
题图:by cfunk44 from Instagram
在使用 Ajax 技术加载数据的网站中, JavaScript 发起的 HTTP 请求通常需要带上参数,而且参数的值都是经过加密的。如果我们想利用网站的 REST API 来爬取数据,就必须知道其使用的加密方式。破解过程需要抓包,阅读并分析网站的 js 代码。这整个过程可能会花费一天甚至更长的时间。
问:那么是否有办法绕过这机制,直接获取网站数据? 答:有的。使用 Selenium 库模拟浏览器行为来抓取网站数据,达到事半功倍的效果。
本文内容是利用 Selenium 爬取网易云音乐中的歌曲 《Five Hundred Miles》 的所有评论,然后存储到 Mongo 数据库。
0 前期准备
本文中所用到的工具比较多,所以我将其列举出来。
- Selenium
Selenium 是一个 Web 应用程序自动化测试的工具。它能够模拟浏览器进行网页加载。所以使用其来帮助我们解决 JavaScript 渲染问题。
接下来就是安装 selenium, 使用 pip 安装是最方便的。
pip install selenium- Chrome 浏览器
在爬取数据过程中, 需要启动浏览器来显示页面。因此,电脑中需要一款浏览器。这里推荐使用 Chrome 浏览器。推荐使用 59 版本以上的 Chrome,当然能使用最新版本那最好不过,目前最新版本是 68。
- Webdriver
Webdriver 是浏览器驱动。selenium 通过 Webdriver 来操作浏览器。因为我们使用的浏览器是 Chrome,所以需要下载 Chrome 浏览器对应的驱动。
下载地址:http://chromedriver.chromium.org/downloads
webdriver 下载解压完成之后,将其放到 Python 目录下的 Script 文件夹中。

点击查看大图
- MongoDB
网易云音乐的评论数据总数都很大,十几万条数据比比皆是,甚至还有上百万条数据。所以需要将数据存储到数据库中,我选用的是 MongoDB。
- pymongo
pymongo 是 Python 操作 MongoDB 的库。同样使用 pip 进行安装。
pip install pymongo1 爬取思路
1)使用 Selenium 驱动 Chrome 浏览器打开需要爬取的页面。 2)获取页面中 最新评论 标签后面的评论总数,计算出一共有多少个分页, 方便统计。利用总评论数除以 20(每个页面显示 20 条评论),然后对结果进行向上取整。 3)爬取第一页面的评论的数据,然后存储到数据库中。 4)利用 Selenium 模拟点击下一页按钮,再继续爬取该页面的评论数据,并存储到数据库中。 5)一直循环点击,直到所有分页的数据都被爬取完成。
2 代码实现
我们要爬取的歌曲是 《Five Hundred Miles》,先找到其 url 地址,然后调用爬取函数。
if __name__ == '__main__':
url = 'http://music.163.com/#/song?id=27759600' # Five Hundred Miles
start_spider(url)使用 selenium 启动 Chrome 浏览器。
from selenium import webdriver
def start_spider(url):
""" 启动 Chrome 浏览器访问页面 """
"""
# 从 Chrome 59 版本, 支持 Headless 模式(无界面模式), 即不会弹出浏览器
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
brower = webdriver.Chrome(chrome_options=chrome_options)
"""
brower = webdriver.Chrome()
brower.get(url)
# 等待 5 秒, 让评论数据加载完成
time.sleep(5)
# 页面嵌套一层 iframe, 必须切换到 iframe, 才能定位的到 iframe 里面的元素
iframe = brower.find_element_by_class_name('g-iframe')
brower.switch_to.frame(iframe)
# 获取【最新评论】总数
new_comments = brower.find_elements(By.XPATH, "//h3[@class='u-hd4']")[1]
根据评论总数计算出总分页数。
# start_spider(url)
max_page = get_max_page(new_comments.text)
def get_max_page(new_comments):
""" 根据评论总数, 计算出总分页数 """
print('=== ' + new_comments + ' ===')
max_page = new_comments.split('(')[1].split(')')[0]
# 每页显示 20 条最新评论
offset = 20
max_page = ceil(int(max_page) / offset)
print('一共有', max_page, '个分页')
return max_page
接着循环抓取评论数据,首先抓取第 1 页的评论数据。
