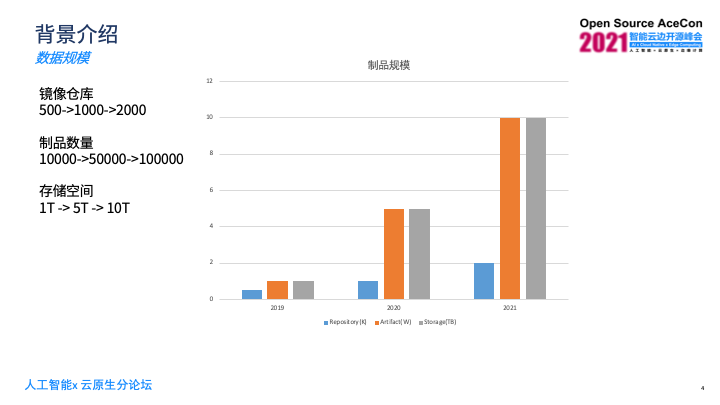
灵雀云从2019年之前就已经开始使用Harbor了,可以看一下近三年数据规模的变化,2019年我们的镜像仓库只有500个左右,到今年已经增长到超过2000个了;另外一块是对应的Harbor里面的制品数量,从最早的1万个,到今年已经超过了10万个;存储空间从最早的1T到今年已经超过10T的一个规模。
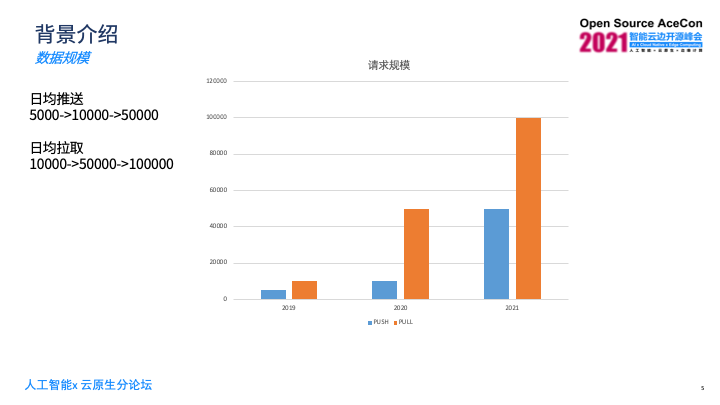
另一方面,是关于请求规模, 2019年每天的日均推送是1000次左右,到今年每天请求次数已经超过50000次了,日均拉取的数量提升更为明显,从最早的10000次,到今年每天拉取次数已经超过10万次。
Harbor从1.x到2.x版本的演进过程
首先看我们企业内部在使用Harbor1.x版本时遇到的问题。之前业务组件都是通过chart去部署,也有多架构镜像的需求,是需要提供两种架构:AMD和 ARM。Harbor1.x只能支持单架构的镜像,想实现多架构的需求,社区主要是通过给镜像tag加架构信息后缀的方式,这种方式有三个缺点,第一:需要维护两个架构版本的chart,第二:tag信息冗余,第三:有额外的tag维护成本。
后来我们采用另外一种方式,通过部署两套Harbor来维护两种架构的镜像,分别是 AMDHarbor和ARMHarbor。优点是业务chart只需要维护一套,接着通过指定registry拉取不同架构的镜像。另外非常显著的优点是tag比较统一,不需要专门维护镜像架构的后缀来作为标志信息。缺点是需要额外的Harbor维护成本。
Harbor发布2.0版本后,增加了对OCI制品的支持,可以通过同一个tag维护多个架构的镜像。我们将之前的流程做变化,直接使用Harbor2.x提供的多架构的能力,这个过程涉及到多架构镜像迁移,因为之前是部署了两套Harbor,又额外部署了Harbor2.x版本。
迁移主要分成两个步骤,第一通过将1.x版本里的单架构镜像push到2.x的Harbor上,过程中注意需要给对应的镜像加上对应架构后缀,如果分成两次push这个镜像,第二次的会覆盖第一次的,所以需要用不同后缀作为区分。
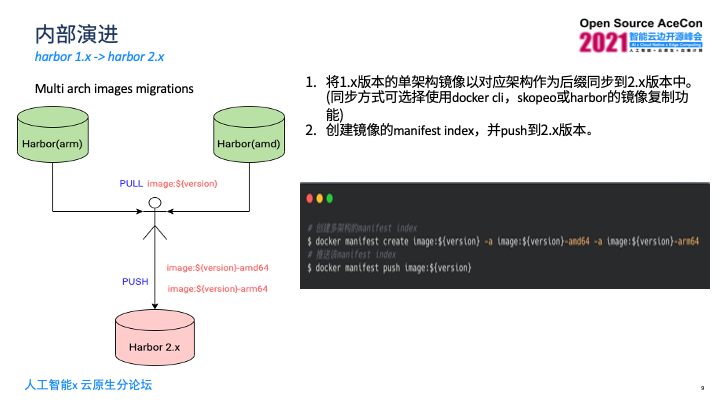
第二push完镜像后,需要手动创建镜像的manifests的index的文件,这是OCI对多架构的index的定义,需要手动创建,创建方式是docker提供了manifests的子命令来完成,只需要去指定镜像的tag信息,然后通过-a的方式来指定index里所包含的对应的不同架构的镜像tag信息,完成后,manifests文件是存在本地,要通过docker manifests push命令将这个index推送到Harbor上,这样就完成了迁移过程。
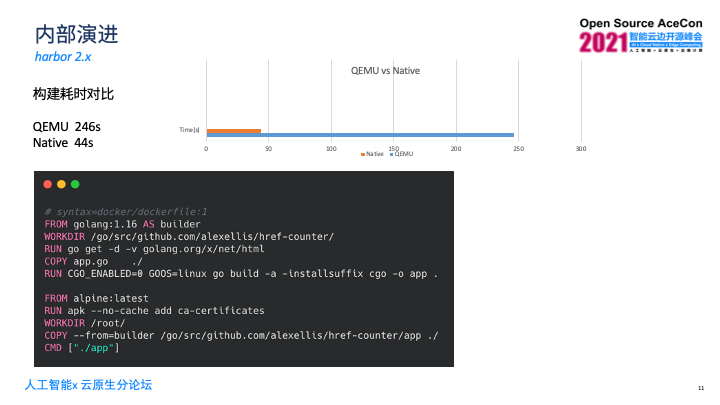
Harbor2.x版本上线后,能够存放多架构镜像,我们企业内部对流水线进行了改造。可通过Buildx构建多架构镜像,目前主要有两种方式,第一是QEMU,相当于在机器上安装QEMU,通过QEMU模拟其他架构环境,该方式配置简单方便,缺点是它的构建速度慢于原生架构的构建。
最后我们通过异构集群(buildx kubernetes driver)来实现。这是需要部署两个集群, AMD和ARM的集群,构建时会根据你所需构建的镜像架构信息调度到对应的不同节点上去构建,这相当于原生的构建,速度比较快。缺点是需要去部署异构集群,配置及维护成本略高。
选择异构集群方案前我们做了原生构建和QEMU构建的耗时对比,以docker官网的golang multistage,就是多阶段构建的dockerfile,在我们的环境上去构建做了比较,两者差距是原生构建速度明显快于QUME构建,差不多是五六倍之多。
企业内部的Harbor治理维护规范
