
自研 AngelPTM 大模型训练框架上线公有云,助力降本增效
最近 ChatGPT 凭借其强大的语言理解能力、文本生成能力、对话能力等在多个领域均取得了巨大成功,掀起了新一轮的人工智能浪潮。ChatGPT、GPT3、以及 GPT3.5 都是基于 Transformer 架构堆叠而成,研究发现随着训练数据量和模型容量的增加可以持续提高模型的泛化能力和表达能力,研究大模型成为了近两年的趋势。国内外头部科技公司均有布局,发布了若干千亿规模以上的大模型,如下图所示:
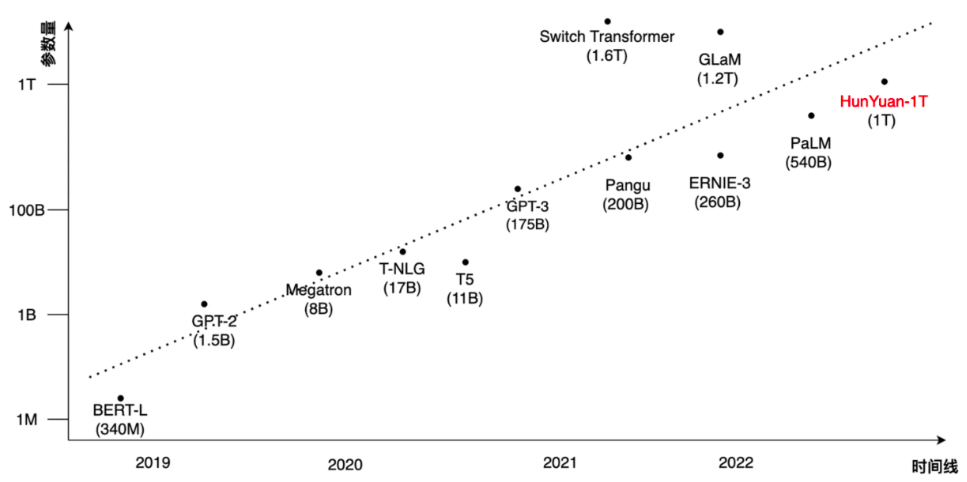
近几年 NLP 预训练模型规模的发展,模型已经从亿级发展到了万亿级参数规模。具体来说,2018 年 BERT 模型最大参数量为3.4亿,2019 年 GPT-2 为十亿级参数的模型。2020 年发布的百亿级规模有 T5 和 T-NLG,以及千亿参数规模的 GPT-3。在 2021 年末,Google 发布了 SwitchTransformer,首次将模型规模提升至万亿。然而 GPU 硬件发展的速度难以满足 Transformer 模型规模发展的需求。近四年中,模型参数量增长了十万倍,但 GPU 的显存仅增长了4倍。

举例来说,万亿模型的模型训练仅参数和优化器状态便需要 1.7TB 以上的存储空间,至少需要 425 张 A100-40G,这还不包括训练过程中产生的激活值所需的存储。在这样的背景下,大模型训练不仅受限于海量的算力, 更受限于巨大的存储需求。
业内大模型预训练的解决方案主要包括微软的 DeepSpeed 和英伟达的 Megatron-LM。DeepSpeed 引入 ZeRO(Zero Redundancy Optimizer )优化器,将模型参数、梯度、优化器状态按需分配到不同的训练卡上,满足大模型对存储的极致要求;Megatron-LM 基于3D并行(张量并行、流水并行、数据并行)将模型参数进行切分,满足大模型在有限显存资源下的训练诉求。
腾讯内部也有非常多的大模型预训练业务,为了以最小的成本和最快的性能训练大模型,太极机器学习平台对 DeepSpeed 和 Megatron-LM 进行了深度定制优化,推出了 AngelPTM 训练框架。2022 年 4 月腾讯发布的混元 AI 大模型便是基于 AngelPTM 框架训练而来。鉴于最近大模型的火热趋势,我们决定将内部成熟落地的 AngelPTM 框架推广给广大公有云用户,帮助业务降本增效。
AngelPTM 技术原理简介
ZeRO-Cache 优化策略
ZeRO-Cache 是一款超大规模模型训练的利器,如下图所示,其通过统一视角去管理内存和显存,在去除模型状态冗余的同时扩大单个机器的可用存储空间上限,通过 Contiguous Memory 显存管理器管理模型参数的显存分配/释放进而减少显存碎片,通过多流均衡各个硬件资源的负载,通过引入 SSD 进一步扩展单机模型容量。
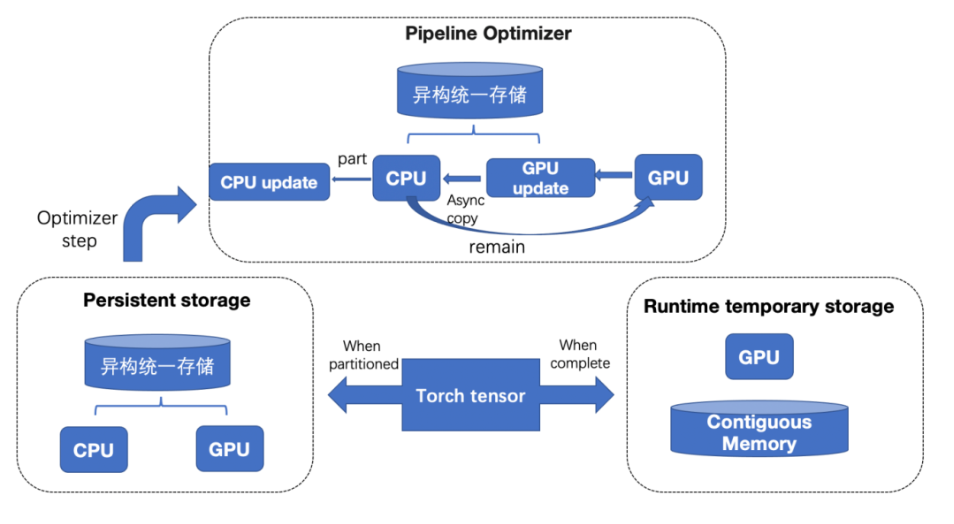
ZeRO-Cache概图
统一视角存储管理
大模型训练时模型状态都位于 CPU 内存中,在训练时会拷贝到 GPU 显存,这就导致模型状态的冗余存储(CPU 和 GPU 同时存在一份),此外大模型的训练中会用到大量的 pin memory,pin memory 的使用会提升性能,但同时也会导致物理内存的大量浪费,如何科学合理的使用 pin memory 是 ZeRO-Cache 着重要解决的问题。
本着极致化去冗余的理念,AngelPTM 引入了 chunk 对内存和显存进行管理,保证所有模型状态只存储一份,通常模型会存储在内存 or 显存上,ZeRO-Cache 引入异构统一存储,采用内存和显存共同作为存储空间,击破了异构存储的壁垒,极大扩充了模型存储可用空间,如下图左图所示:
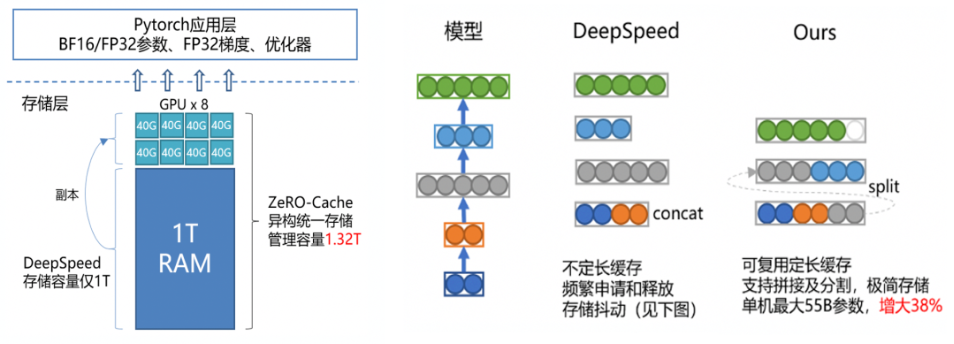
统一视觉存储管理
在 CPU 时原生 Tensor 的底层存储机制对于实际占用的内存空间利用率极不稳定,对此问题 AngelPTM 实现了 Tensor 底层分片存储的机制,在极大的扩展了单机可用存储空间的同时,避免了不必要的 pin memory 存储浪费,使得单机可负载的模型上限获得了极大提升,如上图右图所示。
ZeRO-Cache 显存管理器
PyTorch 自带的显存管理器可以 Cache 几乎所有显存进行二次快速分配,在显存压力不大的情况下这种显存分配方式可以达到性能最优,但是对于超大规模参数的模型,导致显存压力剧增,且由于参数梯度频繁的显存分配导致显存碎片明显增多,PyTorch Allocator 尝试分配显存失败的次数增加,导致训练性能急剧下降。
为此,ZeRO-Cache 引入了一个 Contiguous Memory 显存管理器,如下图所示,其在 PyTorch Allocator 之上进行二次显存分配管理,模型训练过程中参数需要的显存的分配和释放都由 Contiguous Memory 统一管理,在实际的大模型的训练中其相比不使用 Contiguous Memory 显存分配效率以及碎片有显著提升,模型训练速度有质的飞越。
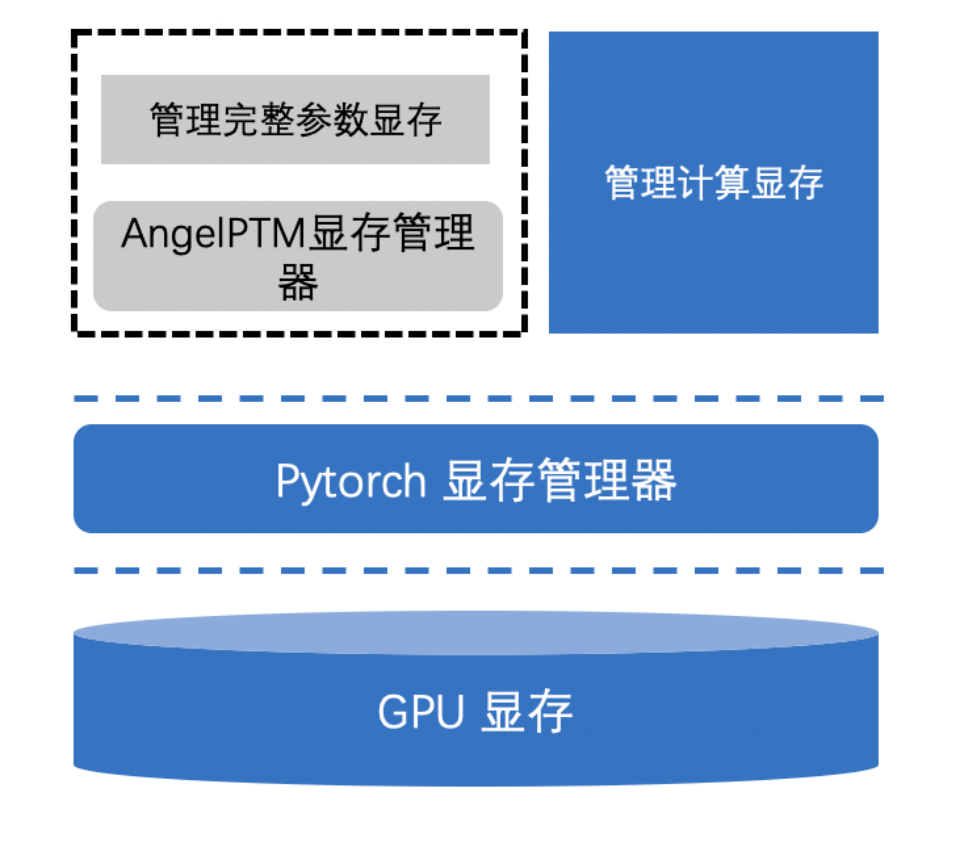
ZeRO-Cache 显存管理器
PipelineOptimizer
ZeRO-Infinity 利用 GPU 或者 CPU 更新模型的参数,特别是针对大模型,只可以通过 CPU 来更新参数,由于 CPU 更新参数的速度相比 GPU 更新参数有数十倍的差距,且参数更新几乎可以占到整个模型训练时间的一半,在 CPU 更新参数的时候 GPU 空闲且显存闲置,造成资源的极大浪费。
如下图所示,ZeRO-Cache 会在模型参数算出梯度之后开始 Cache 模型的优化器状态到 GPU 显存,并在参数更新的时候异步 Host 和 Device 之间的模型状态数据传输,同时支持 CPU 和 GPU 同时更新参数。ZeRO-Cache pipeline 了模型状态 H2D、参数更新、模型状态 D2H,最大化地利用硬件资源,避免硬件资源闲置。
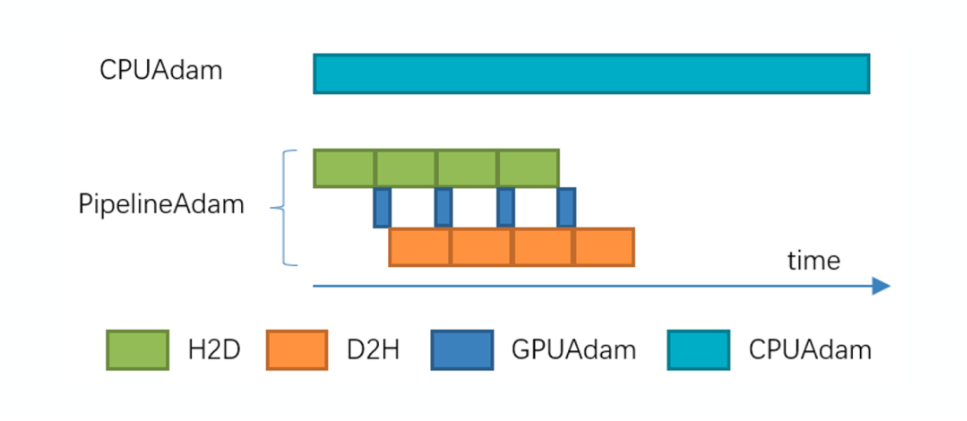
PipelineAdam
此外,AngelPTM 自研了异构 Adafactor 优化器,如下图所示,支持 CPU 和 GPU 同时进行参数的更新,其可以减少 33% 的模型状态存储空间,同时可提高模型训练精度。

异构Adafactor
多流异步化
大模型训练过程中有大量的计算和通信,包括 GPU 计算、H2D 和 D2H 单机通信、NCCL 多机通信等,涉及的硬件有 GPU、CPU、PCIE 等。如下图所示,ZeRO-Cache 为了最大化地利用硬件,多流异步化 GPU 计算、H2D 和 D2H 单机通信、NCCL 多机通信,参数预取采用用时同步机制,梯度后处理采用多 buffer 机制,优化器状态拷贝采用多流机制。

多流计算通信
ZeRO-Cache SSD 框架
为了更加低成本地扩展模型参数,如下图所示,ZeRO-Cache 进一步引入了 SSD 作为三级存储,针对 GPU 高计算吞吐、高通信带宽和 SSD 低 PCIE 带宽之间的 GAP,ZeRO-Cache 放置所有 fp16 参数和梯度到内存中,让 foward 和 backward 的计算不受 SSD 低带宽影响,同时通过对优化器状态做半精度压缩来缓解 SSD 读写对性能的影响。
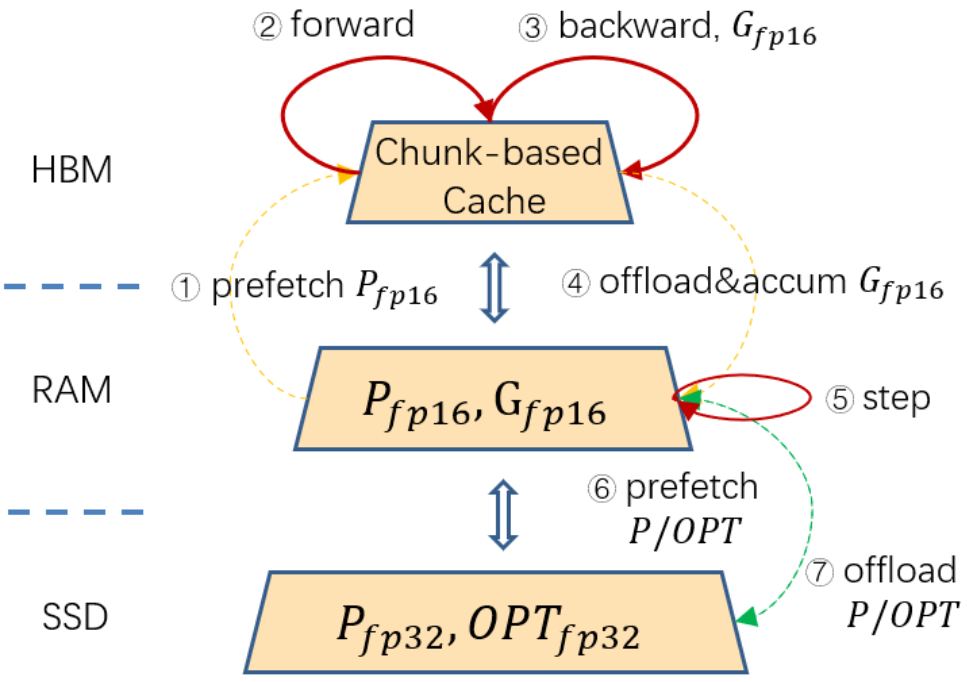
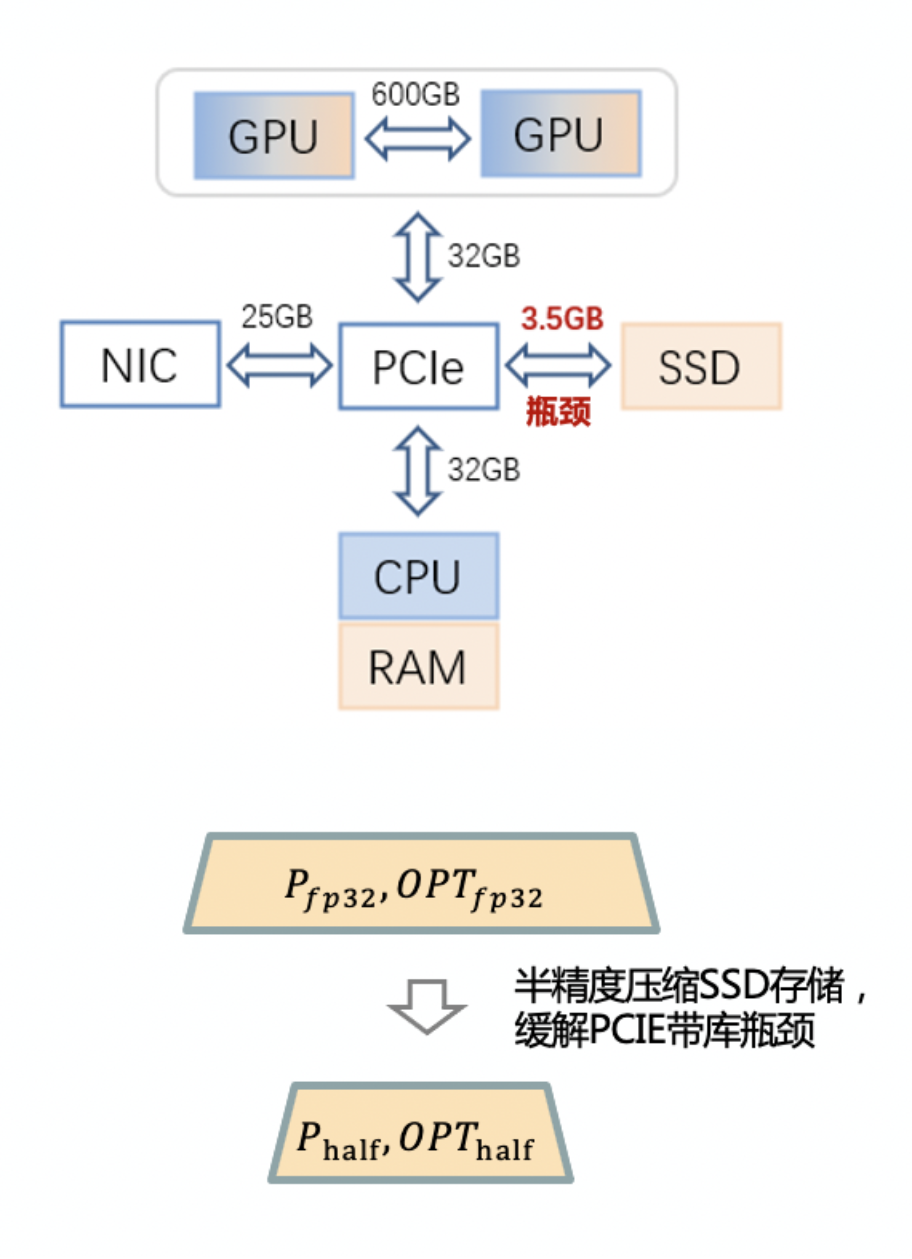
ZeRO-Cache SSD框架
大模型训练加速效果
测试使用的方案版本信息如下:
DeepSpeed | Megatron-DeepSpeed | |
|---|---|---|
社区方案 | 0.8.1+258d2831 | 7212b58 |
AngelPTM 方案 | 0.6.1+474caa20 | c5808e0 |
注意:其他环境,例如 OS/python/CUDA/cuDNN/pytorch 等版本二者一致。
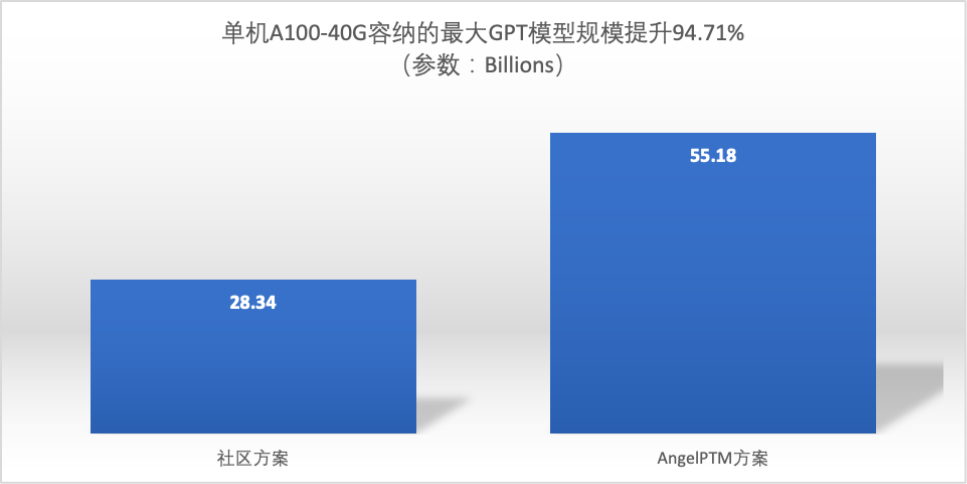
最大容纳模型规模
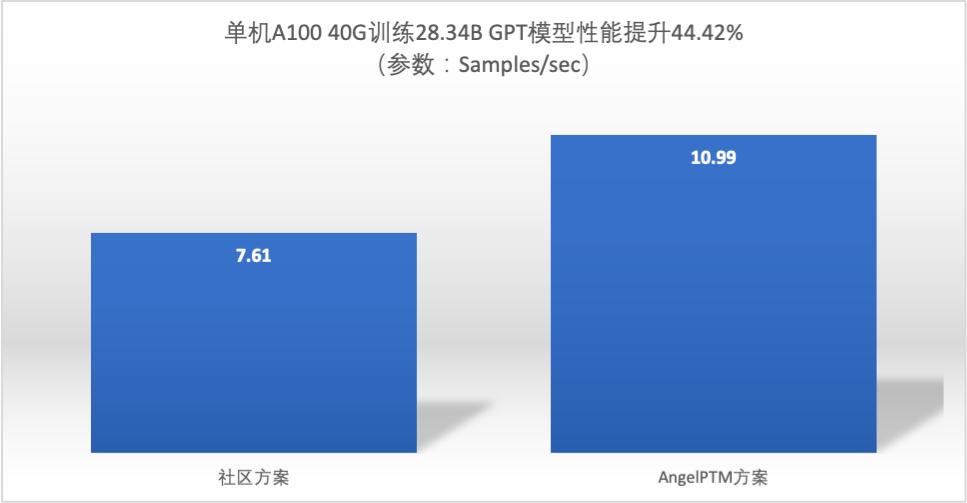
同等模型规模训练性能
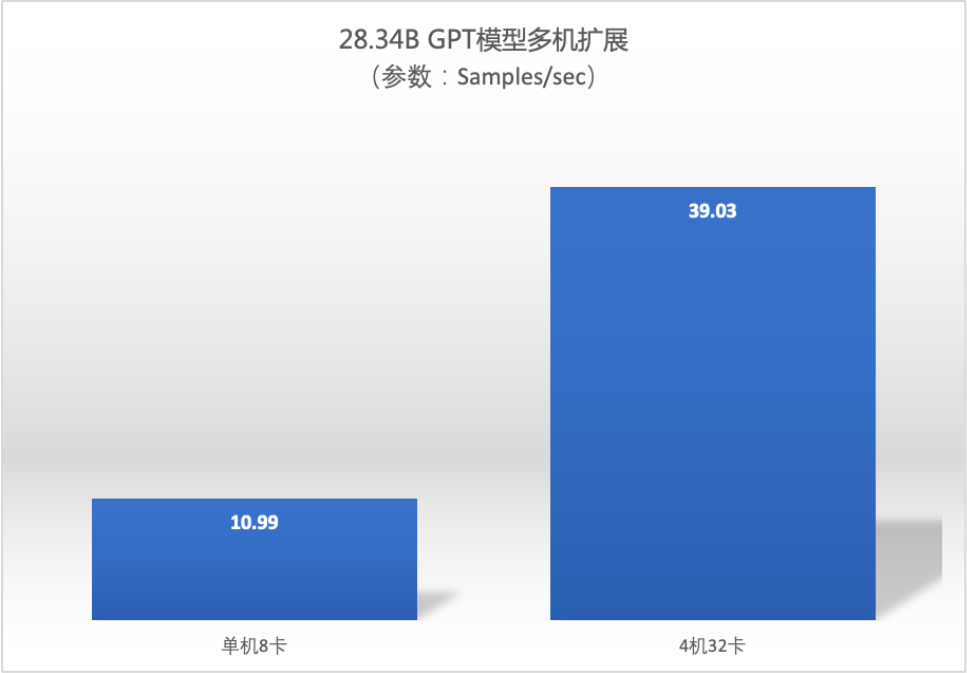
多机扩展比
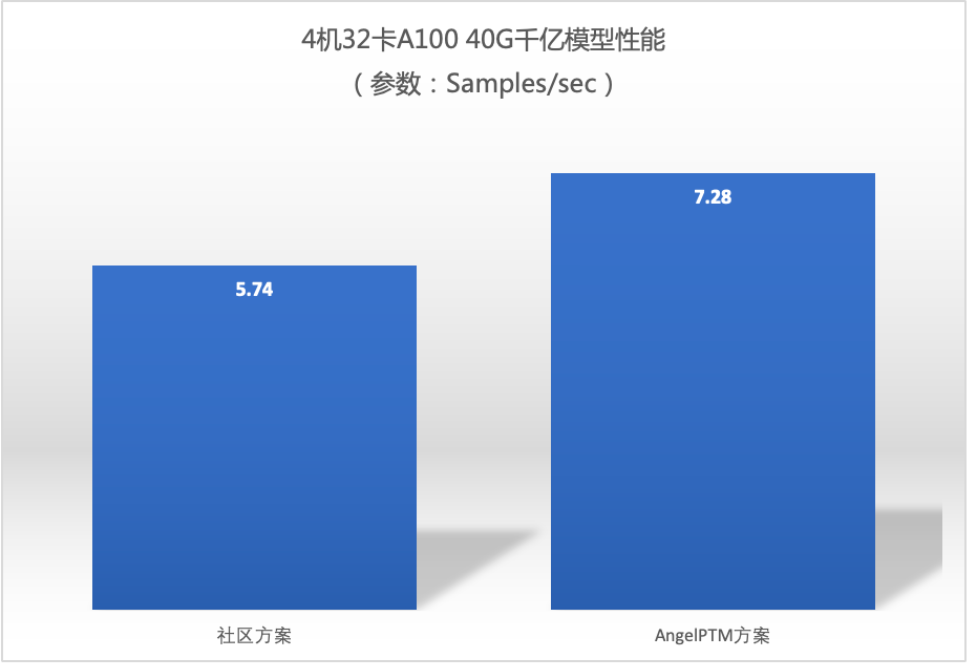
千亿模型性能
注意:4机32卡训练性能提升比例(26.8%)相比单机有所下降主要是由于网络带宽限制。这里使用的是 100Gbps RDMA 网络,未来腾讯云会推出更高带宽 RDMA 的高性能计算集群,预期性能提升会与单机接近。
AngelPTM 已加入 TACO Train 加速组件,助力大模型训练显存上限、性能大幅提高
腾讯云秉承为客户解决实际业务难题,创造增量价值的初衷,不仅要让客户在云上业务可靠运行,还要辅助客户真正发挥出云服务器的算力性价比优势。我们希望通过 TACO Train、TACO Infer、qGPU 共享技术等软件附加值产品,助力客户提升算力效率,降低业务成本,形成可持续发展的长期合作模式。
TACO Train 新增 AngelPTM 训练加速组件,结合高性能计算集群 HCC,可以实现:
- AngelPTM 将单机 A100 40G 容纳的模型规模提升了94.71%
- 基于社区方案能容纳的最大模型规模,AngelPTM 性能提升了44.42%
- 千亿模型规模下,AngelPTM 多机扩展比接近线性
使用 AngelPTM 加速大模型训练最佳实践已上线官网文档,欢迎使用体验。
未来,除了 AngelPTM 大模型加速组件,TACO Train 还会推出 TCCL 集合通信库,动态编译特性支持等。相信随着 TACO Train 的不断发展,使用 TACO Train 的性能收益将会越来越高,欢迎加入交流群,更多组件更新敬请期待。

扫码加入「TACO Train 加速引擎交流群」
