写在前面
首先很幸运能和杰少、林有夕成为队友,与你们一起比赛真是件无比轻松的事情。同时希望我的分享与总结能给大家带来些许帮助,并且一起交流学习。

接下来将会呈现完整方案!!!满满干货!!!
数据集下载链接:https://pan.baidu.com/s/1exjtkUqYPzdWKsCUYGix_g
提取码:0qsm
赛题分析
大赛以“地铁乘客流量预测”为赛题,参赛者可通过分析地铁站的历史刷卡数据,预测站点未来的客流量变化,帮助实现更合理的出行路线选择,规避交通堵塞,提前部署站点安保措施等,最终实现用大数据和人工智能等技术助力未来城市安全出行。
问题简介,通过分析地铁站的历史刷卡数据,预测站点未来的每十分钟出入客流量。
比赛训练集包含1月1日到1月25日共25天地铁刷卡数据记录。分为A、B、C三个榜,分别增加一天的数据记录,预测接下来一天每个站点每十分钟出入客流量。评估指标为MAE。
数据集

评估指标
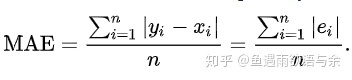
赛题难点
本次比赛分为三个榜,每个榜选取的日期不同,有周内,也有周末。我们将周内看作正常日期,周末看作特殊日期。面对这两类日期如何进行建模,如何建模尽可能达到最大的预测准确性。我们将本次比赛的难点归纳为如下几点。
(1)本次比赛的label需要自己构建, 如何建模使我们能在给定的数据集上达到尽可能大的预测准确性?
(2)对于训练集不同时间段的选取对最终结果都很造成一定的影响,如何选用时间段,让训练集分布和测试集分布类似,也是本次比赛的关键之一。
(3)如何刻画每个时间段的时序特点,使其能够捕捉数据集的趋势性,周期性,循环性。
(4)地铁站点的流量存在太多影响因素,比如同时到站,突发情况,或者是盛大活动等,所以该如何处理异常值&保证模型稳定的情况。
针对上面的几个难点,下面我们分块阐述我们团队算法设计的思路&细节,我们的核心思路主要分为基于EDA的建模模块、特征工程模块以及模型训练&融合三个部分。
核心思路Part1- EDA-based建模框架
1.模型框架
模型我们采用滑窗滚动(天)的方式进行构建,这样可以防止因为某一天存在奇异值而导致模型训练走偏。最后将所有滚动滑窗的标签以及特征进行拼接形成我们最终的训练集。
滑窗的方式可以参考下图:
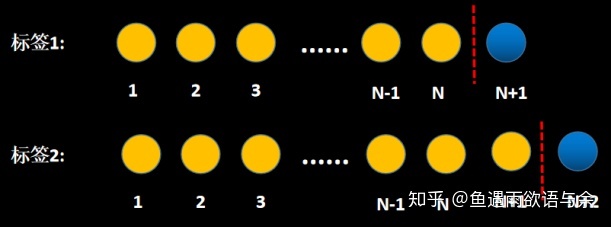
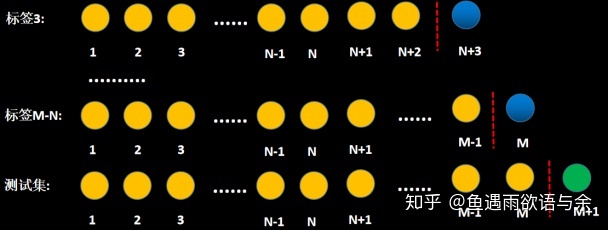
对于常见得时序问题时,都可以采样这种方式来提取特征,构建训练集。
2.模型细节
上面滑窗滚动需要选择分布于测试集类似的进行label的构建才能取得较好的结果,所以在此之前我们需要对分布差异大的数据进行删除。
这里我们进行了简单得EDA来分析label得分布情况。(好的EDA能够帮助你理解数据,挖掘更多细节,在比赛中必不可少)
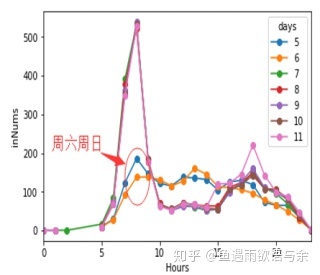
5号-10号各时刻入站流量分布
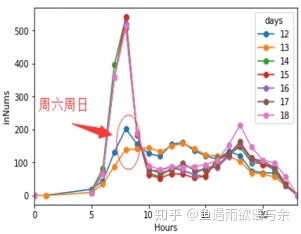
12号-18号各时刻入站流量分布
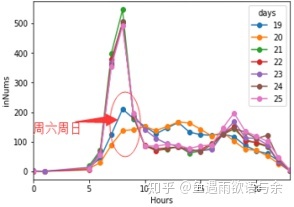
19号-25号各时刻入站流量分布
从三幅图中可以看出周末与周内分布有很大差异,所以我们将测试集为周末和测试集为周内经行区别对待,保证训练集分布的稳定。
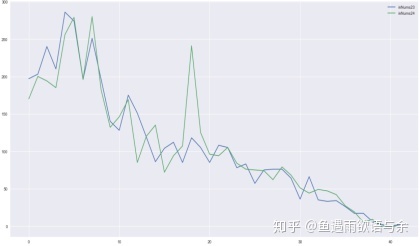
23号和24号入站流量分布
从图中可以看出相同时间段流量突然相差巨大。可以考虑是因为突发性活动,特别事件等因素影响。
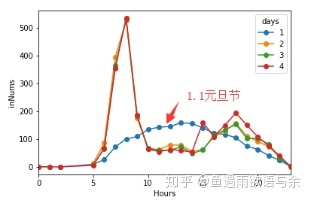
元旦节及之后几天的入站流量分布
由节假日流量分布,我们发现,节假日的信息和非节假日的分布差异非常大,所以我们也选择将其删除。
核心思路Part2-特征工程
有了模型的框架,下面就是如何对每个站点不同时刻的流量信息进行刻画,此处需要切身地去思考影响地铁站点流量的因素,并从能使用的数据中思考如何构造相关特征来表示该因素。最终通过大量的EDA以及分析,我们通过以下几个模块来对地铁流量的特征进行构建。
1. 强相关性信息
强相关性信息主要发生在每天对应时刻,所以我们分别构造了小时粒度和10分钟粒度的出入站流量特征。考虑到前后时间段流量的波动因素,所以又添加上个时段和下个时段,或者上两个和下两个时段的流量特征。同时还构造了前N天对应时段的流量。更进一步,考虑到相邻站点的强相关性,添加相邻两站对应时段的流量。

2. 趋势性
挖掘趋势性也是我们提取特征的关键,我们主要构造特征定义如下:
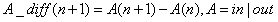
即表示前后时段的差值,这里可以是入站流量也可以是出战流量。同样,我们考虑了每天对应当前时段,每天对应上个时段等。当然我们也可以考虑差比:
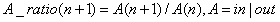

关键代码:
def time_before_trans(x,dic_): if x in dic_.keys(): return dic_[x] else: return np.nan def generate_fea_y(df, day, n): df_feature_y = df.loc[df.days_relative == day].copy()df_feature_y['tmp_10_minutes'] = df_feature_y['stationID'].values * 1000 + df_feature_y['ten_minutes_in_day'].values df_feature_y['tmp_hours'] = df_feature_y['stationID'].values * 1000 + df_feature_y['hour'].values for i in range(n): # 