一、前言:
近年来,随着深度学习、大数据、人工智能、AI等技术领域的不断发展,机器学习是目前最火热的人工智能分支之一,是使用大量数据训练计算机程序,以实现智能决策、语音识别、图像处理等任务。
作者也是经过了以上几个阶段的软件开发历程,从Web时代编程、到云时代分布式编程,到如今的AI时代,传统编程是人类程序员手动编写代码来实现特定的功能,而机器学习是通过让计算机程序从数据中学习,自动地提取特征和规律来实现功能。
如何解决人工智能(机器学习)模型训练与推理、高性能计算等,往往是对于算法、算力和大数据都是实现大规模应用的必备条件。
GPU的广泛应用促进了AI技术的发展。通过GPU的高速计算能力,开发者可以更快地训练模型、测试算法,从而促进AI技术的迅速发展。GPU的出现和发展,也为AI领域的新算法、新模型的研发提供了更多的可能性。

最近腾讯云推出了一款“高性能应用服务HAI”,是一款面向 Al、科学计算的 GPU 应用服务产品,以应用为中心,匹配GPU云算力资源,AI 2.0时代 GPU 新品,预装LLM、AI作画、数据科学等高性能应用,实现即插即用,助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用。

二、即生"瑜"(腾讯云GPU云服务器)何生"亮"(高性能应用服务HAI):
平时接触的AI领域中,大多数搭载GPU云服务器的AI服务器可以覆盖更多的应用场景,尤其在人工智能领域的应用相当多。接下来,让我们先了解一下GPU云服务器的一些概念,只有知已知彼才能百战不殆,进行有效的比较优势与劣势,才能有针对性的选择权。
1. 腾讯云GPU服务器:
GPU 云服务器(Cloud GPU Service,GPU)是提供 GPU 算力的弹性计算服务,具有超强的并行计算能力,作为 IaaS 层的尖兵利器,服务于深度学习训练、科学计算、图形图像处理、视频编解码等场景。腾讯云随时提供触手可得的算力,有效缓解您的计算压力,提升业务效率与竞争力。
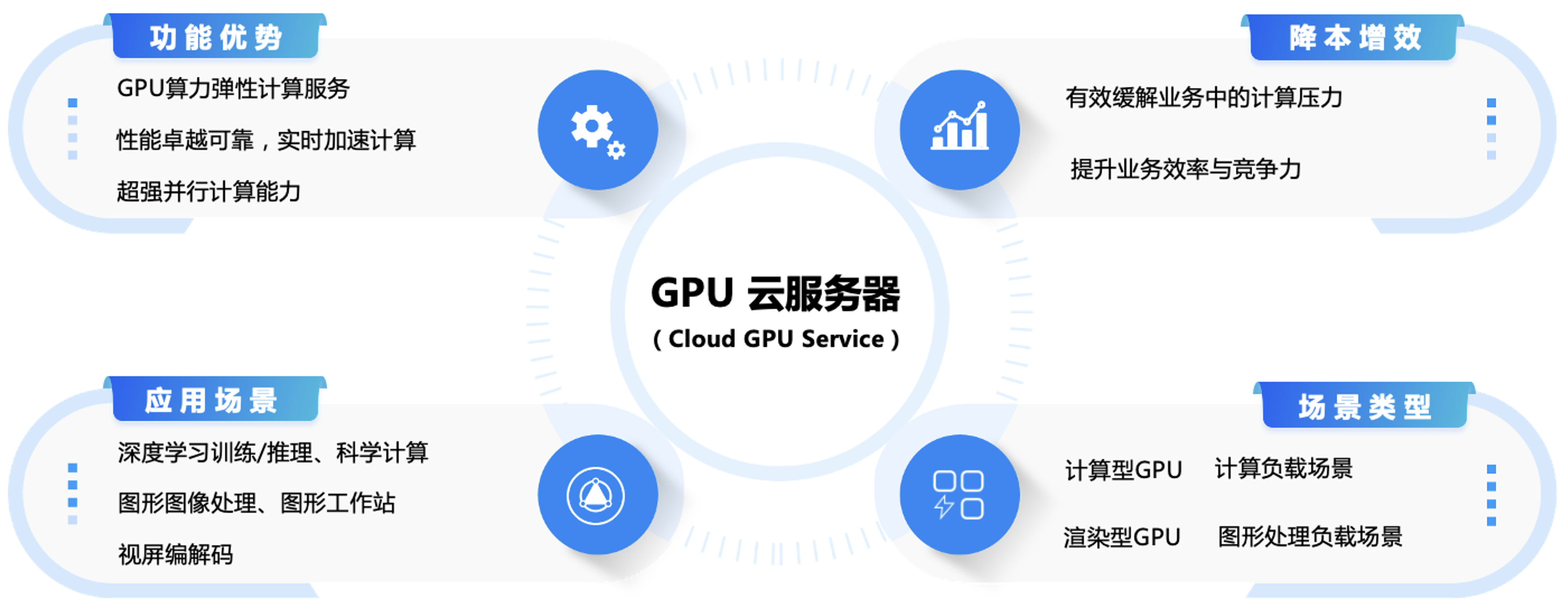
2. 腾讯云GPU云服务器的应用场景:
GPU计算型应用场景:

GPU渲染型应用场景:

三、高性能应用服务HAI介绍:
“高性能应用服务HAI”,它具有澎湃算力,即开即用,基于腾讯云GPU云服务器底层算力,提供开箱即用的高性能云服务。以应用为中心,匹配GPU云算力资源,助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用。
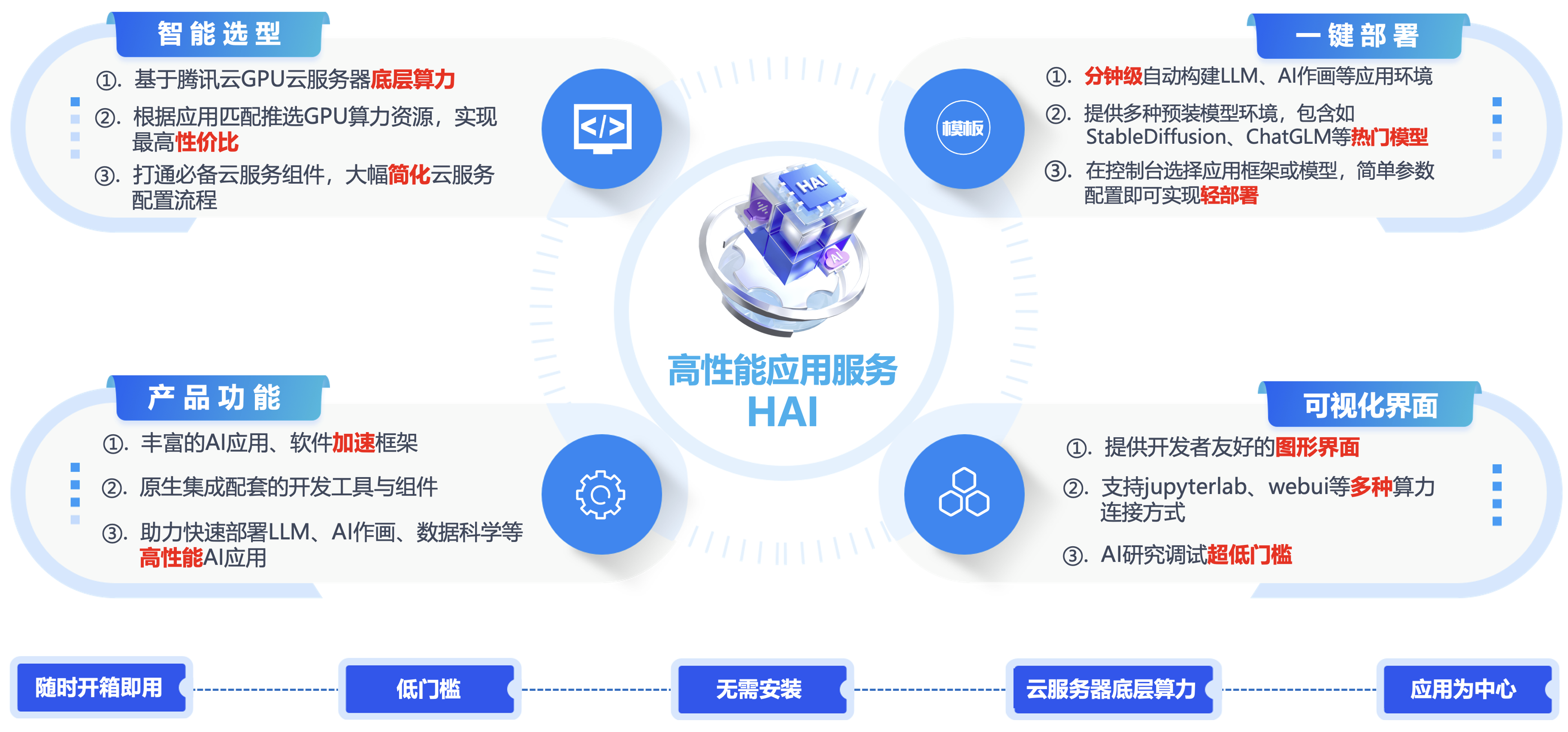
尤其值得一提的是针对开发者,使用可视化的webUI界面和“可视化IDE”的jupyterlab大大的降低了调试的复杂度、降低应用使用的门槛,甚至经过简单的培训,让非开发者(运维人员)也可以参与到使用中来。
1. 横向对比,青出于蓝:
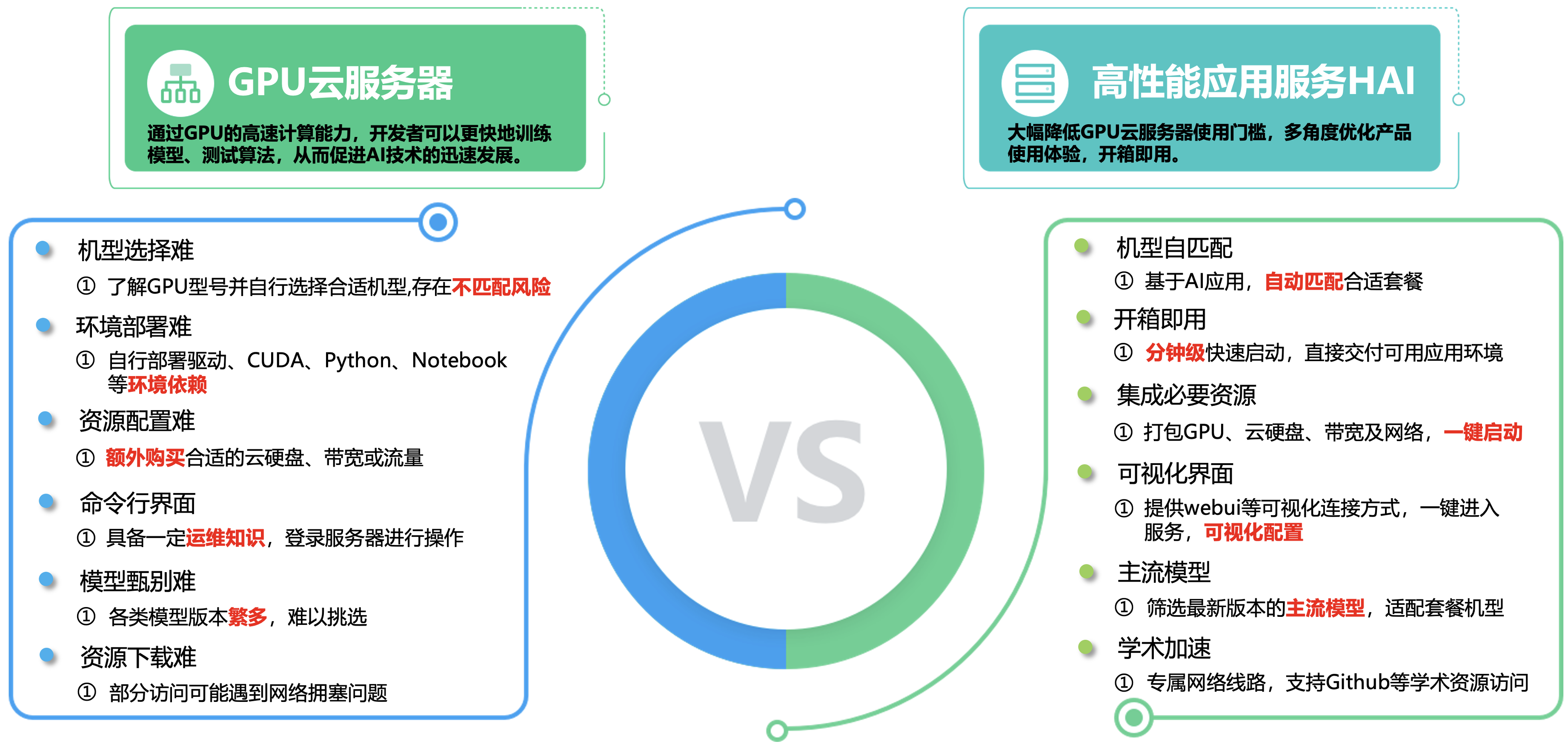
在以往都是自己组合搭建大多数搭载GPU云服务器的AI服务器可以覆盖更多的应用场景,如图形渲染、深度学习、天体物理、化学分子计算、云计算和虚拟化、计算密集型行业等应用。
高性能应用服务HAI的产品的价值:
大幅降低GPU云服务器使用门槛,多角度优化产品使用体验,低门槛、开箱即用。
2. 多种高性能应用部署场景,轻松拿捏:

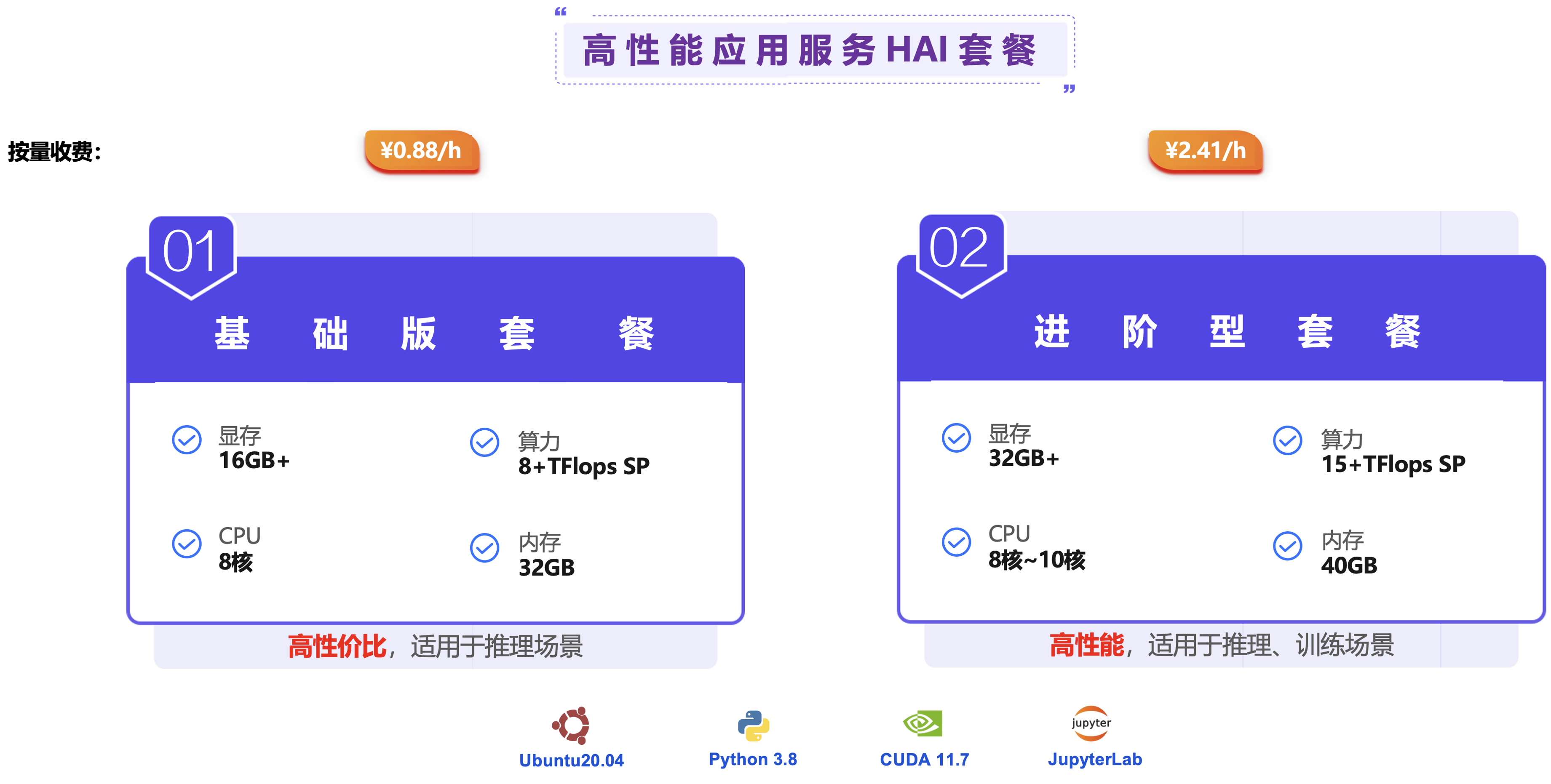
3. 灵活的套餐应对不同的需求场景,提供更性价比的计费方式:
本人在了解与熟悉AI应用的时候,采用的是基础版本,这样产生的费用相对也比较低,在有生成模型、生成数据集的时候,可以采用进阶版本,可以提高产出的效率。
4. 腾讯云高性能应用服务 HAI动手实验:
本次活动是由腾讯云和CSDN联合推出的开发者技术实践活动。通过动手实验的形式,带您深入沉浸式体验腾讯云高性能应用服务 HAI 。
- 第一个实验手册:如何利用HAI轻松拿捏AI作画
- 第二个实验手册:未来对话:HAI创作个人专属的知识宇宙
- 第三个实验手册:融合创新:HAI推动Pytorch2.0 AI框架新时代
活动提供的手册也是非常的详细,可以快速体验一下腾讯云高性能应用服务 HAI相关的AI产品,活动将覆盖多个应用场景,无论您是技术新手还是经验丰富的开发者,都可以从活动中汲取到技术上的精华。
四、Stable Diffusion介绍:
1. Stable Diffusion:
Stable Diffusion是一种基于扩散过程的图像生成模型,可以生成高质量、高分辨率的图像。它通过模拟扩散过程,将噪声图像逐渐转化为目标图像。这种模型具有较强的稳定性和可控性,可以生成具有多样化效果和良好视觉效果的图像。

Stable Diffusion 可以通过生成多样化、高质量的图像、修复损坏的图像、提高图像的分辨率和应用特定风格到图像上等方式,辅助视觉创意的实现。它为视觉艺术家、设计师等提供更多的创作工具和素材,促进视觉艺术领域的创新和发展。
