文 / 赵军
整理 / LiveVideoStack
大家好,我是腾讯云的赵军,同时我也是FFmpeg决策委员会委员、开源爱好者。在2018年成为FFmpeg maintainer,2019年入选 FFmpeg 决策委员会(voting committee),具备丰富的基于Linux 的Router/Gateway 开发经验,并持续关注Linux 在网络方面发展。曾开发基于Linux 的高清/ 标清H.264/MPEG2视频解码器及图像处理平台。曾在Intel DCG/NPG 负责基于FFmpeg以及Intel平台上的视频编码/解码/转码、视频后处理、视频分析的硬件加速的工作。目前在腾讯云负责视频云的系统优化相关工作,除去支持公司内部的项目开发以外,也在持续向FFmpeg社区提交patch,同时也倡导引领同事以开放的心态拥抱开源。
今天的演讲将分为明眸、智眸、云剪和开源四个部分来讲解,其中明眸主要针对音视频编解码与画质增强方案,智眸主要涉及智能媒体检索、分析和审核方案,云剪主要提供在线媒体内容生产方案,而开源则是本次演讲中将重点介绍的内容。
音视频发展现状

在腾讯云团队看来,目前音视频技术的发展现状更偏向于清晰、流畅和品质这三者的博弈,对于视频来说,体育赛事、游戏等领域对直播清晰度要求不断提升,国家政策也在鼓励4K和8K的增长,这些因素使得超高清晰度视频内容成为音视频技术发展的重要方向,与此同时,人们开始追求更多的趣味性和附加能力,但硬件计算能力或者软件性能并没完全跟上,这使得成像品质以及其他附属能力所需要的计算能力也位于了问题之列;一如既往的,无论是4G还是即将到来的5G时代,网络的制约在能预计的时间内,依然也还是一个不可忽视的影响因素之一。
