“造”大模型,有卡就行?
关键是,卡要怎么用!
大模型越来越火,不少手里有卡的伙伴给鹅提“需求”:用自己的卡能不能组建大模型算力集群?
收到,安排!
最近,腾讯云推出专有云智算套件,集合了腾讯云高性能网络IHN(星脉网络)、高并发文件存储系统TurboFS、算力加速框架Taco-LLM等核心能力。
结合腾讯云专有云平台TCE,支撑企业用自有硬件搭建计算集群,在私有算力环境下训练大模型。

一句话划重点:卡,自己的。计算集群,也自己的。工具,鹅给的!
但组建算力集群不是简单“盖楼”,算力并不会随着卡的数量线性增长。存储、网络、计算,共同形成了集群的“木桶短板效应”。
为全面消除集群“短板”,腾讯云智算套件提供了算、存、网一体能力,主打一个“整整齐齐”:

//看存储(TurboFS):一分钟完成TB级CheckPoint
在大模型训练时,数据存储约占整体工程量的30%。
存储就像一间仓库,GPU除了在里面存取“原料”(读写计算结果),也会定期保存工作日志(CheckPoint检查点),以备不时之需(故障检查、重启训练等)。
随着模型参数和计算集群越来越大,动辄数千张卡同时读写,存储不靠谱,GPU性能再强也白搭。

腾讯云高性能文件存储系统TurboFS拥有TiB/s级别总读写吞吐和百万OPS的每秒元数据性能,在私有算力环境下,可以支撑4000卡在一分钟内完成TB级CheckPoint,抬高了海量数据存储的读写性能天花板。
//看网络(IHN星脉网络):网络通信效率提升60%
简单来说,GPU在大模型训练中只干两件事:埋头工作(计算)、等待拉通(计算结果同步)。
在执行一次计算任务时,集群通信时间最高占比可达50%。
网络不给力,高价买来的GPU只能“干等着”。等待,就意味着浪费。
不久前,腾讯自研星脉高性能计算网络全面升级,相比上一代:网络通信效率提升60%,让大模型训练效率提升20%。

大模型训练再提速20%!腾讯星脉网络2.0来了
//看计算(TACO-LLM):模型推理速度提升2倍
训练框架就像一张“蓝图”,可以指导GPU更高效完成任务。
Taco-LLM适配主流训练框架、开创混和序列并行模式、率先跑通FP8训练精度,并适配全部国产模型,能够为不同集群制定最优训练方案,让所有代次的GPU“应用尽用”。
在模型推理时,Taco-LLM的预测采样方式也突破GPU自回归限制。
即GPU不再每次只生成一个结果(Token),而是把多个结果交给目标大模型“验算”。由于GPU单次拉起成本相同,哪怕只“猜中”一个,也是“赚到”。

为配合预测采样,Taco-LLM还改变了GPU的连续显存模式,采用分区(block)存放,并为历史结果分配“专用区”,避免了显存连续分配释放造成的资源浪费。
突破GPU自回归限制和连续显存瓶颈后,让模型推理速度提升了2倍。
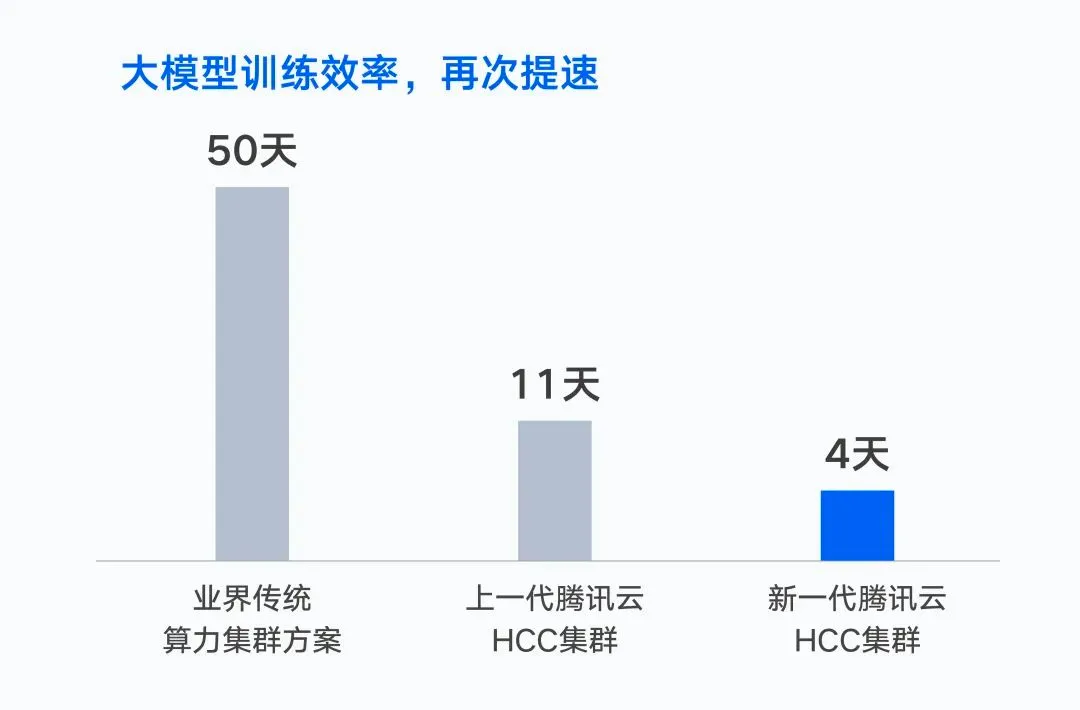
去年,腾讯云发布新一代HCC高性能计算集群,通过自研服务器、自研网络、存储架构等软硬件设施,让万亿参数大模的训练时间从50天缩短至4天。
腾讯云发布:大模型算力集群!
此次专有云智算套件的发布,正是基于公有云算力集群HCC的成熟实践。
美团、小红书等头部互联网企业,以及百川智能、MiniMax、智谱科技、元象……90%的头部大模型企业都选择了腾讯云。
面向有私有算力环境下训练大模型的伙伴,我们会做好从公有云到私有云的“搬运工”,帮助大家搭建好AI大模型基础设施。
搭建自己的大模型计算集群,就从这里开始!