背景
最近在了解国外Firebolt这家公司,对于Firebolt 最初的架构选型和思路是非常认可的。Firebolt 这篇 Paper 核心围绕着这样一个主题:在云数仓领域,对于一家初创公司,如何在人力和资源有限的情况下,怎么能够快速的切入这个这个市场?虽然 FireBolt 本身就有很多技术大牛(比如 Mosha Pasumansky),但是针对数据库所有组件(查询优化器、计算引擎、存储、事务管理器等等)完全从零做,对于初创公司而言,根本不现实。
未来在数据库领域,对于一个 DataBase 的研发,可能就是使用已有的数据库中各模块的标准事实开源组件,快速组装出一个 DB,同时将相对有限的工程资源,尽可能多的投入到差产品异化功能上,这样才能和其他同类产品有竞争优势,形成独特性。对于一个 DataBase 各模块组装选型:比如 SQL 方言标准(Mysql / PG)、SQL Planner 层( Apache Calcite / DuckDB )、Planner 层和 Runtime 层计划序列化通信方式(substrait)、Runtime 层使用( Apache Arrow + Rust Or ClickHouse)、数据湖存储(Iceberg / Hudi / Deltalake)、列存(Parquet Or ORC) 。下面我来解读下 Firebolt 这篇 Paper,以及谈谈我的个人想法。
前言
Firebolt 是一个云数据仓库,旨在支持面向用户的数据密集型应用场景。用户期望查询在几十毫秒内返回,这对于 Firebolt而言,非常有挑战。此外,面向用户的应用程序可以同时拥有数千个用户(并发)和查询,具体表现在查询(QPS)以及高并发性。
构建一个数据库系统是非常有挑战的,因为它包含了很多复杂的组件,比如:查询引擎、存储引擎、事务管理器和系统元数据 catalog 等等,尤其在构建云数仓方面,这些挑战还会被放大,因为云数仓不仅仅包含上面的这些组件,同时还包含了云平台、云存储管理、SaaS 等组件。下图一展示了 FireBolt 的架构设计:
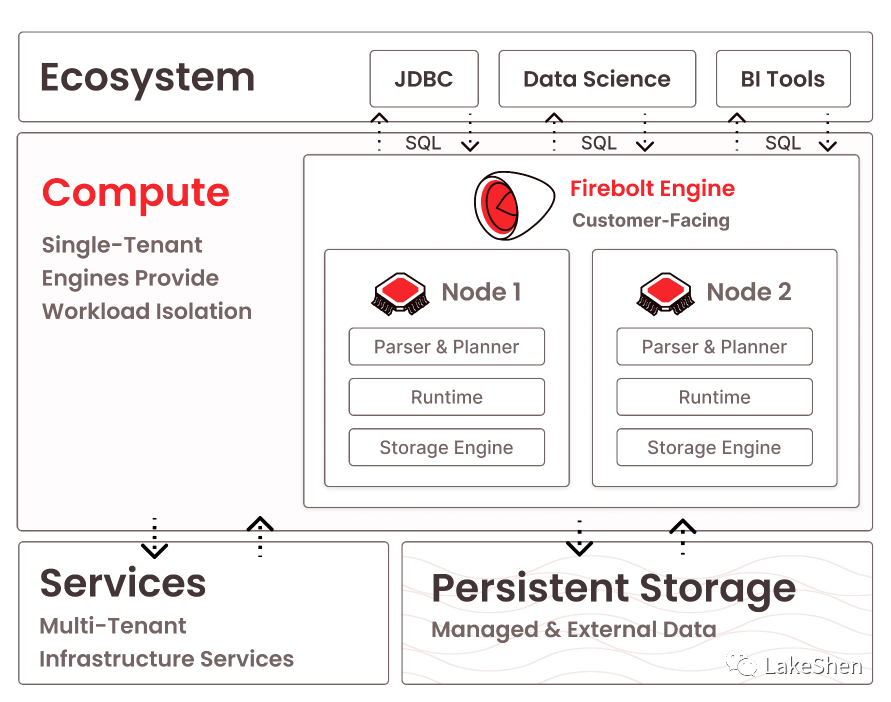
上述说到的组件,对于云数仓构建都是必须的,除此之外,企业还需要投入大量资源,来构建产品的差异化特性。
即使对于非常大的团队来说,从头开始构建上述这样一个系统,都可能都需要几年时间。在 FireBolt,其能够在18个月内构建出能够生产级 Ready 云数据仓库。Firebolt 从多个现有的开源组件来构建自己的云数仓,有些组件可能只要小的改动,就能投入使用。
这篇 Paper 主要讲解了 FireBolt 利用现有开源组件,构建一个云数仓的经验和思考,有些思考和我最开始遇到的一些问题是相似的,这里将这篇文章一起翻译讲解,大家一起学习进步。
一、查询引擎
这一章主要讲解 FireBolt 基于现有开源组件,来构建查询引擎的选型思考。主要包括:SQL 方言标准、SQL 解析器和 Planner、计算引擎、存储引擎。
Firebolt SQL 解析器在接收到用户的 SQL 查询后,会将其转换一棵抽象语法树。然后 Logical Planner 会将 AST 转换为逻辑查询计划(LQP),这个过程需要使用到逻辑层的元数据:Table 和 View 的元数据、数据类型、Function Catalog 等等。之后会使用 Transformation Rule(逻辑优化规则),产出一棵优化后的逻辑计划 Tree。