镜像规模在不断地增长,就需要有一些治理和维护手段,因此我们有一套内部的命名规范。比如说开发阶段开发人员提开发分支的时候,如果是bug,以fix开头,如果是功能分区以feat开头。分支命名规范定下后,镜像tag是能够根据分支名来自动生成,我们会将分支名作为镜像tag的前缀,后面加上构建时的时间戳来作为后缀,这样做了比较好的区分。发版阶段的规范是会在固定的时间去冻结代码,之后会拉出release的分支,该分支跑流水线构建出来对应的tag就是正式的版本号。
规范的目的主要有两个,一是语义化信息,便于溯源,是能通过tag或者分支名知道该分支或镜像的作用,二是统一管理,便于统一的清理维护策略,比如说可以永久保留release相关的代码分支和制品,或者按需清理开发阶段相关的代码分支和制品。
清理规则是通过Harbor的Tag Retention实现镜像的清理。清理周期支持定时执行和立即执行。清理策略提供三个维度,一是匹配或者排除Repo,二是匹配或者排除某些tag,三是保留规则它有很多支持,比如说保留最近推送的#个,最近拉取的#个,最近#天被推送,最近#天被拉取,或是全部保留。
治理维护中最重要的部分是垃圾清理,看垃圾清理之前,先看镜像的结构,首先是有index,它会对应不同架构的manifests文件,里面包含两部分,一是image config,二是这个镜像层信息。我们清理了tag,为什么还需要GC?主要是docker镜像的设计机制,是让这些镜像层能够共享。

如图有两个镜像,镜像a和镜像b,镜像a是依赖层a和层b,镜像b是依赖层a和层c,发现镜像a和镜像b共享了层a,尝试删除镜像b后发现,只是镜像b的manifest文件被删除,它的Layer没有被删除,那么Layer(c)就成为了孤儿层,如果它不被清除会长久占用存储空间,执行GC时发现层c就被清理掉了,它的时间过程是类似编程语言里的标记清除,会去扫描所有的Layer,把其中被引用到的layer去标记下来,然后把没有被用到的Layer做清除操作。
Harbor和灵雀云ACP产品的融合
Harbor和灵雀云ACP产品做了深度融合,提供了开箱即用的部署体验,用户只需要去配置简单的基本信息就可以将Harbor快速部署起来,后续还可持续观察Harbor的健康状态,然后去更新Harbor的配置,达到更新Harbor的目的。
在租户绑定分配方面,能够将Harbor上的项目或是指定的镜像仓库分配给平台对应的项目,绑定后,可查看绑定信息以及对应镜像仓库的信息。另外一方面提供了全局绑定分配的策略,免去手动分配的烦恼,提供了两个维度的绑定策略,一是同名项目自动绑定,会在Harbor上去创建同名的项目,实现自动绑定,后续推送到Harbor上对应项目下的镜像都会自动地绑定到平台的项目下。二是公共镜像仓库,考虑到有些镜像是所有团队共享,将library的镜像设为公共仓库来共享给所有项目使用。还有镜像清理和保护策略,可以定义一些清理策略和保护策略,达到治理Harbor的目的。
灵雀云对Harbor社区的开源贡献
因为在使用Harbor中遇到一些问题,有新的需求,所以我们和社区成立了一个多架构的工作组。之前Harbor社区只提供了标准的x86架构的组件镜像,对于其他架构的环境,比如ARM没办法部署Harbor。Harbor的Issues里也有很多其它架构镜像的支持,所以我们召集了一些对其它架构有兴趣或是有经验的公司一起去做多架构的镜像。目标是能用比较统一的方式去持续地构建多架构的Harbor镜像,比如说构建ARM和龙芯的镜像等。
目前该工作组已有两个仓库,一个是HarborARM,主要用来交互ARM架构的镜像,已经到收尾的阶段,预计在Harbor2.4版本,就提供ARM的镜像。另外一个仓库是龙芯架构,它对上层有更强的依赖,当前还在开发中的阶段。如果对其它架构有经验或有兴趣的朋友,可以加入到这个workgroup中,一起讨论问题或需求等。
Multi Architecture WorkGroup(多架构工作组):https://github.com/goharbor/community/tree/master/workgroups/wg-multiarch
