一、需求和目标
本文主要介绍如何在腾讯云CVM上搭建Hadoop集群,以及如何通过distcp工具将友商云Hadoop中的数据迁移到腾讯云自建Hadoop集群。
二、环境说明
JDK版本:jdk1.8.0_171
Hadoop版本:hadoop-2.7.4
主机 | 角色 | 软件 |
|---|---|---|
腾讯云tx-namenode 172.16.2.234 | NameNode/SecondaryNameNode/ ResourceManager | HDFS/YARN |
腾讯云tx-datanode1 172.16.2.4 | DataNode/NodeManager | HDFS/YARN |
腾讯云tx-datanode2 172.16.2.8 | DataNode/NodeManager | HDFS/YARN |
腾讯云tx-datanode3 172.16.2.7 | DataNode/NodeManager | HDFS/YARN |
友商云ali-namenode 10.1.125.118 | NameNode/SecondaryNameNode/ ResourceManager | HDFS/YARN |
友商云ali-datanode1 10.1.125.119 | DataNode/NodeManager | HDFS/YARN |
友商云ali-datanode2 10.1.125.116 | DataNode/NodeManager | HDFS/YARN |
友商云ali-datanode3 10.1.125.117 | DataNode/NodeManager | HDFS/YARN |
三、腾讯云Hadoop集群搭建
1、系统环境配置
1.1 配置主机名(永久修改)
(1)在腾讯云tx-namenode节点配置:
[root@tx-namenode ~]# vim /etc/sysconfig/networkNETWORKING=yes #使用网络
HOSTNAME=tx-namenode #设置主机名(2)腾讯云tx-datanode1节点配置:
[root@tx-datanode1 ~]# vim /etc/sysconfig/networkNETWORKING=yes #使用网络
HOSTNAME=tx-datanode1 #设置主机名(3)腾讯云tx-datanode2节点配置:
[root@tx-datanode2 ~]# vim /etc/sysconfig/networkNETWORKING=yes #使用网络
HOSTNAME=tx-datanode2 #设置主机名(4)腾讯云tx-datanode3节点配置:
[root@tx-datanode3 ~]# vim /etc/sysconfig/networkNETWORKING=yes #使用网络
HOSTNAME=tx-datanode3 #设置主机名1.2 安装JAVA运行环境