前n天每一天 d = day - i - 1 df_d = df.loc[df.days_relative == d].copy() # 当天的数据 # 特征1:过去在该时间段(一样的时间段,10minutes)有多少出入量 df_d['tmp_10_minutes'] = df['stationID'] * 1000 + df['ten_minutes_in_day'] df_d['tmp_hours'] = df['stationID'] * 1000 + df['hour'] # sum dic_innums = df_d.groupby(['tmp_10_minutes'])['inNums'].sum().to_dict() dic_outnums = df_d.groupby(['tmp_10_minutes'])['outNums'].sum().to_dict() df_feature_y['_bf_' + str(day -d) + '_innum_10minutes'] = df_feature_y['tmp_10_minutes'].map(dic_innums).values df_feature_y['_bf_' + str(day -d) + '_outnum_10minutes'] = df_feature_y['tmp_10_minutes'].map(dic_outnums).values # 特征2:过去在该时间段(小时)有多少出入量 dic_innums = df_d.groupby(['tmp_hours'])['inNums'].sum().to_dict() dic_outnums = df_d.groupby(['tmp_hours'])['outNums'].sum().to_dict() df_feature_y['_bf_' + str(day -d) + '_innum_hour'] = df_feature_y['tmp_hours'].map(dic_innums).values df_feature_y['_bf_' + str(day -d) + '_outnum_hour'] = df_feature_y['tmp_hours'].map(dic_outnums).values # 特征3: 上10分钟 df_d['tmp_10_minutes_bf'] = df['stationID'] * 1000 + df['ten_minutes_in_day'] - 1 df_d['tmp_hours_bf'] = df['stationID'] * 1000 + df['hour'] - 1 # sum dic_innums = df_d.groupby(['tmp_10_minutes_bf'])['inNums'].sum().to_dict() dic_outnums = df_d.groupby(['tmp_hours_bf'])['outNums'].sum().to_dict() df_feature_y['_bf21_' + str(day -d) + '_innum_10minutes'] = df_feature_y['tmp_10_minutes'].agg(lambda x: time_before_trans(x,dic_innums)).values df_feature_y['_bf1_' + str(day -d) + '_outnum_10minutes'] = df_feature_y['tmp_10_minutes'].agg(lambda x: time_before_trans(x,dic_outnums)).values # 特征4: 上个小时情况 dic_innums = df_d.groupby(['tmp_hours_bf'])['inNums'].sum().to_dict() dic_outnums = df_d.groupby(['tmp_hours_bf'])['outNums'].sum().to_dict() df_feature_y['_bf1_' + str(day -d) + '_innum_hour'] = df_feature_y['tmp_hours'].map(dic_innums).values df_feature_y['_bf1_' + str(day -d) + '_outnum_hour'] = df_feature_y['tmp_hours'].map(dic_outnums).values for col in ['tmp_10_minutes','tmp_hours']: del df_feature_y[col] return df_feature_y </code></pre></div></div><h4 id="64d7i" name="%E8%A1%A5%E5%85%85%EF%BC%9A%E4%B8%8A%E9%9D%A2%E6%98%AF%E6%AF%94%E8%B5%9B%E6%89%80%E7%94%A8%E4%BB%A3%E7%A0%81%EF%BC%8C%E4%BD%86%E8%B5%9B%E5%90%8E%E6%89%8D%E5%8F%91%E7%8E%B0%E6%9C%89%E9%83%A8%E5%88%86%E9%80%BB%E8%BE%91%E9%94%99%E8%AF%AF%EF%BC%8C%E8%BF%99%E4%B8%AA%E9%94%99%E8%AF%AF%E4%BB%8EA%E6%A6%9C%E5%88%B0C%E6%A6%9C%E9%83%BD%E6%B2%A1%E5%8F%91%E7%8E%B0">补充:上面是比赛所用代码,但赛后才发现有部分逻辑错误,这个错误从A榜到C榜都没发现</h4><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0"># 错误代码dic_innums = df_d.groupby(['tmp_10_minutes_bf'])['inNums'].sum().to_dict()
