背景
案例一、
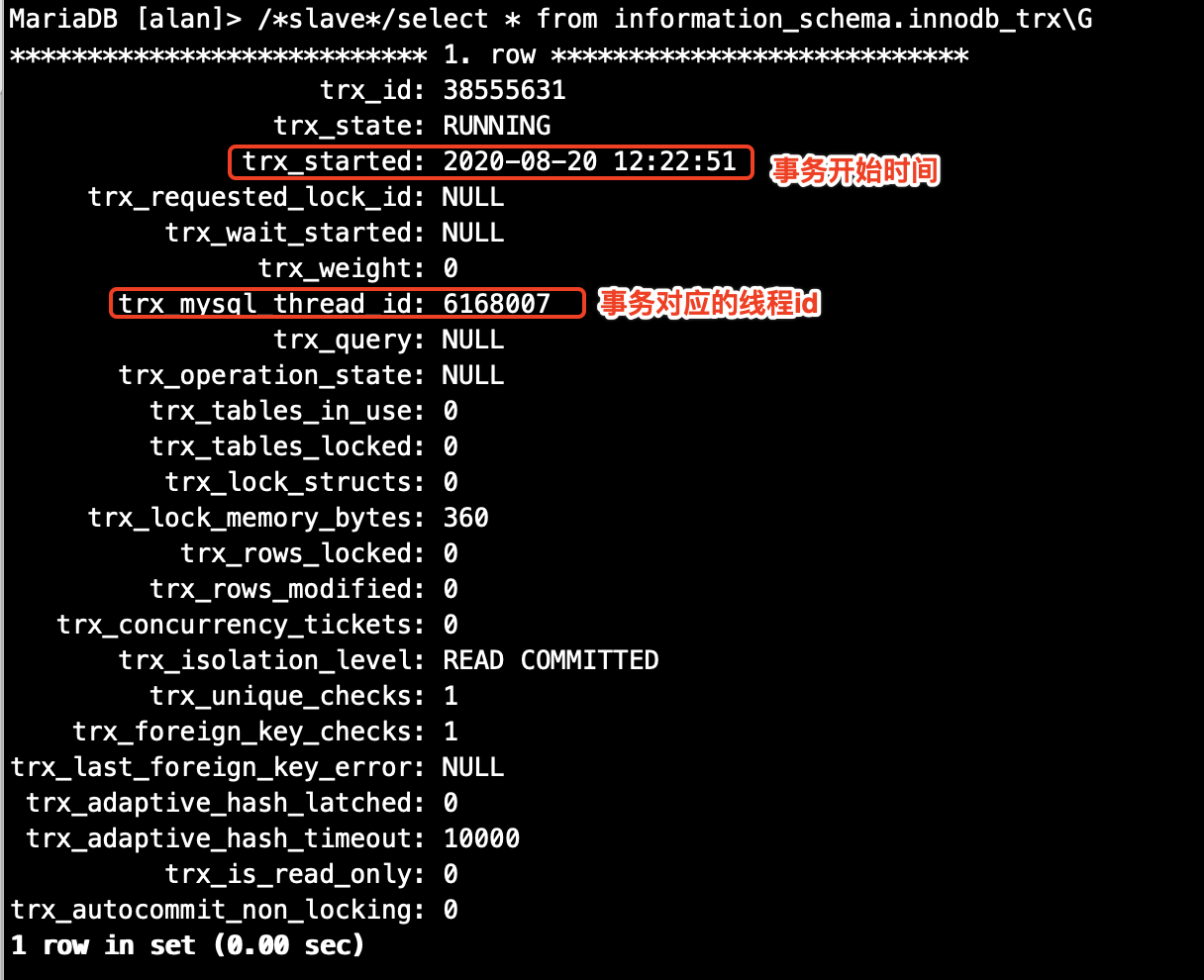
某用户A反馈CDB实例读业务数据库没有响应,在控制台界面看到ro节点被剔除,剔除之前数据库监控上面cpu负载正常,活跃线程数出现大量的堆积;提单后,平台紧急介入,观察到ro节点出现大量的waiting for table metadata lock的报错。
案例二、
某用户B反馈TDSQL实例部分读账户无法正常访问从节点了;提单后,观察到主从之间的延迟甚至达到了3000s,tdsql为保证从节点读到数据和主节点数据一致性,拒绝从节点继续服务。同时通过观察,发现从节点上面出现大量的waiting for table metadata lock的报错。
分析
对于mysql族的数据库,出现waiting for table metadata lock的报错,我们都可以套用一套经典的故障场景,即
session1 | session2 | session3 | |
|---|---|---|---|
T1 | A表相关大事务 | ||
T2 | 申请A表原子写锁操作线程处于waiting metadata lock | ||
T3 | A表相关查询线程处于waiting metadata lock |
表格1
通过这个图我们观察到,要出现该报错,需要具备的条件 (1)、首先实例特定表上面存在未提交的大事务 (2)、其次实例该表接受到获取原子写锁的操作,常见的包括FTWRL和ddl操作(包括drop、truncate、alter、rename等等修改表结构的操作) (3)、最后,我们需要在该表上面进行任意的dml操作
检查故障时间点的会话情况,我们确实都看到了相对应的线程,可以确认由于实例踩中了这个场景,导致实例出现会话线程飙升。
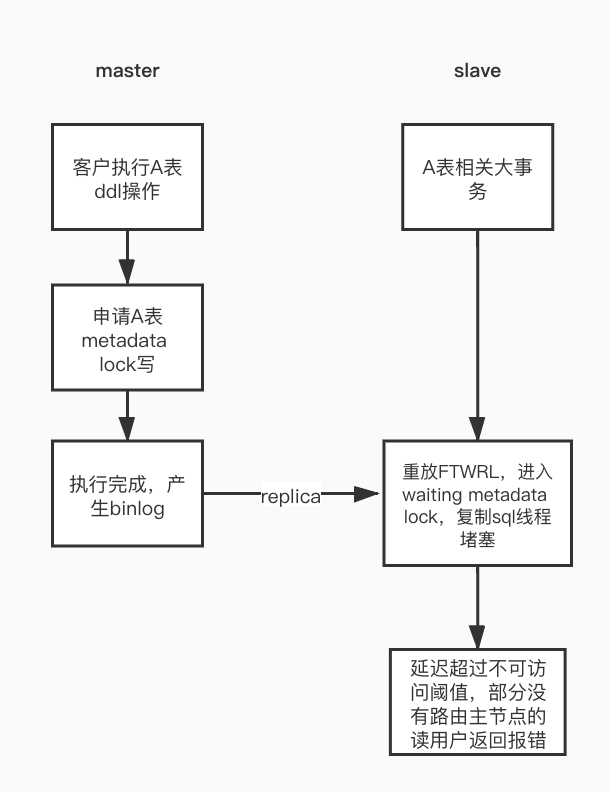
