语音识别就是把语音变成文字的过程,相信大家在平时生活也已经用到过一些语音识别的场景,比如说语音输入法、地图产品的语音输入。近年来,随着互联网的发展,各种音频数据和文本数据得到不断积累和丰富,CPU、GPU硬件的发展,以及深度学习算法大规模的应用,语音识别技术的应用开始获得大规模的商业化拓展。

此次我们整理了腾讯云大学大咖直播课《智能语音技术解密》的回顾,帮助大家了解智能语音,以及智能语音背后的一些技术。
一、智能语音识别的过程:
机器识别语音到文字的过程和人识别语音的过程类似:从录音文件或是麦克风收集的音频中提取特征,经过声学模型和语言模型的处理,最后得出的是识别结果的文字。提取特征的方式有很多种,比较常见的是MFC(多频互控)。

在这个过程中,我们将重点关注特征提取、声学模型、语言模型这三个流程。
特征提取方面:
我们在拿到一段音频文件后,会先把这个文件进行转码变成PCM格式,然后把这个文件分成一片一片,也就是分帧,再对每一帧的数据进行采样。
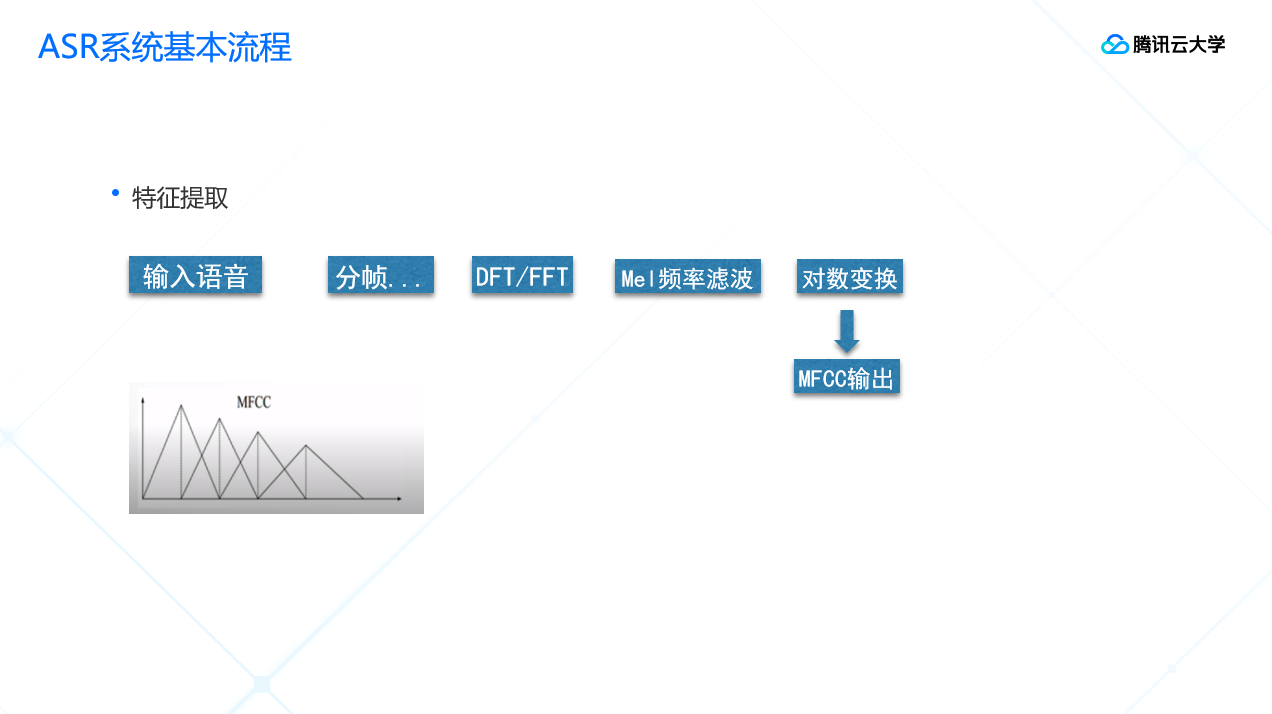
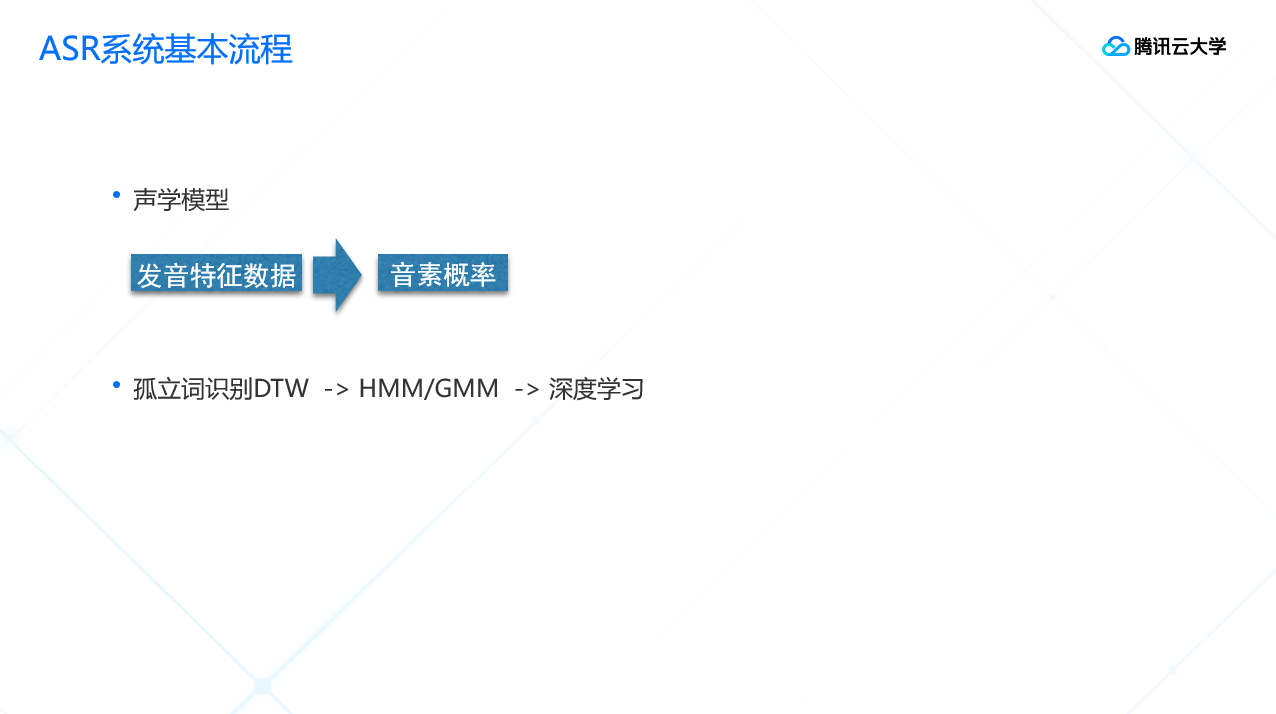
声学模型方面:
提取了特征之后,就要进行声学模型的处理。这个过程就是把之前提取到的发音特征数据变成音素概率。
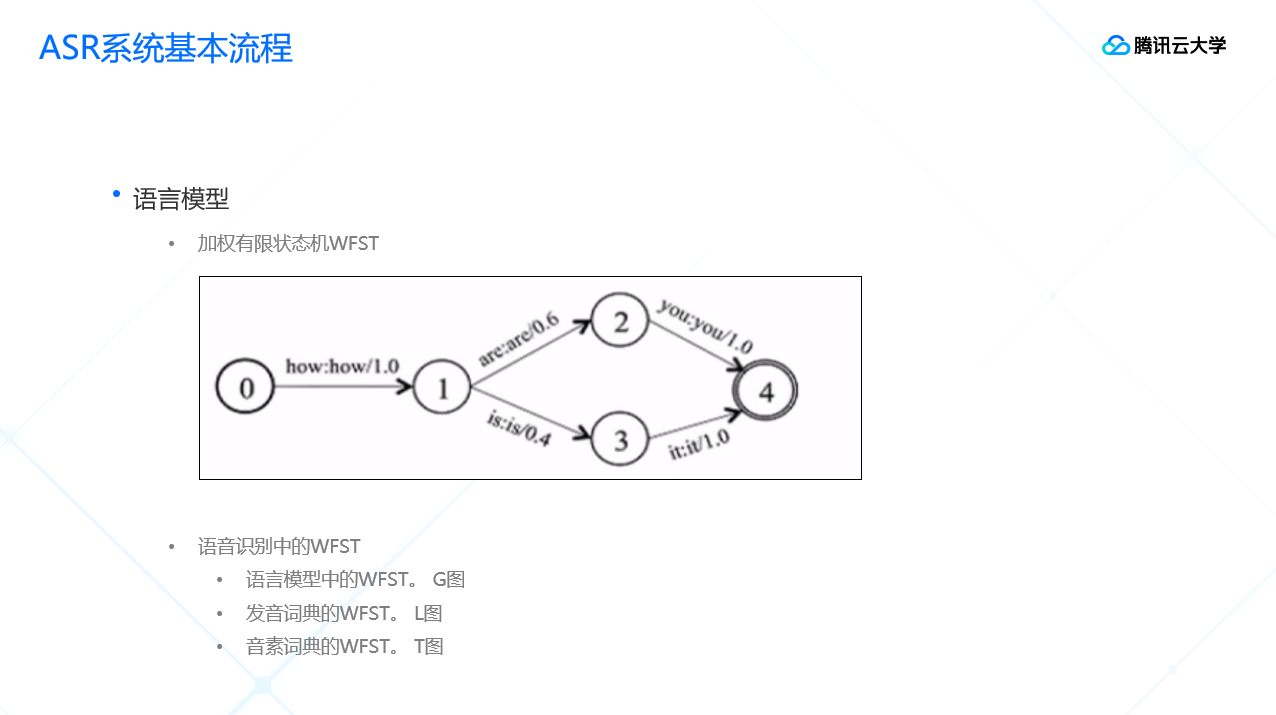
语言模型方面:
语言模型的处理需要大量的文本语料,通过这些文本语料统计出我们平时看到的词语和句子出现的概率。语音模型中用的比较多的技术是WFST,通过搜过WFST的图,可以得到对应这个音素发音的概率最高的句子,最终形成语音识别结果的文本。
