概述
随着微服务以及容器技术的发展,系统软件的构建方式也随之发生了改变,微服务调用关系错综复杂,传统的监控方案很难满足当下应用场景的需求,指标、链路追踪以及日志目前已经成为了云原生应用的“必备品”,当把它们集成在一起时,需要拥有一个更加成熟的现代化可观测体系来支撑,以便了解应用系统内发生的事情。通过可观测性体系的建立,我们可以更好的去洞察监控数据,从而能够更快速的做问题定界以及根因定位,降低 MTTR。
随着腾讯云的快速发展,越来越多的企业客户选择腾讯云作为其业务运行的基础设施。为了更好地满足客户需求,提升用户体验,腾讯云在应用性能监控(APM)方面持续发力,提供了全链路追踪功能。本文将分享腾讯云 APM 全链路追踪的落地实践,供您参考。
从监控到可观测的演进历程
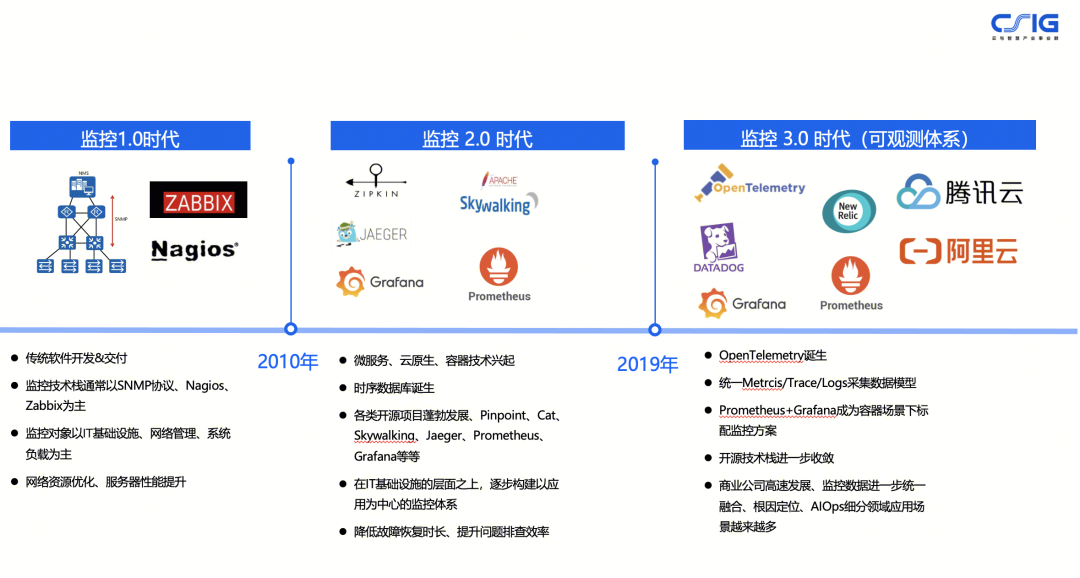
伴随着可观测体系的演进历程,全链路追踪的技术栈也得到了进一步的收敛,2019年 OpenTelemetry 诞生后统一了 Trace 模型,逐步成为全链路追踪领域的事实标准。
腾讯云的应用性能监控(APM)的全链路追踪能力,也是基于 OpenTelemetry 的标准上构建的,全面兼容开源标准,并且支持 OpenTelemetry、Jaeger、Skywalking、Zipkin 等多种 Trace 协议上报,且支持 Java、Python、PHP、Node.js 等多种语言的接入。
落地全链路追踪遇到的一些挑战
- 目前主流的 Trace 协议比较多,如 Skywakling、Zipkin 等都有不同的协议定义,腾讯云的应用性能监控(APM)做为商业化产品如何保证全面的兼容;