1. 音视频技术+AI,打造从内容生产、极速高清到视频识别分析全链路产品
1.1 明眸:极速高清-智能动态编码
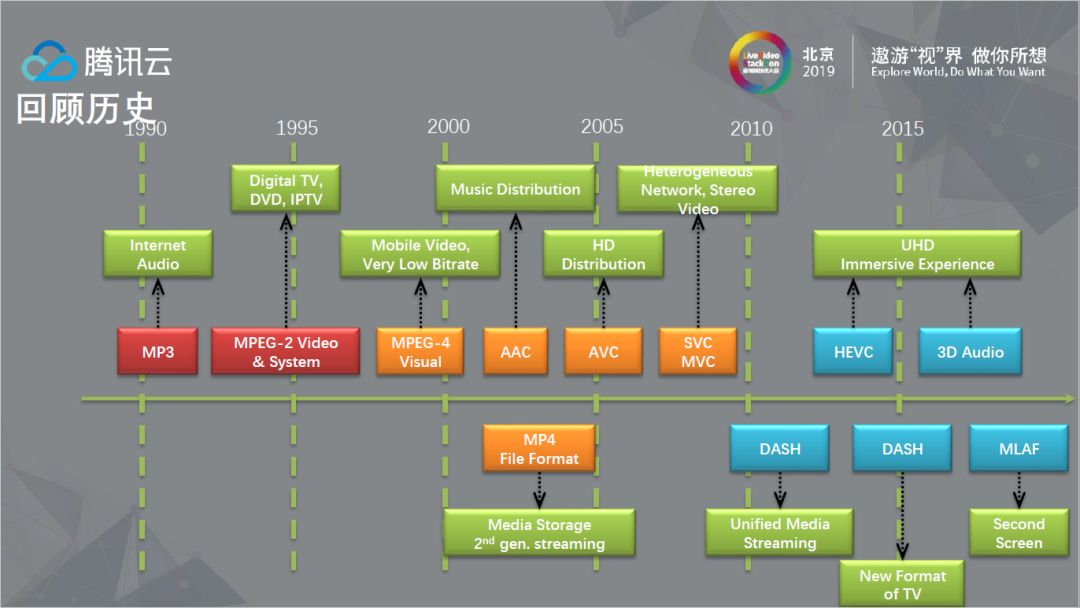
提到极速高清就不得不聊聊视频编码,上图从Codec和系统工具的角度,以MPEG组织为基准描述了发展历史,图片下方是容器格式,做过工程的人都了解,很多时候相比Codec,容器格式有时会暴露很多的工程问题。图中色块分别代表不同阶段的技术发展,红色部分已经是历史,橙色部分表示过渡,蓝色部分更像是现在和不远的将来的交界。

明眸主体由场景识别、前置处理和编码算法动态优化三部分组成,场景识别主要是对场景进行切分,根据场景预设编码模板。其次前置处理主要解决的问题是多次转码带来的副作用,最后在基于以上两部分的前提下做编码算法的动态优化。

当场景识别、前置处理和编码算法动态优化三部分做完之后,我们可以得到一些基本的结论,由于直播客户更在意主观质量,明眸以VMAF为目标做开发。简单提及一下,腾讯云在对VMAF和PSNR做比较时发现,如果VMAF的分数在70分左右甚至更高,VMAF的分数会与PSNR正相关,倍数关系大概在2.5-3倍之间,反之,我们也发现,PSNR分数比较高时,VMAF的分数不一定高,所以我们认为,以VMAF为目标的优化也大概率的涵盖了PSNR的目标值。明眸可以在相同码率下将VMAF评分提升10+,同VMAF分下码率节省可以达到30%左右。当然VMAF也存在一些问题,比如对小分辨率的适配并不是很好,这可能与Netflix自身由点播内容居多,并且片源的质量都非常高有关。