成果:
- https://github.com/goharbor/harbor-arm (ARM架构)
- https://github.com/goharbor/harbor-loongson (国产化龙芯架构)
Slack:# harbor-multi-arch-workgroup
另外是性能方面,我们和社区一起成立了性能工作组,因为harbor包括我们在使用的过程中,在大的数据规模下或者是并发较多的情况下会存在性能的问题,之前官方也没有相关的性能测试工具和性能测试报告,所以需要在该领域有专注解决性能的Issues或者是做性能的优化领域的贡献者。性能工作组的目标是能够提高harbor在大数据集或是高并发规模下的稳定性和性能,还有建设统一的性能测试工具,能够在Harbor每次release发版的时,提供标准的性能测试报告等。
目前性能测试工作的进展是,我们提供了性能测试工具集,在对应的go harbor performance仓库下,主要有三个功能,功能一:准备测试数据,比如全新部署的Harbor,可以去moke数据来跑性能测试,功能二:执行并发测试,可以配置不同的并发数,不同的规模等。功能三:跑完并发测试后,自动生成测试报告,比如说在Harbor2.3版本,我们用该工具跑了一份标准的性能测试报告,放在perfomance的wiki里。另外一方面是性能提升,解决性能问题后,我们内部做过测试,在并发数300,制品数为10万的情况下,Harbor2.3,小于2.3以及2.3版本做了一个对比,比如说Catalog提升了3倍左右,Projects提升了4倍左右,Artifacts的速度提升了15倍,Tags提升了4倍,审计日志提升了10倍左右。

Performance WorkGroup(性能工作组):
https://github.com/goharbor/community/tree/master/workgroups/wg-performance
成果:
- 性能测试工具集: https://github.com/goharbor/perf
- harbor2.3性能测试报告: https://github.com/goharbor/perf/wiki/Harbor-2.3.0-Performance-Test-Reports
性能问题修复:
- https://github.com/goharbor/harbor/issues/14819 https://github.com/goharbor/harbor/issues/14815
- https://github.com/goharbor/harbor/issues/14814
- https://github.com/goharbor/harbor/issues/14813
- https://github.com/goharbor/harbor/issues/14716
Harbor企业版
近年来,灵雀云已服务了数百家来自政府、金融、能源、制造、地产、交通等领域的头部客户,为其中超过100家客户部署了Harbor开源版,同时提供了高质量的运维服务,获得了客户的高度评价。灵雀云愿意基于自身丰富的Harbor运维经验帮助更多Harbor企业客户解决后顾之忧,让客户获得稳定、可靠、性能优异的制品库产品使用体验。因此我们推出了Harbor企业版(Alauda Registry Service for Harbor)。
企业版服务内容:
- Harbor云原生制品仓库的高可用解决方案; a) 企业级高可用解决方案; b) 基于Kubernetes Operator的高可用解决方案;
- Harbor云原生制品仓库的版本升级、漏洞修复;
- Harbor云原生制品仓库运行环境的运维支持服务,包括:镜像复制迁移、故障恢复、环境部署等;
- DevOps工具链解决方案。