
大数据文摘出品
作者:蒋宝尚
小伙伴们大家好呀~~用Numpy搭建神经网络,我们已经来到第三期了。第一期文摘菌教大家如何用Numpy搭建一个简单的神经网络,完成了前馈部分。第二期为大家带来了梯度下降相关的知识点。
这一期,教大家如何读取数据集,以及将数据集用于神经网络的训练,和上两期一样,这次依然用Numpy实现。在开始代码之前,文摘菌先带大家看看今天我们使用的数据集。
数据集介绍
数据集采用著名的MNIST的手写数据集。根据官网介绍,这个数据集有70000个样本,包括60000个训练样本,10000个测试样本。
数据集下载下来之后,文件分为4个部分,分别是:训练集图片、训练集标签、测试集图片、测试集标签。这些数据以二进制的格式储存。

其中,训练集图片文件的前16个字节是储存了图片的个数,行数以及列数等。训练集标签文件前8个字节储存了图片标签的个数等。测试集的两个文件同理。
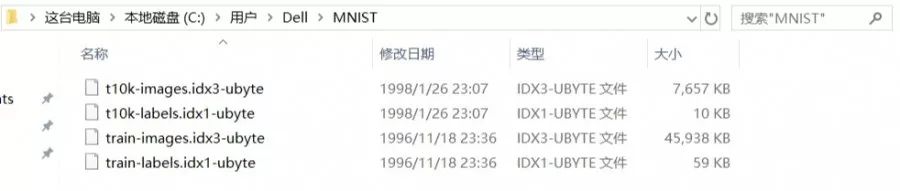
文摘菌下载好的文件存储地址
读取数据
train_img_path=r'C:\Users\Dell\MNIST\train-images.idx3-ubyte'
train_lab_path=r'C:\Users\Dell\MNIST\train-labels.idx1-ubyte'
test_img_path=r'C:\Users\Dell\MNIST\t10k-images.idx3-ubyte'
test_lab_path=r'C:\Users\Dell\MNIST\t10k-labels.idx1-ubyte'根据文件在本地解压后的储存地址,生成四个地址,上面代码中‘r’是转义字符,因为\在Python中有特殊的用法,所以需用转义字符明确文件地址。
为了让后面的模型表现更好,我们将训练集拆分,拆成50000个训练集和10000个验证集。
注:验证集是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。
import structtrain_num=50000
valid_num=10000
test_num=10000with open(train_img_path,'rb') as f:
struct.unpack('>4i',f.read(16))
tmp_img=np.fromfile(f,dtype=np.uint8).reshape(-1,28*28)
train_img=tmp_img[:train_num] #前五万个数据是训练集
valid_img=tmp_img[train_num:] #第五万到第六万个数据是测试集with open(test_img_path,'rb') as f:
struct.unpack('>4i',f.read(16))
test_img=np.fromfile(f,dtype=np.uint8).reshape(-1,28*28)with open(train_lab_path,'rb') as f:
struct.unpack('>2i',f.read(8))
tmp_lab=np.fromfile(f,dtype=np.uint8)
train_lab=tmp_lab[:train_num]
valid_lab=tmp_lab[train_num:]
with open(test_lab_path,'rb') as f:
struct.unpack('>2i',f.read(8))
test_lab=np.fromfile(f,dtype=np.uint8)
因为,文件是以二进制的格式储存,所以数据读取方式是‘rb’。又因为我们需要数据以阿拉伯数字的方式显示。所以这里用到了Python的struct包。struct.unpack('>4i',f.read(16))中的>号代表字节存储的方向,i是整数,4代表需要前4个整数。f.read(16)是指读取16个字节,即4个整数,因为一个整数等于4个字节。
reshape(-1,28*28):如果参数中存在-1,表示该参数由其他参数来决定.-1是将一维数组转换为二维的矩阵,并且第二个参数是表示每一行数的个数。
注:fromfile的用法np.fromfile (frame, dtype=np.float, count=‐1, sep=''),其中:frame : 文件、字符串。dtype :读取的数据类型。count : 读入元素个数,‐1表示读入整个文件。sep : 数据分割字符串。
文件读取完成,接下来按照用图片的方式显示数据。
import matplotlib.pyplot as plt
def show_train(index):
plt.imshow(train_img[index].reshape(28,28),cmap='gray')
print('label:{}'.format(train_lab[index]))
def show_test(index):
plt.imshow(train_img[index].reshape(28,28),cmap='gray')
print('label:{}'.format(test_lab[index]))
def valid_train(index):
