一、前言
用户在腾讯云上自建的 ES 集群或者在其它云厂商购买的 ES 集群,如果要迁移至腾讯云 ES(适用于大部分普通索引迁移),用户可以根据自己的业务需要选择合适的迁移方案。如果业务可以停服或者可以暂停写操作,可以使用以下几种方式进行数据迁移:
- COS 快照
- logstash
- elasticsearch-dump
具体实践可参考官网文档:https://cloud.tencent.com/document/product/845/35568
二、常见报错场景
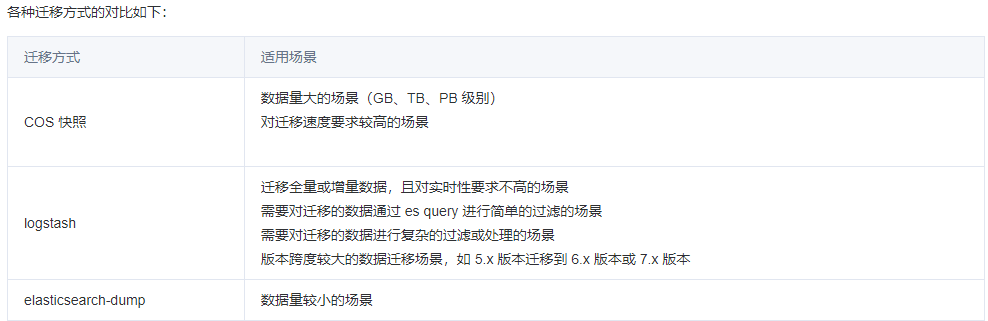
1、创建repository 仓库报错my_cos_backup path is not accessible on master node
{
"error" : {
"root_cause" : [
{
"type" : "repository_verification_exception",
"reason" : "[my_cos_backup] path is not accessible on master node"
}
],
"type" : "repository_verification_exception",
"reason" : "[my_cos_backup] path is not accessible on master node",
"caused_by" : {
"type" : "i_o_exception",
"reason" : "Exception when write blob master.dat",
"caused_by" : {
"type" : "cos_service_exception",
"reason" : "cos_service_exception: The specified bucket does not exist. (Status Code: 404; Error Code: NoSuchBucket; Request ID: NjUzYzkwYmRfMzAxNzUyMWVfMjJmYmNfYTJkOGY1Ng==); Trace ID: OGVmYzZiMmQzYjA2OWNhODk0NTRkMTBiOWVmMDAxODc1NGE1MWY0MzY2NTg1MzM1OTY3MDliYzY2YTQ0ZThhMDFhOWZlZTQxMzRkMTQ2NGM4MmFlZDk1MTQzM2UyMTll"
}
}
},
"status" : 500
}
报错原因:bucket和app_id参数入参有误,bucket经常会有客户把桶appid完整复制上导致出错、app_id填成UIN也会有这个问题。
解决方案:
bucket:COS Bucket 名字,不带 appId 后缀的 bucket 名
app_id:腾讯云账号 APPID
二、cos快照恢复集群red,"explanation": "node does not match index setting index.routing.allocation.require filters temperature:\"hot\""
报错原因:通常是由于客户将热节点的集群通过cos快照迁移到温节点的集群会出现这个问题,这个意思是说用户在目标集群恢复的时候 因为磁盘属性不同,导致数据恢复失败。 做快照的集群是ssd的,SSD磁盘的数据节点默认是hot属性的, 需要恢复的集群时高性能云硬盘,高性能云盘的数据节点默认是warm属性的 。从hot节点集群恢复到warm节点集群就会出现这个冲突异常。
解决方案:
先删除之前恢复的索引,然后在恢复的命令中,加以下相关参数
POST _snapshot/cos_backup/snapshot_名称/_restore
{
"indices": "*,-.monitoring*,-.security*,-.kibana*",
"ignore_unavailable": true,
"ignore_index_settings": [
"index.routing.allocation.require.temperature"
]
}三、ES 8.8.1版本创建仓库报错{"error":{"root_cause":[{"type":"repository_exception","reason":"my_cos_repository No region defined for cos repository"}],"type":"repository_exception","reason":"my_cos_repository failed to create repository","caused_by":{"type":"repository_exception","reason":"my_cos_repository No region defined for cos repository"}},"status":500}
curl -u 'elastic:xxxx' -X PUT 'http://xxxxx:9200/_snapshot/my_cos_repository' -H "Content-Type: application/json" -d '
{
"type": "cos",
"settings": {
"bucket": "xxx",
"region": "ap-shanghai",
"access_key_id": "XXX",
"access_key_secret": "XXX",
"base_path": "/",
"app_id": "xxxx"
}
}
' 解决方案:
8.8.1版本需要这样创建
PUT _snapshot/my_cos_backup
{
"type": "cos",
"settings": {
"compress": true,
"chunk_size": "500mb",
"cos": {
"client": {
"app_id": "xxxx",
"access_key_id": "xxxx",
"access_key_secret": "xxxx",
"bucket": "xxxx",
"region": "ap-guangzhou",
"base_path": "/"
}
}
}
}四、快照恢复报错
{
"statusCode": 400,
"error": "Bad Request",
"message": "Alias [.kibana] has more than one indices associated with it [[.kibana_2_backup, .kibana_1]], can't execute a single index op: [illegal_argument_exception] Alias [.kibana] has more than one indices associated with it [[.kibana_2_backup, .kibana_1]], can't execute a single index op"
}解决方案:
恢复ES备份的时候,把源集群的.kibana_1和.kibana_2也复制过来了,这个.kibana_2的别名是.kibana。导致冲突了。
首先移除.kibana_2别名
POST _aliases
{
"actions": [
{
"remove": {
"index": ".kibana_2",
"alias": ".kibana"
}
}
]
}关闭索引自动创建
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": false
