云监控系统,可以做到实时的检测云产品的关键指标,并可自定义告警阈值和发送告警的规则。配置监控的步骤比较简单,跟着页面提示勾勾选选即可完成。但是深究起来,发现里面埋着很多数学计算的复杂逻辑。
本篇重点解决其中一种常见疑惑,告警通知与监控系统经常对不上,怀疑告警不准确。
问题背景:
1. mongo数据库的告警通知:
告警内容:云数据库MongoDB | 云数据库(MongoDB)单位时间延迟次数(100ms以上)>2000次
告警对象:cmgo-xxxx
当前数据:4123次
触发时间:2020-02-04 18:30:00(UTC+08:00)
持续时间:5分钟
2. 查看系统监控,对应时间最高700-800的样子,并没有通知的4123次。
下面通过一个测试,详细阐述告警策略配置和监控值之间的隐秘关系。
2 条策略配置分别如下,均是根据5分钟的监控数据做告警,但是区别较大:


区别一:统计周期不同。统计周期代表指标数值采集的粒度,以及对应会采用的不同的聚合方法。
区别二:持续周期不同。持续周期代表周期内,超过阈值的采集点持续一定时间,才会触发告警。
那么两个策略分别表示:
mongo-1minute: 使用采集粒度为1分钟的监控,持续有连续6个采集点(5个间隔)的值大于100次,才会告警;
mongo-5minute: 使用采集粒度为5分钟的监控,持续有连续2个采集点(1个间隔)的值大于100次,才会告警。
下面看控制台监控曲线:
默认页面,显示时间粒度为1分钟,监控值在25次左右波动。