plt.imshow(valid_img[index].reshape(28,28),cmap='gray')
print('label:{}'.format(valid_lab[index]))注意,如果不定义cmap='gray',图片的底色会非常奇怪。
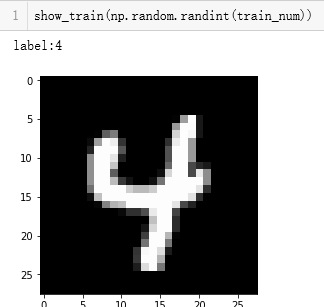
测试一下,定义完函数之后,显示的是这样的~
数据显示和读取完成,接下来开始训练参数。
训练数据
在开始之前,为了能够上下衔接,我们把第一次课程的代码贴上来~
def tanh(x): return np.tanh(x)def softmax(x):
exp = np.exp(x-x.max())
return exp/exp.sum()
dimensions = [28*28,10]
activation = [tanh,softmax]
distribution=[
{
'b':[0,0]
},{
'b':[0,0],
'w':[-math.sqrt(6/(dimensions[0]+dimensions[1])),math.sqrt(6/(dimensions[0]+dimensions[1]))]
}]初始化参数b
def init_parameters_b(layer):
dist = distribution[layer]['b']
return np.random.rand(dimensions[layer])*(dist[1]-dist[0])+dist[0]初始化参数w
def init_parameters_w(layer):
dist = distribution[layer]['w']
return np.random.rand(dimensions[layer-1],dimensions[layer])*(dist[1]-dist[0])+dist[0]#初始化参数方法
def init_parameters():
parameter=[]
for i in range(len(distribution)):
layer_parameter={}
for j in distribution[i].keys():
if j=='b':
layer_parameter['b'] = init_parameters_b(i)
continue;
if j=='w':
layer_parameter['w'] = init_parameters_w(i)
continue
parameter.append(layer_parameter)
return parameter预测函数
def predict(img,init_parameters):
l0_in = img+parameters[0]['b']
l0_out = activation0
l1_in = np.dot(l0_out,parameters[1]['w'])+parameters[1]['b']
l1_out = activation1
return l1_out
先定义两个激活函数的导数,导数的具体推到过程在这里不呈现,感兴趣的同学可以自行搜索。
def d_softmax(data): sm = softmax(data) return np.diag(sm)-np.outer(sm,sm)def d_tanh(data):
return 1/(np.cosh(data))**2
differential = {softmax:d_softmax,tanh:d_tanh}
其中tanh的导数 是np.diag(1/(np.cosh(data))**2),进行优化后的结果是1/(np.cosh(data))**2
注:diag生成对角矩阵 ,outer函数的作用是第一个参数挨个乘以第二个参数得到矩阵
然后定义一个字典,并将数解析为某一位置为1的一维矩阵
differential = {softmax:d_softmax,tanh:d_tanh}
onehot = np.identity(dimensions[-1])求平方差函数,其中parameters是我们在第一次课程定义的那个初始化的参数,在训练的过程中,会自动更新。
def sqr_loss(img,lab,parameters):
y_pred = predict(img,parameters)
y = onehot[lab]
diff = y-y_pred
return np.dot(diff,diff)计算梯度
def grad_parameters(img,lab,init_parameters):
l0_in = img+parameters[0]['b']
l0_out = activation0
l1_in = np.dot(l0_out,parameters[1]['w'])+parameters[1]['b']
l1_out = activation1
diff = onehot[lab]-l1_out
act1 = np.dot(differentialactivation[1],diff)
grad_b1 = -2act1
grad_w1 = -2np.outer(l0_out,act1)