之后,Firebolt Physical Planner 会将 LQP 转换为分布式的执行计划(DQP)。这个过程需要用到物理层的元数据信息,包括:Table 的索引、Table 的基数、数据分布等等。之后会将分布式执行计划,下发到 Firebolt 节点集群执行。这个过程中也包括:计划调度、Stage 之间的数据分发等等,最终计算返回结果。
1.1 SQL 方言选型
云数仓并不是独立存在的,它是整个数据生态的一部分。这个生态包括:ETL/ELT 工具、BI 软件、数据科学、机器学习、数据可观测性等等,比如 Fivetran、Dbt、Tableau、Looker、Monte-Carlo 这些产品。当用户在这些工具上构建自己的应用程序时,FireBolt 和这些产品的生态进行集成,是非常关键的一点,没有人会使用一个没有生态系统集成的云数仓(不可能用了你这个产品,其他产品都用不了)。
幸好上述产品都使用 SQL 与数仓进行交互,这很大程度上简化了与这些生态集成的难度。当然问题还在,尽管 ANSI SQL 已经是 SQL 语言标准,但是现在每个数据库都有自己的 SQL 方言。结果就是,上述工具需要使用各种自定义的驱动、连接器、适配器,来支持不同的数据库系统。
云数仓想要成功,从一开始就需要思考和上述工具的生态系统集成。Firebolt 作为一家初创公司,肯定不能指望上面这些产品的公司花费一定时间和资源专门来适配 Firebolt。
所以 Firebolt 一开始想的就是傍一个已经存在的,且被广泛使用的 SQL 方言,这样能够简化与上述生态系统工具的集成,最终选择了Postgres SQL 方言(PG 国外非常火)。几乎所有的数据栈相关工具,都支持 Postgres SQL。当然,与 Postgres 的 SQL 方言兼容,并不意味着要和 Postgres Wire 通信协议兼容,Firebolt Driver 基于自定义的 HTTP REST 协议来和 Server 端进行通信。
1.2 SQL Parser 和 Planner选型
上一节 Firebolt SQL 方言标准选择了兼容 Postgres SQL 标准,那就意味着 DDL、DML、DCL 、DQL(Select 语句)的行为需要和 Postgres SQL 一致。
在 Firebolt Planner 的选型上面,准备使用现有的开源项目来满足需求。Planner 不仅需要支持云数仓相关很多优化规则,比如谓词下推、关联子查询消除等等,同样对于优化规则,能够支持自定义扩展等。除了需要支持基于优化规则之外,Planner 还需要支持 Cost-based 的 Join Reorder 的优化。所以这还包括需要自定义统计信息和 Cost Model。考虑到 Firebolt 支持不同类型的索引类型,这一点尤其重要。比如 Firebolt 可以使用稀疏索引和二级索引,也能够使用 Broadcast Join 场景下的特定索引。
最后,Planner 需要支持复合数据类型,比如 Arrays 数据和 Row(Struct)类型。这些数据类型在数据密集型应用中,使用的非常广泛。
SQL 解析和优化器可以选择不同的项目来进行构建,但是需要在 SQL 解析器和 Planner 之间,需要复杂的接口将两者链接起来(也就是 AST 转换完成后,进入 Planner 之前的过程)。所以 Firebolt 选型时会优先考虑同时包含 SQL Parser 和 Planner 的开源项目。接下来对这些项目进行介绍。