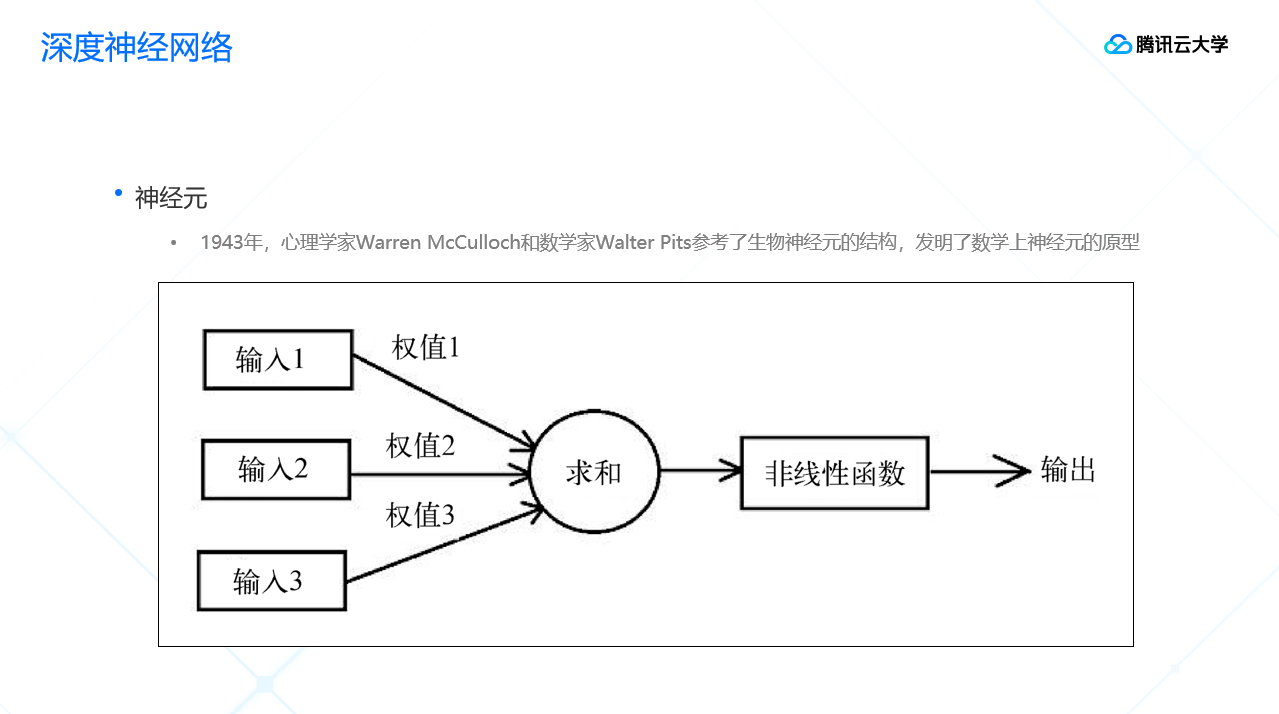
二、深度神经网络
说到智能语音识别,就不得不提智能语音识别领域中最重要深度神经网络技术。从名称上理解的话,深度神经网络其实是模拟人的大脑神经元的工作原理得出的。1943年,心理学家Warren McCulloch和数学家Walter Pits发明了数学上神经元的原型。
基于简单的神经元的单元,可以组合出更复杂的神经网络的结构,后面这两张图分别是简单的神经网络和多层的神经网络的示例,对比可以看出,多层神经网络的神经更复杂、层数和节点更多、计算量更大。
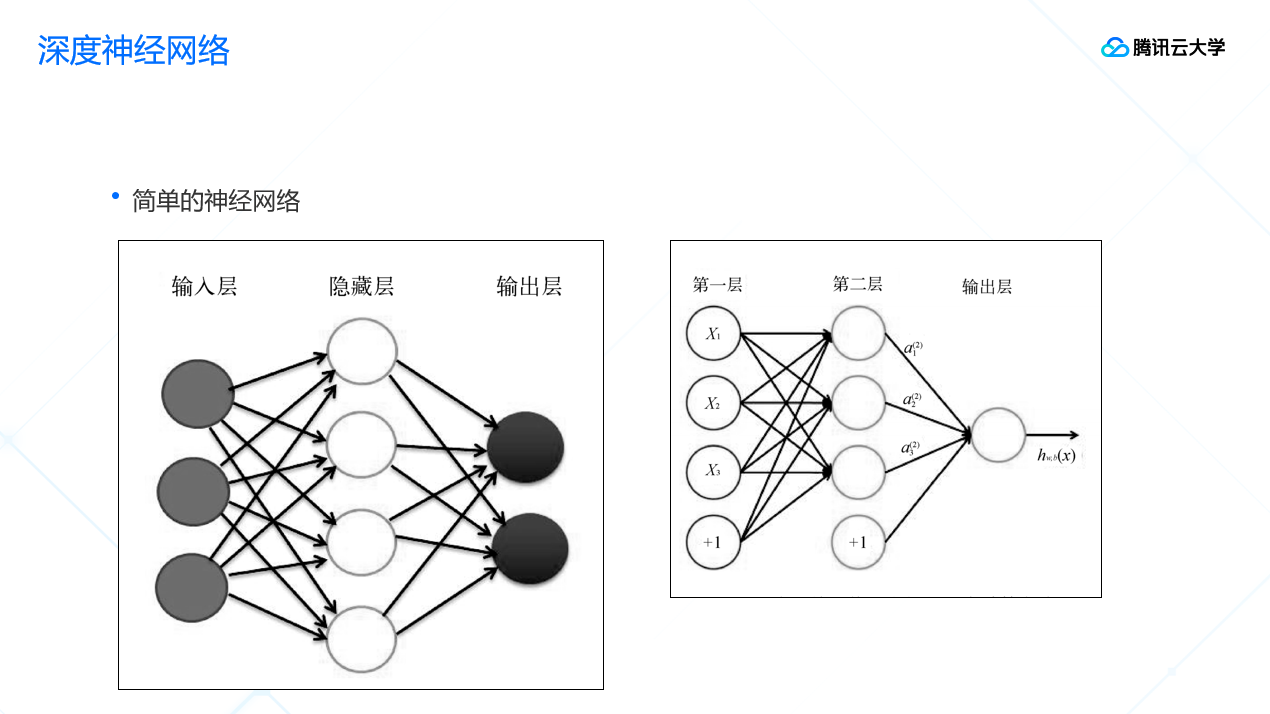