1.2 智眸:智能媒体生产平台
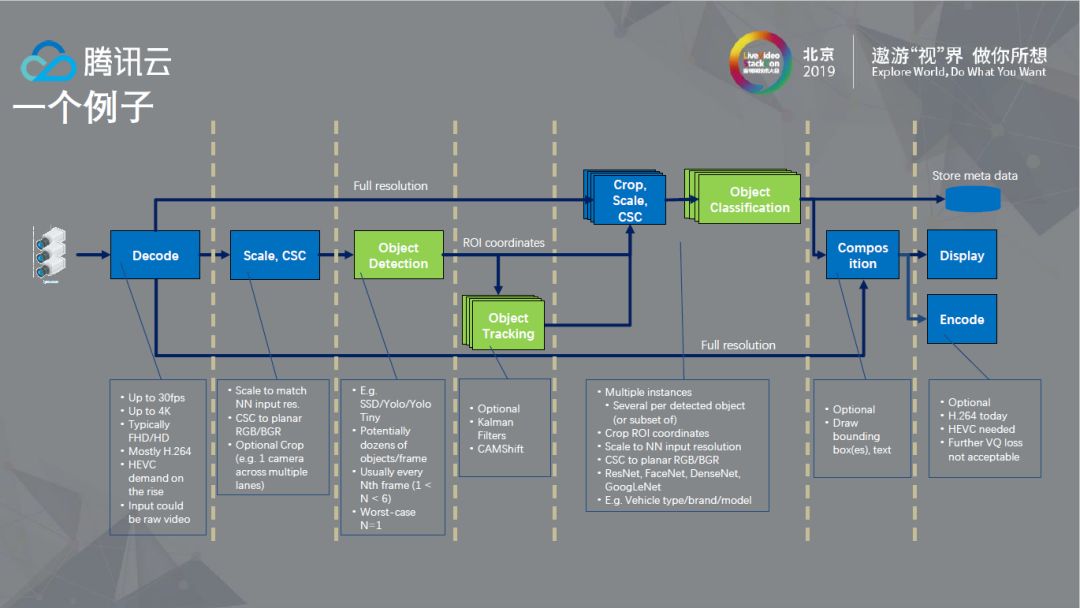
从上图可以看到目前视频AI比较通用的流程,视频源从左向右边,解码之后如果要做对象探测会有一个Scale和CSC,如果做Tracking会向下走,如果做ROI coordinates会向上进行正常的解码。这个流程图看似简单,但在工程中需要各种各样的考量,其中的每一个点都可能会成为潜在的性能瓶颈。
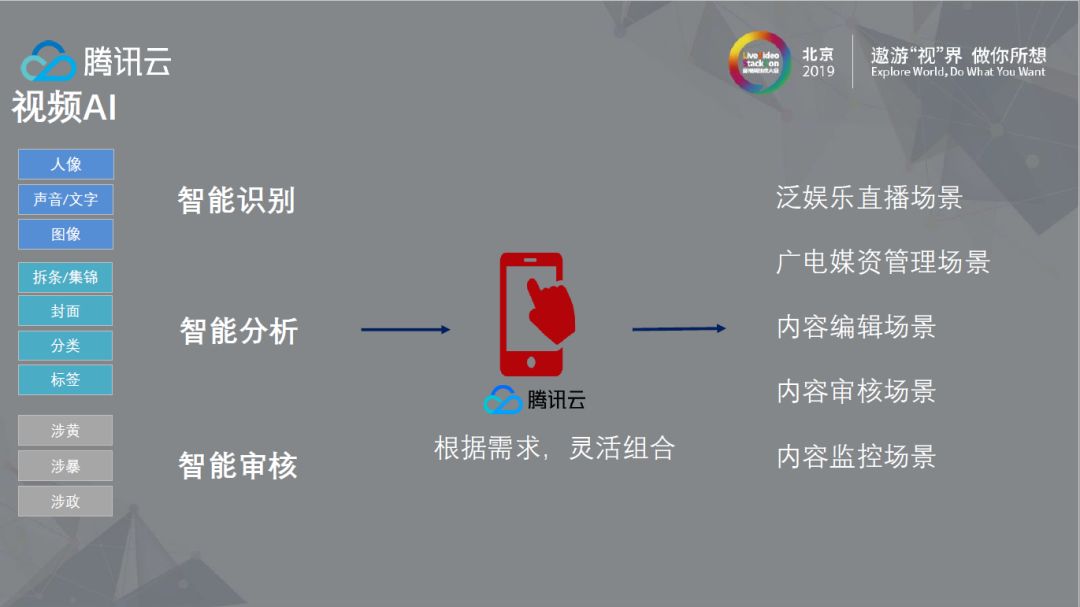
以上是智眸的一些基本能力,包括人像、声音/文字、图像以及基本物体的识别、智能分析和审核,它可以根据需求灵活组合,图中也列出了很多的应用场景。
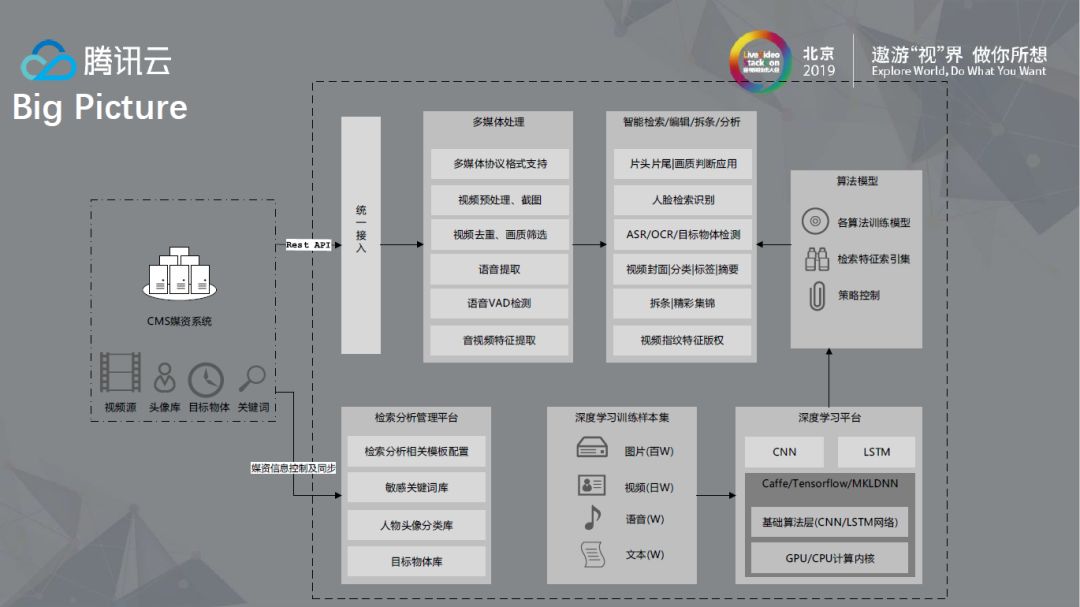
在客户使用和对接时,基本上是以Rest API做对接,图中清晰展示了整个流程运行起来的全貌。
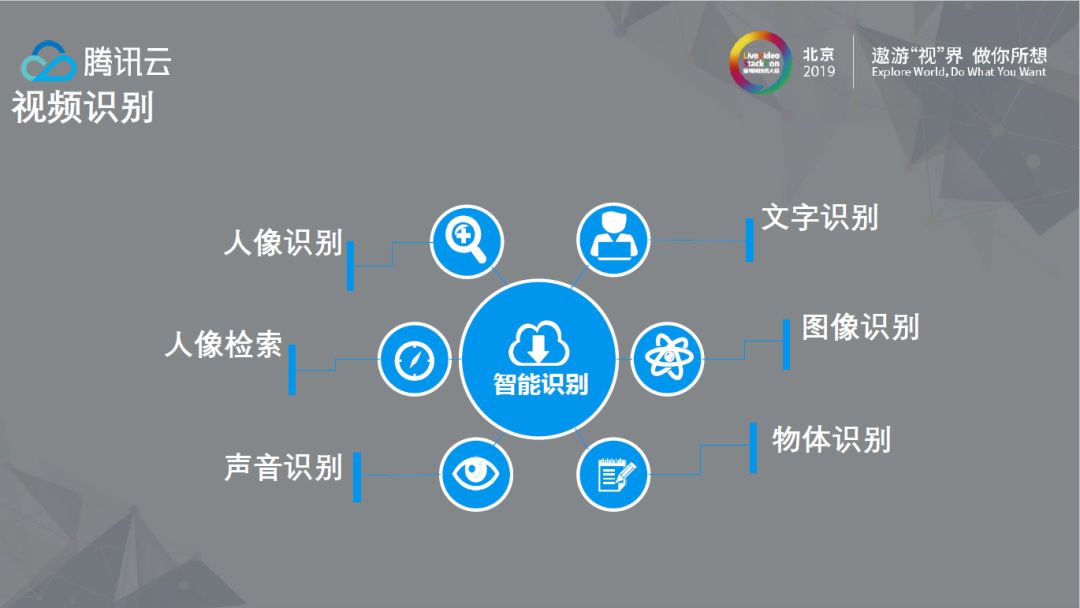
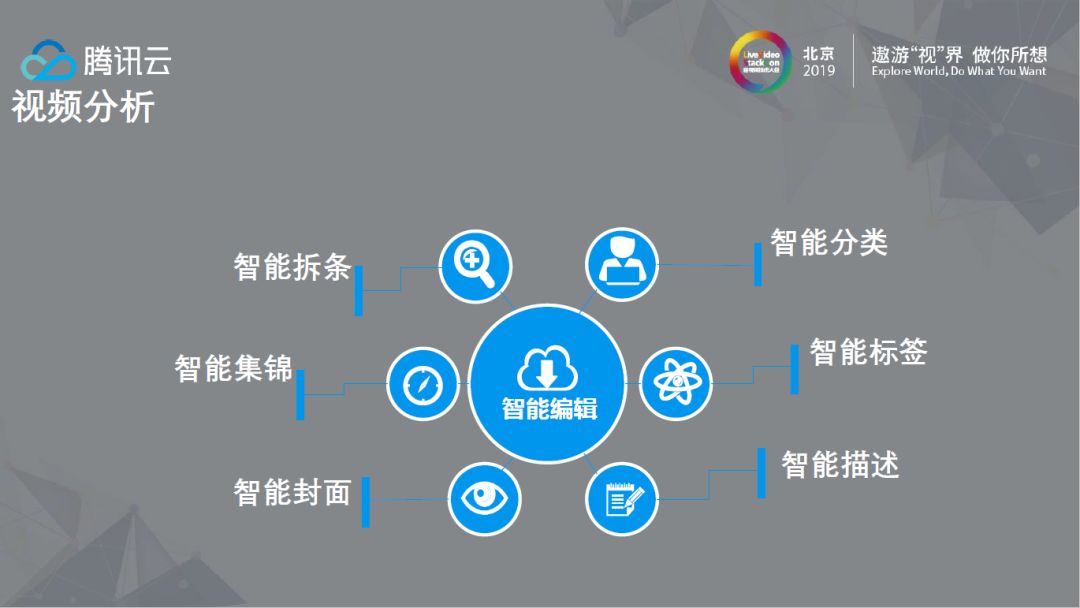
以上是腾讯云在视频识别和视频分析中要解决的问题,其中智能拆条需要根据内容或关键人物出现进行拆分,智能集锦应用在体育场景中较多,比如制作进球或得分集锦。
1.3 云剪:助力提升视频生产效能