(1)在/usr下创建Java目录
mkdir -p /usr/java(2)将JDK包解压到/usr/java下
tar xvf jdk-8u171-linux-x64.tar -C /usr/java(3)设置环境变量
vim /etc/profile#添加如下配置 export JAVA_HOME=/usr/java/jdk1.8.0_171 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME="/usr/hadoop-2.7.4"
export PATH=HADOOP_HOME/bin:HADOOP_HOME/sbin:$PATH
#重新加载,使配置生效
source /etc/profile1.3 配置hosts
#腾讯云侧每个节点都需要修改
vim /etc/hosts172.16.2.234 tx-namenode
172.16.2.4 tx-datanode1
172.16.2.8 tx-datanode2
172.16.2.7 tx-datanode31.4 配置SSH免秘钥登录
#注意:每个节点都需要操作
1.ssh-keygen,生成公钥和秘钥,在/root/.ssh/中
2.ssh-copy-id 其他节点IP 将公钥拷贝到其他节点2、Hadoop安装与配置
2.1 配置HDFS集群
有3个相关的配置文件,hadoop-env.sh、core-site.xml、hdfs-site.xml,每台节点上都需要配置。
(1)配置 hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_171(2)配置 core-site.xml
mkdir –p /var/hadoop #创建Hadoop临时目录vim core-site.xml#添加如下代码
#一般hdfs的rpc通信端口用9000和8020,这里配置9000
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://tx-namenode</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value>
</property>
</configuration>(3)配置 hdfs-site.xml
vim hdfs-site.xml#添加如下代码
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>tx-namenode:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>tx-namenode:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value> #指定HDFS副本数量为2