- 面对海量且重复的调用链数据,用户可能只对部分调用链感兴趣,如出错的调用链、慢的调用链,如何来提升调用链的存储价值;
- 字节码增强的方式进行埋点,仅仅能覆盖已知的三方组件,当业务代码出现性能问题时,已知的 Span 信息无法满足问题定位的需要。
主流 Trace 框架
基于 OpenTelemetry 开源标准实现并增强,全面兼容主流 Trace 框架。各主流 Trace 框架全链路调用时协议透传的主要 Key 定义
Zipkin | Jaeger | Skywalking | OpenTelemetry |
|---|---|---|---|
X-B3-TraceIdX-B3-SpanIdX-B3-ParentSpanIdX-B3-SampledX-B3-Flagsbaggage-key | uber-trace-idjaeger-baggage | sw8sw8-correlation | ot-tracer-Traceidot-tracer-spanidot-tracer-sampledot-baggage-key |
从上面的表格可以清晰的看到,不同的 Trace 框架的透传协议定义不同,这样就会导致在不同的 Trace 框架下的链路无法互通,腾讯云的应用性能监控(APM)支持以上不同的 Trace 协议数据上报,并在网关统一转换成 OpenTelemetry 标准的 Trace 数据后再进行预处理与存储。
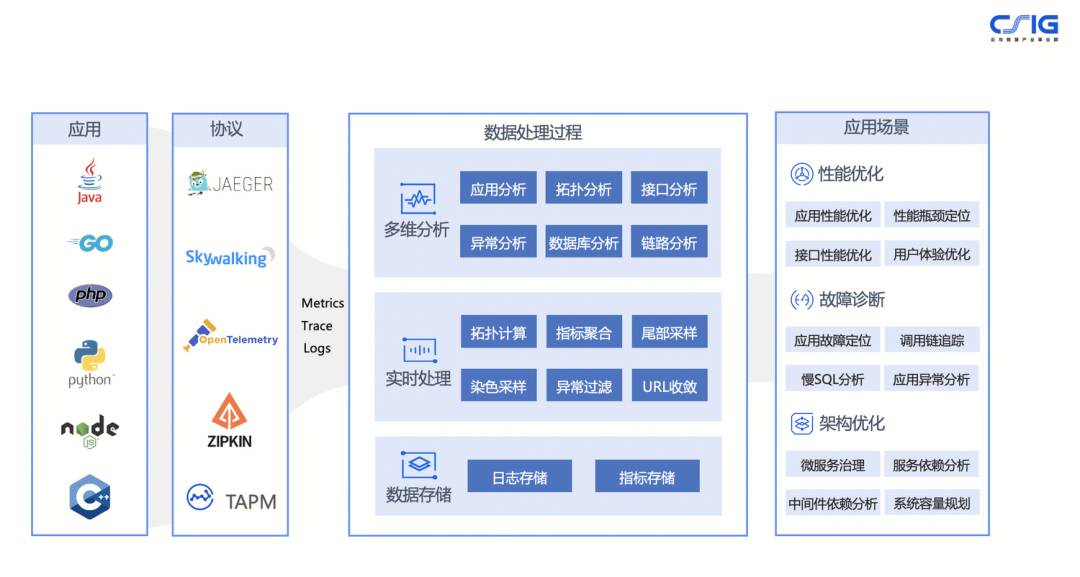
上面这张图是腾讯云应用性能监控(APM)的技术架构图,左侧是数据采集层,中间是数据处理层,最后侧是数据展示层。