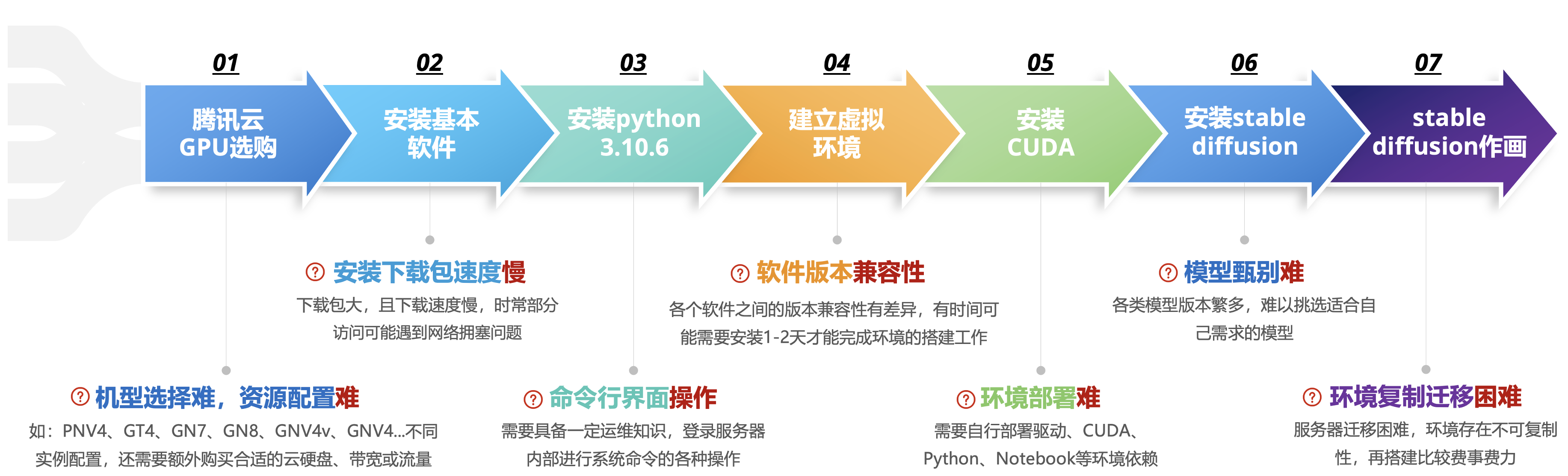
2. 对比一下GPU服务器自行部署痛点:
打开腾讯云GPU服务器控制台进行购买实例。
2.1 安装基本软件:
sudo apt install wget git2.1 安装python 3.10.6:
# 安装依赖 sudo apt install wget git python3 python3-venv # 删除默认的低版本 which python3 sudo rm /usr/bin/python # 配置软链接 ls -lh /usr/bin | grep python ln -s /usr/bin/python3 /usr/bin/python # 若是GPU环境的用户需要安装与cuda版本对应的torch pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117 # pip换源 pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple # 安装对应依赖pip install -r requirements_versions.txt
建立虚拟环境
sudo apt-get install python3.5-venv
python3 -m venv_name
source venv_name/bin/activate
2.2 安装CUDA:
# 下载Cuda
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run安装cuda
sudo sh cuda_11.8.0_520.61.05_linux.run
