提示:公众号展示代码会自动折行,建议横屏阅读
多机房容灾是存储系统领域非常重要的课题。本文将从内核代码层面,介绍腾讯云MongoDB数据库系统(CMongo)在多机房部署场景下,如何实现业务到机房的就近访问,并保证数据一致性。
1. 背景介绍
为了保证服务可用性和数据可靠性,一些重要业务会将存储系统部署在多地域多机房。比如在北京,上海,深圳 每个地域的机房各存储一份数据副本,保证即使某个地域的机房无法提供访问,也不会影响业务的正常使用。
在多机房部署时,需要考虑多机房之间的网络延迟问题。以作者的ping测试结果为例,上海<-->深圳的网络延迟约为30ms,而在一个机房内部,网络延迟仅在0.1ms左右。
腾讯云MongoDB在架构上,结合L5就近接入以及内部的“nearest”访问模式,实现了业务对机房的就近访问,避免了多机房带来的网络延迟问题。整体架构如下图所示,其中mongos为接入节点,可以理解为proxy;mongod为存储节点,存储用户的实际数据,并通过 1 Primary 多 Secondary的模式形成多个副本,分散到多个机房中
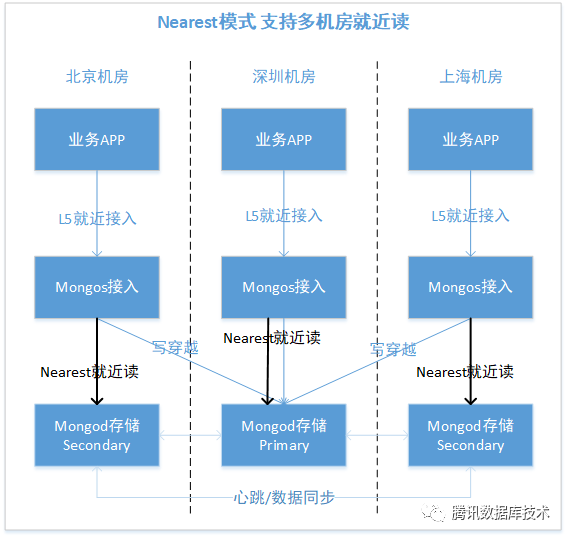
下面主要对腾讯云MongoDB中nearest模式的实现和使用方式做详细介绍。
2. 什么是nearest访问模式
2.1 副本集概念
MongoDB中,副本集 是指保存相同数据的多个副本节点的集合。用户可以通过Driver直接访问副本集,或者通过mongos访问副本集。如下图所示
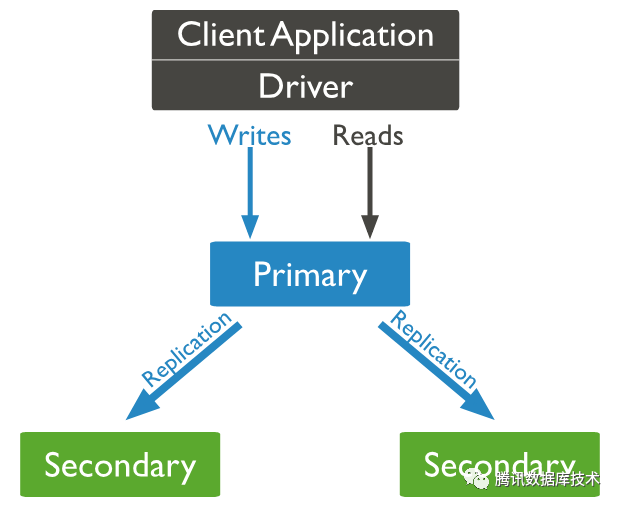
副本集内部通过raft算法来选主,通过oplog同步数据。
2.2 读写分离和readPreference
MongoDB默认读写都在Primary节点上执行,但是也提供了接口进行读写请求分离,充分发挥系统的整体性能。读写分离的关键在于设置请求的readPreference。这个参数标识了用户希望读取哪种节点,目前可配置的类型共5种,如下所示

2.3 读写一致性保证
有些读者可能已经产生了疑问:如果Secondary节点从Primary同步数据可能存在延迟,如何保证在从节点能够读取到刚刚写入的数据?解决方法是:设置写入操作的WriteConcern,保证数据写入到全部节点之后再返回,此时再去从节点,肯定可以读取到最新的数据。
写操作是需要跨机房同步数据的,所以如果业务模型是写多读少,需要谨慎考虑。
3. nearest实现原理解析
如果业务通过mongos接入(腾讯云MongoDB架构常用方式),则mongos侧来完成到mongod的就近访问。如果业务直接接入副本集,则在driver层会完成到mongod的就近访问。
下面会结合mongos(腾讯云MongoDB代码),mgo-driver,以及官方最新发布的go-driver,来分析如何实现nearest访问,并给出一些使用上的建议。
3.1 mongos代码分析
延迟信息采集
mongos 每隔5秒会对集群中的每个副本集启动探测线程,执行 isMaster命令并采集自己到每个节点的网络延迟情况,采集方式如下所示:
try { ScopedDbConnection conn(ConnectionString(ns.host), socketTimeoutSecs); bool ignoredOutParam = false; Timer timer; //开始计时 if (conn->isStillConnected()) { conn->isMaster(ignoredOutParam, &reply); //执行isMaster命令获取副本集状态 } else { log() << "Connection to " << ns.host.toString() << " is closed"; reply = BSONObj(); } pingMicros = timer.micros(); //统计本次耗时 conn.done();} catch (const DBException& ex) { ...}然后根据本次采集的延迟进行平滑更新, 核心如下所示:
if (reply.latencyMicros >= 0) { if (latencyMicros == unknownLatency) { latencyMicros = reply.latencyMicros; //第一次更新,直接赋值 } else { // update latency with smoothed moving average (1/4th the delta) latencyMicros += (reply.latencyMicros - latencyMicros) / 4; //根据当前延迟和历史统计,进行平滑更新 }}nearest节点选取
节点选取的算法,可以参考SetState::getMatchingHost方法。大致的选取流程为:按照每个节点的延迟升序排序 -> 排除延迟太高的节点(比最近节点的延迟大15ms)-> 随机返回一个符合条件的节点。
case ReadPreference::SecondaryOnly:case ReadPreference::Nearest: { BSONForEach(tagElem, criteria.tags.getTagBSON()) { uassert(16358, "Tags should be a BSON object", tagElem.isABSONObj()); BSONObj tag = tagElem.Obj();
std::vector<const Node*> matchingNodes; for (size_t i = 0; i < nodes.size(); i++) { // 如果是SecondaryOnly模式,需要进行过滤 if (nodes[i].matches(criteria.pref) && nodes[i].matches(tag)) { matchingNodes.push_back(&nodes[i]); } }
// don't do more complicated selection if not needed if (matchingNodes.empty()) continue; if (matchingNodes.size() == 1) return matchingNodes.front()->host;
// order by latency and don't consider hosts further than a threshold from the // closest. // 对候选节点按延迟进行排序 std::sort(matchingNodes.begin(), matchingNodes.end(), compareLatencies); for (size_t i = 1; i < matchingNodes.size(); i++) { int64_t distance = matchingNodes[i]->latencyMicros - matchingNodes[0]->latencyMicros; if (distance >= latencyThresholdMicros) { // this node and all remaining ones are too far away // 剔除延迟超过阈值(默认15ms,可配置)的节点 matchingNodes.erase(matchingNodes.begin() + i, matchingNodes.end()); break; } }