如果将视频当作一条链路来考虑,可以看到视频从最初上传到制作处理,再到内容管理、传输分发,最后在终端播放,其中制作与处理部分腾讯云存在一些技术缺失,因此腾讯云做了云剪来弥补这部分的功能,主要目的是让用户实现在云端不需要SDK就可以对视频数据做处理,这种场景中比较具有代表性的是电竞行业,它的素材可能在PC端已经做好,不用在移动端进行处理。
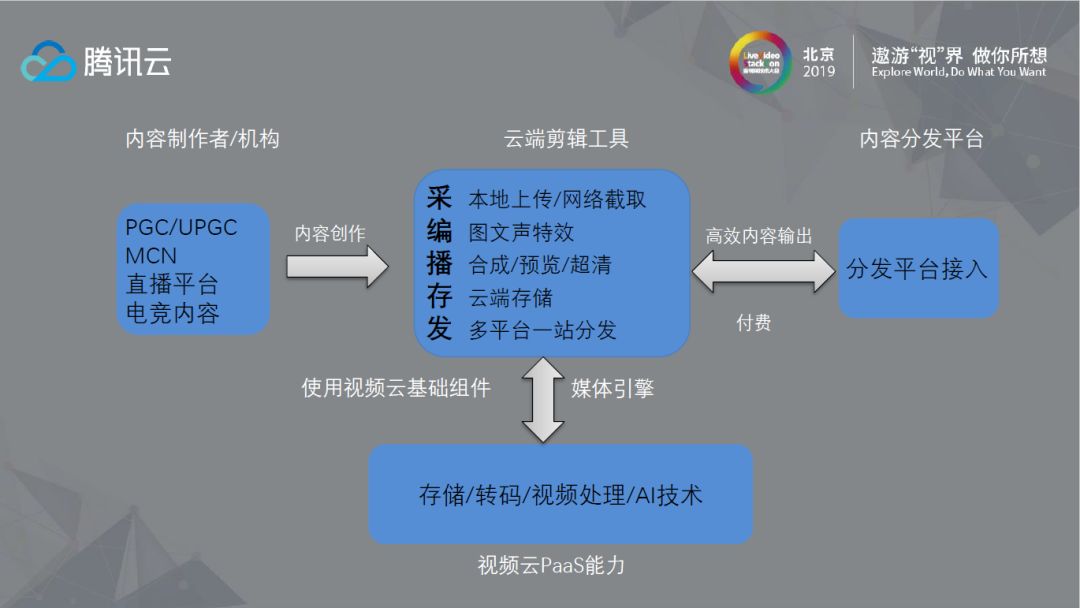
云剪目前也是一个把腾讯云已有的能力打包,用以解决行业痛点的一个综合性质的产品。
2. 拥抱开源,以开放的心态加速技术升级
2.1 FFmpeg简介

从事多媒体行业,基本没有人可以完全忽视 FFmpeg这个开源界中最流行的多媒体库,FFmpeg库有着多平台的支持,无论是服务器Linux、移动端Android、PC 端的MAC以及Windows都可以使用,使用方式分为tools和C libraries两种,tools包括ffmpeg、ffplay、ffprobe等,另一种方式则是C libraries,但C libraries场景时候,我们也发现它在某些场景下缺乏一定的灵活性。
2.2 开源与协同

在刚进腾讯云时,大的部门中有38个repo都叫FFmpeg,这可能也是业务快速发展过程中所经历的一些痛处。我们开始尝试做一个统一版本,尝试将部门将不同repo中,比较有价值的部分提炼出来,构造一个内部完整而统一的Repo;另一方面,我们认为,既然使用的FFmpeg来自开源,我们在它上面的工作成果,也应该让它最终返回到开源社区去。这样,一方面可以使得原来内部的FFmpeg库统一,减少内部的重复性工作,另一方面对于社区来说腾讯云及时将Feature、Bug Fix、性能优化、文档更新和samples反馈给它,在这个过程中,也顺势打造了一个非常完整流畅的工作流程,用于支持内部的开发,也用于反馈给开源社区。
2.3 接口与框架

提及接口和框架的问题,首先想到的是上面这段话,简单说来,犹如为院子造墙,什么放在墙外,什么放在墙内,门开在什么地方,还要提防想着把墙推倒的人;在实际的项目中,也有类似的问题,如果项目要和别人合作,首先需要明确两人的职责,这是最容易出问题的部分;具体到FFmpeg,一方面,它需要解决怎么屏蔽不同的Os、硬件平台和Codec细节,并保持使用过程中能灵活构建media pipeline的能力,与此同时,在AI大潮中,它也面临着是否需要集成Deep Learning框架到AVFilter模块的这种现实问题。
2.4 性能之痛

性能在多媒体技术中一直是一个永恒的话题,例如压缩技术在十年间可以提升50%的压缩率,但复杂度却会提升10倍以上,这对计算能力提出了一个非常大的挑战。我们知道,所有优化的前提是理解算法与数据流向,并且有Profiling的数据作为支撑,除了算法上面的提升以外,也需要更好更充分的利用已有的硬件资源。大部分情况下,硬件性能优化是在CPU和GPU上完成。以FFmpeg为例,它的CPU优化在上体现在多线程和SIMD优化两个方面,在解码过程中使用了基于Frame和Slice的线程以及更为底层的SIMD优化,在Filter中只用了基于Slice的线程与SIMD。