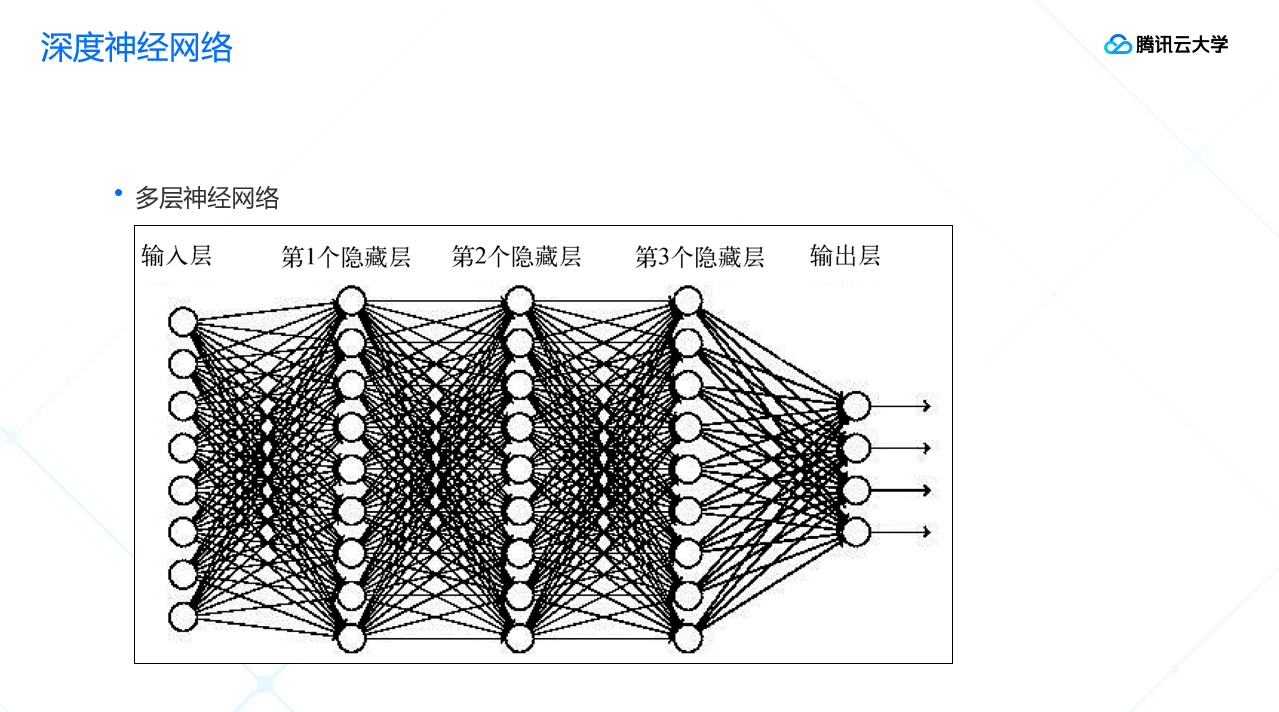
神经网络训练的方式主要有两种:损失函数和优化函数。损失函数指评价网络输出结果和标准结果相差多少;优化函数的作用是优化网络里的参数。

深度神经网络在刚被提出时并没有受到太多的重视,因为它的计算量很大、效果也不比当时其他的算法好。直到卷积神经网络的出现并高效应用于图像识别领域时,深度神经网络技术才受到大家的重视。第一个采用卷积思想的神经网络在1988年面世;2012年,Hinton的学生Alex Krizhevsky在寝室死磕出来一个使用GPU来加速计算的卷积神经网络模型,从此深度神经网络技术开始大放异彩。

那么,卷积神经网络中的“卷积”是什么意思呢?
