前言:这篇文章是学习网络层协议时候总结的笔记,前面的主要部分介绍的都是IP协议, 后半部分介绍NAT协议和DHCP协议
参考书籍
《计算机网络-自顶向下》 作者 James F. Kurose
《图解TCP/IP》 作者 竹下隆史,荒井透, 刘田幸雄
《计算机网络技术基础教程》 作者 刘四清, 龚建萍 (教科书)
IP协议
IP地址的意义
IP地址是分配给每台主机或网络设备(路由器)的一个32位的二进制数字标识。
不过呢,上面的这个说法容易给我们带来一种错觉,就是: IP地址和主机或路由器是一一对应的关系。
但实际上,IP地址是由主机上的网卡(NIC)设置的(通常情况下,一个网卡只设置一个IP地址),所以
- 因为一个主机一般配置一个网卡,所以一般来说一个主机对应一个IP地址
- 因为一个路由器一般配置多个网卡,所以一般来说一个路由器对应多个IP地址
图示如下:
IP地址的结构
我们前面说过,IP地址是一个32位的二进制数字标识,但为了更好地为人们所接受,我们一般用点分十进制(dotted-decimal notation)的转化方式去表示它。
点分十进制: 将原来32位的IP地址每8位为1组,分成4组,中间用“.”隔开,然后将每组数转化为10进制数。
例子
10101100 00010100 00000001 00000001
加点分组得到:
10101100. 00010100. 00000001. 00000001
转化为10进制:
172.20.1.1
(以00010100转化为20为例,从右向左计算1 × 2^2 + 1 × 2^4 = 20 )
IP地址的总数量
因为IP地址有32位,由0或1的二进制数组成,所以一共有2^32 ≈ 43亿 个不同组成。也就是IP地址(IPv4)总量是43亿个左右。 这些IP地址在未来显然是不够用的(我们下面将介绍高效地使用IP的一些方法)
IP地址的组成
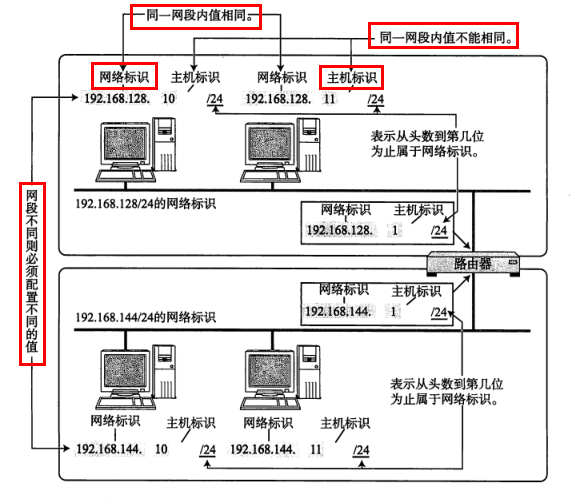
IP地址由“网络地址”(网络标识)和“主机地址”(主机标识)两部分组成
网络地址和主机地址的划分,使我们能够清晰地区分 [不同的网段] 和 [同一网段内的不同主机]
- 不同的网段的网络地址不同
- 对同一网段的不同主机IP,网络地址相同,主机地址不同
IP地址的分类
- IP地址的前5位用于标识地址的类型, 据此将IP地址划分为A类,B类,C类,D类和E类。如第一位为0代表A类地址,前两位为10代表B类地址,前三位为110代表C类地址
- A/B/C类地址叫做主类地址,为用户使用的地址。D/E类地址叫做次类地址。
- 如下图所示,可以看到从A ->B -> C ,在IP地址中, 主机地址所占位数越来越少,而网络地址所占位数越来越多。因此,从A到C,IP地址所能允许的网络数量越来越多, 而每个网络里所能容纳的主机数则越来越少。
【注意】IP地址前几位用于是标识IP类型的数字,IP地址也可以看作由三部分组成: 地址类型,网络地址和主机地址。

关于从A到C,IP地址所能允许的网络数量越来越多, 而每个网络里所能容纳的主机数则越来越少, 这一点做一个量化的描述:
- 使用A类地址的网络数上限126个(2^7 -2 = 126, 因为0和128两个地址有特殊作用), 每个网络能容纳主机数约为1700万个(2^24)。
- 使用B类地址的网络数上限1万6千个(2^14 = 16384), 每个网络能容纳主机数约为6万5千(2^16 = 65536)。
- 使用C类地址的网络数上限30万个(2^14 =297152), 每个网络能容纳主机数为256个(2^8)。
各类地址的特点
(1) A类 —— 主要用于拥有大量主机的网络,它的特点是网络数少而主机数多
(2) B类 —— 主要用于小型局域网络,它的特点是网络数和主机数大致相同(同一等级上)
(3) C类 —— 主要用于小型局域网络,它的特点是网络数多, 而主机数少
(4) D类 —— 主要用于已知的多点传送或组的寻址
(5) E类 —— 一个实验地址,保留给将来使用
子网和子网掩码
固定的IP分类的弊端
上面我们说到: 主类IP地址可以分为A,B,C类。 但这种固定的分类方式却导致了IP地址的浪费: 例如一个需要1万个IP地址的机构,若使用C类地址显然不能满足需要(使用C类地址的网络最多容纳256个主机)但使用B类地址则又造成了5.5万个IP地址的浪费!(使用C类地址的网络最多容纳6万5千个主机) IP地址的利用率将低于20%。
这时候,我们意识到一个问题: 我们需要细分出比A/B/C类更细粒度的网络, 而完成这项工作的,就是子网掩码。
子网掩码的作用
子网掩码的作用是屏蔽IP地址的一部分,从而更加灵活地指定网络地址的长度,实现网络地址和主机地址的进一步细分, 具体:
- 凡是IP地址的网络和子网地址部分, 用 1表示
- 凡是IP地址的主机地址部分, 用 0表示
如下图所示:

可以看到, IP地址172.20.100.52 原是个B类的地址, 网络地址的长度为14位,但经过子网掩码的作用,扩展为24位。 正因为子网掩码的作用,才能灵活地指定网络地址的长度,而不局限于A/B/C类的地址分类,从而提高IP地址的利用率
子网掩码的结构和表示方式
子网掩码是和IP地址结构相同的32位的二进制数字标识,也同样可以用点分十进制的方式表示
子网掩码有两种表示方式,例如以 172. 20. 100. 52为例
1. 将IP地址和子网掩码的地址分别用两行来表示

2. 在IP地址的后面追加网络地址的位数, 用 ”/“ 隔开

CIDR技术
CIDR是伴随着子网掩码出现的地址分配策略(Classless Interdomain Routing, CIDR)。
正如前面所提及的问题,直到20世纪90年代中期, 向各种组织分配IP地址都以A类,B类,C类等分类单位进行。对架构大规模网络的组织,一般会分配一个A类地址。反之,在架构小规模网络时候,则分配C类地址。然而A类地址的派发在全世界最多也无法超过128个,加上C类地址的主机标识最多只允许254台计算机相连, 这导致众多组织开始申请B类地址,结果是B类地址也开始严重缺乏。
于是乎, 人们开始放弃IP地址的分类, 而是采用任意长度分割IP地址的网络标识和主机标识。这种方式就是CIDR,即“无类型域间选路”
根据CIDR,连续多个C类地址就可以划分到一个较大的网络内,从而更有效地利用了当前的的IPv4地址,同时又通过路由集中降低了路由器的负担。

IP数据报格式(IPv4)
IP数据报的格式如图所示:

它的组成部分包括:
- 版本号
- 首部长度
- 服务类型(TOS)
- 数据报长度
- 标识,标志,片偏移
- 寿命
- 协议
- 首部检验和
- 源IP地址/目的IP地址
- 数据/有效载荷
版本号
这4比特规定了数据报的IP协议版本,目前使用的IP版本为IPv4
首部长度
因为一个IPv4的数据报包含一些可选项(包含在IP数据报的首部中),所以首部长度并不是固定的,所以我们需要用“首部长度”这4比特来确定数据报中的数据部分是从哪里开始的
服务类型
服务类型(TOS)用来使不同类型的IP的IP数据报(例如一些特别要求低时延,高吞吐量或可靠性的数据报)能互相区分开来。
数据报长度
这是IP数据报的总长度(首部加上数据), 以字节计
标识,标志,片偏移
该三个字段和IP分片有关(下面会细讲)
寿命
寿命(Time - To - Live, TTL)字段用来确保数据报不会永远在网络中循环(如由于长时间的选路循环) 每当数据报经过一台路由器时,该字段减1, 若TTL字段减为0 , 则该数据报必须丢弃。
协议
该字段仅在一个IP数据报到达其最终目的地时才会用到。该字段值指明了IP数据报的数据部分应该交付给哪个运输层协议。 例如值为6则表明数据部分要交给TCP, 值为17表明数据要交给UDP
首部检验和
首部检验和用于帮助路由器检测收到的IP数据报中的比特错误。首部检验和是这样计算的: 将首部中每两个字节当作一个数,用反码运算对这些数求和,这个和就叫做“检验和”,被存放在报文字段中。 同时,路由器会对每个接收到的IP数据报计算其首部检验和, 通过检查这两个检验和是否一致,来检查是否出现了错误
源IP地址/目的IP地址
当源主机产生一个数据报的时候, 它在源IP字段中插入它的IP地址,在目的IP地址字段中插入其最终目的地的地址
数据(有效载荷)
这是IP数据报最后的也是最重要的字段,大多数情况下,IP数据报中的数据字段含有要交付给目的地的运输层报文段(TCP或UDP),在少数情况下,也能承载其他类型的数据,例如ICMP报文。
IP数据报分片
分片的概念
数据报分片,就是路由器将一个较大IP数据报分成两个或更多较小的数据报发送, 这些被分割后的小数据报叫做片(fragment)
分片的原因
为什么要分片呢? 这要从最大传输单元(MTU, Maximum Transmission Unit)开始说起。
在OSI模型中,网络层是依靠链路层支撑的,每个IP数据报是封装在链路层帧中传输的。 所以IP数据报的字节长度受到链路层帧的承载能力的限制
一个链路层帧的最大传输单元, 叫做MTU。
下面是不同的链路层协议的MTU示例:

那么让我们考虑这样一个场景, 一个路由器连接了一个MTU为4352的FDDI和一个MTU只有1500的以太网。 假设一个数据报经由路由器从FDDI进入以太网,因为FDDI的MTU比较高, 使得IP数据报的字节长度可以达到4000多字节。
但当这个4000多字节的大数据报试图进入MTU=1500的以太网的时候, 这个大数据没办法在一个链路层帧内传输, 那该怎么办呢?

路由器将对这个大数据报进行分片, 分割成几个较小的数据报, 封装在以太网的链路层帧中传输。

分片和重新组装
有分必有合, 既然有分片, 那么当然也有重新组装的功能。
IP数据报的分片是由路由器完成的,而重新组装则是由分组最终到达的接收主机完成的,如下图所示

重新组装成功进行的依据——标志, 标识和片偏移
重新组装要怎样才能准确无误地完成呢? 从IP数据报的接收主机的角度,我们需要思考以下三个问题:
- 怎么识别哪些数据报是来源于同一个初始数据报?
- 怎么确定当前接收的数据报是初始数据报的最后一个片? (如何确定接收完成)
- 怎么确保接收的小数据报能够以正确的顺序组装?
完成这三个问题所对应的功能的, 就是我们前面所介绍的IP数据报的报文字段: 标识,标志,片偏移
标识
- 当发送主机创建一个数据报时, 发送主机会在该报文的标识字段中写入标识号, 标示号是一个每发送一次数据报就增加1的数字, 这为每个初始数据报提供了唯一标识
- 当路由器分片的时候,每个小数据报(片)的报文里除了附加初始数据报的源/目的主机地址外,还会附加初始数据报的标识号
对目的主机来说,接收到的数据报的标识相同,则它们都来源于同一个初始数据报,这样就解决了第一个问题
标志
在分片的时候,最后一个片的标志比特被设置为0, 而其他的片的标志比特被设置为1。这样,目的主机就可以知道它当前接收到的这个数据报到底是不是最后一个“片” (接收工作是否已经处理完毕)
这样就解决了第二个问题
片偏移
片偏移用来指定当前这个片应该被放置在原数据报的哪个位置,从而确保了组装的正确顺序, 这样就解决了第三个问题
下面是 标识,标志,片偏移的示范图:

DHCP协议
DHCP的全称是Dynamic Host Configuration Protocol, 即动态主机配置协议, 它的特点是能够自动设置IP地址,并实行统一的管理。
我们有两种为主机设置IP地址的方式:
- 管理员手动设置主机的IP地址
- 通过DHCP自动设置IP地址
DHCP的作用
DHCP是一种即插即用的协议(plug-and-play protocol)。实际上,我们在生活中经常享受着DHCP带来的便利:我们有时会携带笔记本电脑或手机到公共场所里例如图书馆,并且通过WiFi连上一个陌生的子网,但是我们并没有做重新为主机配置IP地址的工作!
假设没有DHCP的帮助:

而在DHCP的支持下:

DHCP服务器的工作流程
- DHCP服务器管理着一个包含一系列IP地址的地址池
- 每当一台新的主机加入时,DHCP服务器就从其当前可用地址池中分配一个任意的地址给它
- 而每当一台主机离开的时候,其IP地址就被回收到地址池中

NAT协议
要描述NAT协议, 要先从私有地址和全局地址说起
私有地址和全局地址
先让我们思考一下:主机的IP地址是否必须是唯一的呢?
1. 的确,在一开始的时候,任何一台主机或路由器都必须配有一个唯一的IP地址。
2. 但随着IP地址不足的问题日益显著, 人们对IP地址做了新的处理方式:
- 将IP地址分为私有IP地址和全局IP地址
- 全局IP地址必须是唯一的
- 私有IP地址不需要是唯一的,只要在同一个域里保持唯一便可,在不同域里可以重复
下图所示的是私有IP地址的范围(A/B/C类各有一段,共三段)

下图所示的是私有IP地址和全局IP地址的图解:

NAT定义
NAT(Network Address Translator)也即网络地址转换,是用于在本地网络中使用私有地址,在连接互联网时转而使用全局IP地址的技术。
NAT工作流程
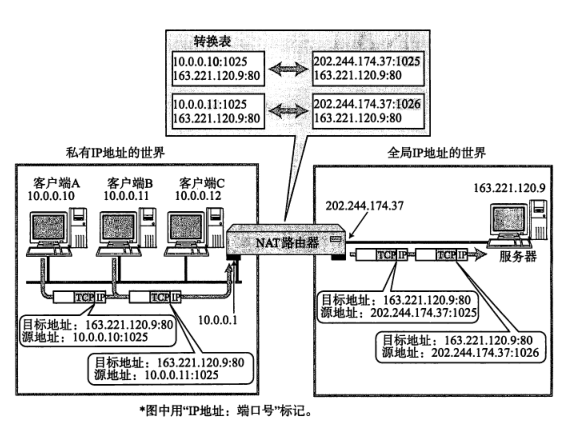
如下图所示, 以10.0.0.10的主机与163.221.120.9的主机的通信为例,利用NAT, 途中的NAT路由器将发送源地址从10.0.0.10转换为全局地IP地址(202.244.174.37)再发送数据。 反之,当包从地址163.221.120.9发过来时,目标地址(202.244.174.37)先被转换成私有IP地址10.0.0.10以后再被转发。

NAT作用机理
在NAT路由器内部, 有一张自动生成的用于转换地址的表, 当1.0.0.10向163.221.120.9发送第一个包的时候生成这张表,并且按照表中的映射关系进行处理。