GPU一般来说有二个优化方向,一个是专有硬件,比如Intel GPU中的QSV部分,一块是通用计算加速和3D渲染,分别是CUDA,以及尝试和CUDA对抗的OpenCL,还有历史悠久的OpenGL以及它的继任者Vulkan。
2.4.1 CPU加速
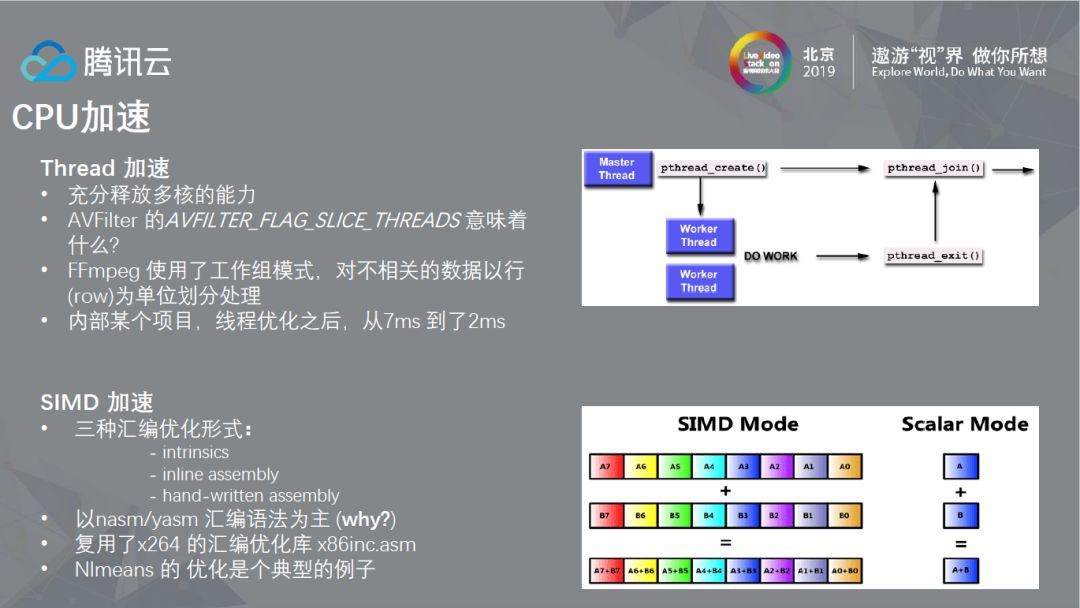
CPU的加速中,首先想到的是线程,本质上说,使用线程能力优化是想充分释放多核的能力,目前对于大部分的PC来说以4线程或8线程居多,但对于Sever来说核数可能会更多,目前的环境多以48或96线程为主,因此在不互相影响的前提下调动多核的积极性是CPU加速所要解决的首要问题。在FFmpeg中,以AVFilter为例,他有一个AVFILTER_FLAG_SLICE_THREADS的标识,很多实现上,是把一个Frame中不相关的数据以行或者列的方式做加速,以我的经验来看,如果程序出现性能问题,首先应该考虑的问题是是否使用了CPU的多线程能力。第二种CPU加速方式是SIMD加速,SIMD汇编优化形式一般有intrinsics、inline assembly、hand-written assembly三种,FFmpeg汇编优化以第三种为主,这是由于intrinsics在封装是有些潜在的性能损失,相同的功能用intrinsics和hand-written assembly去解决,前者可能会引入一些性能损失;而inline assembly的问题在于比较难以跨平台,比如Linux和Windows,而FFmpeg的跨平台是它的目标之一。