// of the remaining nodes, pick one at random (or use round-robin) if (ReplicaSetMonitor::useDeterministicHostSelection) { // only in tests return matchingNodes[roundRobin++ % matchingNodes.size()]->host; } else { // normal case // 从剩余的候选节点中,随机选取一个返回 return matchingNodes[rand.nextInt32(matchingNodes.size())]->host; }; }
return HostAndPort();}使用建议
可以注意到mongos代码中有一个 默认的15ms配置,含义为:如果有一个节点的延迟比最近节点的延迟还要大15ms,则认为这个节点不应该被nearest策略选中。但是15ms并不是对每一个业务都合理。如果业务对延迟非常敏感,可以根据自己的需要来进行设置方法是在mongos配置文件中添加下面配置选项:
replication: localPingThresholdMs: <int>3.2 mgo driver代码分析
延迟信息采集
mgo driver 每隔15秒会通过 ping命令采集自己到mongod节点的网络延迟状况,并将最近6次采集结果的最大值作为当前网络延迟的参考值。代码如下所示:
for { if loop { time.Sleep(delay) // 每隔一段时间(默认15秒)采集一次 } op := op socket, _, err := server.AcquireSocket(0, delay) if err == nil { start := time.Now() _, _ = socket.SimpleQuery(&op) // 执行ping命令 delay := time.Now().Sub(start) // 并统计耗时
server.pingWindow[server.pingIndex] = delay server.pingIndex = (server.pingIndex + 1) % len(server.pingWindow) server.pingCount++ var max time.Duration for i := 0; i < len(server.pingWindow) && uint32(i) < server.pingCount; i++ { if server.pingWindow[i] > max { max = server.pingWindow[i] // 统计最近6次(默认)采集的最大值 } } socket.Release() server.Lock() if server.closed { loop = false } server.pingValue = max // 将最大值作为网络延迟统计,作为后续选择节点时的评估依据 server.Unlock() logf("Ping for %s is %d ms", server.Addr, max/time.Millisecond) } else if err == errServerClosed { return } if !loop { return }}nearest节点选取
和mongos相同,会排除延迟太高(>15ms)的节点。但是区别在于不是随机返回一个满足条件的节点,而是尽量返回当前压力比较小的节点(通过当前使用的连接数来判定),这样可以尽量做到负载均衡。代码如下所示:
// BestFit returns the best guess of what would be the most interesting// server to perform operations on at this point in time.func (servers *mongoServers) BestFit(mode Mode, serverTags []bson.D) *mongoServer { var best *mongoServer for _, next := range servers.slice { // 遍历每一个候选节点 if best == nil { best = next best.RLock() if serverTags != nil && !next.info.Mongos && !best.hasTags(serverTags) { best.RUnlock() best = nil } continue } next.RLock() swap := false switch { case serverTags != nil && !next.info.Mongos && !next.hasTags(serverTags): // Must have requested tags. case next.info.Master != best.info.Master && mode != Nearest: // Prefer slaves, unless the mode is PrimaryPreferred. swap = (mode == PrimaryPreferred) != best.info.Master case absDuration(next.pingValue-best.pingValue) > 15*time.Millisecond: // Prefer nearest server. // 如果找到一个明显更近(默认15ms为判断依据)的节点,则用更近的 swap = next.pingValue < best.pingValue case len(next.liveSockets)-len(next.unusedSockets) < len(best.liveSockets)-len(best.unusedSockets): // Prefer servers with less connections. // 如果延迟没有明显差距,则用当前连接数比较小的节点 swap = true } if swap { best.RUnlock() best = next } else { next.RUnlock() } } if best != nil { best.RUnlock() } return best}3.3 官方go driver代码分析
延迟信息采集
官方go driver 每隔10秒会通过 isMaster命令采集自己到mongod节点的网络延迟状况:
now := time.Now() // 开始统计耗时
// 去对应的节点上执行isMaster命令isMasterCmd := &command.IsMaster{Compressors: s.cfg.compressionOpts}isMaster, err := isMasterCmd.RoundTrip(ctx, conn)
...