# 与上文优化d_tanh有关,将矩阵乘法化为数组乘以矩阵
grad_b0 = -2differentialactivation[0]np.dot(parameters[1]['w'],act1)
return {'b1':grad_b1,'w1':grad_w1,'b0':grad_b0}这次的梯度计算公式用到了公式:(y_predict-y)^2,根据复合函数求导,所以有-2(y_prdict-y)乘以相关的导数,这也是grad_b1后面-2的来历。
按理说应该更加导数的定义[f(x+h)-f(x)]/h验证下我们的梯度求的对不对,为了照顾新手同学对神经网络的理解过程,这一步在这儿省略了哈。
下面进入训练环节,我们将数据以batch的方式输入,每个batch定位包含100个图片。batch_size=100。梯度的获取是用平均求得的,代码体现在:grad_accu[key]/=batch_size。
def train_batch(current_batch,parameters):
grad_accu = grad_parameters(train_img[current_batchbatch_size+0],train_lab[current_batchbatch_size+0],parameters)
for img_i in range(1,batch_size):
grad_tmp = grad_parameters(train_img[current_batchbatch_size+img_i],train_lab[current_batchbatch_size+img_i],parameters)
for key in grad_accu.keys():
grad_accu[key] += grad_tmp[key]
for key in grad_accu.keys():
grad_accu[key]/=batch_size
return grad_accu
import copy
def combine_parameters(parameters,grad,learn_rate):
parameter_tmp = copy.deepcopy(parameters)
parameter_tmp[0]['b'] -= learn_rategrad['b0']
parameter_tmp[1]['b'] -= learn_rategrad['b1']
parameter_tmp[1]['w'] -= learn_rate*grad['w1']
return parameter_tmp
采用copy机制,是避免parameters变化影响全局的训练,copy.deepcopy可以重新拷贝不影响原来的数据。
并且这里用到了公式:
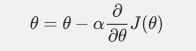
然后定义学习率:
def learn_self(learn_rate):
for i in range(train_num//batch_size):
if i%100 == 99:
print("running batch {}/{}".format(i+1,train_num//batch_size))
grad_tmp = train_batch(i,parameters)
global parameters
parameters = combine_parameters(parameters,grad_tmp,learn_rate)里面的if语句可以让我们看到神经网络训练的进度。

到这里,我们就完成了神经网络的一次训练,为了验证准确度如何,我们可以用验证集看看准确度如何。
定义验证集的损失:
def valid_loss(parameters):
loss_accu = 0
for img_i in range(valid_num):
loss_accu+=sqr_loss(valid_img[img_i],valid_lab[img_i],parameters)
return loss_accu计算准确度:
def valid_accuracy(parameters):
correct = [predict(valid_img[img_i],parameters).argmax()==valid_lab[img_i] for img_i in range(valid_num) ]
print("validation accuracy:{}".format(correct.count(True)/len(correct)))最后得到结果:
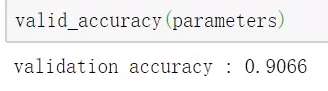
有90%的准确度哎~结果还好,还好,毕竟没有怎么调学习率以及解决过拟合。
好了,这一期的内容就到这了,内容有些多大家多多消化,下一期我们讲讲怎么调节学习率以及看看更复杂的神经网络。
*注:此篇文章受B站up主大野喵渣的启发,并参考了其代码,感兴趣的同学可以去B站观看他关于神经网络的教学视频,以及到他的Github地址逛逛。
视频地址与Github:
https://www.bilibili.com/video/av51197008
https://github.com/YQGong