数据采集层:一般会在采集侧部署一个或多个采集探针来收集这三类数据,可以是 Java 语言,也可以是非 Java 语言,在前面的章节中也提到过 Jaeger、Skywalking、Zipkin 等等这些开源项目,它们都有各自的协议标准。基于此的话我们一般会在网关侧去做数据格式的对齐,将 Jaeger、Skywalking、Zipkin 等不同的 Trace 协议转换成标准的 OpenTelemetry 格式,这样便于后续的统一模型存储及分析;
数据处理层:数据在网关侧被统一收集后,会经过中间的处理过程,这个过程可以对这些数据进行实时处理,包括对数据二次聚合、URL 收敛处理、尾部采样等等;
数据展示层:可以针对这些数据进行更多关联性的分析,比如慢 SQL 分析、异常分析、上下游调用的依赖分析等等,当然也可以构建一些 Profiling 的产品能力,提供一些原子化诊断工具,解决生产环境中常见的一些性能问题,比如 CPU 高的问题,内存溢出的问题等等,主要还是帮助我们的客户遇到问题时能够通过白屏化的方式做问题的定界与定位,提高问题排查的效率。
实现数据价值最大化
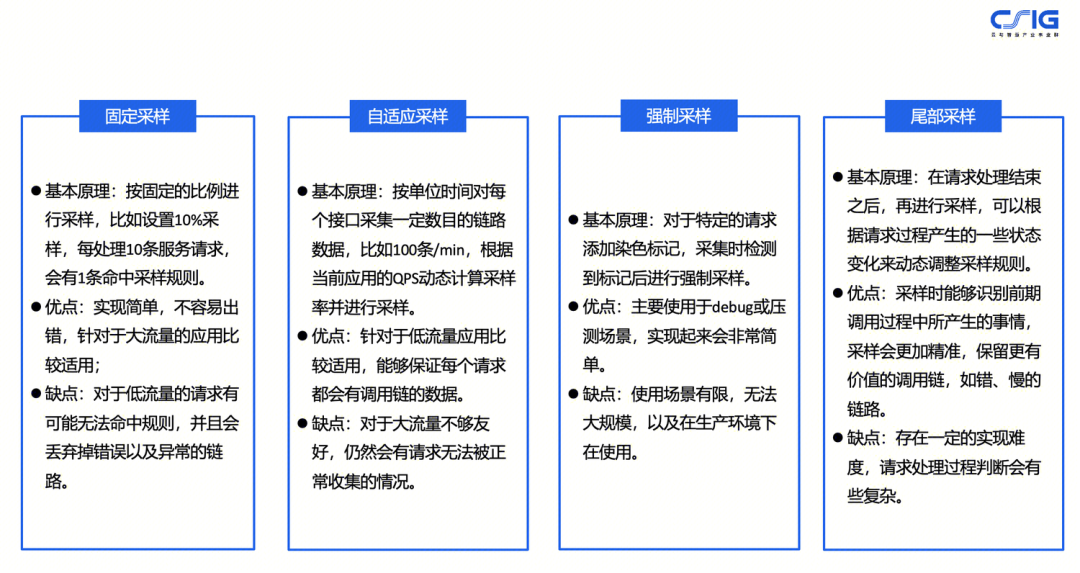
通过实现错、慢调用链路全采样,实现数据价值的最大化。下面介绍几种常见的调用链路采样策略,分别为固定采样、自适应采样、强制采样、以及尾部采样。
腾讯云应用性能监控(APM)作为腾讯云的云产品,既服务于外部公有云用户,同时也会服务于腾讯集团的内部用户;
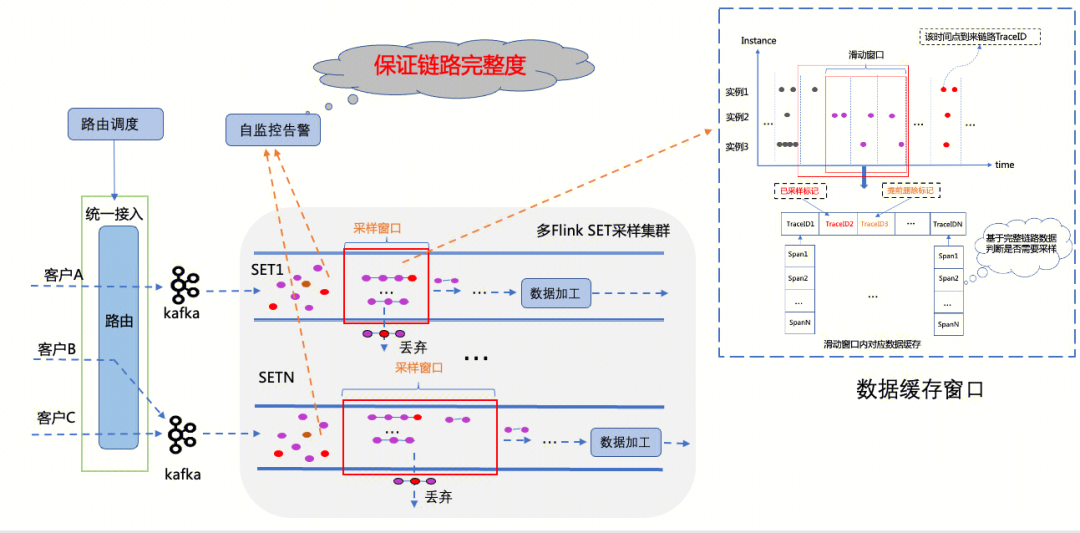