配置环境变量
增加下面两行内容,并保存
vim ~/.bashrc
export PATH=/usr/local/cuda-11.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH使配置文件生效
source ~/.bashrc
2.3 安装stable diffusion:
# 拉取stable diffusion 代码:
git clone GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI安装stable diffusion:
cd stable-diffusion-webui/
启动
./webui.sh
以上是自行尝试购买腾讯云GPU服务器,自己手动搭建环境,并运行stable diffusion。大概花费了<font color="red"><b>差不多一个下午的时间</b></font>,而且这个还是自己以前尝鲜有过经验的前提下。
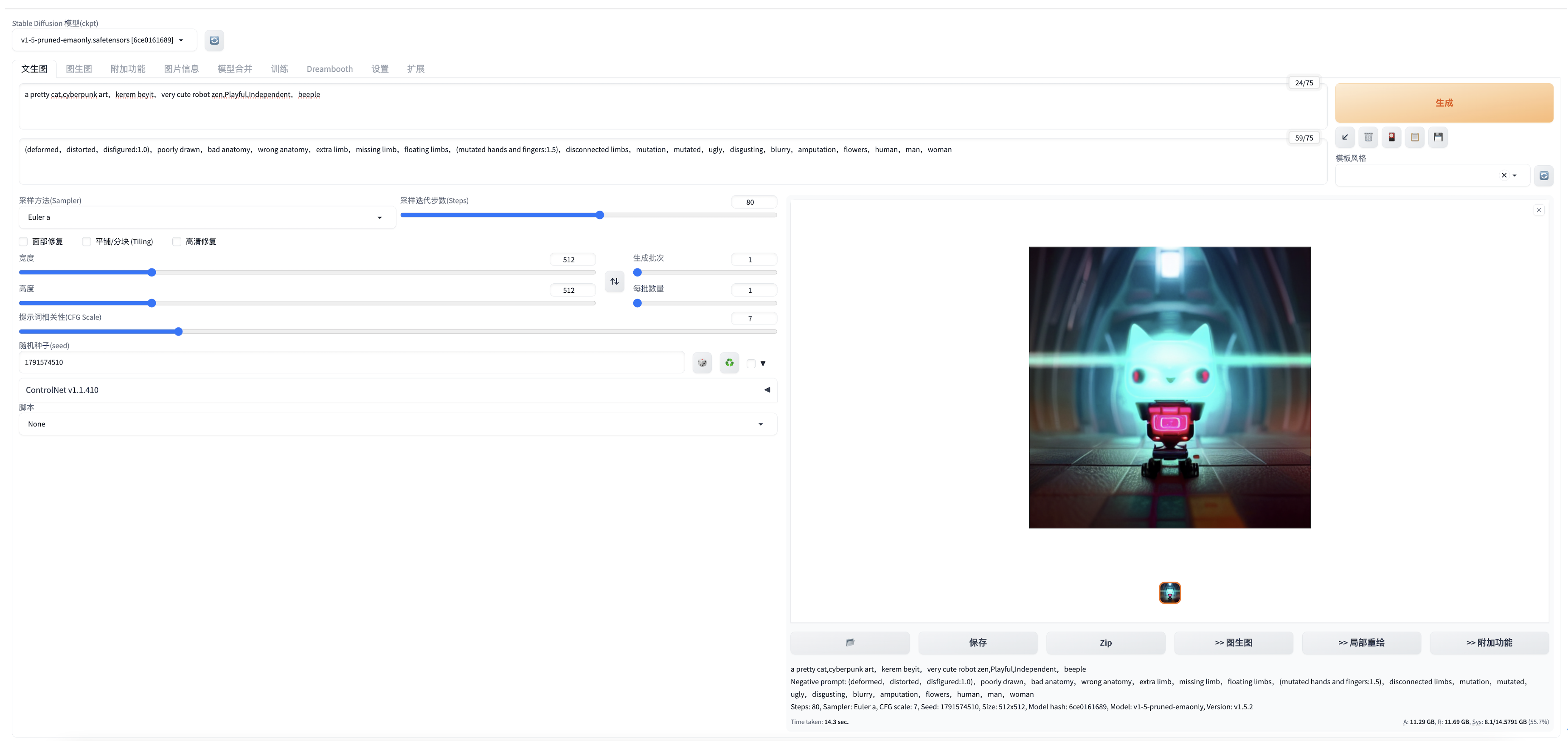
3. 对比HIA产品的提效:
通过完成官方提供的第一个动手实验,如何利用HAI轻松拿捏AI作画。我们大概只花了不到10分钟就可以从购买到使用stable diffusion开始作画,并且不到20分钟就能完成动手的实验(如下图),网上有太多的文章描述如何使用,这里就不去“鹦鹉学舌”重复赘述了。
可以看出以下的对比,“自己选购部署”与“高性能应用服务HAI”在以下7点存在业务痛点,“高性能应用服务HAI”大大的降低了使用的门槛、降低了学习的成本,让更多的企业、开发者能够加入到AI应用的行业中来。

