根据PolarDB for PG 宣称的一些特性
- 数据存储成本相较PostgreSQL RDS产品有30% -50%的存储成本的下降。
- SQL的处理CPU消耗相较用户PostgreSQL RDS产品更稳定,消耗的CPU更少
- 内存使用率在运行类似的SQL语句相较与PostgreSQL 内存的使用率更低
针对PolarDB for PostgreSQL 提出的特性,其中PG原生数据库最大的问题之一是磁盘空间占用的问题,相对于其他的数据库产品PostgreSQL 数据库会在使用中占用更多的磁盘空间,这是人尽皆知的问题,其他的两个问题也需要进行测试,通过测试来验证PolarDB for PostgreSQL产品是否和宣传的比PostgreSQL RDS产品更具竞争力。
在此之前我也收到过一些DBA同学被公司的IT部的老板问及,为什么MySQL存储空间比PG要节省得问题,怎么回答这样的问题,从这里可以反应出成本是IT部门领导看中的问题。
解释问题,不如解决问题这里我们就根据PolarDB for PostgreSQL的资料来验证他们所宣传的是否属实,节省空间 50%,这里我们制定了简易的测试方案,通过两台同样配置的数据库产品进行POC,同时PolarDB 磁盘系统我们降级没有使用PolarDB 推荐的PLS5 ,而是使用了成本更低性能稍差的PLS4,RDS产品我们使用了默认的磁盘系统,最高IOPS为5万的产品PL1,从成本上考量这两个数据库的成本是雷同的。
1 台PolarDB 4C 16G 启动硬件压缩 PLS4
1 台PostgreSQL RDS 4C 16G PL1 5万IOPS
- 针对测试存储空间的部分,我们产生了7个表饱含了BIGINT ,INT ,FLOAT,JSON,TEXT ,VARCHAR,和具备所有这些字段的表,分别向表里面灌入数据,且观察注入数据以后,PolarDB for PostgreSQL 相对PostgreSQL RDS 是否可以节省成本。
testdb=> \d table_bigint Table "public.table_bigint" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+------------------------------------------ id | integer | | not null | nextval('table_bigint_id_seq'::regclass) data | bigint | | | Indexes: "table_bigint_pkey" PRIMARY KEY, btree (id)testdb=> \d table_float
Table "public.table_float"
Column | Type | Collation | Nullable | Default
--------+------------------+-----------+----------+-----------------------------------------