下面结合尾部采样的原理,为大家介绍一下在实际生产环境中通过尾部采样+滑动窗口的机制实现错、慢链路全采的技术方案。
通过采样数据窗口实现最少缓存
尾部采样依赖一个窗口来缓存等待一条完整链路数据,对于海量的监控数据上报场景,必然会产生大量的内存消耗,所以我们的窗口实现中要尽可能少的缓存数据。Flink 现有提供的窗口实现(如滚动窗口或回话窗口)并不能很好的满足我们的需要,我们最终选择了 Flink 所提供的低阶流处理算子 ProcessFunction 来实现我们的窗口。
业务上报的 Span 数据进过 Keyby(TraceID) 后,相同 TraceID 的数据会进入到一个窗口中,窗口中的数据什么时候会流入到下一个算子呢,有如下几个时机:
1. 这个链路第一个要采样的 Span 数据到来(已经知道这个链路数据要采样了),直接将缓存的所有数据发送给下游,并记录采样标记,同时后续到来的 Span 数据不缓存直接输出。
2. 到达窗口的截止时间:这条链路已到最大等待时间,直接输出。当我们知道这条链路是明确需要采样或丢弃的那一刻起,该条链路的数据就不再需要缓存了,从而尽可能减少窗口带来的资源消耗。
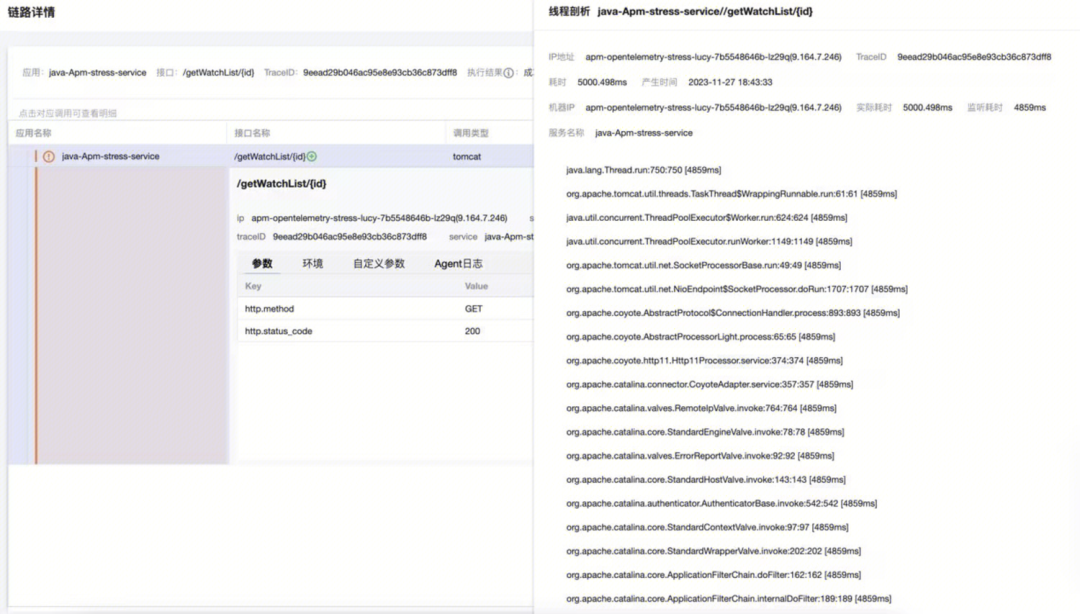
实现慢调用链路的快速定位
通过线程剖析填补调用空白,实现慢调用链路的快速定位
字节码插桩技术是 APM 类型产品常见使用的一种探针动态安装技术,能够实现在业务应用无需修改代码的场景下完成采集探针的安装;虽然字节码插桩可以提高程序监控的精度和细粒度,并且是零侵入的,但是在实际的应用过程中也存在一些弊端,比如字节码埋点主要关注程序的字节码级别信息,以及依赖的三方组件信息,精准度会有些损失,这样的话会导致在某些情况下无法获取到足够细粒度的跟踪数据,影响问题的定位与排查。