- Postgres Parser
- 初衷:考虑到 Firebolt 的 SQL 语法和 Postgres 兼容 ,所以直接选择 Postgres 的解析器是显而易见的。这种方法已经其他项目中得到使用,libpg_query 这个开源项目已经将 Postgres 的解析器剥离出来,它是一个基于 C语言的 Postgres 解析器库。
- 不足:虽然直接使用 Postgress SQL Parser 库,在 SQL 解析方面几乎不需要投入成本,但在 Planer 这一侧还需要投入大量的研发才能达到生产可用。libpg_query 仅仅只是一个 PG SQL Parser 库。
- ZetaSQL
- 初衷: ZetaSQL 是谷歌基于 C++ Based 一个 SQL 解析和分析项目。它是 GoogleSQL 开源的一个项目,GoogleSQL 主要由谷 BigQuery、Spanner、Dataflow、Dremel、F1、Procella 来共同提供支持。
- 不足:ZetaSQL 提供的 SQL 方言和基本特性与 Postgres SQL 有很多不一致的点,同时 ZetaSQL 只支持基本的优化规则,没有功能完备的 SQL Planner。
- Apache Calcite
- 初衷:Apache Calcite 是一个查询解析、优化的数据处理框架。它内部包括多种 SQL 方言的解析器,同时它的优化规则、以及Planner 可以自定义扩展,同时也被大量其他开源项目使用,比如 Flink、Hive、Storm、Druid。
- 不足:由于 Firebolt RunTime 是 C++ 开发的,而 Calcite 是 Java 开发,他们认为在 Planner 层和 Runtime 这一层还有很多工作要做,如果两个模块开发语言不同,会增加开发人员上下文切换成本,同种语言编写,几乎没有切换成本。
- DuckDB
- 初衷:DuckDB 源于 CWI(荷兰数学和计算机科学研究学会),它是一个在进程中内存分析型数据库。它被广泛测试并广泛用于交互式数据分析。DuckDB的查询优化器支持基于规则的优化和基于成本的 Join Reorder 优化。DuckDB 使用 libpg_query 项目作为解析器的,这样提供 PostgresSQL 兼容性。如今,DuckDB 将其解析器移植到 C++
- 不足:在那时 FireBolt 选型的时候,DuckDB 整体还不成熟(所以时机也很重要啊)。今天来看,DuckDB 非常成熟且非常流行。
- Hyrise
- 初衷:Hyrise 是 HPI 开发的内存数据库,它的代码整体相对简洁,所以整体比较容易重构和扩展,它整体于 DuckDB 类似,也支持基于规则的优化和基于成本的 Join Reorder 优化。
- 不足:Hyrise 是一个学术性项目,也没有经过生产级验证,也没有广泛的 SQL 覆盖度。
FireBolt 从一开始就决定,在 SQL Planner 和 Runtime 使用相同语言进行开发。当然,这也不是硬性要求,有很多成功的项目,其 SQL Planner 使用 Java 编写,Runtime 使用的是 C++ 编写(比如 Apache Doris)。但作为一家初创公司来说,Planner 和 Runtime 使用相同语言开发,能提升开发效率。在数据库系统中,有很多工作发生在 Planer 和 Runtime 的交叉点,这点在 Firebolt 尤为明显,因为 Firebolt 的 Planner 和 Runtime 来源于两个不同开源组件。使用相同的编程语言来开发 Planner 和 Runtime,使得开发人员尽可能减少这种语言切换带来的技术栈的切换成本。当 Filebolt 决定用 C++ 开发 Runtime时,Planner 只能选择 Hyrise 或 DuckDB。