dic_outnums = df_d.groupby(['tmp_hours_bf'])['outNums'].sum().to_dict()修改后代码
dic_innums = df_d.groupby(['tmp_10_minutes_bf'])['inNums'].sum().to_dict()
dic_outnums = df_d.groupby(['tmp_10_minutes_bf'])['outNums'].sum().to_dict()
3.周期性
由于周末分布类似,工作日分布类似。所以我们选择对应日期对应时间段的信息进行特征的构建,具体地:

关键代码:
columns = ['_innum_10minutes','_outnum_10minutes','_innum_hour','_outnum_hour']# 过去n天的sum,mean
for i in range(2,left):
for f in columns:
colname1 = 'bf'+str(i)+'_'+'days'+f+'sum'
df_feature_y[colname1] = 0
for d in range(1,i+1):
df_feature_y[colname1] = df_feature_y[colname1] + df_feature_y['bf'+str(d) +f]
colname2 = 'bf'+str(d)+''+'days'+f+'_mean'
df_feature_y[colname2] = df_feature_y[colname1] / i过去n天的mean的差分
for i in range(2,left):
for f in columns:
colname1 = 'bf'+str(d)+'_'+'days'+f+'mean'
colname2 = 'bf'+str(d)+''+'days'+f+'_mean_diff'
df_feature_y[colname2] = df_feature_y[colname1].diff(1)
df_feature_y.loc[(df_feature_y.hour==0)&(df_feature_y.minute==0), colname2] = 0
4.stationID相关特征
主要来挖掘不同站点及站点与其它特征组合得热度,关键代码:
def get_stationID_fea(df):
df_station = pd.DataFrame()
df_station['stationID'] = df['stationID'].unique()
df_station = df_station.sort_values('stationID')
tmp1 = df.groupby(['stationID'])['deviceID'].nunique().to_frame('stationID_deviceID_nunique').reset_index()
tmp2 = df.groupby(['stationID'])['userID'].nunique().to_frame('stationID_userID_nunique').reset_index()
df_station = df_station.merge(tmp1,on ='stationID', how='left')
df_station = df_station.merge(tmp2,on ='stationID', how='left')
for pivot_cols in tqdm_notebook(['payType','hour','days_relative','ten_minutes_in_day']):
tmp = df.groupby(['stationID',pivot_cols])['deviceID'].count().to_frame('stationID_'+pivot_cols+'_cnt').reset_index()
df_tmp = tmp.pivot(index = 'stationID', columns=pivot_cols, values='stationID_'+pivot_cols+'_cnt')
cols = ['stationID_'+pivot_cols+'_cnt' + str(col) for col in df_tmp.columns]
df_tmp.columns = cols
df_tmp.reset_index(inplace = True)
df_station = df_station.merge(df_tmp, on ='stationID', how='left')
return df_station</code></pre></div></div><h3 id="bcstm" name="%E6%A0%B8%E5%BF%83%E6%80%9D%E8%B7%AFPart3-%E6%A8%A1%E5%9E%8B%E8%AE%AD%E7%BB%83&%E8%9E%8D%E5%90%88"><strong>核心思路Part3-模型训练&融合</strong></h3><p>模型训练方面我们主要有三个方案,分别是<strong>传统方案</strong>、<strong>平滑趋势</strong>和<strong>时序stacking</strong>。最后将这三个方案预测的结果根据线下验证集的分数进行加权融合。</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:56%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723331298568884404.jpeg" /></div></div></div></figure><p><strong>由于C榜分数得优越性,所以此处我们主要阐述C榜的方案。