# start_spider(url)
current = 1
is_first = True
while current <= max_page:
print('正在爬取第', current, '页的数据')
if current == 1:
is_first = True
else:
is_first = False
data_list = get_comments(is_first, brower)def get_comments(is_first, brower):
""" 获取评论数据 """
items = brower.find_elements(By.XPATH, "//div[@class='cmmts j-flag']/div[@class='itm']")
# 首页的数据中包含 15 条精彩评论, 20 条最新评论, 只保留最新评论
if is_first:
items = items[15: len(items)]data_list = [] data = {} for each in items: # 用户 id userId = each.find_elements_by_xpath("./div[@class='head']/a")[0] userId = userId.get_attribute('href').split('=')[1] # 用户昵称 nickname = each.find_elements_by_xpath("./div[@class='cntwrap']/div[1]/div[1]/a")[0] nickname = nickname.text # 评论内容 content = each.find_elements_by_xpath("./div[@class='cntwrap']/div[1]/div[1]")[0] content = content.text.split(':')[1] # 中文冒号 # 点赞数 like = each.find_elements_by_xpath("./div[@class='cntwrap']/div[@class='rp']/a[1]")[0] like = like.text if like: like = like.strip().split('(')[1].split(')')[0] else: like = '0' # 头像地址 avatar = each.find_elements_by_xpath("./div[@class='head']/a/img")[0] avatar = avatar.get_attribute('src') data['userId'] = userId data['nickname'] = nickname data['content'] = content data['like'] = like data['avatar'] = avatar print(data) data_list.append(data) data = {} return data_list</code></pre></div></div><p>将第 1 页评论数据存储到 Mongo 数据库中。</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0"># start_spider(url)save_data_to_mongo(data_list)
def save_data_to_mongo(data_list):
""" 一次性插入 20 条评论。
插入效率高, 降低数据丢失风险
"""
collection = db_manager[MONGO_COLLECTION]
try:
if collection.insert_many(data_list):
print('成功插入', len(data_list), '条数据')
except Exception:
print('插入数据出现异常')
模拟点击“下一页”按钮。
# start_spider(url)
time.sleep(1)
go_nextpage(brower)模拟人为浏览
time.sleep(random.randint(8, 12))
current += 1
def go_nextpage(brower):
""" 模拟人为操作, 点击【下一页】 """
next_button = brower.find_elements(By.XPATH, "//div[@class='m-cmmt']/div[3]/div[1]/a")[-1]
if next_button.text == '下一页':
next_button.click()
最后就一直循环爬取评论。
3 爬取结果
评论总数大概有 23W 条, 我又在代码中增加延时操作。所以爬取所有评论大概需要 69 个小时。目前我只跑了 9 个小时,我贴下暂时爬取的结果。
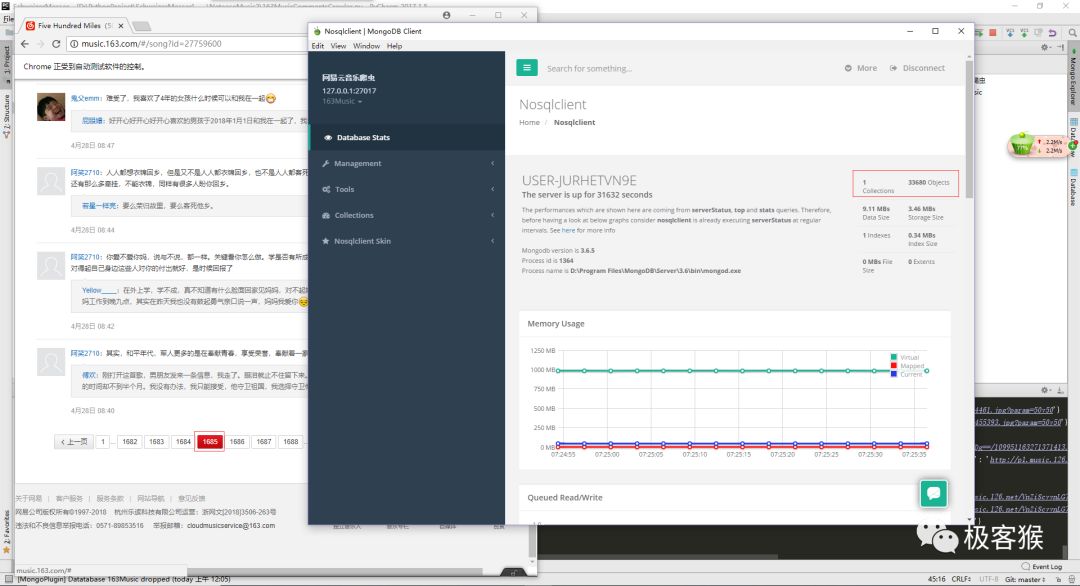
点击查看大图
4 扩展知识
这部分内容跟上述内容联系不大, 属于服务器技术范畴。如果你不感兴趣的话,可以直接跳过。另外,这部分内容是自己的理解。如果有讲错的地方,还请多多指出。
我们访问普通网站的整个过程:

点击查看大图
我们访问使用 Ajax 加载数据的网站的整个过程:
