网络上的文章基本上是根据设备商规划好的网络架构来计算AI/HPC算力光模块(以下简称光模块)的数量。今天,大成鹏通信就以LLaMa 65B模型训练实例来阐释AI训练模型需要的网络架构对应的光模块数量如何计算。本案例的训练模型为LLaMa 65B,使用的GPU为A100,数量2048个。
算力计算:
①单个GPU的算力供给计算公式:
单GPU算力供给(A) =GPU核数 * 单核主频 * 单周期浮点计算能力。(该参数一般由GPU厂商直接给出)
②单个模型的算力需求计算公式为:
单模型算力需求(C)=6 * 模型的参数量 * 训练数据的 token 数。
③估算训练时间:
T=C/(X*A),X为GPU数量,单位为秒。
结合我们的案例:
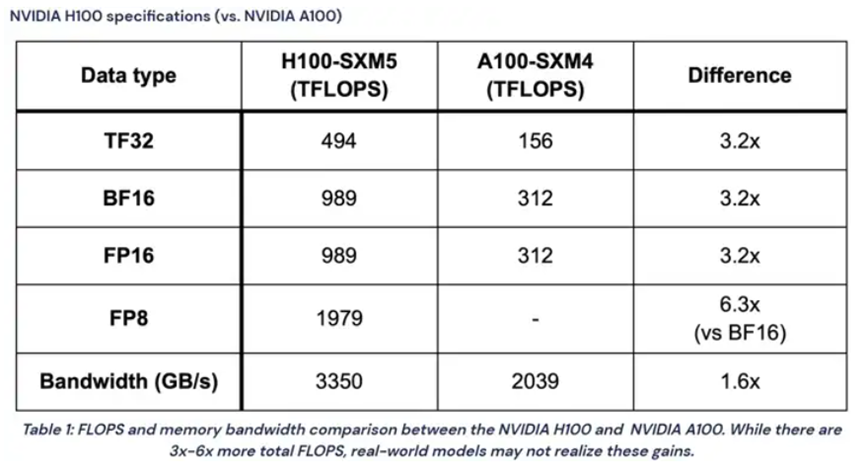
①单张GPU A100的算力供给:
BF16浮点数格式(训练精度)下,算力为312TFLOPS。也就是单GPU算力供给(A) =312 TFLOPS=312* 10^12FLOPS。
实际应用中要考虑训练效率:A100的实际利用率50%左右,并以此为基础推算单个A100的算力A=312* 10^12FLOPS *50%=156*10^12FLOPS。
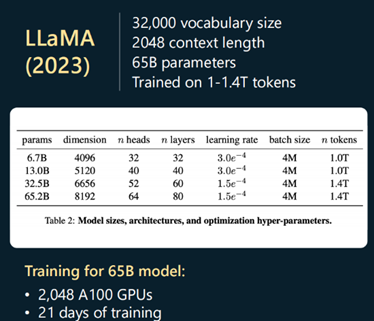
②LLaMa 65B模型算力需求:
C=6*65B*1.4T=6*65*10^9*1.4*10^12=546*10^21
③估算训练时间:
GPU数量为2048个,T=C/(2048*A) =546*10^21/(2048*156* 10^12)=1708984.375秒≈20天。
(可以根据此公式,预设训练时间,反推出GPU数量)
网络架构选择:
IB组网通常采用无阻塞网络设计,其关键是采用 Fat-Tree(胖树)网络架构。交换机下联和上联带宽采用 1:1 无收敛设计,即如果下联有32个400Gbps 的端口,那么上联也有 32个 400Gbps 的端口。