回到文章前面的问题本身: 对于案例一、我们了解到用户在故障之前启用了dts订阅,然而dts订阅会有获取binlog位点的操作,该操作需要执行flush table with read lock,也即是FTWRL操作。该操作会有mdl申请写锁的步骤,在主节点上面,dts订阅会检查主节点上面是否存在该表的未提交大事务(也就是(1)中的条件),保证ddl语句能够正常进行,但是该操作随着mysql复制到达ro节点上面进行重放,重放过程中,不巧碰到ro节点上面存在该表的大事务,后续业务和该表相关的dml语句也都hang住,同时由于flush table with read lock没有能正常执行完成,复制的sql线程hang住,延迟增加到剔除阈值,导致ro节点被剔除。整个流程如图1。

对于案例二、我们在用户从节点的线程中观察到存在执行时间超过8ws的大事务,同时也观察到存在alter该表的语句,可以确定也踩中了该场景,经过确认,用户之前在主节点进行了alter操作,该操作跟随mariadb复制传送到从节点,从节点上面存在该表的大事务长期占用mdl读锁,导致sql线程无法正常进行。主从延迟超过10s后,系统拒绝从节点继续提供服务,部分无法访问从节点就报错的业务返回错误,所幸另外一部分设置为从节点访问报错继续访问主节点的业务还能勉强为业务提供服务。整个流程如图2。
拓展
我们上面聊到,只要满足表格1中的情况,就会导致出现原子表锁等待,继而导致大量的线程产生。那么在TDSQL和cdb实际的情况是怎样的呢。这里先介绍一个参数:lock_wait_timeout
lock_wait_timeoutCommand-Line Format --lock-wait-timeout=#
System Variable lock_wait_timeout
Scope Global, Session
Dynamic Yes
Type Integer
Default Value 31536000
Minimum Value 1
Maximum Value 31536000This variable specifies the timeout in seconds for attempts to acquire metadata locks. The permissible values range from 1 to 31536000 (1 year). The default is 31536000.
