1 简介
测试小姐姐正在对云原生的电商应用进行压测,但是如何对压测结果进行持续的观测呢?这一直是比较头痛的事情,本文将介绍如何利用 DeepFlow 的全景拓扑帮助小姐姐快速找到瓶颈点。DeepFlow 全景拓扑无需业务修改代码、配置或者重启服务,利用 BPF/eBPF 技术通过对业务零侵扰的方式构建而来,这是一种很便捷且低成本的方式来观测全链路压测的结果。
2 背景介绍
DeepFlow 在线的 Sandbox 环境中部署了一个云原生的电商应用,此电商应用来源于 GitHub[1],此应用覆盖 Go/Java/.NET/PHP/Python 等多种语言,且涵盖 Redis/Kafka/PostgreSQL 等中间件,所有的这些服务都部署在 K8s 环境中。在做全链路压测时,当前通常的方式需要对应用进行代码级别的改造,这对于仅负责测试的小姐姐来说又很难推动,接下来将详细介绍 DeepFlow 的全景拓扑如何轻松解决小姐姐的苦恼。
以下是电商应用微服务的调用关系图,提供了外网和内网访问的两种方式。
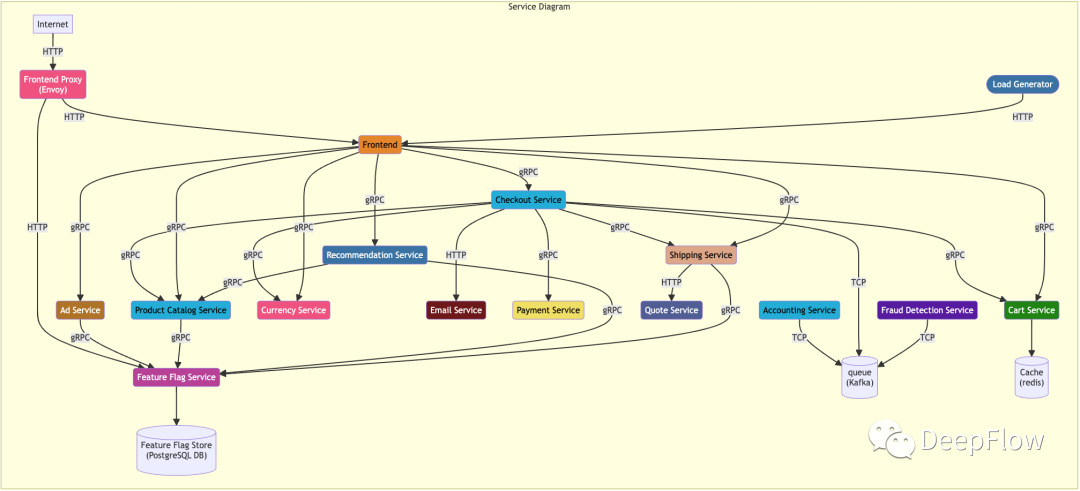
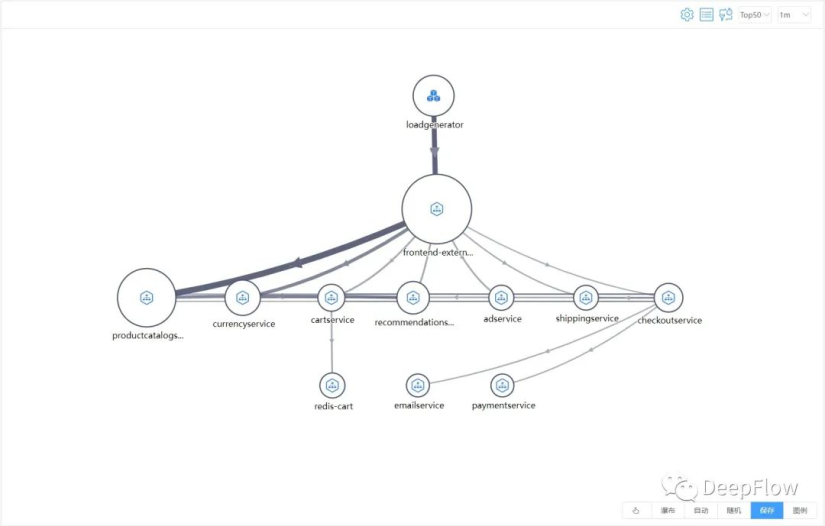
DeepFlow 的 Sandbox 考虑到安全性的问题,仅支持了内网的访问方式,以下是 DeepFlow 的全景拓扑自动绘制的调用关系,接下来的整个过程都将基于此拓扑进行。

DeepFlow 的全景拓扑可以与多指标进行结合,当指标量超过阈值时,则将通过标红的形式可视化出来。在开始接下来压测及调优过程之前,需要对本次过程中使用到的指标有一个了解。
指标 | 说明 | 观测目标 |
|---|---|---|
流量速率 | 作为主指标,构建全景拓扑 | -- |
应用请求速率 | 统计服务的请求速率,主要用于观测压测过程中请求量是否符合压测预期 | 符合测试压测的速率 |
应用异常个数 | 统计服务的异常个数,主要用于观测压测过程中是否存在服务异常的情况 | 0 |
应用响应时延 | 统计服务的响应时延,主要用于观测压测过程中响应时延是否超过预期 | 1s 以内 |
TCP 建连时延 | 统计 TCP 建连时延,主要用于观测压测过程中网络是否存在波动 | 10ms 以内 |
TCP 建连失败 | 统计 TCP 建连失败,主要用于观测压测过程中系统性能是否稳定 | 0 |
3 逐个击破性能瓶颈
在 loadgenerator 所在的 node,通过脚本模拟 1.5k 的并发访问量,观测全景拓扑,一片红(在当前并发量的情况下,观测的指标量都超过阈值了),说明了目前这个系统在当前资源分配情况下,是扛不住 1.5k 的并发访问量的。查看指标量,应用响应时延、异常数和网络建连时延、建连失败的指标量都远超阈值了。
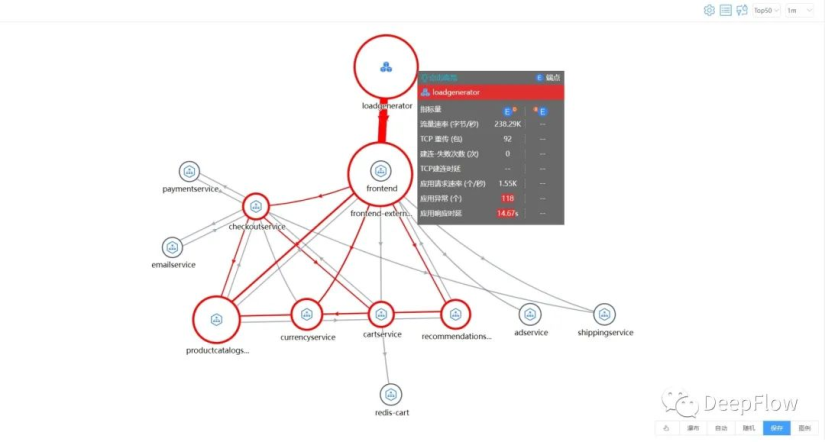
找一个指标量(服务响应时延)来层层追踪拓扑图,loadgenerator 访问 frontend 响应时延达到 15s,而 frontend 访问后端服务中,其中访问 productcatalog 及 recommendation 分别都消耗了大概 11s、5s 的时延,其中 productcatalog 没有继续往后的访问了,可继续追踪 recommendation 访问的后端,其中也是访问 productcatalog 消耗了大概 4s 的时延,到此基本能确定当前应用的性能瓶颈就在 productcatalog 上。
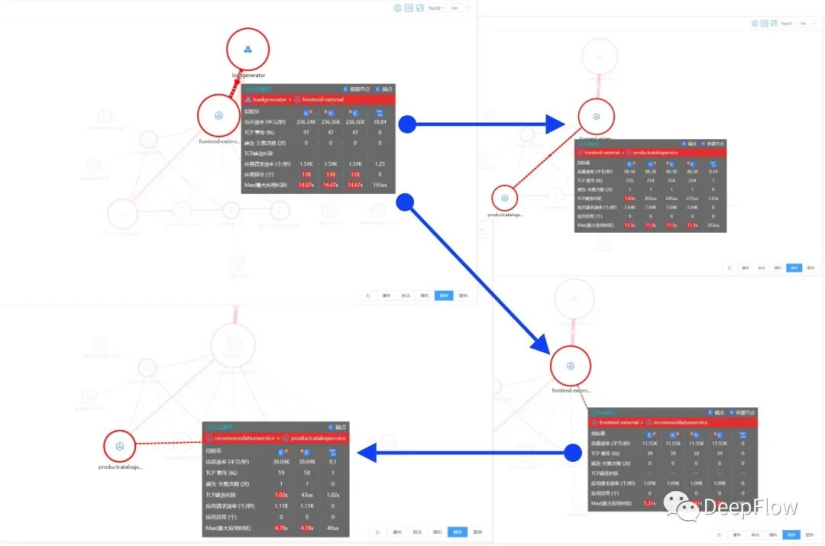
接下来先直接对 productcatalog 扩容,增加 pod 数量到之前的 1 倍,然后再观测下全景拓扑,可以看出来拓扑图上的红变少一些了,同时观测下指标量,发现应用的响应时延及异常数都降下来了。
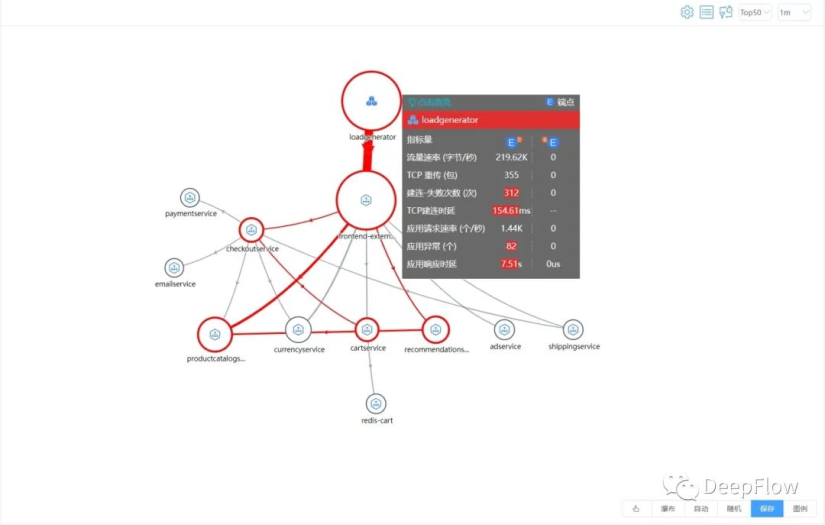
沿着前面的思路,依然使用服务响应时延来层层追踪拓扑图,发现通过扩容 1 倍的 POD 数,虽然缓解了 productcatalog 性能压力,但是还是没彻底解决。

接下来继续对 productcatalog 扩容,这次扩容到 2 倍,再观测全景拓扑,红色部分更少了,指标量也更接近预期了。不过这次发现解决了 productcatalog 的性能问题后,cart 的性能问题冒出来了。

继续对 cart 服务的 POD 的数量扩容 1 倍,观测全景拓扑,发现红色部分都没了。到此基本上可以出压测结果了,针对当前电商应用在 1.5k 的并发访问量的情况下,productcatalog 需要是比其他服务(除 cart 外) 2 倍的资源分配,cart 需要比其他服务(除 productcatalog 外) 多 1 倍的资源分配才能应对。
4 指标量分析
再结合历史曲线图,来详细分析下指标量的变化,让大家能更好的理解为什么应用的性能问题除了带来应用指标量的波动,为什么还会带了网络指标量的变化。明显在 17:48 分后端服务是整个处理不过来的,这时多个指标都能反应此情况。建连失败很多,在失败的过程中还不停的重传 SYN 报文,同时建连失败的都是因为服务端直接回 RST 导致,此时仅看这部分指标量已经能清楚是后端系统对连接处理不过来了。再继续结合应用指标量分析,在建连失败多的情况下,请求量反而下降了,这是因为建连都没成功,根本发不了请求,此时后端的异常数及响应时延也都是挺高,也是直接反应了后端对请求处理不过来了。

5 什么是 DeepFlow
DeepFlow[2] 是一款开源的高度自动化的可观测性平台,是为云原生应用开发者建设可观测性能力而量身打造的全栈、全链路、高性能数据引擎。DeepFlow 使用 eBPF、WASM、OpenTelemetry 等新技术,创新的实现了 AutoTracing、AutoMetrics、AutoTagging、SmartEncoding 等核心机制,帮助开发者提升埋点插码的自动化水平,降低可观测性平台的运维复杂度。利用 DeepFlow 的可编程能力和开放接口,开发者可以快速将其融入到自己的可观测性技术栈中。
GitHub 地址:https://github.com/deepflowio/deepflow
访问 DeepFlow Demo[3],体验高度自动化的可观测性新时代。
参考资料
[1] GitHub: https://github.com/open-telemetry/opentelemetry-demo
[2] DeepFlow: https://github.com/deepflowio/deepflow
[3] DeepFlow Demo: https://deepflow.io/docs/zh/install/overview/
https://deepflow.io:7788/blog/028-service_map_observation_performance_test/