</strong></p><h4 id="1ira" name="1.%E4%BC%A0%E7%BB%9F%E6%96%B9%E6%A1%88"><strong>1.传统方案</strong></h4><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:46.56%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723331298978481817.jpeg" /></div></div></div></figure><p>由于C榜测试集为周内数据,所以我们移除了周末数据,保证分布基本一致,为了保持训练集的周期性,我们移除了周一和周二。这也作为我们最基本的方案进行建模。</p><h4 id="47h5f" name="2.%E5%B9%B3%E6%BB%91%E8%B6%8B%E5%8A%BF"><strong>2.平滑趋势</strong></h4><p>我们设计了一种处理奇异值的方法,也就是第二个方案平滑趋势。方案思想是,对于周内分布大体相同的日期,如果相同时刻流量出现异常波动,那么我们将其定义为奇异值。然后选取与测试集有强相关性的日期作为基准,比如C榜测试集为31号,那么选择24号作为基准,对比24号与其它日期的相对应时刻的站点流量情况。这里我们构造其它日期对应24号时刻流量的趋势比,根据这个趋势比去修改对应时刻中每个10分钟的流量。因为小时的流量更具稳定,所以根据小时确定趋势比,再修改小时内10分钟的流量。对流量进行修改后再进行传统方案的建模,这里我们回保留周一和周二的数据。</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723331299358643626.jpeg" /></div></div></div></figure><p><strong>具体步骤:</strong></p><ul class="ul-level-0"><li>删除周六周日</li><li>平滑24号之前日期对应24号的时刻流量趋势</li><li>常规训练</li></ul><p>下面将给出<strong>平滑趋势关键代码</strong>:</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0">if (test_week!=6)&(test_week!=5):
inNums_hour = data[data.day!=31].groupby(['stationID','week','day','hour'])['inNums' ].sum().reset_index(name='inNums_hour_sum')
outNums_hour = data[data.day!=31].groupby(['stationID','week','day','hour'])['outNums'].sum().reset_index(name='outNums_hour_sum')
# 合并新构造特征
data = data.merge(inNums_hour , on=['stationID','week','day','hour'], how='left')
data = data.merge(outNums_hour, on=['stationID','week','day','hour'], how='left')
data.fillna(0, inplace=True)
# 提取24号流量
test_nums = data.loc[data.day==24, ['stationID','ten_minutes_in_day','inNums_hour_sum','outNums_hour_sum']]
test_nums.columns = ['stationID','ten_minutes_in_day','test_inNums_hour_sum' ,'test_outNums_hour_sum']
# 合并24号流量
data = data.merge(test_nums , on=['stationID','ten_minutes_in_day'], how='left')
# 构造每天与的趋势
data['test_inNums_hour_trend'] = (data['test_inNums_hour_sum'] + 1) / (data['inNums_hour_sum'] + 1 )
data['test_outNums_hour_trend'] = (data['test_outNums_hour_sum'] + 1) / (data['outNums_hour_sum'] + 1)
if (test_week!=6)&(test_week!=5):
# 初始化新的流量
data['inNums_new'] = data['inNums']
data['outNums_num'] = data['outNums']
for sid in range(0,81):
print('inNums stationID:', sid)
for d in range(2,24):
inNums = data.loc[(data.stationID==sid)&(data.day==d),'inNums']
trend = data.loc[(data.stationID==sid)&(data.day==d),'test_inNums_hour_trend']
data.loc[(data.stationID==sid)&(data.day==d),'inNums_new'] = trend.values*(inNums.values+1)-1
for d in range(25,26):