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value> #设置为true,确保客户端访问datanode的时候是通过主机域名访问,就不会出现通过内网IP来访问了
<description>only cofig in clients</description>
</property>
</configuration>2.2 配置YARN集群
有2个相关的配置文件,mapred-site.xml、yarn-site.xml,在每个节点上都需要做配置。
(1)mapred-site.xml 配置
默认有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架
cp mapred-site.xml.template mapred-site.xml vim mapred-site.xml#添加如下代码
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(2)yarn-site.xml 配置
vim yarn-site.xml#添加如下代码
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>tx-namenode</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
<discription>每个节点可用内存,单位MB</discription>
</property>
</configuration>
2.3 集群启动与测试
(1)格式化namenode,只需要在腾讯云tx-namenode上执行一次
#格式化
./bin/hdfs namenode -format(2)启动和停止HDFS集群,在每个节点上执行
#启动
./sbin/start-dfs.sh#停止
./sbin/stop-dfs.sh(3)验证HDFS集群是否组建成功
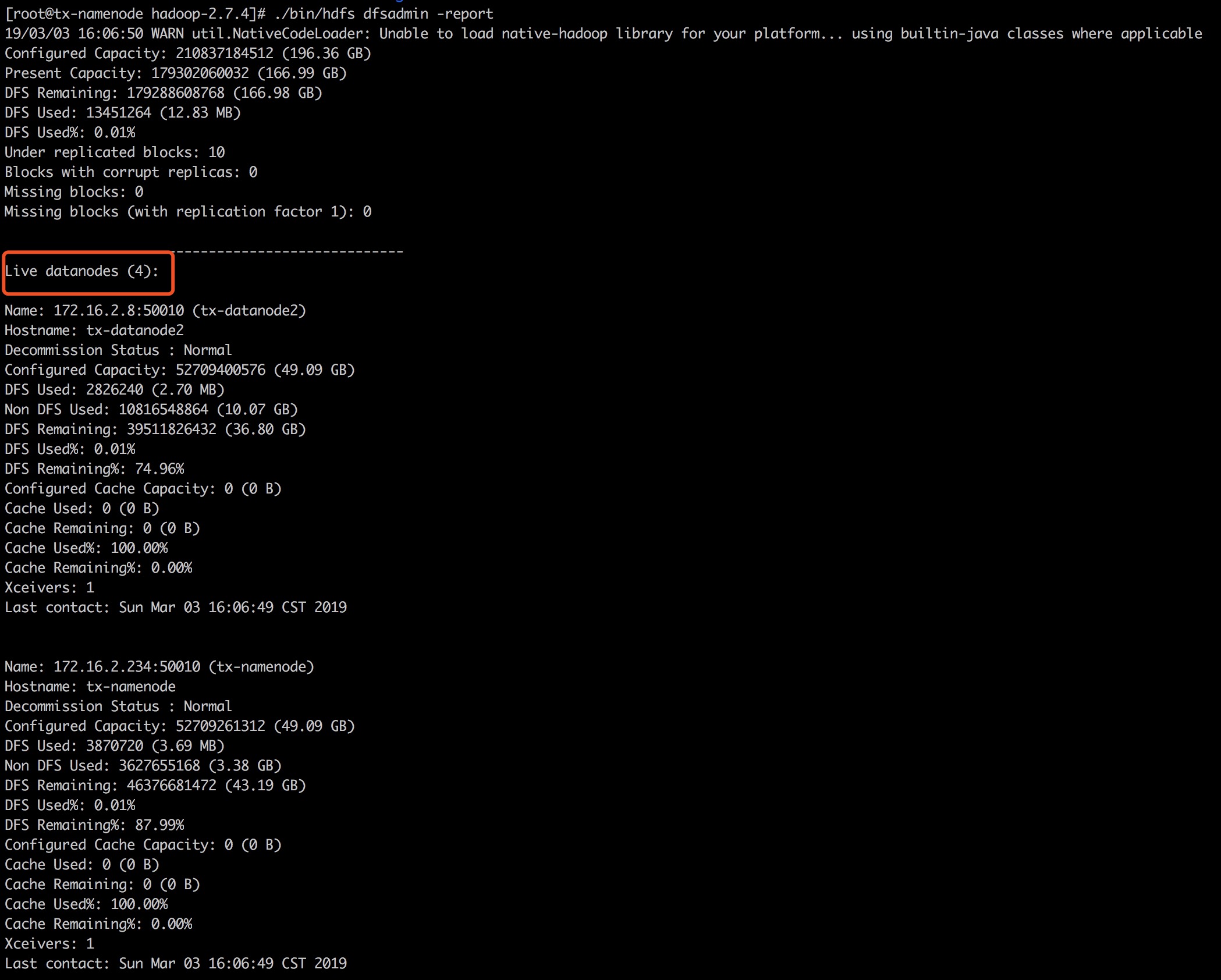
./bin/hdfs dfsadmin -report看到4个节点,说明HDFS集群正常
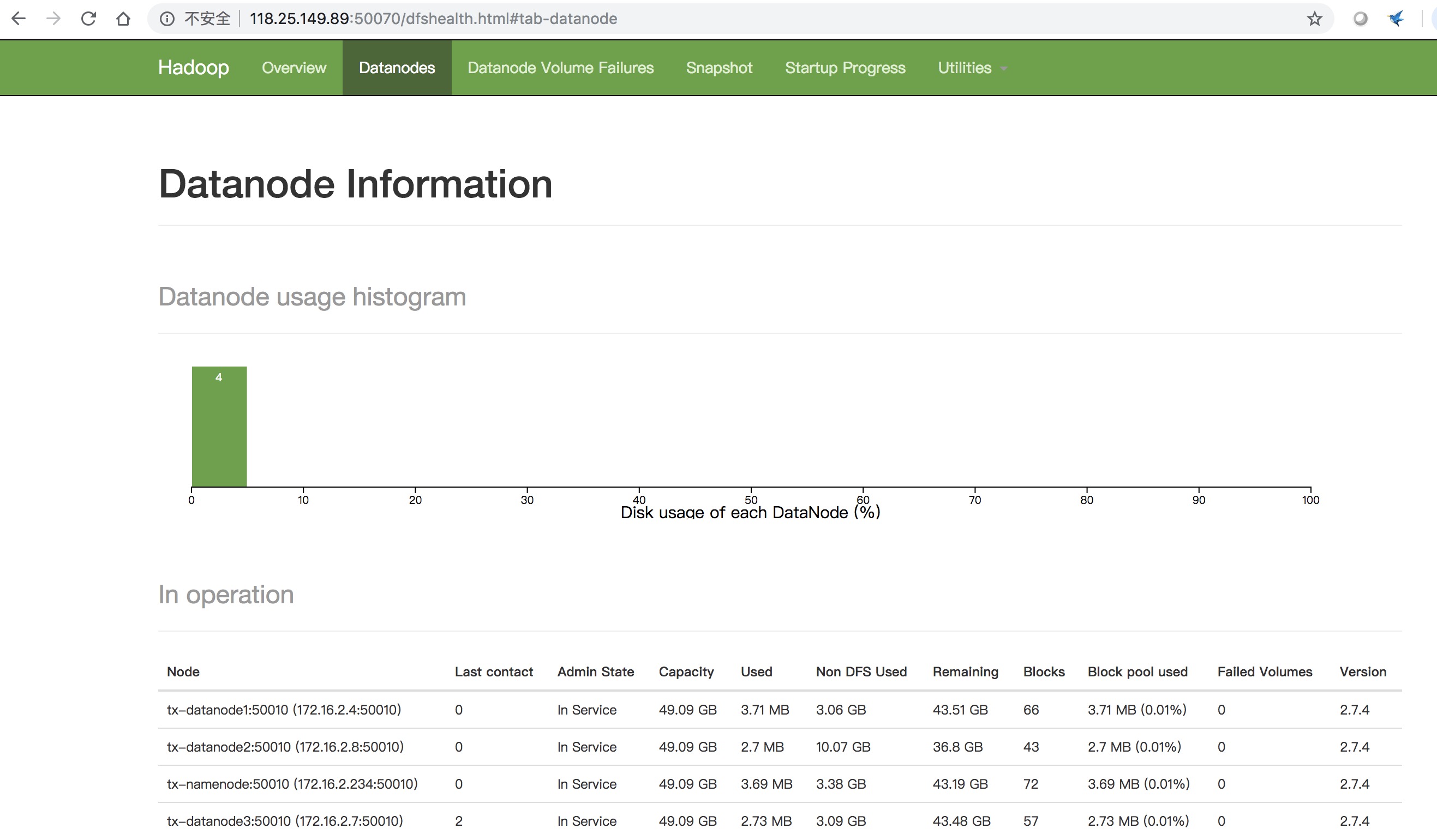
HDFS的web管理控制台,端口是50070
(4)验证角色
jps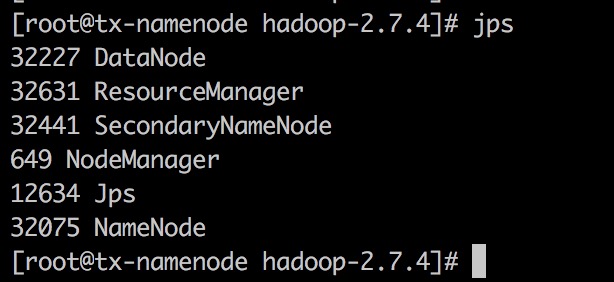
(5)启动和停止yarn集群,在每个节点上执行
#启动
./sbin/start-yarn.sh#停止
./sbin/stop-yarn.sh(6)验证yarn集群状态
./bin/yarn node -list看到4个节点,说明yarn集群正常

可以访问YARN的管理界面,端口是8088,验证YARN,如下图所示:
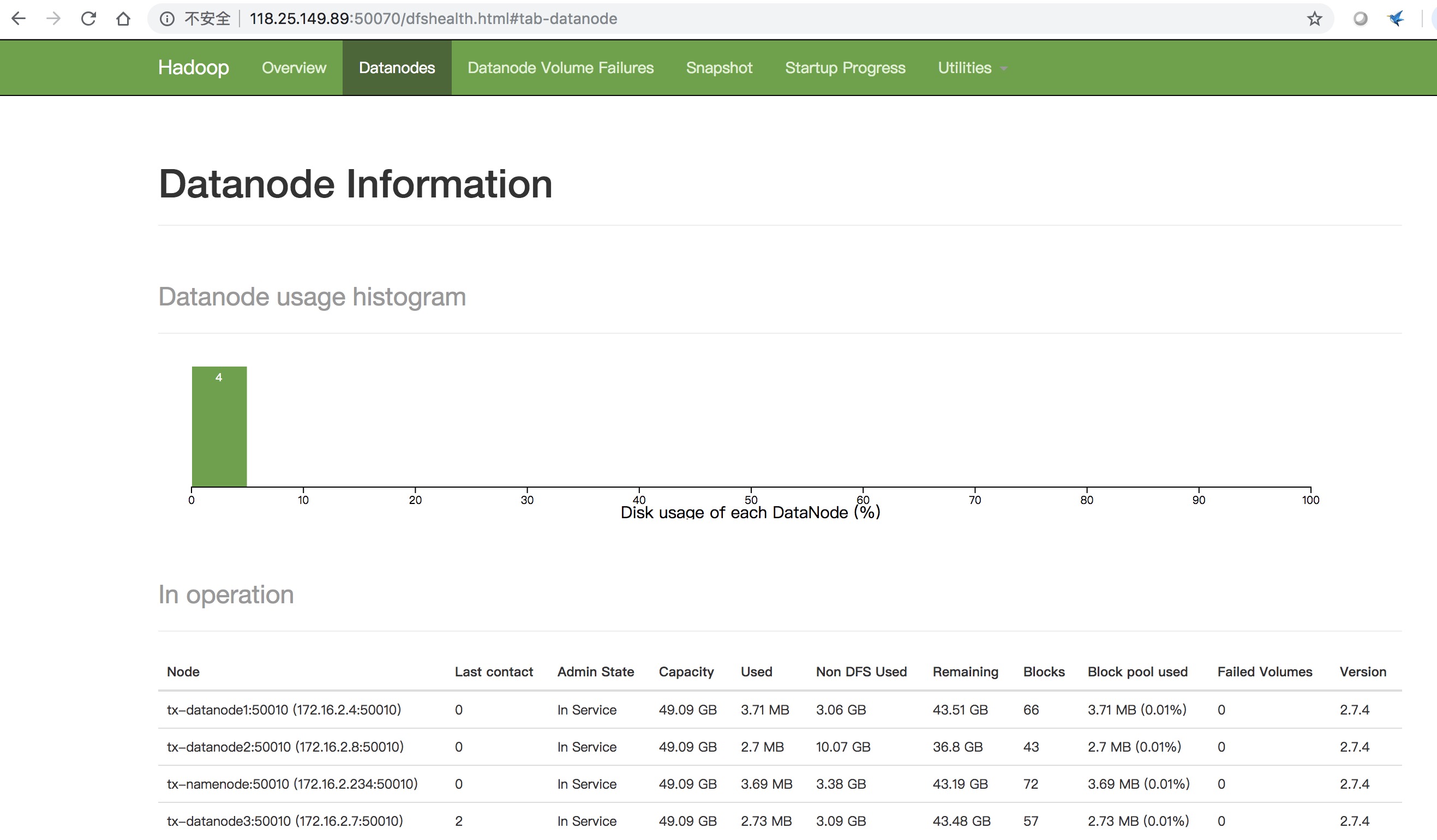
2.4 运行一个MR任务