由于 Hyrise 项目的简洁性和可扩展性,Firebolt 决定在 Hyrise 上面构建 SQL Planner。现在来看,虽然 Firebolt 已经达到生产级 Ready ,但事实证明 Hyrise 本质也只是一个学术系统。对于今天需要构建数据库的同学来说,使用 DuckDB 可能是一个更好的选择。自从Firebolt 研发构建以来,DuckDB 已经非常成熟,并且现在也被广泛使用。不过在当时那个时间点来看,选型 Hyrise 的确是一个更好的选择。今天 Firebolt 在 Planner 方面的很多设计,都借鉴的 Apache Calcite 这个项目
1.3 Runtime 选型
如果说 SQL Planner 是查询引擎的大脑,那么 Runtime 就是查询引擎的心脏。RunTime 负责 SQL 查询的计算以及存储。
与 SQL Parser 和 Planner 类似,Firebolt 可以选择从头开始构建一个新的查询引擎,也可以基于现有的开源项目来进行构建。许多数据库公司都是从头构建一个 Runtime,比如:CockroachDB、Databricks、Snowflake 等等。Firebolt 认为,作为一家初创公司,要想快速切入到云数仓这个领域,最好从现有的项目开始,将相对有限的工程资源投入到 Firebolt 独特的差异化功能上面去。
为了应对用户的数据密集型应用查询,Firebolt 需要一个低延迟的高性能查询引擎,构建现代高性能引擎有两种方法:向量化计算和代码生成技术。Firebolt 决定使用向量化计算。虽然代码生成可以构建高性能引擎,但是需要对高级编译技术投入巨大人力,同时增加了引擎的复杂度,对于新的开发者,入门门槛较高。
对于 Runtime 而言,还需要考虑引擎的健壮性,同时需要能够支持分布式执行。虽然已经有很多学术性和实验性的开源项目,但很多项目都没有得到生产级的验证,或者不支持分布式执行。对于构建高性能查询引擎,存储引擎必须是列存的。
由于存储引擎和计算引擎的关系就像 SQL Parser 和 Planner 一样,两者如果分离,也需要共享大量复杂的接口,所以如果计算引擎和存储引擎在一个项目中,这样能够极大简化构建高性能引擎的成本。最终 Firebolt 选择了 ClickHouse 作为其查询引擎。ClickHouse Runtime 是向量化计算,同时其有自己的列存文件存储格式(Merge Tree), ClickHouse 也经过大量的生产级验证。所以在 ClickHouse 上面构建 Firebolt,可以加快 Firebolt 构建速度。
1.4 Planner 和 Runtime 通信
SQL Planner 产出最优的物理计划后,然后会将物理计划转换为可分布式计算的执行计划,生成 Plan Fragment,然后通过 Scheduler 调度下发到 Worker 集群计算。所以 Planner 层和 Runtime 之间也存在通信,需要将计划下发到 Worker 执行。