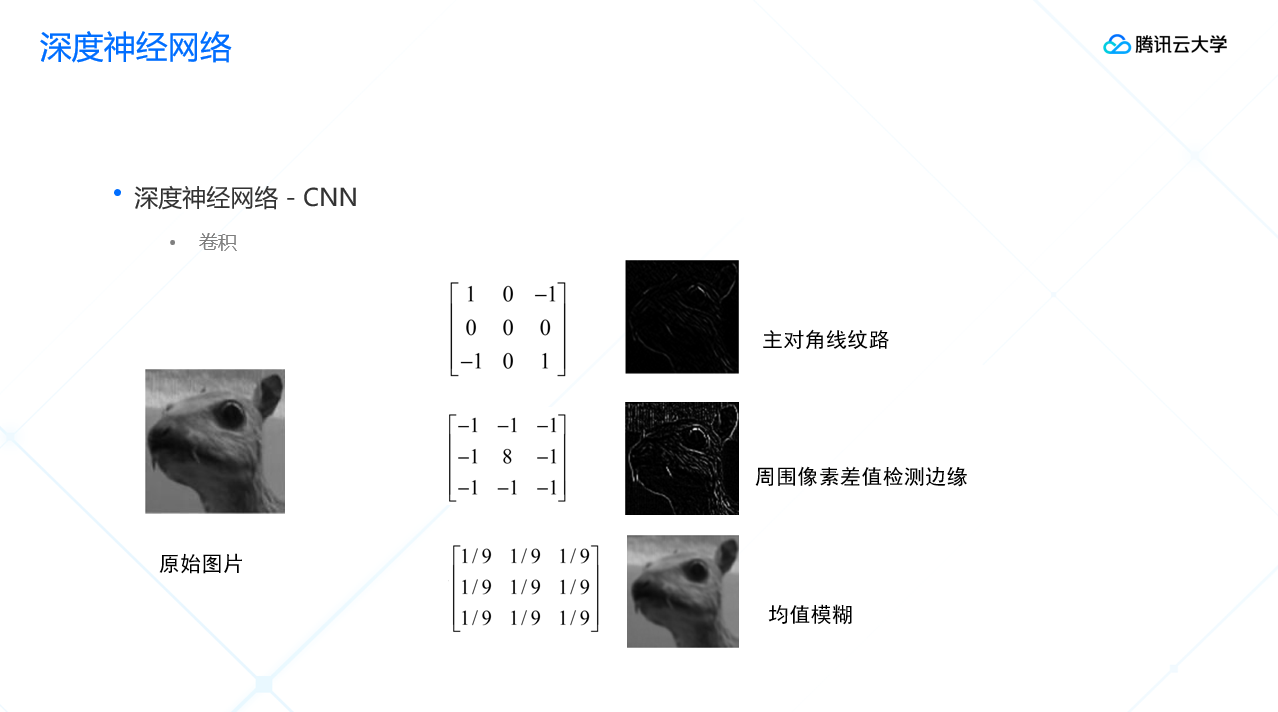
“卷”指加法操作,“积”指乘法操作。在图像领域中,卷积的过程就是对原始图像的像素值对应位做乘法、再做加法,卷积核会在原始图像上不断平移进行这样的计算,最终算出卷积之后的像素值。卷积核在这其中相当于一个提取特征的方式。
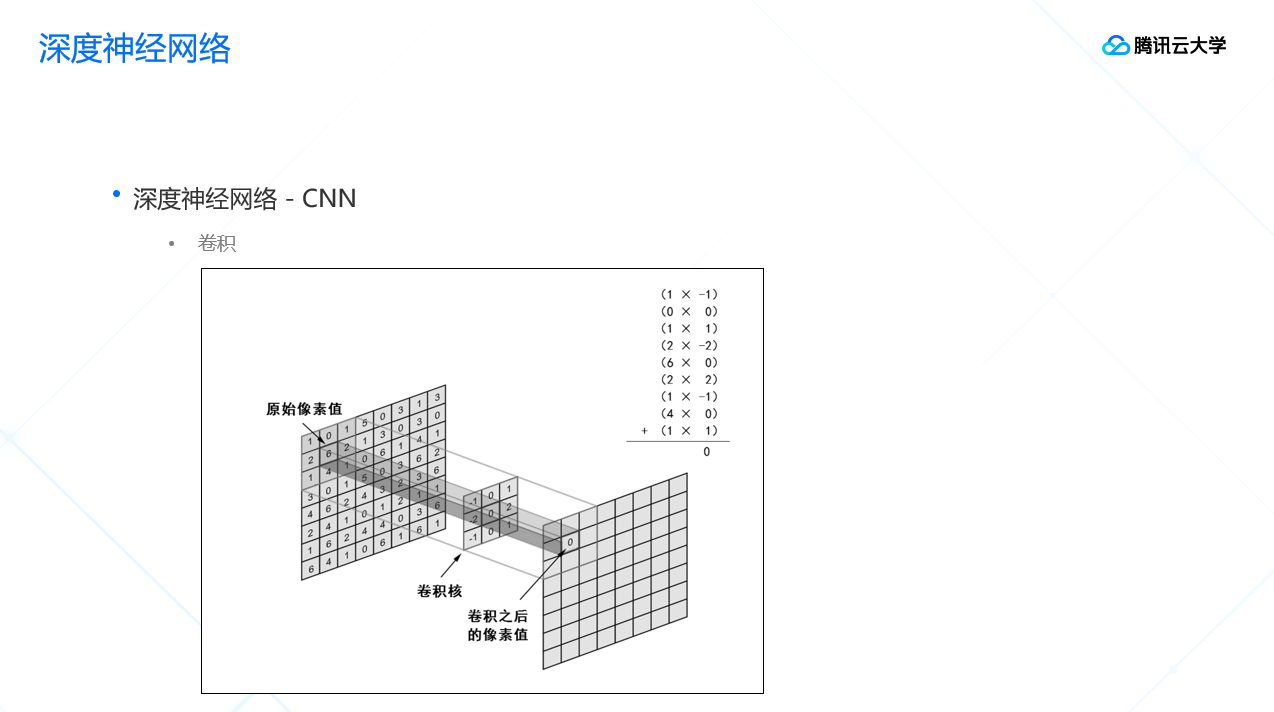