Hadoop安装包里提供了现成的例子,在Hadoop的share/hadoop/mapreduce目录下。运行例子:
[root@tx-namenode hadoop-2.7.4]# ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar pi 5 10
Number of Maps = 5
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Starting Job
19/03/02 21:17:36 INFO client.RMProxy: Connecting to ResourceManager at ali-namenode/10.10.2.12:8032
19/03/02 21:17:37 INFO input.FileInputFormat: Total input paths to process : 5
19/03/02 21:17:37 INFO mapreduce.JobSubmitter: number of splits:5
19/03/02 21:17:37 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1551530990772_0001
19/03/02 21:17:37 INFO impl.YarnClientImpl: Submitted application application_1551530990772_0001
19/03/02 21:17:37 INFO mapreduce.Job: The url to track the job: http://ali-namenode:8088/proxy/application_1551530990772_0001/
19/03/02 21:17:37 INFO mapreduce.Job: Running job: job_1551530990772_0001
19/03/02 21:17:43 INFO mapreduce.Job: Job job_1551530990772_0001 running in uber mode : false
19/03/02 21:17:43 INFO mapreduce.Job: map 0% reduce 0%
19/03/02 21:17:48 INFO mapreduce.Job: map 20% reduce 0%
19/03/02 21:17:49 INFO mapreduce.Job: map 100% reduce 0%
19/03/02 21:17:53 INFO mapreduce.Job: map 100% reduce 100%
19/03/02 21:17:53 INFO mapreduce.Job: Job job_1551530990772_0001 completed successfully