id | integer | | not null | nextval('table_float_id_seq'::regclass)
data | double precision | | |
Indexes:
"table_float_pkey" PRIMARY KEY, btree (id)testdb=> \d table_int
Table "public.table_int"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------------------------------------
id | integer | | not null | nextval('table_int_id_seq'::regclass)
data | integer | | |
Indexes:
"table_int_pkey" PRIMARY KEY, btree (id)testdb=> \d table_varchar
Table "public.table_varchar"
Column | Type | Collation | Nullable | Default
--------+-------------------------+-----------+----------+-------------------------------------------
id | integer | | not null | nextval('table_varchar_id_seq'::regclass)
data | character varying(2000) | | |
Indexes:
"table_varchar_pkey" PRIMARY KEY, btree (id)testdb=> \d table_json
Table "public.table_json"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+----------------------------------------
id | integer | | not null | nextval('table_json_id_seq'::regclass)
data | json | | |
Indexes:
"table_json_pkey" PRIMARY KEY, btree (id)testdb=> \d table_union
Table "public.table_union"
Column | Type | Collation | Nullable | Default
--------+-------------------------+-----------+----------+-----------------------------------------
id | integer | | not null | nextval('table_union_id_seq'::regclass)
data1 | integer | | |
data2 | character varying(2000) | | |
data3 | text | | |
data4 | bigint | | |
data5 | json | | |
data6 | double precision | | |
Indexes:
"table_union_pkey" PRIMARY KEY, btree (id)
在灌入数据后,大部分表已经来到了4000万行的数据量,下图图1是PolarDB for PG ,和图2 PostgreSQL RDS占用磁盘空间的截图 ,从磁盘占用的情况可以看出的确PolarDB for PostgreSQL 在同样的数据存储量上,在实际使用的存储空间有优势。实际数据时151.98G的数据在存储到存储后被压缩到55.43GB,相当于我们节省了96.55G 存储空间,越占整体存储空间的64%的空间被省下来了。
这里用的是一套程序,同时向PG 和 POLARDB 数据库进行数据的插入,明显看到从外部占用空间的情况是一致的,PG 是152.44 PolarDB 是151.98,55.43G 是PolarDB for PG 启用了压缩后,实际占用的磁盘空间。
图1

图2

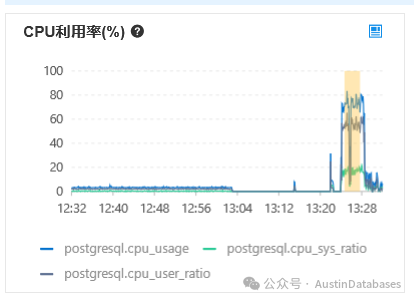
与此同时我们也非常关心在测试中,基于测试中数据压缩中给CPU带来的损耗的问题,这里官方给我的数据时10%的损耗,这里数据压缩并不是使用数据库的实例所带的CPU,损耗的是磁盘存储系统上的CPU,但我在压测的时候并未发现所称的损耗10%的CPU实际的体现。相对于PostgreSQL RDS 产品,CPU使用率还略低。这是我们在测试中获得真实数据。
图3 PolarDB for PG的CPU使用率
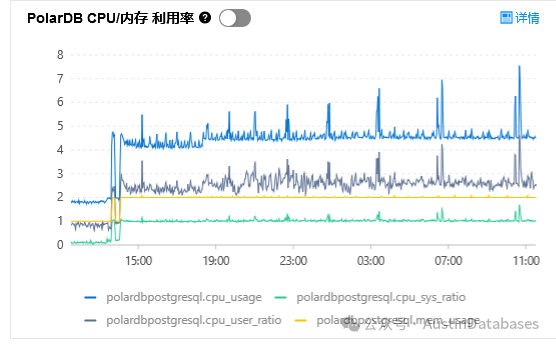
图4 PostgreSQL RDS 的CPU 使用率
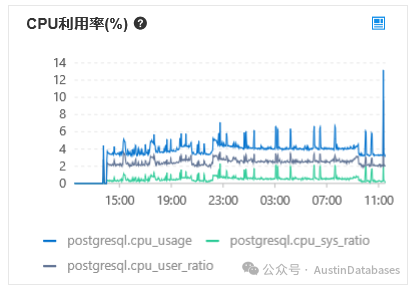
在CPU中我们并未找到多消耗的10%的说明,我们期望PolarDB for PostgreSQL 和大众汽车一样在马力上是反向虚标,在CPU上我们没有发现问题后,我们将注意点转向到内存的部分。
PolarDB for PostgreSQL 有意思吗?有意思呀
不太清楚PolarDB for PostgreSQL 的原理的同学可以看上面的连接中的内容
图 5 PostgreSQL RDS 监控图

图 6 PolarDB for PostgreSQL 监控图
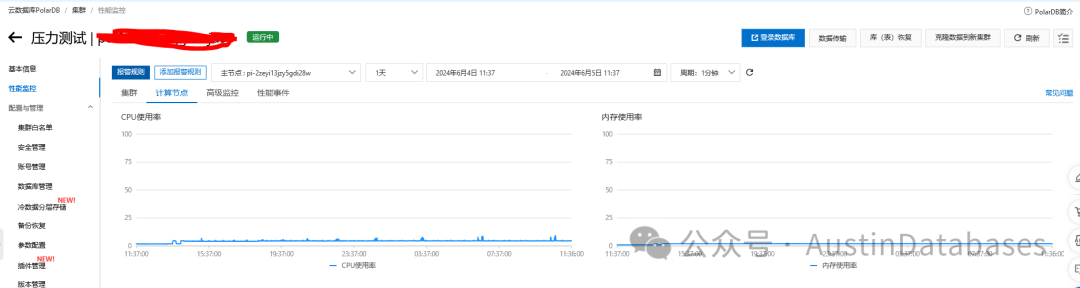
起初看到上面图5 和 图6 监控图后,我也向阿里云的老师提出异议,我认为可能是监控出现问题,为什么PostgreSQL RDS 产品的内存波动的非常厉害,而在PolarDB for PostgreSQL 产品的内存监控中,基本没有较大的波动。