我们以下图为示例,来说明卷积的效果。左边是原始图像,右边是卷积之后的图像,我们可以看到通过不断地卷积运算,图像识别内容逐渐丰富。
另一种是RNN的网络,RNN主要提取时间上的特征。
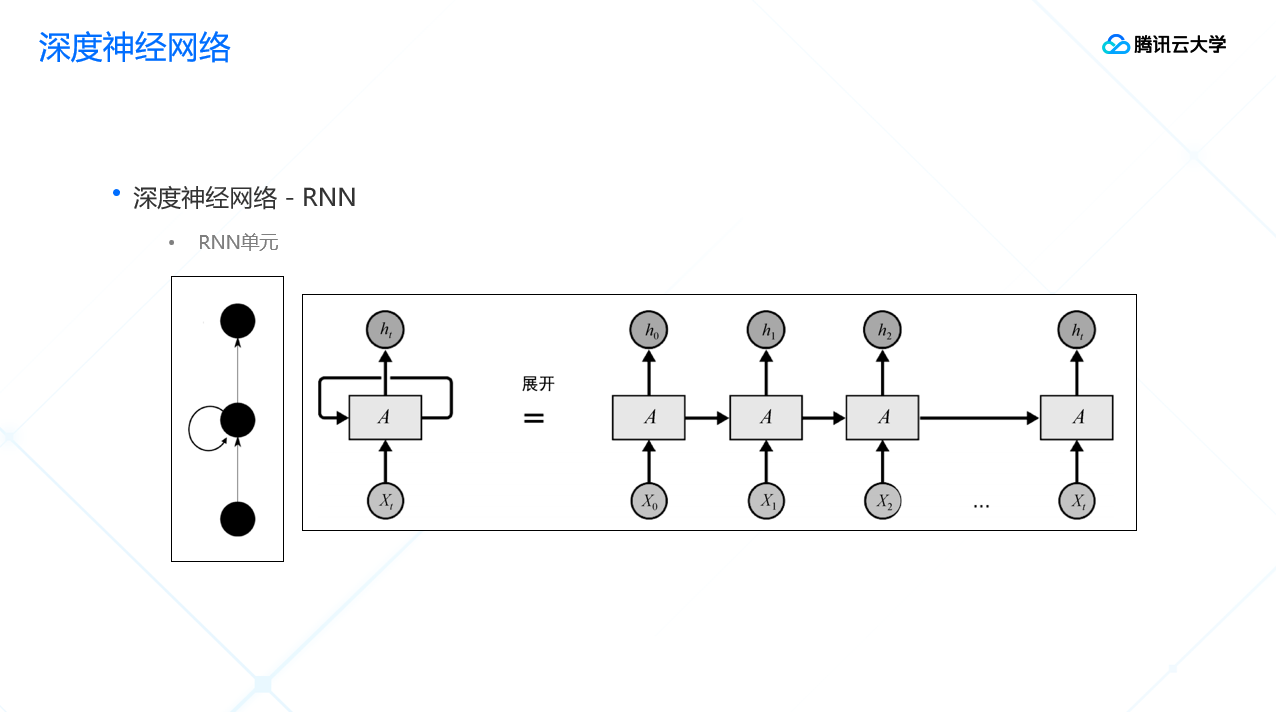
三、深度学习的应用
我们说了这么多关于深度学习的内容,那么深度学习在声学模型中究竟如何运用呢?