所以,现在FFmpeg社区更偏向于hand-written assembly方式,另外,大部分的hand-written assembly汇编优化其实是以x264的汇编优化库为基础做的,并且选择nasm为汇编器(不选择yasm是由于它没有支持最新的一些CPU指令)。
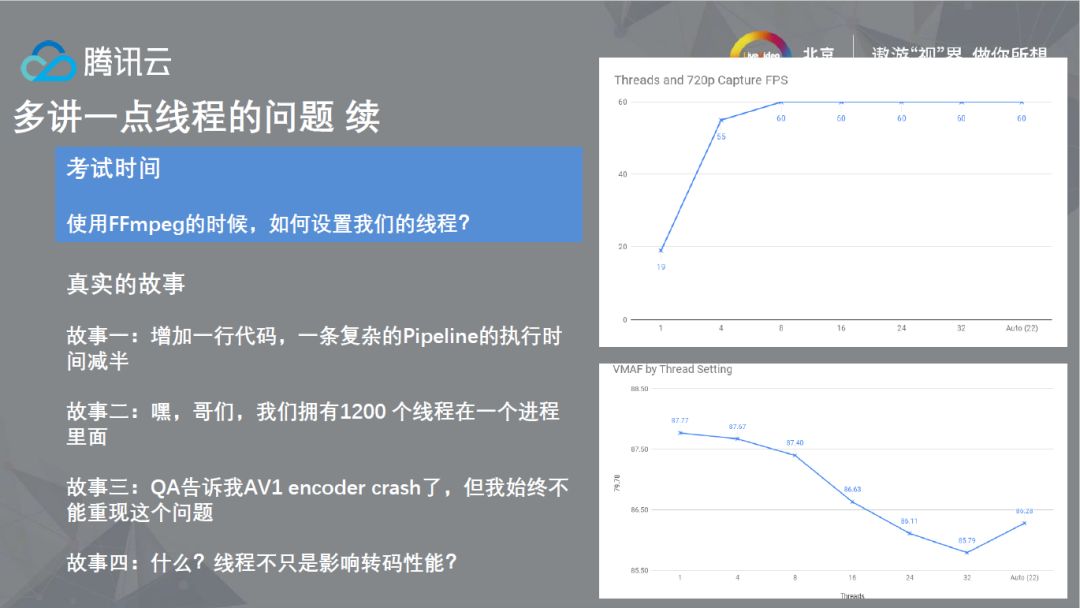
提及了多线程优化,我们也以使用者的角度看着,使用FFmpeg API的时候,如何设置线程。对于FFmpeg来说,大部分的情况下可能并未考虑在高负载/重耦合场景下运行的情况,FFmpeg在解码时的默认策略是根据CPU的核数创建线程,目前大部分的PC设备都是四核八线程的配置,但一个典型的数据中心的Server有48核96线程,但解码器实际上并没法同时使用这么多的核,这种情况下,需要自己控制解码线程,而非使用FFmpeg的默认策略,我们也遇到过使用FFmpeg API时候,默认创建超过1200个线程的问题。第三个是BUG的问题,FFmpeg集成时很多时候只在PC端测试过,并未在拥有这么多核的服务器上测试,使得FFmpeg的VP9encoder当时甚至会在多核服器上crash,种种事情表明,在多核服务器下使用FFmpeg,需要在多线程上做更细致的控制,而仅仅只使用其默认线程策略。另外,还有一点要提及,线程并不只是影响性能,它也会影响图像质量,我们也发现,在编码时候,随着编码器使用的线程数目的增加,其VMAF分数可能会降低。在服务器端,使用FFmpeg这类框架时候,如何在保证性能以及图像质量的前提下,怎么更好的控制线程(使用CPU的计算能力),是个非常有趣的问题。