19/03/02 21:17:53 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=116
FILE: Number of bytes written=852369
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1335
HDFS: Number of bytes written=215
HDFS: Number of read operations=23
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=5
Launched reduce tasks=1
Data-local map tasks=5
Total time spent by all maps in occupied slots (ms)=17114
Total time spent by all reduces in occupied slots (ms)=2057
Total time spent by all map tasks (ms)=17114
Total time spent by all reduce tasks (ms)=2057
Total vcore-milliseconds taken by all map tasks=17114
Total vcore-milliseconds taken by all reduce tasks=2057
Total megabyte-milliseconds taken by all map tasks=17524736
Total megabyte-milliseconds taken by all reduce tasks=2106368
Map-Reduce Framework
Map input records=5
Map output records=10
Map output bytes=90
Map output materialized bytes=140
Input split bytes=745
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=140
Reduce input records=10
Reduce output records=0
Spilled Records=20
Shuffled Maps =5
Failed Shuffles=0
Merged Map outputs=5
GC time elapsed (ms)=426
CPU time spent (ms)=2190
Physical memory (bytes) snapshot=1516769280
Virtual memory (bytes) snapshot=12634689536
Total committed heap usage (bytes)=1082130432
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=590
File Output Format Counters
Bytes Written=97
Job Finished in 17.683 seconds
Estimated value of Pi is 3.28000000000000000000四、Hadoop集群间的数据迁移
目的:用Hadoop自带的distcp工具,将友商云HDFS的数据迁移到腾讯云
1、配置注意事项
(1)确保友商云和腾讯云侧的主机名不一样;
(2)友商云和腾讯云侧所有节点配置公网IP;
(3)hosts配置:所有节点上都配置本地集群内的内网IP与主机名映射 + 对方集群的外网IP与主机名映射;
在友商云上hosts配置如下,因为要将友商云HDFS数据拷贝到腾讯云,所以在友商云每个节点需要添加腾讯云节点外网IP:
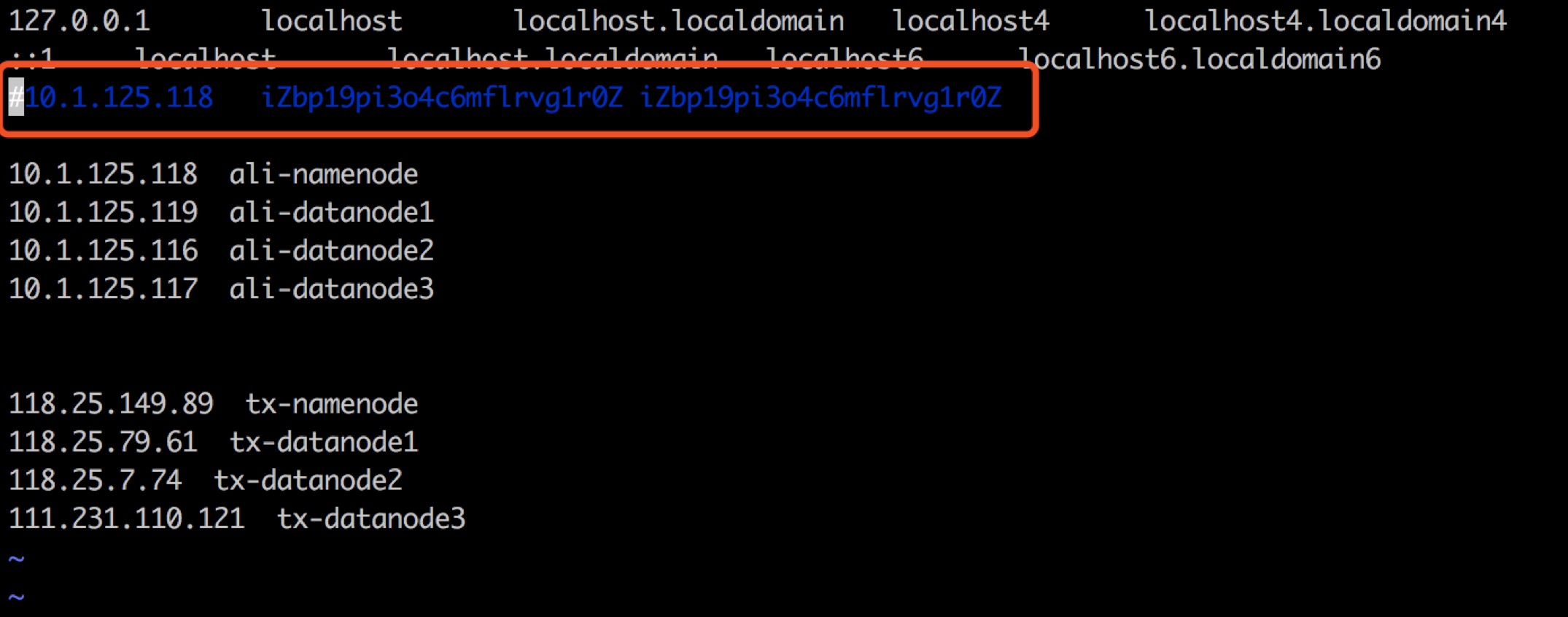
(4)安全组放行流量,确保友商云所有节点与腾讯云所有节点互相能够连通。
2、在友商云Hadoop集群上执行distcp进行拷贝
[root@ali-namenode hadoop-2.7.4]#./bin/hadoop distcp hdfs://ali-namenode:9000/ali4 hdfs://tx-namenode/执行成功信息如下:
[root@ali-namenode hadoop-2.7.4]# ./bin/hadoop distcp hdfs://ali-namenode:9000/ali4 hdfs://tx-namenode/
19/03/03 17:22:52 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=false, deleteMissing=false, ignoreFailures=false, maxMaps=20, sslConfigurationFile='null', copyStrategy='uniformsize', sourceFileListing=null, sourcePaths=[hdfs://ali-namenode:9000/ali4], targetPath=hdfs://tx-namenode/, targetPathExists=true, preserveRawXattrs=false}
19/03/03 17:22:52 INFO client.RMProxy: Connecting to ResourceManager at ali-namenode/10.1.125.118:8032
19/03/03 17:22:52 INFO Configuration.deprecation: io.sort.mb is deprecated. Instead, use mapreduce.task.io.sort.mb