delay := time.Since(now) // 得到耗时统计desc = description.NewServer(s.address, isMaster).SetAverageRTT(s.updateAverageRTT(delay)) // 进行平滑统计采集完成后,会结合历史数据进行平滑统计,如下:
func (s *Server) updateAverageRTT(delay time.Duration) time.Duration { if !s.averageRTTSet { s.averageRTT = delay // 如果是第一次统计,则直接赋值 } else { alpha := 0.2 // 进行平滑处理,新数据和历史数据的比重为 1 : 4 s.averageRTT = time.Duration(alpha*float64(delay) + (1-alpha)*float64(s.averageRTT)) } return s.averageRTT}nearest节点选取
以Find命令为例,go driver会生成一个 复合选择器,复合选择器会依次执行各项选择算法,得到一个候选节点列表:
readSelect := description.CompositeSelector([]description.ServerSelector{ // 复合选择器 description.ReadPrefSelector(rp), // 1.根据readPreference设置,选择主从节点 description.LatencySelector(db.client.localThreshold), //2.根据延迟选择最优节点})其中对于节点延迟的选择主要依赖于 LatencySelector。大致流程为:统计到所有节点的最小延迟min-->计算延迟满足标准:min+15ms(默认)-->返回所有满足延迟标准的节点列表。核心代码如下:
func (ls *latencySelector) SelectServer(t Topology, candidates []Server) ([]Server, error) { if ls.latency < 0 { return candidates, nil }
switch len(candidates) { case 0, 1: return candidates, nil default: min := time.Duration(math.MaxInt64) for _, candidate := range candidates { if candidate.AverageRTTSet { // 计算所有候选节点的最小延迟 if candidate.AverageRTT < min { min = candidate.AverageRTT } } }
if min == math.MaxInt64 { return candidates, nil } // 用最小延迟加阈值配置(默认15ms)作为最大容忍延迟 max := min + ls.latency
var result []Server for _, candidate := range candidates { if candidate.AverageRTTSet { if candidate.AverageRTT <= max { // 返回所有符合延迟标准(最大容忍延迟)的节点 result = append(result, candidate) } } }
return result, nil }}最后根据选择得到的候选列表,随机返回一个正常节点作为目标节点。核心代码如下:
for { // 根据前面介绍的“复合选择器”,得到候选节点列表 suitable, err := t.selectServer(ctx, sub.C, ss, ssTimeoutCh) if err != nil { return nil, err }
// 随机选择一个作为目标节点 selected := suitable[rand.Intn(len(suitable))] selectedS, err := t.FindServer(selected) switch { case err != nil: return nil, err case selectedS != nil: return selectedS, nil default: // We don't have an actual server for the provided description. // This could happen for a number of reasons, including that the // server has since stopped being a part of this topology, or that // the server selector returned no suitable servers. }}使用建议
关于上述15ms的默认配置,官方go driver也提供了设置接口。对于延迟敏感的业务,可以通过这个接口配置ClientOptions,降低阈值。
4. 总结
MongoDB通过nearest模式支持多机房部署场景中客户端driver->mongod以及mongos->mongod的就近读。本文结合腾讯云MongoDB内核代码和常用的go driver代码对nearest的原理进行分析,并给出了一些使用建议。

腾讯数据库技术团队对内支持QQ空间、微信红包、腾讯广告、腾讯音乐、腾讯新闻等公司自研业务,对外在腾讯云上支持TencentDB相关产品,如CynosDB、CDB、CTSDB、CMongo等。腾讯数据库技术团队专注于持续优化数据库内核和架构能力,提升数据库性能和稳定性,为腾讯自研业务和腾讯云客户提供“省心、放心”的数据库服务。此公众号和广大数据库技术爱好者一起,推广和分享数据库领域专业知识,希望对大家有所帮助。