五、“高性能应用服务HAI”的应用给公司业务提效方案可行性评估:
自从AIGC人工智能生成内容的来临,在过去的一段时间里,以Stable Diffusion 为代表的 AIGC 绘画迎来了爆发式增长,引发了一场生产力的革命。
1. Stable Diffusion AI绘画帮助设计师降本增效方案评估:
在传统的设计团队,通常的设计师的工作流程如下:
- 运营提出商业意图与图形的要求
- 设计在“千图网”找一些符合要求的参考图,或者自己手工画一些设计的初稿
- 在与业务确认沟通风格和草图,再跟业务确认,是否符合业务的要求
- 设计进行建模,并且针对一些细化的设计进行调整
- 最终,设计定稿,交付设计图
在这个设计的阶段过程中,交付给业务团队的耗时点如下:
- 设计师往往需要在“千图网”找大量的参考图,这个过程是比较费事也费劲的,一般需要半个工作日的倍数。
- 如果遇到一些比较复杂的交互,设计师还需要自己手画设计草图,也是比较费时间的。
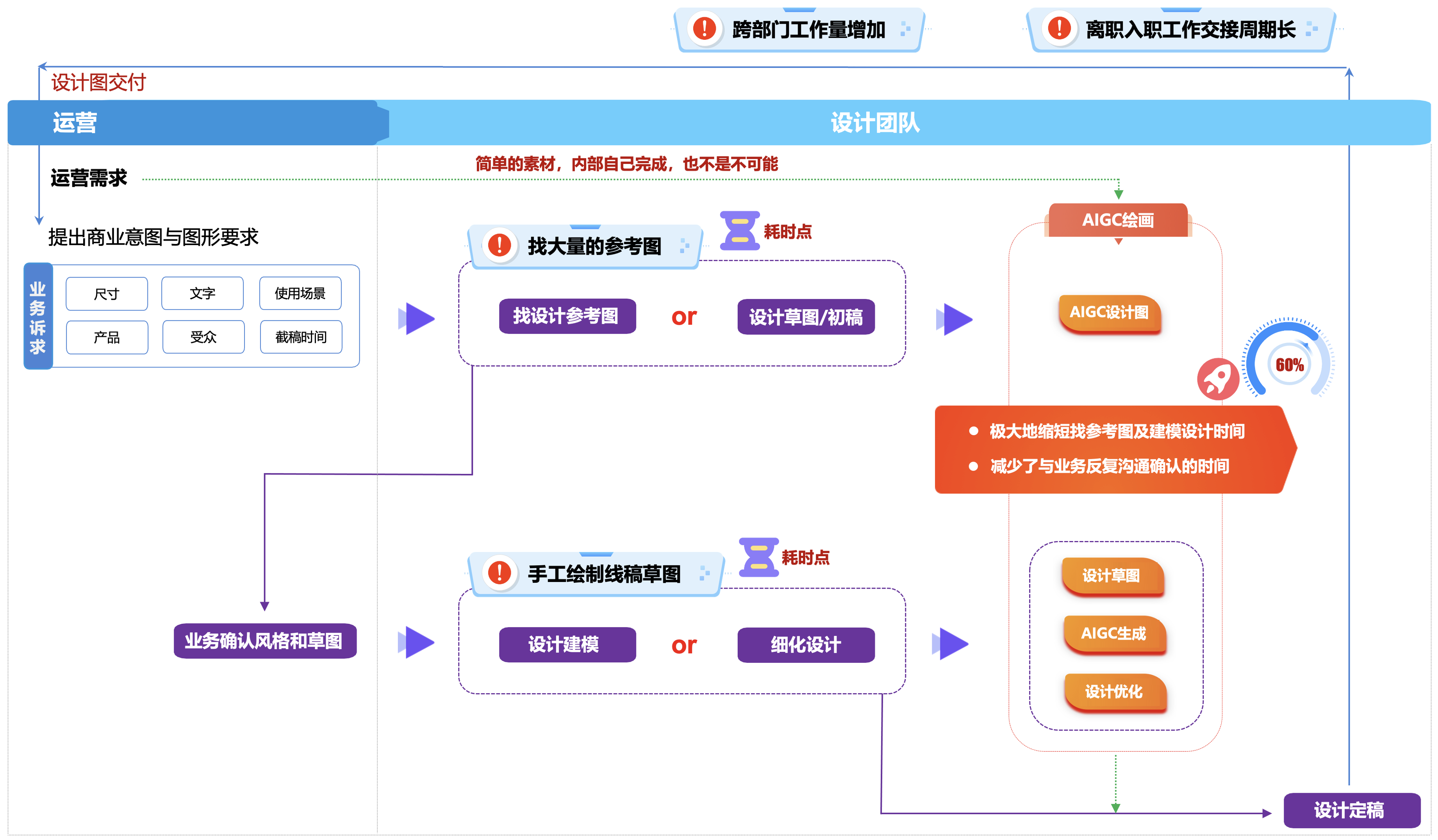
现在有了AIGC绘画的工具辅助后,可以极大地缩短找参考图及建模设计草图时间,同时也减少了与业务反复沟通确认的时间。使用Stable Diffusion生成设计参考图,可以快速与业务确认设计风格,绘制线稿草图后,再通过 Stable Diffusion 直接生成设计图,设计师再做细节优化,大大提升了整个设计流程的效率。<font color="red"><b>甚至,简单的绘图可以直接交付由业务单位来完成</b></font>。
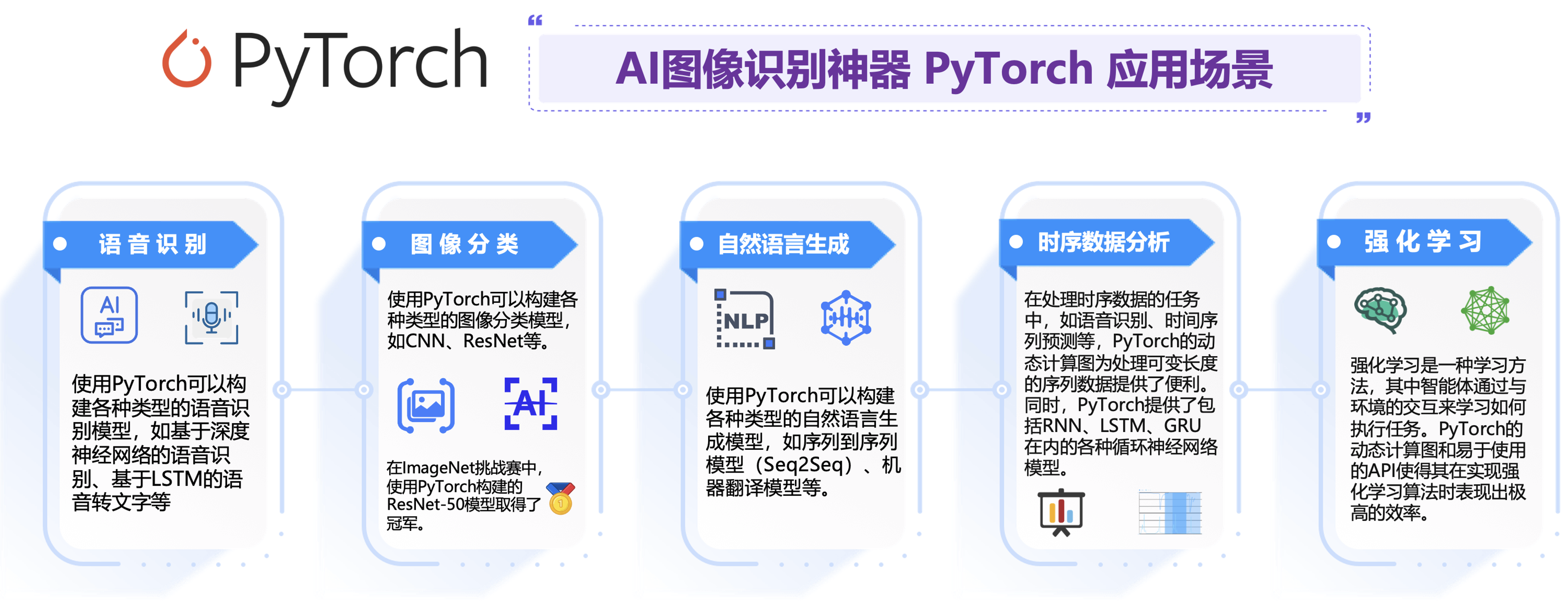