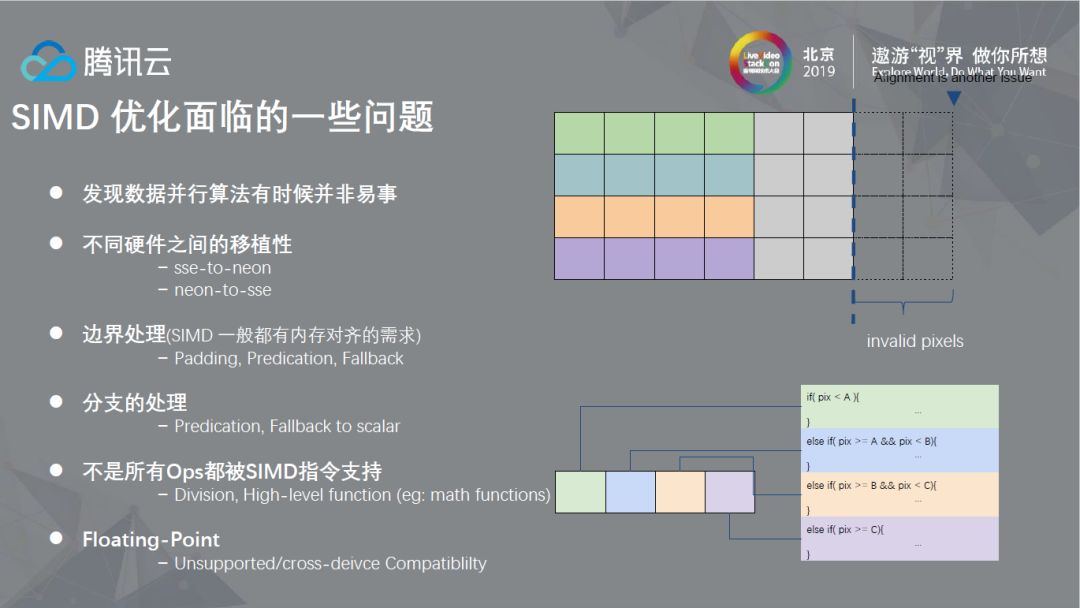
在性能优化过程中,SIMD优化也面临着一些挑战,一是在使用SIMD优化时需要将算法改造成适合SIMD的算法,这并不总是一件容易的事情,其次需要考虑不同硬件之间的移植性。另外,对于SIMD一般都有内容对齐的需求,且算法上要尽量避免分支使得数据可以流化,同时,算法上的一些操作并不都被SIMD指令支持(相较而言x86的SIMD指令要比arm更为丰富一些);另外,还有考虑不同硬件之间浮点算法的精确性,种种挑战,使得SIMD的优化的使用上并不特别的便利。
2.4.2 GPU优化

当时我基于英特尔的GPU做整个转码链路的优化,Codec解码主要有两套plugins,一套是基于MSDK,类似FFmpeg集成x264后依赖第三方去做解码。第二套思路是基于VAAPI的interface去做,使得整个硬件加速Codec是FFmpeg自身的一部分。除了做Codec的加速以外,团队同时还用OpenCL做了一些AVFiltrer的优化,这两种优化之间各有优势。顺带提及一句,即使GPU已经加速,在API的角度依然无法判断是否使用了GPU资源,这个问题目前只能归结到FFmpeg API的设计缺陷。另外,关于更多GPU的优化问题,可以参考我之前的一些文章(FFmpeg在Intel GPU上的硬件加速与优化)。