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html
根据官档的定义,该参数决定了等待元数据锁超时的时间。默认值为31536000,也就是一年。在TDSQL当中,该值默认值被设为5s,对于主节点上面,如果产生表格1中的场景,申请元数据锁的操作将会在等待5s即抛出超时异常同时释放原子写锁,保证其它的线程能够正常运行。如下
mysql> alter table a force;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction那为什么在我们这篇文档的开头仍然出现了该情况呢?
这是由于我们的大事务在从节目持有原子读锁,而申请原子写锁的事物,是在relay log当中,重放过程中并没有受到这个参数的影响。导致从节点其它事物出现大量的原子读锁等待,复制线程也被hang住。
而cdb的lock_wait_timeout默认值沿用了mysql的缺省值,为一年,不过在这个案例里面也出现在了从节点。理论上在主节点也会出现该种场景。
那么为什么需要元数据锁呢?
设想一个场景:
session1 | session2 | |
|---|---|---|
T1 | mysql> begin; | |
T2 | mysql> begin; | |
T3 | mysql> commit; |
表格2
我们知道,在存在元数据锁的情况下,session 2在session 1提交之前,一直会处于hang住的状态。假设不存在元数据锁了,这两个事务得到了正常的提交。那么会产生一个现象,在binlog当中的,insert的操作被记录到了drop操作之后,sql执行序列发生了改变。当然,对于实例本身,这里不会产生影响。
但是如果使用全量数据+binlog增量数据作为备份呢?这里在回档过程中,明显会出现增量binlog无法重放的现象。导致了我们备份数据无效的数据安全场景。不仅仅是备份,在使用mysql复制作为从节点的方案里面,这里也会直接导致主从复制出现中断。因此,mysql在 5.5.3版本之后引入了元数据锁来保证数据备份的可靠性。
除开mysql表的元数据锁,也引进了schemas, stored programs (procedures, functions, triggers, scheduled events), tablespaces 相关的元数据锁。
参考文档
Metadata Lock Release
To ensure transaction serializability, the server must not permit one session to perform a data definition language (DDL) statement on a table that is used in an uncompleted explicitly or implicitly started transaction in another session. The server achieves this by acquiring metadata locks on tables used within a transaction and deferring release of those locks until the transaction ends. A metadata lock on a table prevents changes to the table's structure. This locking approach has the implication that a table that is being used by a transaction within one session cannot be used in DDL statements by other sessions until the transaction ends.
https://dev.mysql.com/doc/refman/5.7/en/metadata-locking.html
规避
1、数据库变更(ddl)需要放在业务低谷,保证对业务的影响最低
2、ddl变更之前除了需要观察主节点是否存在未提交的大事务外,还需要关注从节点是否存在未提交的大事务,如果存在大事务,可以先将大事务kill掉。如图3。