2. Pytorch模型AI图像识别帮助业务单位降本增效方案评估:
PyTorch是Facebook人工智能研究院(FAIR)开发的一个开源机器学习库,它使用Python语言编写,支持动态计算图和分布式训练。
案例一: | |
|---|---|
在理赔的业务中,往往会遇到车辆的刮蹭、车辆恶意损坏、划痕等理赔案例时,往往需要参考大量的案例。 | |
业务痛点: | |
改善措施: |
案例二: | |
|---|---|
在理赔凭证审核环节,由于经常发生将申请材料与历史凭证中高度相似的理赔凭证,从而存在理赔欺骗的问题,有点类似常说的“骗保”。 | |
业务痛点: | |
改善措施: |
3. ChatGLM2 6B模型AI对话帮助业务单位降本增效方案评估:
目前公司的客服业务,是传统的人工客服和自动配置机械化的文案回复的客服机器人,这种混合工作模式。与商家而言,减少用人成本,同时消费者也能获得更快速的回应与服务。
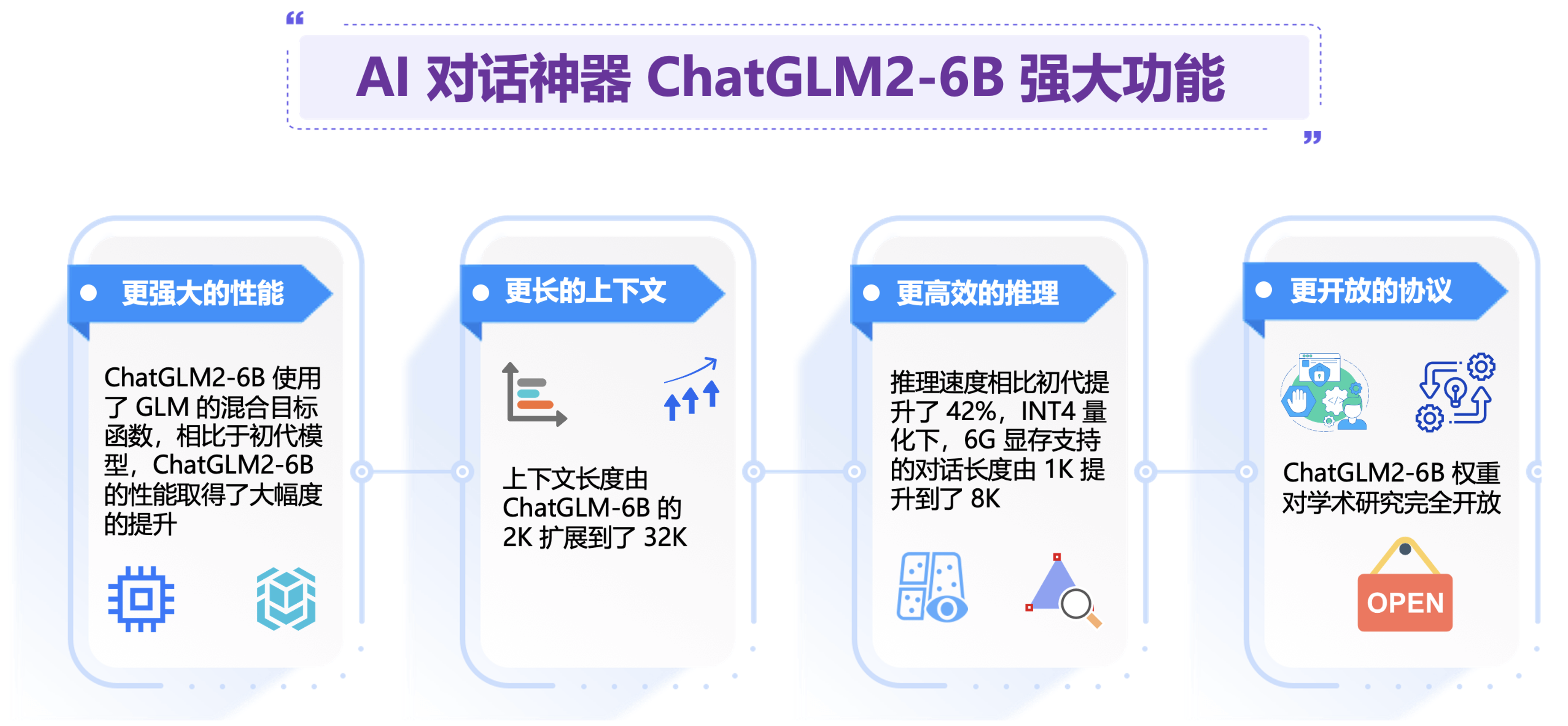
ChatGLM2-6B 使用了 Multi-Query Attention,提高了生成速度,同时也降低了生成过程中 KV Cache 的显存占用。同时,ChatGLM2-6B 采用 Causal Mask 进行对话训练,连续对话时可复用前面轮次的 KV Cache,进一步优化了显存占用。

但是目前自动配置机械化的文案回复,也让很多消费者难以读懂,但消费者就算跟智能客服反馈自己看不懂,也不会得到别的回应。“腾讯云高性能应用服务HAI”的AI对话,可以帮助消费者更好地理解自己遇到的问题,这不是更加方便吗?