inNums = data.loc[(data.stationID==sid)&(data.day==d),'inNums']
trend = data.loc[(data.stationID==sid)&(data.day==d),'test_inNums_hour_trend']
data.loc[(data.stationID==sid)&(data.day==d),'inNums_new'] = trend.values*(inNums.values+1)-1
for sid in range(0,81):
print('outNums stationID:', sid)
for d in range(2,24):
outNums = data.loc[(data.stationID==sid)&(data.day==d),'outNums']
trend = data.loc[(data.stationID==sid)&(data.day==d),'test_outNums_hour_trend']
data.loc[(data.stationID==sid)&(data.day==d),'outNums_online'] = trend.values*(outNums.values+1)-1
for d in range(25,26):
outNums = data.loc[(data.stationID==sid)&(data.day==d),'outNums']
trend = data.loc[(data.stationID==sid)&(data.day==d),'test_outNums_hour_trend']
data.loc[(data.stationID==sid)&(data.day==d),'outNums_new'] = trend.values*(outNums.values+1)-1
# 后处理
data.loc[data.inNums_new < 0 , 'inNums_new' ] = 0
data.loc[data.outNums_new < 0 , 'outNums_new'] = 0
data['inNums'] = data['inNums_new']
data['outNums'] = data['outNums_new']</code></pre></div></div><h4 id="btq28" name="3.%E6%97%B6%E5%BA%8FStacking"><strong>3.时序Stacking</strong></h4><p>因为历史数据中存在一些未知的奇异值,例如某些大型活动会导致某些站点在某些时刻流量增加,这些数据的影响很大,为了减小此类数据的影响,我们用了时序stacking的方式进行解决,如果模型预测结果和我们的真实结果相差较大,那么此类数据就是异常的,方案的可视化如下,通过下面的操作,我们线下和线上都能得到稳定的提升。</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:91.84%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723331299646351060.jpeg" /></div></div></div></figure><h4 id="5e0eo" name="4.%E6%A8%A1%E5%9E%8B%E8%9E%8D%E5%90%88"><strong>4.模型融合</strong></h4><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:63.14%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723331299976203803.jpeg" /></div></div></div></figure><p>三个方案各具优势,线下的表现的相关性也较低,经过过融合后线下的结果更加稳定,最终我们依线下CV的表现对其进行加权融合。</p><h3 id="27src" name="%E5%AE%9E%E9%AA%8C%E7%BB%93%E6%9E%9CPart4"><strong>实验结果Part4</strong></h3><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:91.84%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723331300144890854.jpeg" /></div></div></div></figure><p>A榜结果第一</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:91.84%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723331300413842739.jpeg" /></div></div></div></figure><p>BC榜综合考虑第二名</p><p>上面的代码我们在线上A榜取得了第一名的成绩。在BC榜去掉复现失败的队伍,我们也能取得第二的成绩。</p><h3 id="eiuvs" name="%E6%AF%94%E8%B5%9B%E7%BB%8F%E9%AA%8C%E6%80%BB%E7%BB%93"><strong>比赛经验总结</strong></h3><p><strong>1. 模型拥有较强的鲁棒性,在A榜取得了第一,BC榜综合成绩上第二</strong></p><p><strong>2. 设计了一种处理奇异值的方法, 线下线上都取得了一致的提升</strong></p><p><strong>3. 较为完备的时序特征工程 + 不同时段的数据选择</strong></p>