腾讯云应用性能监控(APM)的采集探针针对于 OpenTelemetry 进行了大量的二次开发与能力增强,不仅兼容了开源原生的采集能力,还能够针对一些慢调用的场景,自动抓取调用堆栈信息,从调用上下文中获取 TraceId 的信息,并与之进行关联形成信息互补,当遇到慢调用的场景时,能够通过调用链原始的 Span 信息,与调用堆栈信息结合,快速找到问题的性能瓶颈。
以上重点讲解的是结合腾讯云应用性能监控(APM)云产品落地全链路追踪体系的一些思考和技术方案,接下来介绍几种 APM 的最佳实践。
APM 最佳实践
- 实践1:从应用拓扑到调用链,实现链路的错、慢下钻分析。

从应用拓扑到调用链,实现链路的错、慢下钻分析,这是一个经典的使用可观测平台实现的产品能力,通过拓扑图可以看到有异常的应用信息,选中该应用之后,可以关联到调用链的明细的数据,在调用链的界面我们可以看到出现了慢的调用,或者是错误的调用,打开调用链的详情之后,可以进行下钻分析,看到此次调用的请求参数,以及调用堆栈和运行时产生的异常信息。
相同的应用场景,如果使用原始的排查方式的话,比较大概率会依赖应用的日志,如果应用日志没有输出请求的一些耗时信息的话,排查这种慢的问题还是比较花费时间的,基于可观测平台产品能力的话,基本上可以实现错、慢这类问题的分钟级定位效果了。
- 实践2:前后端打通,实现全链路互通及可观测闭环。
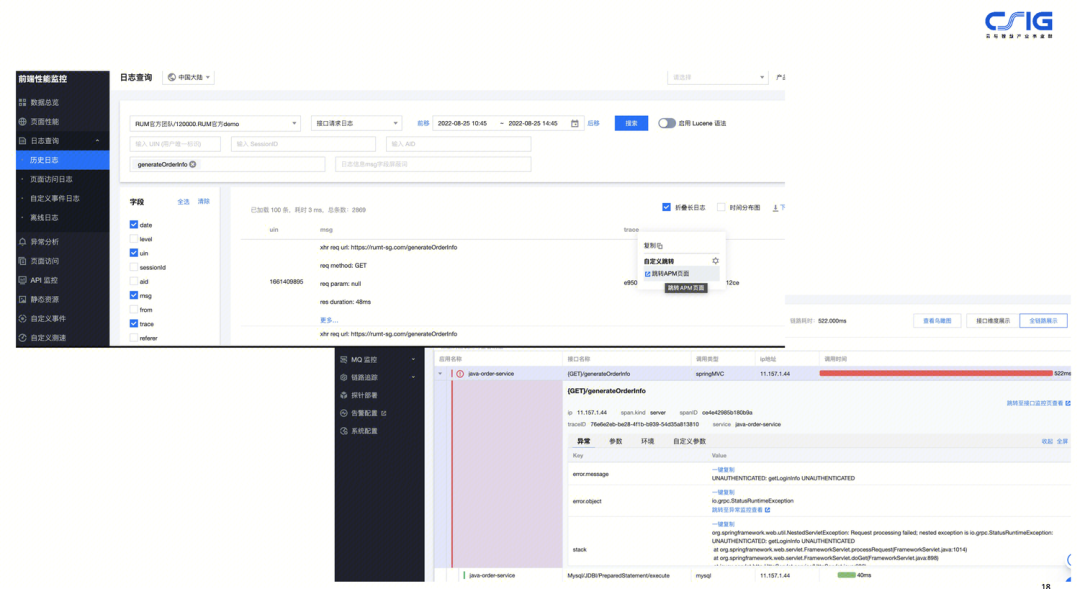