}
}操作完成后重新进行恢复数据操作
多可用区集群增量恢复报错
{"unassigned_info":{"reason":"EXISTING_INDEX_RESTORED","details":"restore_source[my_cos_backup/snapshot_2]"},"node_allocation_decisions":[{"deciders":[{"explanation":"there are too many copies of the shard allocated to nodes with attribute [set], there are [3] total configured shard copies for this shard id and [3] total attribute values, expected the allocated shard count per attribute [2] to be less than or equal to the upper bound of the required number of shards per attribute [1]"}]},{"deciders":[{"explanation":"there are too many copies of the shard allocated to nodes with attribute [set], there are [3] total configured shard copies for this shard id and [3] total attribute values, expected the allocated shard count per attribute [2] to be less than or equal to the upper bound of the required number of shards per attribute [1]"}]},{"deciders":[{"explanation":"there are too many copies of the shard allocated to nodes with attribute [set], there are [3] total configured shard copies for this shard id and [3] total attribute values, expected the allocated shard count per attribute [2] to be less than or equal to the upper bound of the required number of shards per attribute [1]"}]},{"deciders":[{"explanation":"there are too many copies of the shard allocated to nodes with attribute [set], there are [3] total configured shard copies for this shard id and [3] total attribute values, expected the allocated shard count per attribute [2] to be less than or equal to the upper bound of the required number of shards per attribute [1]"}]},{"deciders":[{"explanation":"the shard cannot be allocated to the same node on which a copy of the shard already exists [[sel_pitem_his][2], node[Tg4tV6mcT22SO_0ZCfWHWA], [R], s[STARTED], a[id=X7H-v4fRQTaWnOPsu3j7KA]]"},{"explanation":"there are too many copies of the shard allocated to nodes with attribute [set], there are [3] total configured shard copies for this shard id and [3] total attribute values, expected the allocated shard count per attribute [2] to be less than or equal to the upper bound of the required number of shards per attribute [1]"}]},{"deciders":[{"explanation":"the shard cannot be allocated to the same node on which a copy of the shard already exists [[sel_pitem_his][2], node[b2RSlGbNR82IU_1j1HShJw], [P], s[STARTED], a[id=UXIVucaDQkyNSQ5syzrkwA]]"},{"explanation":"there are too many copies of the shard allocated to nodes with attribute [set], there are [3] total configured shard copies for this shard id and [3] total attribute values, expected the allocated shard count per attribute [2] to be less than or equal to the upper bound of the required number of shards per attribute [1]"}]}]}解决方案:
方案一
结合集群环境,计算副本数目
不需要调整的副本数目需要用以下公式计算:
ceil{(replicas + 1) / (可用区+1)} = ceil{(replicas + 1) / 可用区}
repilcas <= 总节点数 -1
以2可用区,单可用区3节点为例
replicas可用值为:0,1,3
然后获取集群所有索引分片数目,如果和上述结果不一致,则挂起
方案二
换一个思路,分片迁移出现异常是由于awareness.attributes 中set属性限制导致,流程执行到checkScaleInCvmCluster后,执行如下命令:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "ip"
},
"transient": {
"cluster.routing.allocation.awareness.attributes": "ip"
}
}执行完上述命令后,卡住的分片随后会自动迁移,并且老的可用区节点自动下线, "cluster.routing.allocation.awareness.attributes": "ip"会自动还原为 "cluster.routing.allocation.awareness.attributes" : "set,ip"