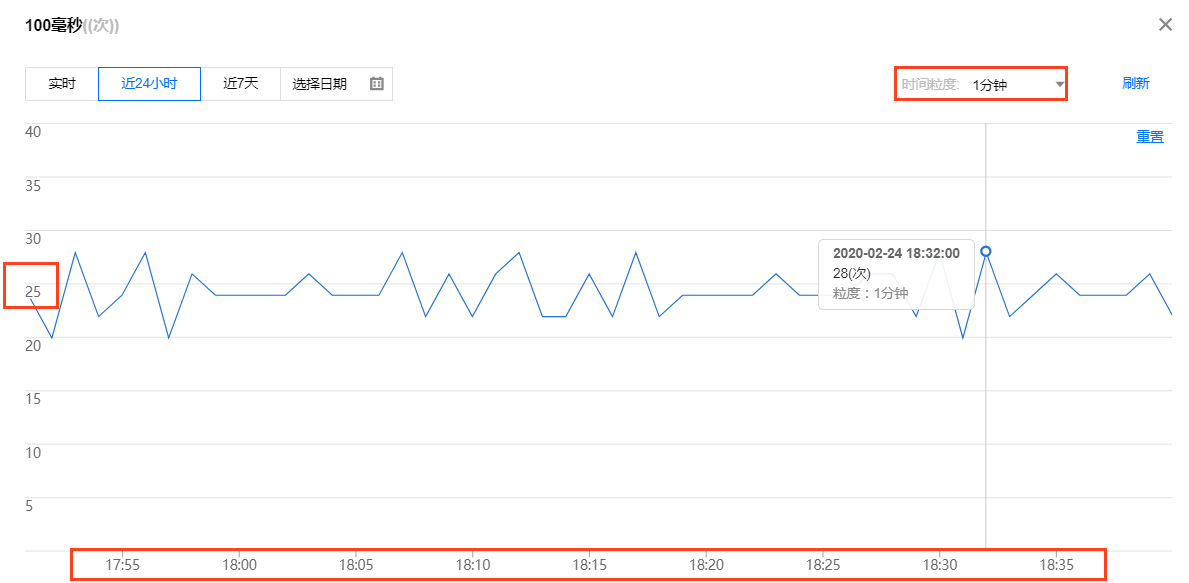
更换时间粒度为5分钟,因为指标单位为次数,会经过sum聚合,指标值为125次左右波动。
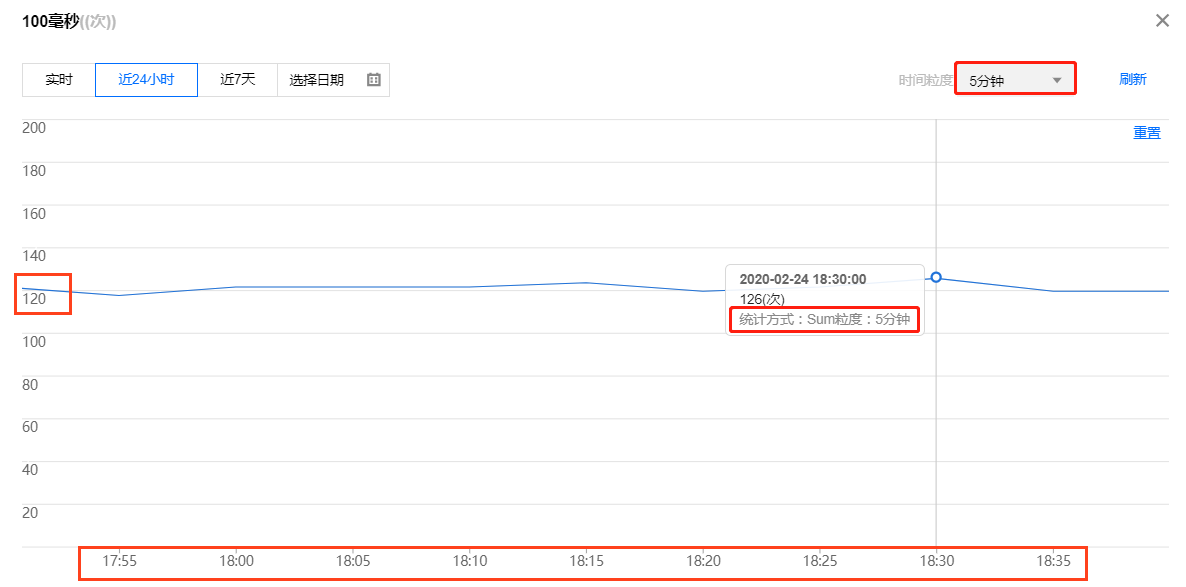
可见监控数据采集粒度和聚合的方式不同,会得到不同的监控曲线。
那么两个告警策略,是否会触发告警,哪个策略会触发告警呢?
答案是:
mongo-5minute 触发了告警,对应使用粒度5分钟的曲线,连续2个点超过100,即触发了告警。
mongo-1minute 没有触发告警,对应使用监控粒度1分钟的曲线,没有超过100次的点,因此没有告警。
再举一例,加深理解。
修改mongo-1minute 的阈值为20次,其余不变,那么根据如下监控,18:45分取值20不符合大于20的条件,18:51时为第6个取值超过20的点(分别是18:46,18:47,18:48,18:49,18:50,18:51),触发告警。
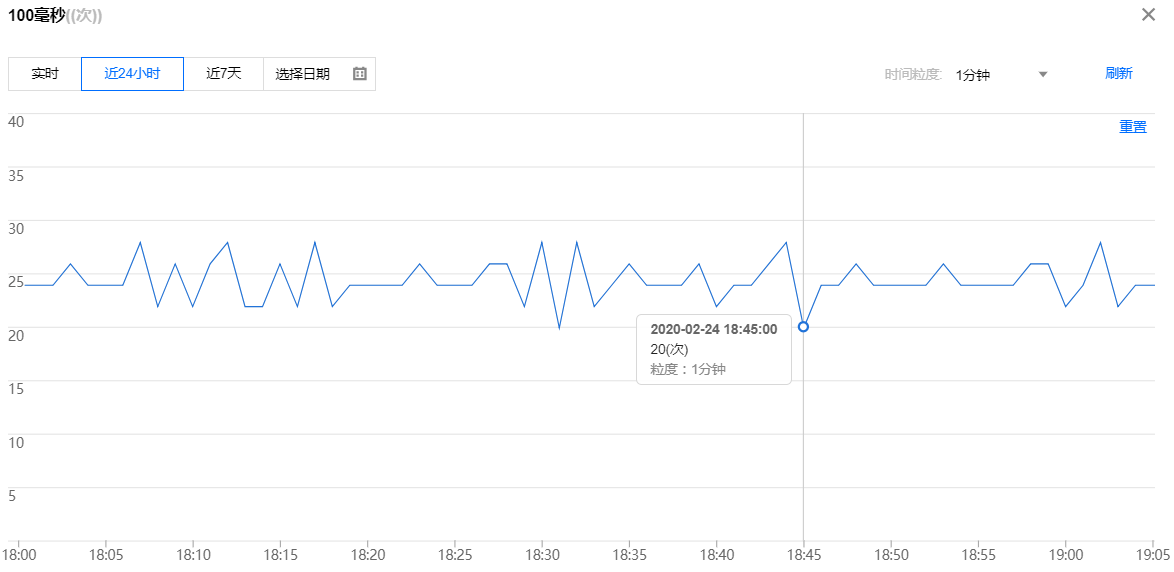
当然,除了这里举例的指标采用的sum聚合方式外,还有Max、Min、Avg等不同的聚合方式,结合指标的真实含义来定义。
最后回到最初的那个疑问,便比较容易解答。
重新查看云监控的告警配置,发现采用的统计周期为5分钟,更换监控粒度为5分钟且sum的聚合方式后,查看到对应时间峰值为4123,监控与告警完全一致,符合预期。