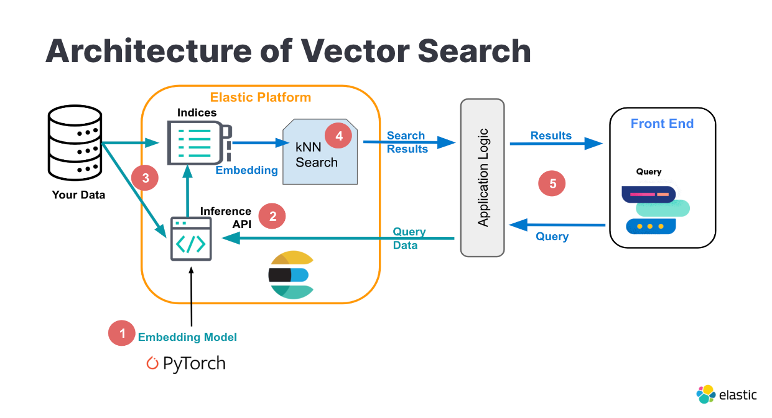
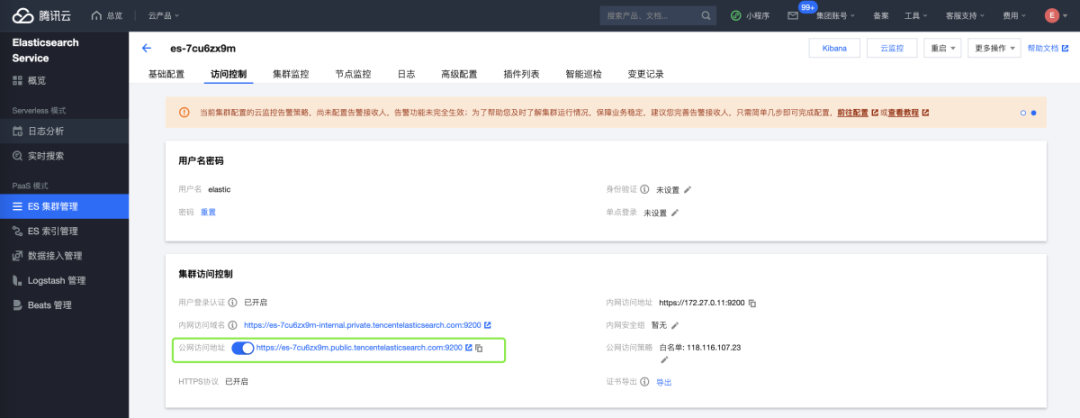
eland_import_hub_model --url https://es-7cu6zx9m.public.tencentelasticsearch.com:9200 --insecure -u elastic -p changeme --hub-model-id distilbert-base-uncased-finetuned-sst-2-english --task-type text_classification --start --insecure
2023-07-13 10:06:23,354 WARNING : NOTE: Redirects are currently not supported in Windows or MacOs.
2023-07-13 10:06:24,358 INFO : Establishing connection to Elasticsearch
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/elasticsearch/_sync/client/__init__.py:394: SecurityWarning: Connecting to 'https://es-7cu6zx9m.public.tencentelasticsearch.com:9200' using TLS with verify_certs=False is insecure
_transport = transport_class(
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:06:24,535 INFO : Connected to cluster named 'es-7cu6zx9m' (version: 8.8.1)
2023-07-13 10:06:24,537 INFO : Loading HuggingFace transformer tokenizer and model 'distilbert-base-uncased-finetuned-sst-2-english'
Downloading pytorch_model.bin: 100%|████████████████████████████████████████████████████████████| 268M/268M [00:19<00:00, 13.6MB/s]
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/transformers/models/distilbert/modeling_distilbert.py:223: TracerWarning: torch.tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.
mask, torch.tensor(torch.finfo(scores.dtype).min)
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:06:48,795 INFO : Creating model with id 'distilbert-base-uncased-finetuned-sst-2-english'
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:06:48,855 INFO : Uploading model definition
0%| | 0/64 [00:00<?, ? parts/s]/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2%|█ | 1/64 [00:01<01:25, 1.36s/ parts]/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
3%|██ | 2/64 [00:01<00:53, 1.16 parts/s]/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
...
100%|██████████████████████████████████████████████████████████████████████████████████████████| 64/64 [00:45<00:00, 1.42 parts/s]
2023-07-13 10:07:34,021 INFO : Uploading model vocabulary
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:07:34,110 INFO : Starting model deployment
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:07:41,163 INFO : Model successfully imported with id 'distilbert-base-uncased-finetuned-sst-2-english'