Firebolt 中每个 Node 即能够作为 SQL 进行解析、 Plan 的 Coordinator,同时也能够作为计算节点。当 Query 进入到 Firebolt 集群时,它将被路由到集群的一个节点,然后该节点会作为 Coordinator,对用户的 Query 进行解析和优化。由于 Firebolt 是基于 Clickhouse 来进行实现的,最终需要将物理计划转换为 Clickhouse 能够识别的一种表示。可以将 Planner 优化后的物理计划,转换为 ClickHouse SQL方言,这样ClickHouse 能够将 SQL 方言转换为可以直接执行的计划。Firebolt 最开始就是这么做的,因为这样实现相对比较简单,可以快速构建引擎的初始版本,Firebolt 将这个过程称为:backtranslate 的过程。
一开始 Firebolt 将其优化后的计划,转换为 Clickhouse SQL 方言,虽然能够快速让产品 Work,但是这种方式也存在很多问题。本身从物理计划转成 ClickHouse SQL 方言, ClickHouse 端还需要对其进行 SQL 解析和元数据验证,这个过程不仅需要消耗一部分时间,更为致命的是,从物理计划转换到 SQL 方言,原本计划有很多优化信息,都已经丢失了。所以现在 Firebolt 会直接将优化后的物理计划,直接转换为 ClickHouse 的分布式执行计划,对于 Planner 和 Runtime 之间的计划通信方式,Firebolt 基于 Protobuf 的自定义的序列化方式来进行通信,Worker 端接收到序列化后的计算逻辑,然后使用向量化的 Operator 算子来进行计算。未来,Subswait 可能会成为 SQL Planner 和 Runtime 之间序列化通信的标准事实。
1.5 分布式执行
ClickHouse 的分布式查询计算,在某些场景下非常高效。比如:单表分析、低基数下的聚合、broadcast join 等等。另一方面,Clickhouse 在数仓方面的 SQL 语义支持较少,比如多表 Join、高基数下的聚合、没有 Partition By 的窗口函数、分布式排序等等。
ClickHouse 中的分布式查询处理对于某些形状的查询非常有效。例如,选择率高的表扫描的查询、按字段分组的低基数分布式聚合以及Broad Join。同时,ClickHouse 不支持数据仓库中常见的许多重要 SQL 优化,例如两个大型表之间的连接分析、具有高基数分组字段的聚合、没有粒度 partition by 子句的窗口函数以及数据量大的分布式排序等等。所以对于 ClickHouse 的分布式计算栈,Firebolt 决定进行重构和扩展,这样能够支持更多的数据密集型场景。比如支持两个超大表的 Join、高基数下的聚合等等。
二、测试系统
构建好的软件不仅仅只是代码研发,同时还需要确保软件能够正确运行,对于数据库系统,这一点尤为重要。用户将数据存到你的数据库中,依靠你们的引擎,计算出正确的查询结果。虽然在引擎内部,Firebolt 投入了很大的人力在引擎单测用例构建上,相对于真实业务场景,开发侧仅仅只能构建和验证其中一部分 case。在 Firebolt 中,对于引擎的测试体系和框架投入了巨大人力,可能从任何地方获取测试用例,实现最大的测试覆盖范围。
2.1 FireBolt 查询验证框架