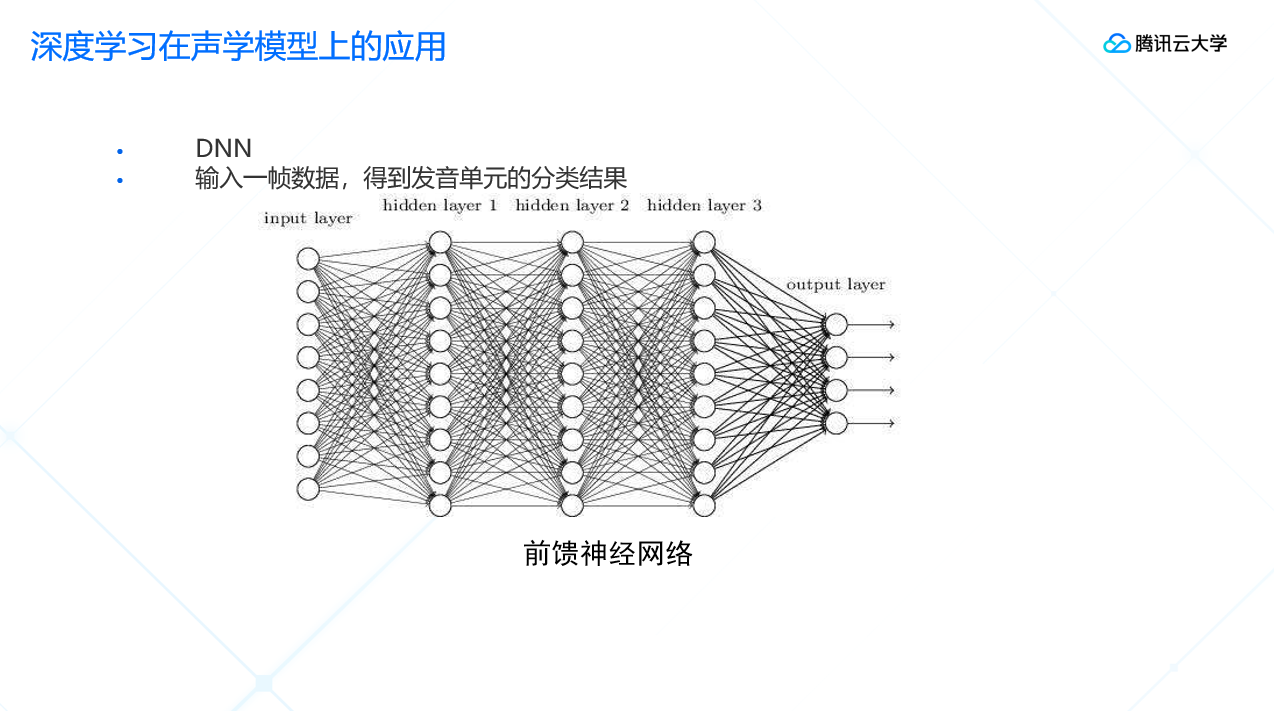
语音识别过程提取了特征之后,一帧的数据变成一个单位的向量,多帧的数据变成了一个矩阵。
在DNN网络中,输入一帧数据,得到发音单元的分类结果。
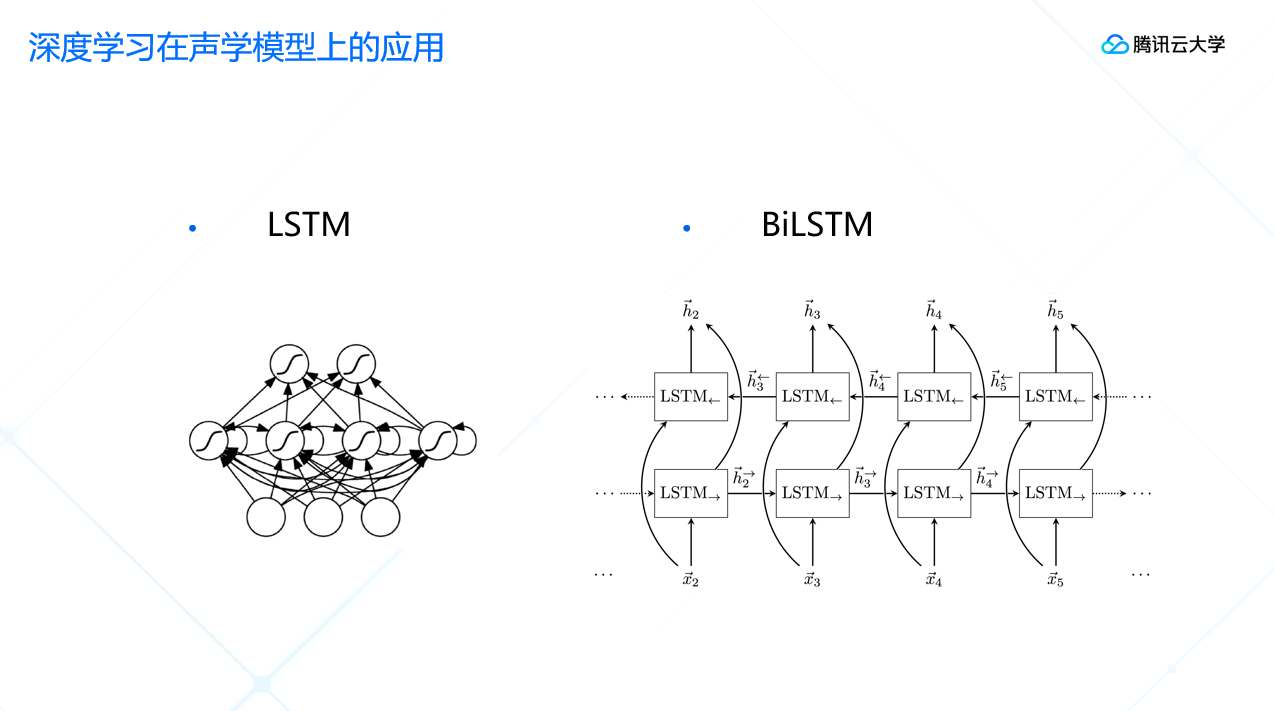
目前使用得更多的是RNN的LSTM网络, LSTM网络可以更好地追踪发音的变化过程,更好地识别音素。
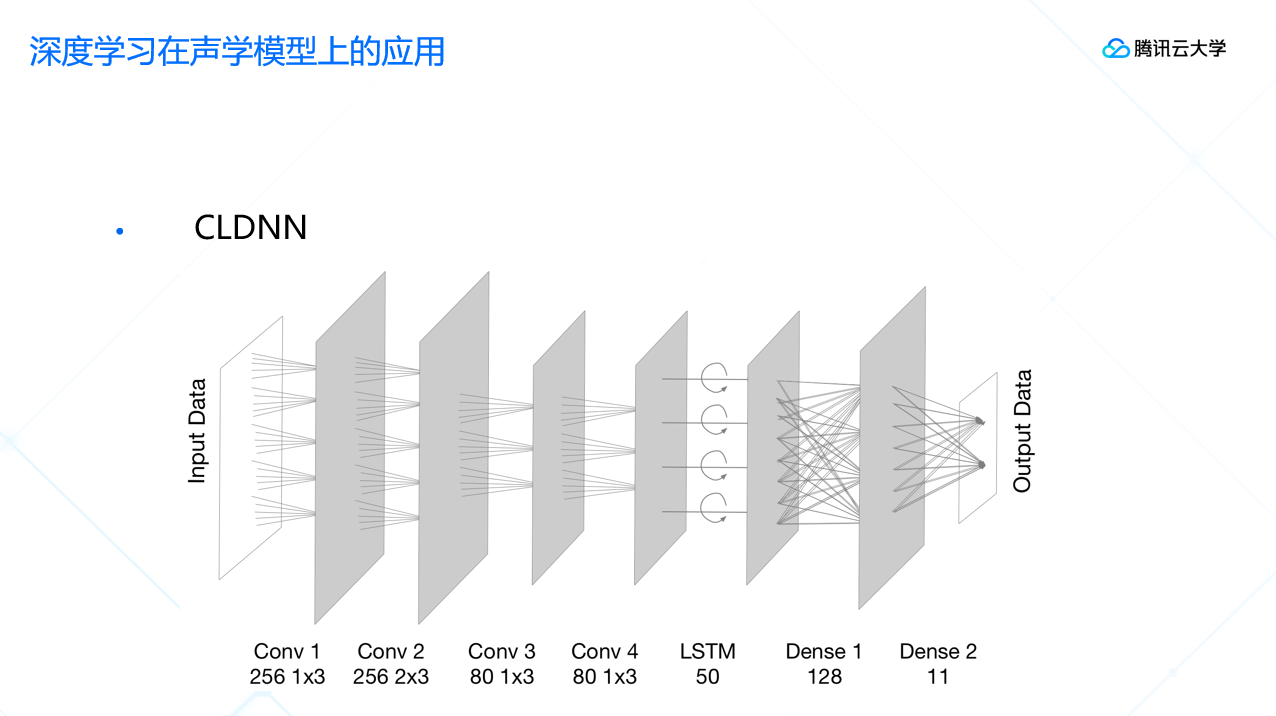
还有一种网络是CLDNN网络,这种网络可以训练出效果比较好的声学模型。
四、语音识别产品的应用场景
智能语音识别技术能将自动将人类的语音内容转换为相应的文字,这种技术到底运用在哪些商业化场景中?我们以腾讯云语音识别产品为例讲一讲。
手机端应用内置语音输入识别
APP,微信公众号与小程序等应用内,不便文字输入场景进行语音输入识别,如手机语音助手,手机端游戏,手机输入法等应用中,手机内置语音输入法已成为人机交互的标准配置。

大型呼叫中心客服电话录音质检
对于呼叫中心质检,人工处理速度慢,成本高,标准很难统一,而基于语音识别能力包装的智能质检能够克服当前存在的痛点,降本增效。

审讯庭审记录(会议纪要)
公检法系统通过语音识别可以大幅提升效率,在法庭庭审过程中,减少了庭审记录员核对时间,让法庭开庭数量有提升,公安监狱笔录过程中,笔录内容真实,提升审讯效率。

目前,腾讯云的语音识别服务已经过微信、腾讯视频、王者荣耀等大量内部业务验证,同时也在线上线下大量外部客户业务场景下成功落地。关于如何使用腾讯云语音识别产品,大家可以点击【阅读原文】观看完整录播视频,也可以在腾讯云官网体验腾讯云的语音识别产品服务。
Q&A
Q:腾讯云ASR的识别率是多少?
A:这个主要看音频里的人说普通话是否标准,在比较安静的环境、普通话比较标准的话识别率在97%以上。
Q:一段音频文件中如果有2人或多人说话,能否根据声纹做智能分轨?
A:如果是2个人的话,可以做到话者的区分。
Q:是否支持本地化部署腾讯云ASR吗?
A:支持。
点击观看完整课程

腾讯云大学是腾讯云旗下面向云生态用户的一站式学习成长平台。腾讯云大学大咖分享邀请行业技术大咖,为你提供免费、专业、行业最新技术动态分享。