在我提出异议并认为这不符合常理的情况下,PolarDB for PostgreSQL 的相关负责人给一个技术解释。PolarDB for PostgreSQL 虽然在使用上与PG没有任何的差异,但在数据库底层层面与PG的设计是截然相反的,PolarDB for PostgreSQL 本身是自有管理内存的方式,而非需要借助操作系统的文件cache来进行操作数据的给付,所以在内存层面 shared buffer pool 可以和其他的数据库产品一样设置的更大,可以占整体数据库内存的60% 或 更大,所以在监控层面看到的PolarDB for PostgreSQL 的内存使用波动在此次测试中不大的原因是两个数据库底层的原理不一导致的。
但我对相关解释存在一些疑问,所以继续对于数据进行读取的测试,从时间和内存的消耗上以及CPU的使用量上,我们使用了一个直接且粗暴的方案来对比两个数据库产品的差异。
图 7 测试程序
You are now connected to database "testdb" as user "cy_test_rds".
testdb=> select count(*) from table_union;
count
42099601
(1 row)
testdb=> CREATE OR REPLACE FUNCTION query_table_count_loop()
testdb-> RETURNS VOID AS
testdb$> DECLARE
testdb$> i INT := 1;
testdb$> BEGIN
testdb$> -- 循环100次
testdb$> WHILE i <= 100 LOOP
testdb$> -- 查询表的记录数量并打印输出
testdb$> RAISE NOTICE 'Iteration: %, Table Count: %', i, (SELECT count(*) FROM table_union);
testdb$> i := i + 1; -- 增加循环次数
testdb$> END LOOP;
testdb$> END;
testdb$>
LANGUAGE plpgsql;
CREATE FUNCTION
测试程序本身比较简单,粗暴,主要就是针对大表进行不停的select count() 的数据读取。
1 PolarDB for PG 稍微再测试中吃一点亏的情况下,CPU 稳定在60%以下,RDS POSTGRESQL 有少许的超过80%的情况,大部分在70%多,且两个数据库比对非常有意思,一个CPU 是平稳的,一个是波折的。
图 8 PolarDB select count() 测试监控图
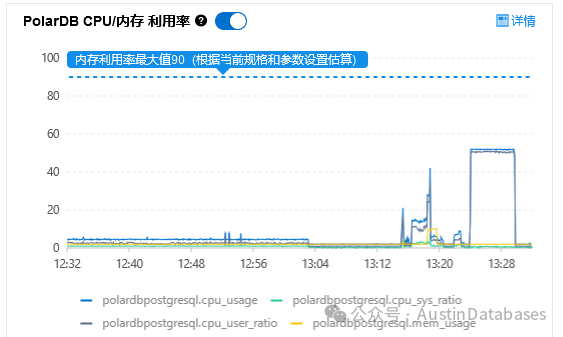
图 9 PolarDB select count(*) 测试监控图
PolarDB for PostgreSQL 100次 4千六百万数据最终使用的时间是 5分46秒 ,PostgreSQL RDS 100次 4千2百万的时间在 7分11秒,明显PolarDB for PostgreSQL 在大表 count(*) 方面,在数据的处理速度,稳定性,CPU 使用 均占优。
图10 PolarDB for PostgreSQL 测试结果
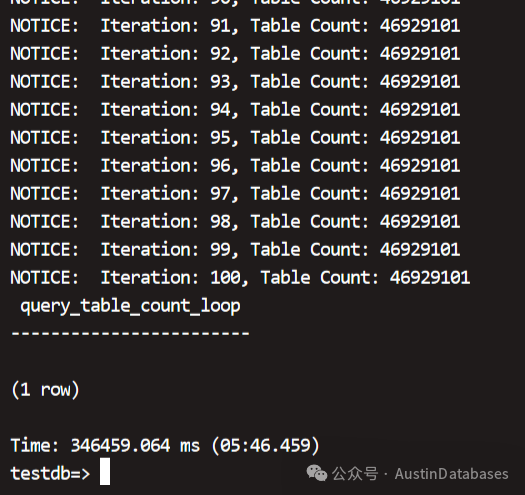
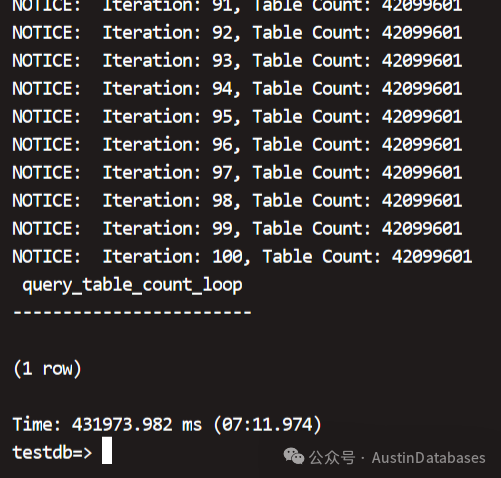
图 11 PolarDB for PostgreSQL 测试结果
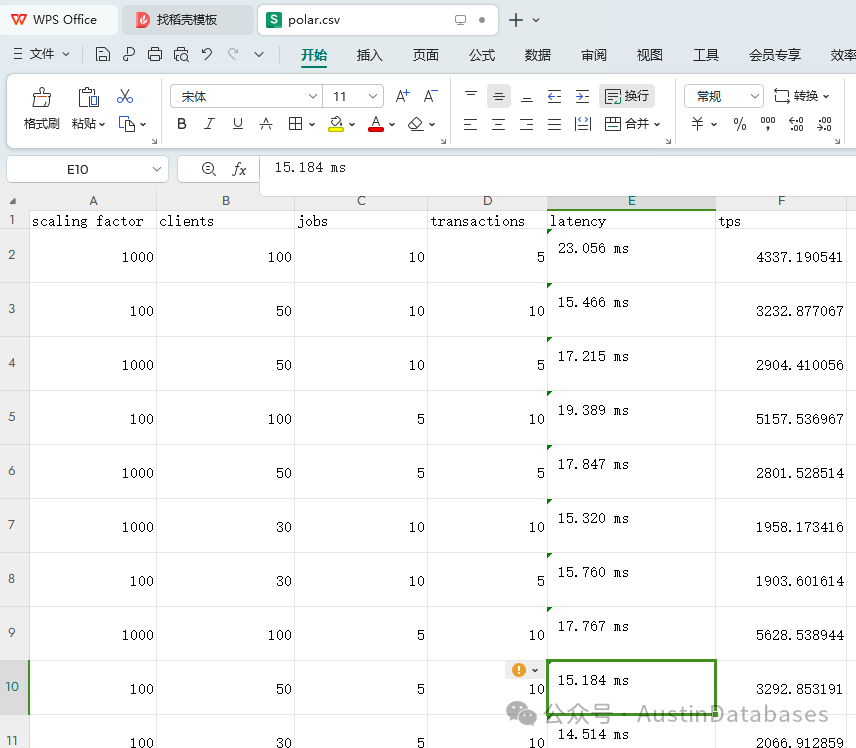
我们还撰写程序通过pgbench不同组合参数,模拟高并发增删改查的压测方法,对两种数据库进行高并发和多客户端模拟的压测,以及不同的数据量,1000万单表,一个亿单表,多客户端,及一个客户端执行多jobs,限定执行的事务数量,最终获得单次测试的延迟和TPS执行数的结果,延迟越低越好,tps越高越好,下图测试结果,PolarDB for PostgreSQL执行的TPS要多,延迟更低,二者还是有一定的差距。
图12 PostgreSQL RDS 测试结果
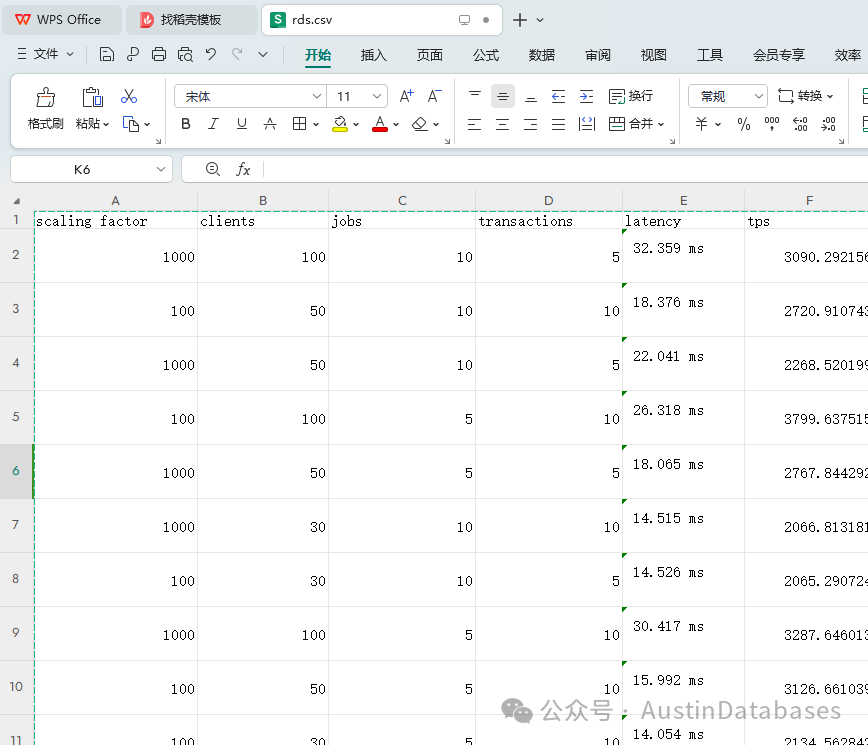
图 13 PolarDB for PostgreSQL 测试结果
最后针对大事务在业务中有一定的要求,我们模拟了50万插入数据作为一个事务提交的业务情况。
图 14 测试程序代码
import psycopg import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
logger.addHandler(logging.FileHandler("1.log"))
conn_str = "postgresql://cy_test_polar/testdb?sslmode=disable"
with psycopg.connect(conn_str, autocommit=False) as conn:
for x in range(10):
with conn.cursor() as cur:
for i in range(500000):
cur.execute("insert into table_int2 (data1,data2,data3) values (%s,%s,%s)", (1000000000,))
if i % 1000 == 0:
logger.info("epoch:%d,inserted:%d", x, i)
conn.commit()
50万行数据一提交,连做10次,整体操作中PG 和 POLARDB for PG 都比较稳定没有出现问题, 可以看到POLARDBIOPS 有略微升高的情况,RDS PG 产品也比较稳定。
图 15 PolarBD IOPS 测试
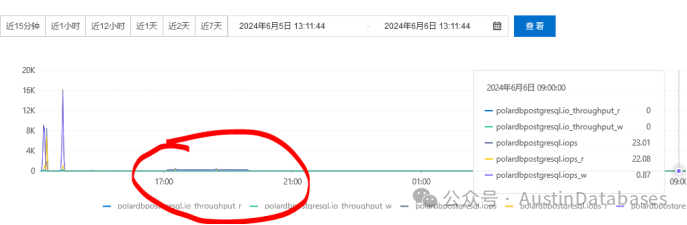
图 16 RDS PostgreSQL IOPS 测试

结论:在整体测试中,通过各种测试方法比对数据库在高并发和大事务,及数据存储成本节省的测试项目中,PolarDB for PostgreSQL 基本达到了官方提供的测试预期。