大多数 SQL 查询测试框架都遵循类似的模式——它们基于一个或者多个数据文件,来构建测试数据流。首先,SQL DDL 可以定义表的 Schema,然后 SQL DML 能够修改表的数据。最后,通过 SQL 查询语句,根据预定义的预期结果和实际运行结果进行比较和验证。Firebolt 内部构建了一个名为PeaceKeeper 的定制测试框架,以遵循类似的模式。PeaceKeeper 能够在不同环境中,来构建 Firebolt 集群。这样就可以允许开发人员在个人电脑、云上快速构建 FireBolt 集群,进行定位和开发。PeaceKeeper 使用带有输入查询和预期结果的测试文件。Firebolt已经实现了2K+Firebolt特定的SQL查询测试用例。
2.2 Clickhouse 功能性测试
由于 Firebolt 的 Runtime 是基于 ClickHouse,所以可以很自然的使用 ClickHouse 内部 3 W+ 的单测。不过由于 ClickHouse SQL 方言和 Firebolt SQL 方言有很大不同,所以并不是所有的 ClickHouse 单测都能够应用到 Firebolt。所以对于部分不能够使用 ClickHouse 的单测,Firebolt 中进行弃用。
2.3 Postgres SQL 回归测试
Firebolt 的 SQL 方言以 Posgres SQL 为标准,所以重用 Postgres 已有测试组件是有必要的。Postgres 已有测试组件中包含12K+测试用例。对于这些测试用例中,对于 Firebolt 不支持的测试用例,我们能够通过测试组件立马发现和定位。
2.4 ZetaSQL 语义兼容性测试
ZetaSQL 本身有 60K+ 测试用例。ZetaSQL 语义兼容性测试的独特之处在于:很大一部分测试用例集中于 SQL 表达式和单个函数,广泛涵盖了不同的边界条件——这是许多其他测试套件不能提供的。
2.5 SQL 逻辑正确性测试
逻辑正确性SQL 测试的天花板,是 SQLLite 的 SQLLogicTest 框架。它包含超过 7M 个测试查询(即700万!)。Firebolt 编写了一个脚本,将 SQLLogicTests 移植到内部 PeaceKeeper 格式,进行测试。DuckDB 也采用了类似的方法。
三、经验教训
最后总结一下 Firebolt 的经验教训:
选择成熟且经得起生产验证的项目来构建数据库。目前来看,Planner 可以选择 Apache Calcite 或者 DuckDB 来进行构建。
最好使用单一语言来构建系统。用单一编程语言来开发数据库可以提升开发效率,这在项目初期尤为明显,因为开发人员可能需要频繁地在不同组件之间切换,或者在整个堆栈中构建功能。
尽可能选择少的项目来进行数据库构建。当 Planner 和 Runtime 是不同系统时,工程团队需要大量投资在这些组件之间构建简洁清晰的交互接口。当 SQL Parser 和 Planner,或者计算引擎和存储引擎在不同的系统时,也是类似的情况。因此,Firebolt 建议尽可能选择少的项目来构建数据库。未来可以考虑基于 Apache Arrow 来构建数据库。
尽早构建引擎的测试系统,同时尽可能多的与可用测试框架进行集成。虽然在初期需要投入大量的人力来构建,但从长远来看,它带来的收益是值得的。它能够帮助研发团队快速发现 SQL 方言中的潜在兼容性问题以及正确性问题,这些边界问题在实际的单测中很难发现。
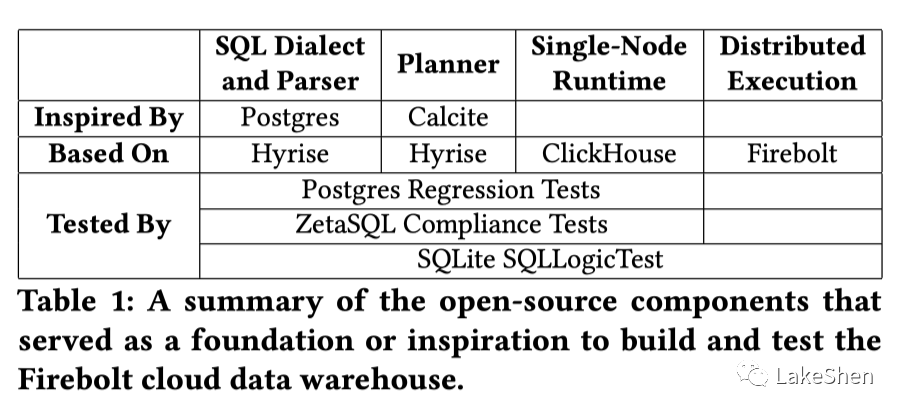
下图是 Firebolt 使用到的开源组件: