陈云,数数科技资深云原生研发工程师,专注于云原生在大数据场景下的应用探索。负责数数科技TE(新一代数据分析引擎)的云原生方向架构建设、优化和迭代。
背景
ThinkingEngine (简称“TE”)新一代数据分析引擎,由数数科技研发,提供一站式的数据应用服务。让数据分析能够覆盖全品类分析场景,帮助游戏公司专注在游戏本身的业务上,更好地挖掘数据价值。
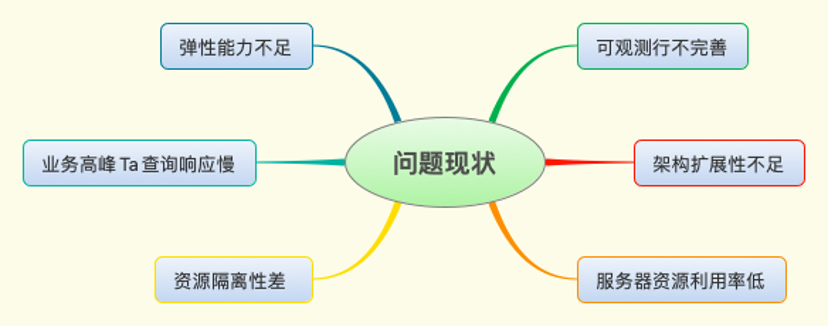
我们常常会收到客户的反馈:在业务高峰时容易出现分析查询慢和卡顿的情况。造成这种现象的原因是查询引擎在业务高峰时资源瓶颈,查询只能排队等待。用户也采取过增加资源的方式来缓解这一状况,但是由于架构的耦合性,很多程序部署相互依赖,扩展比较困难。这也会导致资源的利用率在业务低谷时非常低。
这种方式在一定程度上缓解了查询慢的问题,但是需要付出更多的人力和服务器成本。我们通过架构的演进实现按需弹性资源,增强架构的扩展性。在提高查询效率的同时平衡服务器成本。
设计思路
整体方案设计围绕Trino查询引擎资源瓶颈问题来展开,并且需要兼顾到服务器成本。让Trino的架构具备资源弹性能力,在业务高峰时动态弹性扩资源,在资源负载低时释放资源,做到动态按需按量使用资源。
现有的部署方式是同一个节点可能会部署多个程序。同节点和跨节点的程序与程序之间又相互有依赖关系,这对于架构的扩展非常难。想要实现查询引擎的弹性能力,在架构上就需要做一些调整。这里借鉴了一些微服务架构的设计方法。单一职责原则,服务化设计,程序独立运维部署。
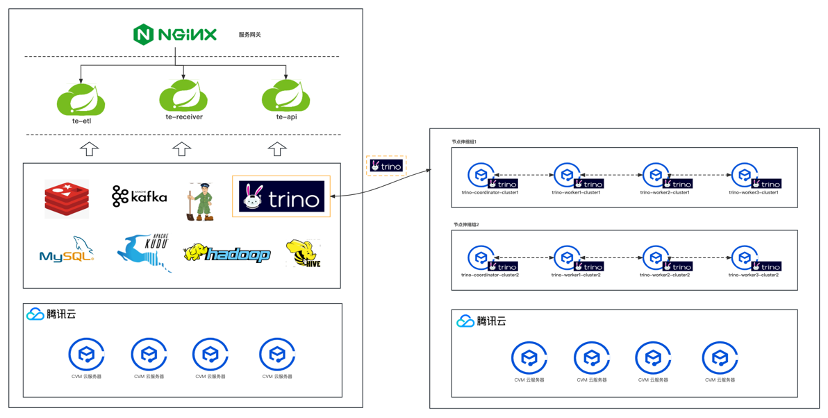
将Trino从原有的架构体系中分离出来,独立部署,独立维护和扩展。原有的架构通过配置切换即可使用到新的查询引擎的能力。新老查询引擎可以并存,按照架构实际使用效果逐步将老的查询引擎缩减直至完全下线,使Trino的计算资源具备弹性能力。
常见的方案如下两种( 以腾讯云平台为例 ):
节点伸缩组
节点维度来控制和管理计算资源,仍旧采用虚拟机部署的方式,利用云厂商的弹性能力实现按需弹性资源。
弹性容器
采用容器化部署,利用 Kubernetes HPA 的弹性伸缩能力来满足需求。
在腾讯云上的容器服务有两种:
TKE 普通节点
- 全场景适用,完全兼容开源 Kubernetes 集群标准能力
- 同时支持超级节点、原生节点、注册节点及 CVM
- 支持资源可视化及优化分析,轻松提升资源利用率
TKE Serverless模式
- 适用于高稳定性、高安全性常驻业务及临时计算任务
- 支持安全沙箱容器,业务容器强隔离,无互相干扰
- 可秒级启动上万 Pod,并按实际时长计费
节点伸缩组的优势在于架构简单,部署和维护方便。可以和现有的架构风格很好的兼容和融合(都是采用虚拟机的部署方式)。不足之处在于弹性的维度比较单一,只支持CPU或内存的指标进行弹性伸缩,且弹性效率不足,大概需要3min30s左右才能弹性好资源。
弹性容器云服务的优势在于可以无缝对接自动化CI/CD工具,可以更加细粒度、以更丰富的方式对资源进行调度和控制。k8s的HPA也很方便的支持多种类型的监控数据作为弹性指标,而且弹性速度也很快,可以较好地满足计算资源弹性需求。
我们是ToB的业务,服务器权限归属于用户。我们通常只能够通过有限的权限和访问路径帮助排查问题和更新、维护业务系统的版本内容,其中部署架构的简洁性也是一个重要参考维度。TKE Serverless模式刚好比较符合我们的期望。
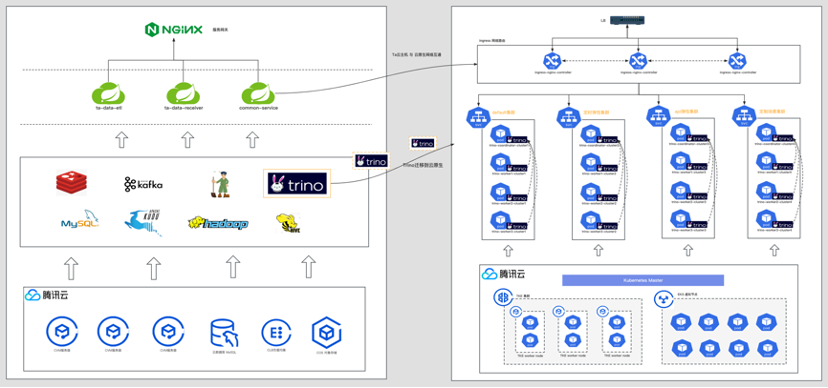
弹性能力的设计大体方向,是利用云厂商的Serverless容器服务作为基础设施,然后根据实际业务需求进行调整和设计。云原生的架构通常不是孤立的存在。把Trino从原有的架构体系中分离出来,使用云原生的方式重新设计,就必然需要把服务治理的内容给补全(服务网关、服务编排、监控、日志和配置等),这样查询引擎云原生化才能真正有效运行起来。
实现落地
总体方案包括CI/CD、容器编排、资源调度、服务治理和可观测性,以下为核心价值模块的展开介绍:
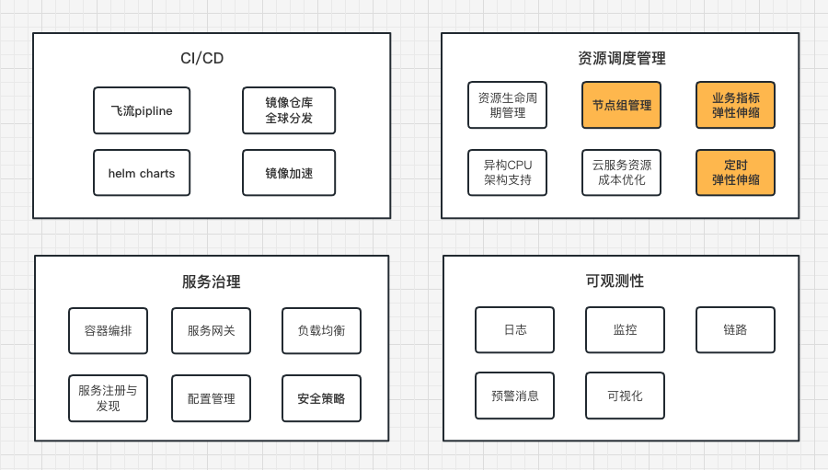
弹性容器资源
预期能通过自定义的监控数据作为弹性伸缩指标,在超过阈值时弹性资源副本,低于阈值时缩减资源数量。始终能确保资源是按需调度和分配的。
Kubernetes的HPA支持CPU和内存维度的监控数据作为弹性指标,但是对自定义弹性指标支持不太友好。而我们的实际场景需要根据一些特定的业务监控数据(例如 : 消息队列积压数、请求处理等待时间等)来触发扩缩。
为此,我们利用Kubernetes API Aggregator的特性,支持将第三方的服务注册到Kubernetes API。这样就实现了直接通过Kubernetes API访问到外部服务,外部服务作为数据源,就有了更好的灵活性和扩展性了。具体落地时我们使用prometheus作为监控数据源,prometheus-adapeter作为扩展服务注册到Kubernetes API。整体逻辑架构图如下:

我们使用了HPA和CronHPA相结合的方式来应对不同的场景。负载缓慢增长的场景使用HPA根据业务指标进行控制,而在瞬时高负载场景下使用CronHPA,根据业务繁忙与空闲规律,提前自动调度好资源。在业务高峰之前扩资源,在业务空闲时释放资源,CronHPA极大缩短了应用冷启动时间。
服务接入
Kubernetes抽象了一层网络供pod相互访问,外部无法访问。外部想要访问Kubernetes通常会采用NodePort、LoadBalancer和Ingress等方式。因为K8s Serverless云服务的特殊性,底层Kubernetes工作节点是封装屏蔽的,所以选择通过云服务LoadBalancer将所有的请求转发到ingress-nginx-controller,再通过 ingress配置具体的路由转发规则。
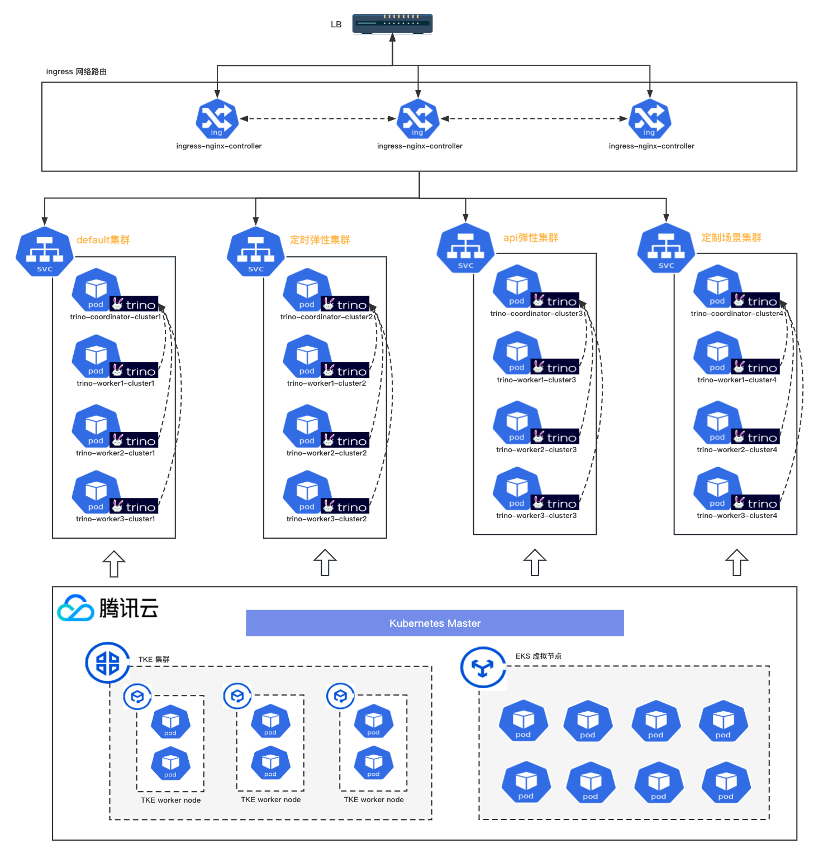
镜象仓库
镜像仓库的设计也是经历了三次改进,有很多问题无法提前预判,我们基本上是在实际的问题和场景中一步一步迭代演进的。私有镜像仓库设计的目的是确保国内和海外的客户,稳定且可靠的获取系统容器镜像。在维护和管理上能做到镜像统一分发和同步到多区域镜像仓库,对外提供统一的域名访问。
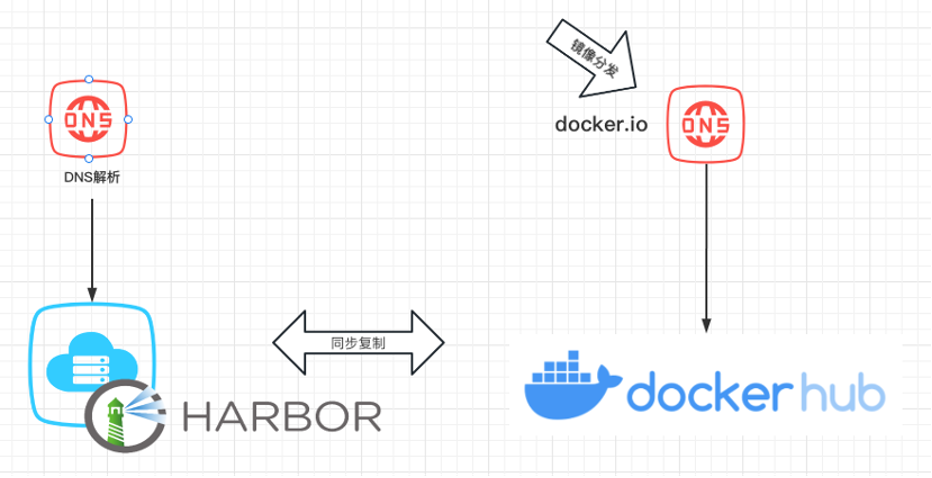
阶段一: 能提供基本的镜像分发能力
存在问题:
a) 海外获取镜像非常慢
阶段二: 国内和海外提供镜像分发能力,稳定运行了很长一段时间
也暴露了两个问题:
a) 国内访问DockerHub服务网络延时和不稳定,经常造成弹性容器无法顺利启动。
b) DockerHub 自身对镜像获取频次和速率有限制,超过阈值就会服务不响应。
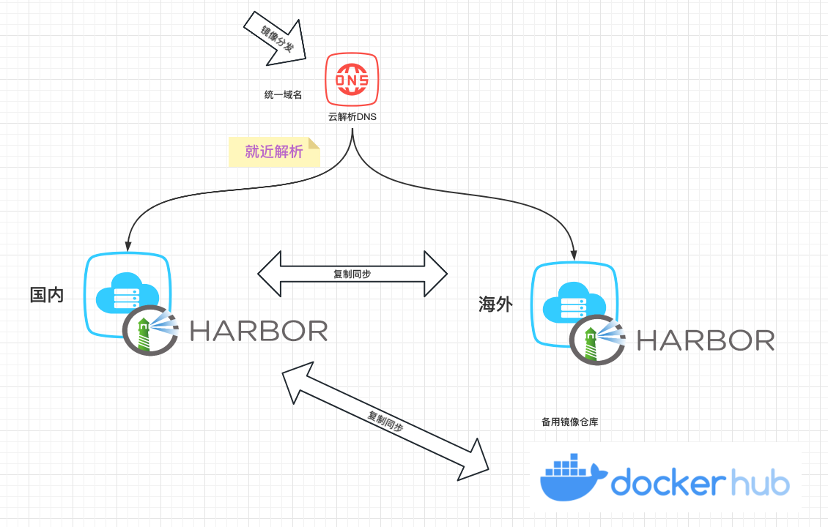
阶段三: 国内和海外提供稳定的镜像分发能力
a) DNS就近解析,国内解析到国内的镜像仓库,海外解析海外的镜像仓库
b) 镜像优先推送到国内仓库,然后由国内镜像仓库同步到海外和DockerHub
c) DockerHub依然保留作为备份,在异常时迅速切换使用
镜像加速
TKE Serverless 弹性资源非常快,但是Pod要消耗很长时间才能处于 Running 状态。我们排查了每个耗时环节发现,绝大部分的时间花在了 Trino 镜像获取上(大概耗时了3min左右)。Trino 镜像大概1.8G左右,在网络带宽不足时可能会消耗更多的时间。从外部来看就会发现弹性应用一直处于等待状态。用户可能需要等待很久,新弹性的应用才会处于 ready 状态,查询体验才会提升。
腾讯云上的镜像缓存云服务,刚好可以很好的应对大镜像获取问题。下面是一个 Trino worker Pod 部分启动事件消息。可以看到镜像已经存在无需重新拉取。

在使用过程中还遇到另一个问题,镜像缓存服务需要手动在云控制台配置,特别是每次镜像版本更新时都需要客户在控制台手动重建一次,整个过程非常麻烦。我们的ToB业务,对客户采用的是私有化部署,这给我们升级维护管理造成了很多不便。腾讯云容器团队,在接收到我们的需求之后,迅速协调研发资源,推出imc镜像加速组件,采用imc组件来实现对镜像缓存的版本管理,镜像缓存版本更新也集成到了自动化部署流程中,非常好地解决我们ToB业务私有化部署的痛点。
节点组
如果对不同业务场景和资源使用方式,采用同一种管理方式,可能会造成资源调度的灵活性不足,扩展难和资源浪费等问题。我们在设计时抽象一层节点组来管理不同类型的资源。节点组维度配置资费模式(包年包月/按量计费/Spot竞价实例)、资费规格、芯片架构和区域,整合了云平台中多种实例类型,根据应用的特性调度不同类型的资源。所有节点组都会被统一管理,根据业务场景、资源规模进行调整优化。在应用性能和服务器成本之间达成一个平衡。
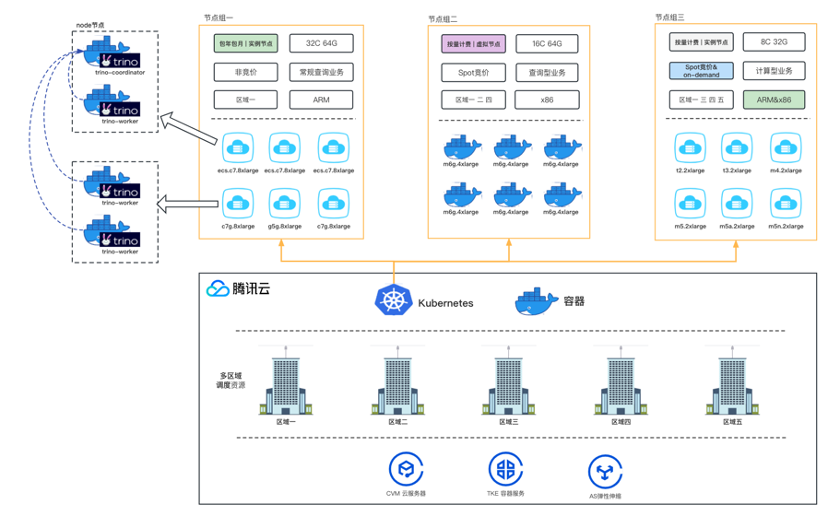
(1) 多种实例规格型号混用
云厂商提供的资源规格非常丰富,但是要合理搭配和使用才能花更小的成本产生更大的价值。得益于Kubernetes强大的兼容性和适配性。节点组可以让各种架构、厂商、规格、型号和版本的资源并存。不同的业务应用调度分配适合的资源类型。
比如有一些常规应用希望使用x86的服务器,而另外一些查询型应用希望使用ARM的服务器,并希望在同一套架构混合使用。通常来说ARM的服务器要比X86便宜约10%。而另外一些对安全和性能要求苛刻的应用,可以独立分配适量的资源。
(2) 资费模式混合
同一套架构为不同类型和使用场景的资源配置差异化的资费模式。例如,常驻留资源使用包年包月,弹性资源使用按量计费模式。程序的不同特性也可以选择是否采用Spot竞价模式。
(3) 多区域调度资源
同一个区域可能会出现特定型号资源存量不足,导致无法申请到资源。Trino云原生方案结合云服务功能打通各区域网络,将资源统一调度和使用整合到一个Kubernetes集群中。这样可以大幅提高资源申请成功率,确保在业务高峰时有充足的资源可供使用。
成本优化的思考
云厂商的资源使用资费模式有很多种类型(包年包月 / 按量计费 / Spot竞价实例 / 预留实例券 / 节省计划)。根据业务实际需求和场景综合使用可以节省比较多成本。
长驻留资源比较适合包年包月,弹性资源部分因为是只在高负载时按需使用,尽可能地使用按量计费模式。但是如果在按量计费模式下,每天时间超过8h,则需要重新计算成本。相同资源规格和使用时长计算的资费成本,按量计费比包年包月要贵一些。如果业务运行实例是无状态且偶发的,中断对业务的影响可以忽略,则可以使用Spot竞价实例模式。竞价计费模式通常比正常的资费要便宜很多,最低可达1折。如果能利用好这种计费模式,节省的服务器成本将相当可观。
利用节点组概念,来区分不同的资费类型。将不同的应用调度到不同的节点组。产生的资费也是按照不同节点组的实际使用情况来计算的。多种资源模式混合使用,将最大化地优化成本结构。

后续演进方向
目前的方案基本满足了大数据查询引擎资源弹性的诉求。不过也还面临着一些问题和挑战。
资源配置稳定性
Kubernetes 通过 HPA 来控制资源的弹性伸缩,如果配置不合理,很容易造成Pod的资源频繁的申请和释放。这会造成一定数量的中间态 Pod Terminating,导致整体架构的不稳定性。后续我们也将在资源控制的精确度上精进,让资源调度更加平稳顺滑,确保资源的生命周期管理有序、有效且合理。
业务价值
在上线云原生方案后基本实现了在业务上的资源隔离,多业务并行运行相互不影响。也可以很方便地支持更多业务和个性化需求的扩展。云原生方案的弹性伸缩能力,可以保证资源的按需使用。在月度硬件成本上下降了40%左右,服务的查询响应速度也提升50%左右。整个运维和治理过程也大大简化,方便后续的维护和管理。
后记
在架构的调研演进时,肯定会碰到各种各样的问题。保持心态的开放,加强与云厂商技术人员的沟通,不断拓展技术的边界,就能够不断深化解决方案的成熟度和完备性。在此,也要感谢腾讯云容器团队的大力支持。同时,对待未知、有待探索的技术领域,实践永远是验证想法和方案的唯一道路。我们一直在不断地探索和创新,期待与更多技术伙伴的交流和学习。