19/03/03 17:22:52 INFO Configuration.deprecation: io.sort.factor is deprecated. Instead, use mapreduce.task.io.sort.factor
19/03/03 17:22:53 INFO client.RMProxy: Connecting to ResourceManager at ali-namenode/10.1.125.118:8032
19/03/03 17:22:53 INFO mapreduce.JobSubmitter: number of splits:1
19/03/03 17:22:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1551594039839_0008
19/03/03 17:22:54 INFO impl.YarnClientImpl: Submitted application application_1551594039839_0008
19/03/03 17:22:54 INFO mapreduce.Job: The url to track the job: http://ali-namenode:8088/proxy/application_1551594039839_0008/
19/03/03 17:22:54 INFO tools.DistCp: DistCp job-id: job_1551594039839_0008
19/03/03 17:22:54 INFO mapreduce.Job: Running job: job_1551594039839_0008
19/03/03 17:23:00 INFO mapreduce.Job: Job job_1551594039839_0008 running in uber mode : false
19/03/03 17:23:00 INFO mapreduce.Job: map 0% reduce 0%
19/03/03 17:23:06 INFO mapreduce.Job: map 100% reduce 0%
19/03/03 17:23:06 INFO mapreduce.Job: Job job_1551594039839_0008 completed successfully
19/03/03 17:23:06 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=144218
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=355
HDFS: Number of bytes written=36
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=3353