这个场景是一个全链路互通的场景,通过打通前后端的链路数据,实现调用过程的闭环。如果在前端浏览器,或者小程序侧作为第一跳产生这个 TraceId,那么就可以实现前后端的调用链的互通,在客户端的视角,就可以看到完整的服务端的调用过程。
当服务端出现异常导致前端调用失败时,站在客户端的视角,可以根据 TraceId,快速的找到服务端错误的原因。
- 实践3:结合应用日志,实现调用链与日志数据的自动关联
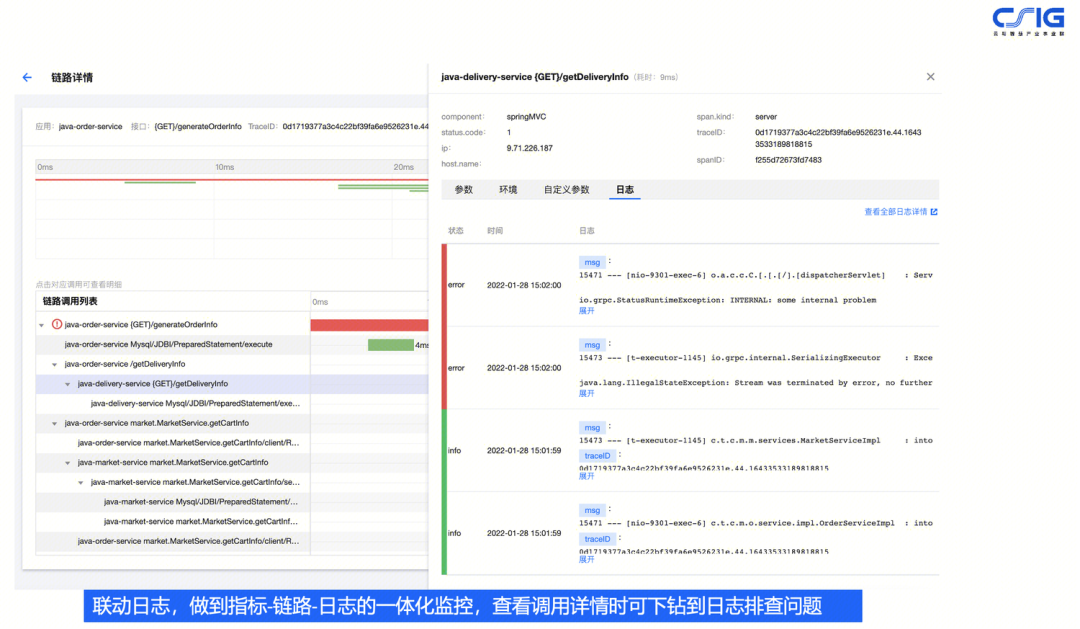
一般来讲我们会结合应用日志来实现调用链与日志数据的自动关联。比如说一个 Java 应用,在输出应用日志的时候会使用 Log4j,或者 Logback 组件来实现日志的输出,通过配置 log 的 pattern 模式,在 pattern 里面可以定义 TraceId 的属性;
采集的探针会自动拦截日志框架的输出日志时机,并从当前的上下文中获取到调用链的 TraceId,再放入到 MDC 里面,以此来实现应用日志里面输出 TraceId。当然不仅仅是 TraceId 可以输出,从上下文中获取到的调用链信息,比如交易流水号也是可以输出的。有了这个机制之后,可以结合实际的应用场景进行灵活的配置。
腾讯云可观测平台(TCOP) 全景图
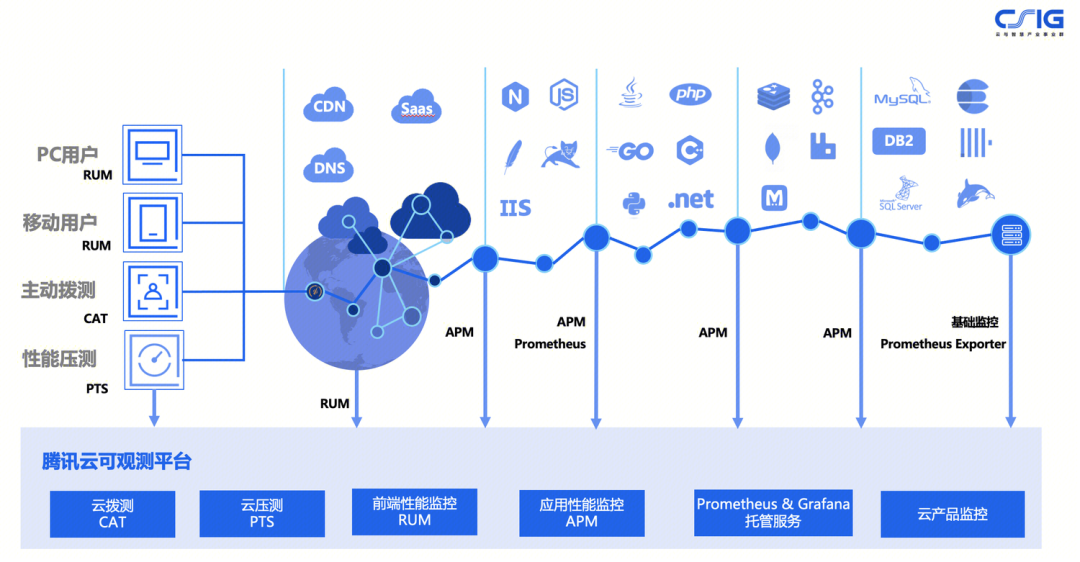