两层胖树和三层胖树最重要的区别是可以容纳的 GPU 卡的规模不同。在下图中 N 代表 GPU 卡的规模,P 代表单台交换机的端口数量。比如对于端口数为 64 的交换机,两层胖树架构可容纳的 GPU 卡的数量是 2048卡,三层胖树架构可容纳的 GPU 卡的数量是 65,535卡。
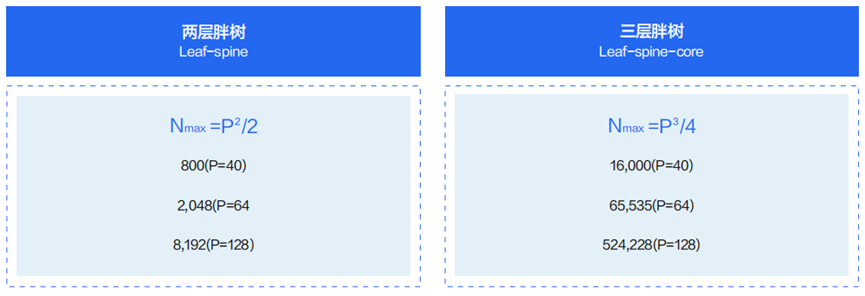
目前,结合我们第一部分算力的计算,使用LLaMa 65B模型,运用A100 GPU进行计算,训练时间20天,GPU数量为2048个,那么选用两层Fat-Tree(胖树)网络结构,即可满足需求。
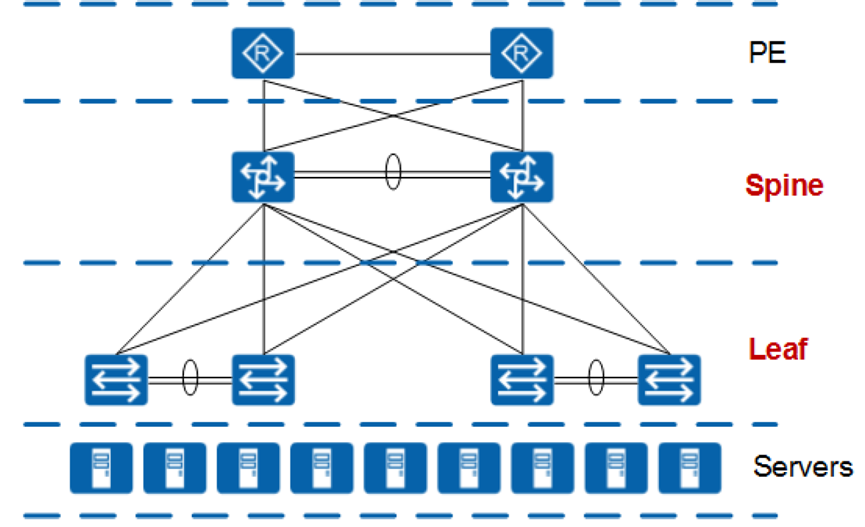
网卡、交换机、光模块数量计算:
①网卡数量计算
单个A100 GPU支持PCI Express 4.0,最大传输带宽32GB/s=256Gb/s。如果单个服务器有2张GPU ,所以可以选择1张400G IB网卡(CX-7)进行传输。


因此GPU卡数量:400G网卡数量=2:1。该案例中GPU数量2048个,那么网卡数量1024个。
②交换机数量计算
以网卡数量来计算交换机数量。使用NVDIA MQM9700系列交换机,每台交换机共计64个400G端口。网络收敛比1:1。
交换机数量:用1024÷32=32,计算出Leaf交换机数量;32÷2=16,计算出Spine交换机数量,总计48台。
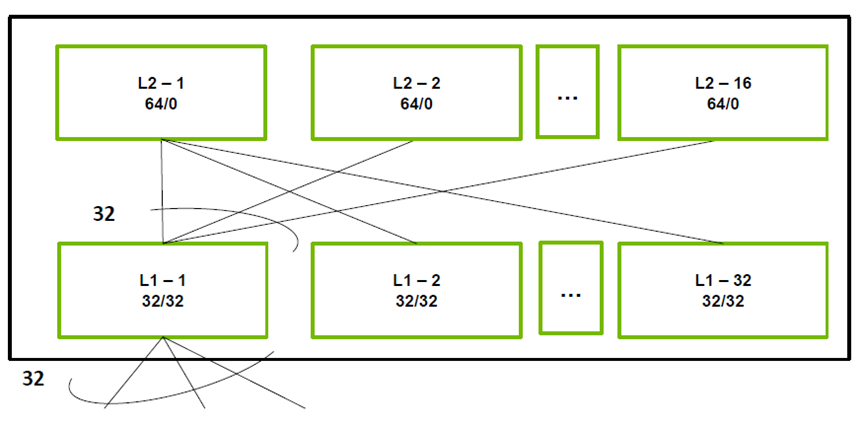
③光模块数量计算
如果全部使用400G光模块互联:48*64+1024=4096个。
如果交换机互联用的400G光模块:32x32+64*16=2048个;交换机和网卡互联使用400G AOC:1024条。
深圳市大成鹏通信有限公司目前正在研发适用于AI算力计算的800G产品,届时将形成200G~800G AI/HPC算力光模块解决方案,完美兼容Infiniband设备,替代原装光模块、AOC、DAC!