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=3353
Total vcore-milliseconds taken by all map tasks=3353
Total megabyte-milliseconds taken by all map tasks=3433472
Map-Reduce Framework
Map input records=1
Map output records=1
Input split bytes=134
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=59
CPU time spent (ms)=470
Physical memory (bytes) snapshot=170491904
Virtual memory (bytes) snapshot=2106613760
Total committed heap usage (bytes)=93323264
File Input Format Counters
Bytes Read=221
File Output Format Counters
Bytes Written=36
DistCp Counters
Bytes Skipped=5
Files Skipped=1在腾讯云HDFS上也可以查到这个文件,说明拷贝成功。

五、通过外网distcp失败案例分析
1、问题现象
通过外网disctp工具拷贝文件失败,从图中报错信息中可以看到remote IP是一个内网IP,因为两个Hadoop集群内网不通,连接肯定失败。
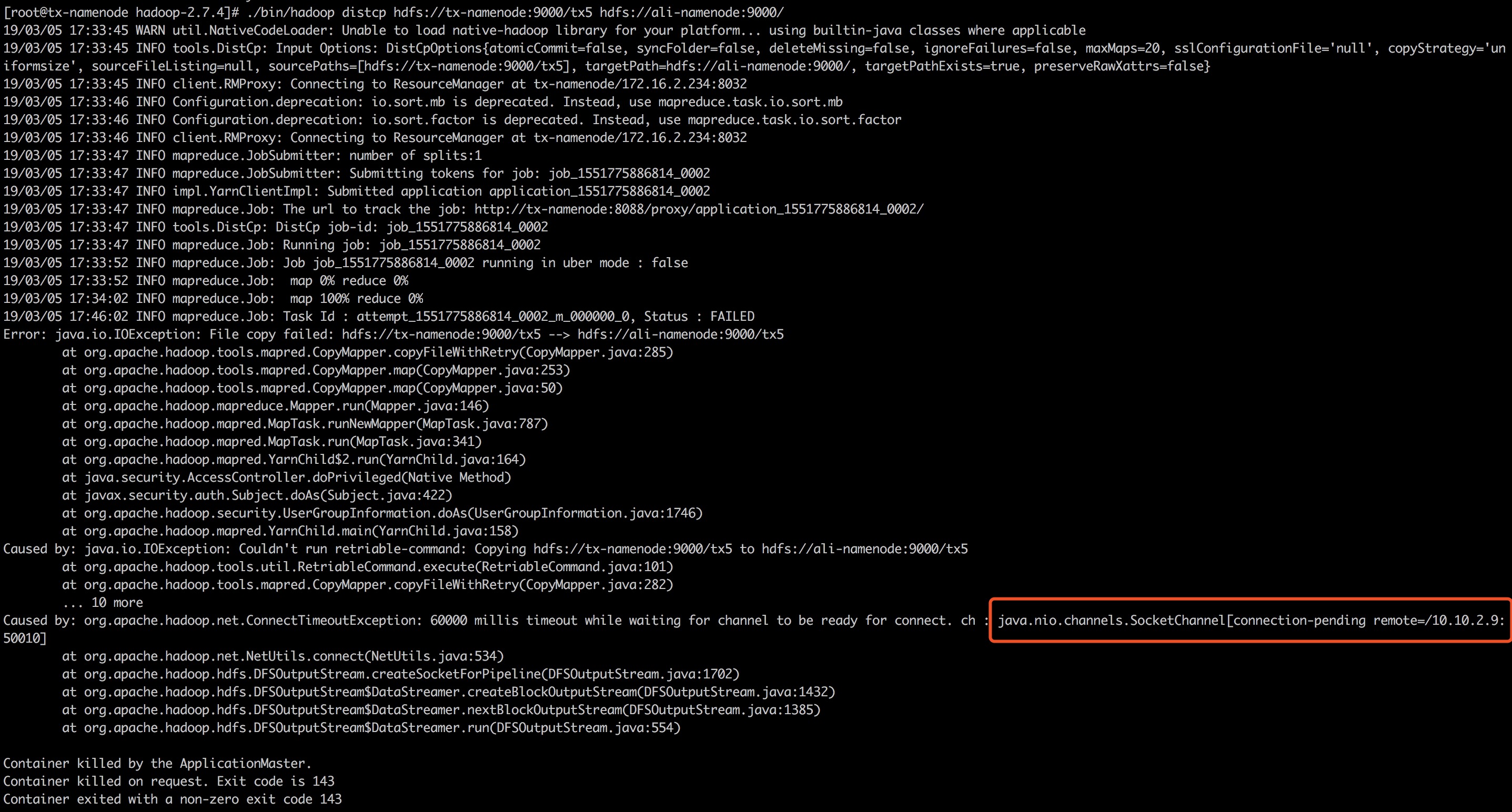
2、问题分析解决
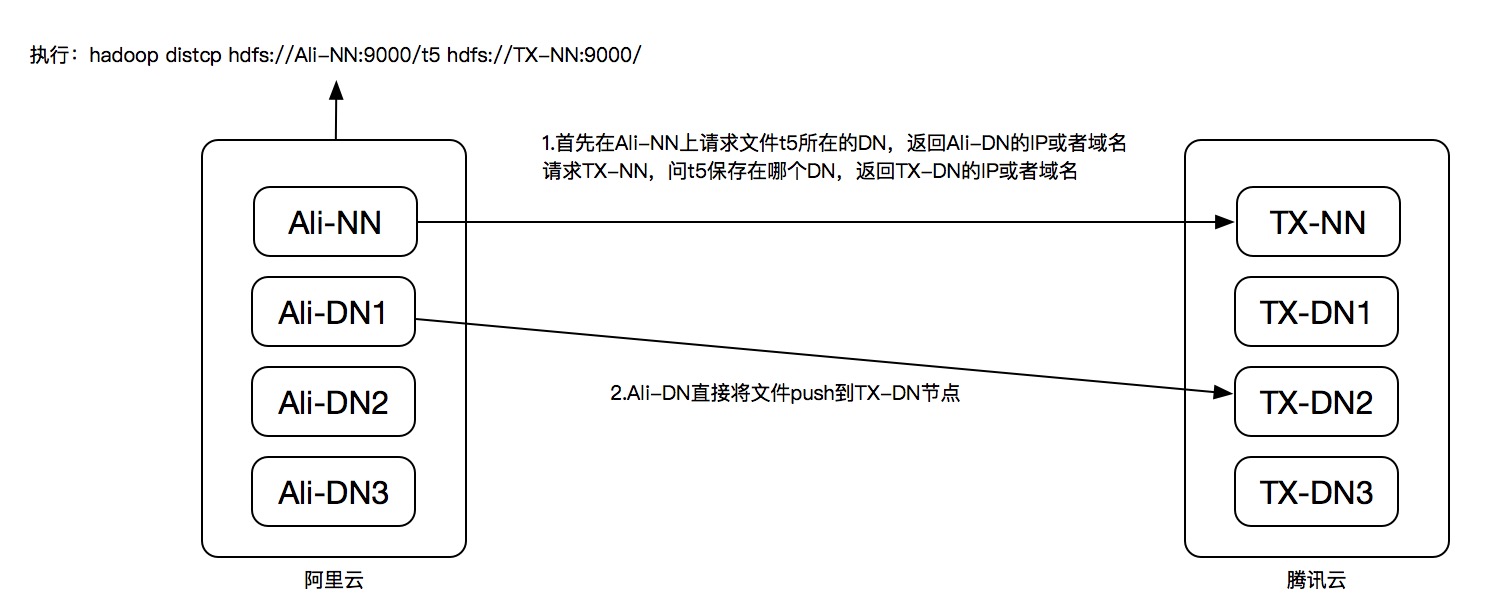
注意:distcp工具可以理解为Hadoop的client,可以在源端执行(push),也可以在目的端(pull)执行,但是在外网拷贝的情况下,一定要在hdfs-site.xml文件中增加以下配置:
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>结论:distcp作为client去NN请求DN的时候,确保返回的是DN的域名(因为在云内部如果返回IP的话就是内网IP,很显然就会连接失败),因为本地有做对端DN与外网IP的hosts绑定,这时候连外网IP就能成功!!
六、总结
Hadoop集群间迁移一般采用distcp工具,这里介绍的是通过在外网如果实现数据的迁移。在企业实际的生产环境中,如果数据量比较大,可以用专线将两边内网打通,基于内网来做数据迁移。
另外如果是冷数据,可以将冷数据迁移到腾讯云COS存储,可以降低成本,具体见:https://cloud.tencent.com/document/product/436/7212