腾讯云可观测平台 (TCOP) 包含了云拨测 (CAT),云压测(PTS)、前端/终端性能监控 (RUM)、应用性能监控 (APM)、Prometheus & Grafana 服务、以及云产品基础监控等多个子产品,经过往几年产品的打磨与积累,在可观测领域已经形成了相对比较完整的产品矩阵,并且同时服务于腾讯集团内部和外部客户,逐步打造成一体化、高效能、低成本的可观测平台,且会进一步提升产品的被集成能力,能够更好被云服务使用者所集成,持续的为广大企业用户提供高质量的产品及服务,帮助更多的企业客户在日常系统能够借助可观测产品的力量,提升研发运维的效能管理,通过可观测的数据,实时发现系统的性能瓶颈,并且通过数据化的方式驱动企业内不同角色的协作与沟通,提升整体的企业运作效率,腾讯云可观测平台将会不断提供更多的优质产品与服务。
关于腾讯云可观测平台
腾讯云可观测平台(Tencent Cloud Observability Platform,TCOP)基于指标、链路、日志、事件的全类型监控数据,结合强大的可视化和告警能力,为您提供一体化监控解决方案。满足您全链路、端到端的统一监控诉求,提高运维排障效率,为业务的健康和稳定保驾护航。功能模块有:
- Prometheus 监控:开箱即用的 Prometheus 托管服务;
- 应用性能监控 APM:支持无侵入式探针,零配置获得开箱即用的应用观测能力;
- 云拨测 CAT:利用分布于全球的监测网络,提供模拟终端用户体验的拨测服务;
- 前端性能监控 RUM:Web、小程序等大前端领域的页面质量和性能监测;
- Grafana 可视化服务:提供免运维、免搭建的 Grafana 托管服务;
- 云压测 PTS:模拟海量用户的真实业务场景,全方位验证系统可用性和稳定性;
- ......等等
点击播放视频快速了解👇
👇点击阅读原文了解腾讯云可观测平台