六、Stable Diffusion AI绘画实际案例参考:
1. AI图像处理:
在实际的工作场景中,经常会遇到商务部门需要做各种活动、手册、邀请活动等物料,一般没有特别说明的话,不会考虑很多场景,比如“易拉宝”、“海报”、“刊物设计印刷”等的场景中,图片在放大时,会在分辨率、清晰度要求更高场景中,会出现模糊、看不清的效果。

如上,需要运用在更大背景区域上,如果采用直接放大设计文件,一般会出现文件内的非矢量元素就会模糊,导致在分辨率、清晰度要求更高场景中,会出现模糊、看不清的效果,此时,可以借助Stable Diffusion放大修复并提升图片清晰度,节省重绘的人力成本。
下面来介绍一下Stable Diffusion几种AI的放大算法:后期处理、脚本UItimate SD插件方案,当然,还有其它很多的方案。做放大算法高清修复、高清放大的时候,对于一张图片的聚焦点在哪里。
1.1 后期处理方案:
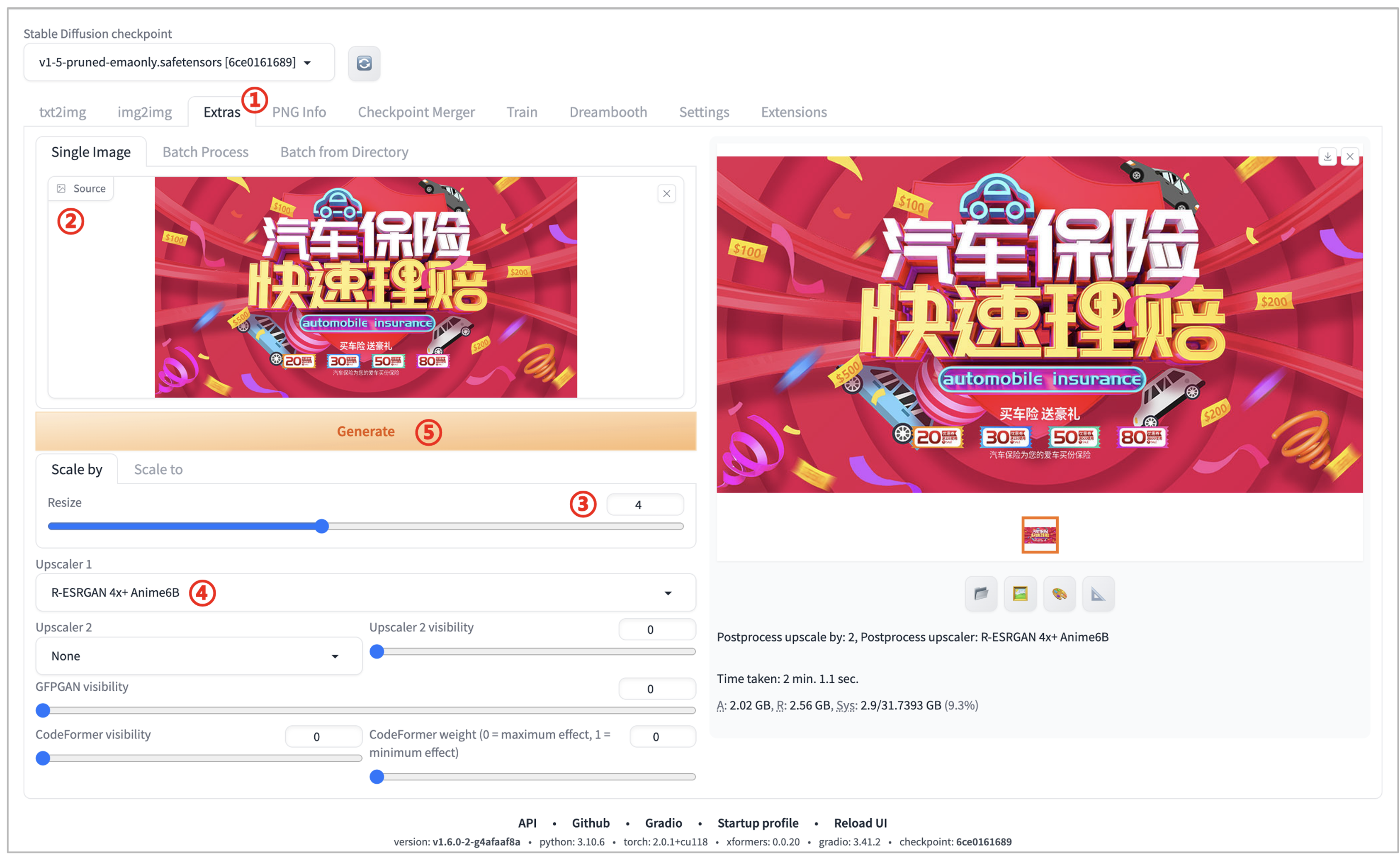
序号 | 操作 | 描述 |
|---|---|---|
1 | 点击“Extras”选项卡 | ①. 对应中文“后期处理” |
2 | 上传需要高清放大的图片 | ①. Single Image(单张图片)可以处理一张图片 |
3 | 在“Scale By(缩放倍数)”输入需要缩放的比例 | ①. 可以根据自己的需求来设定这个值,来调整需要放大的倍数 |
4 | Upscaler1表示放大的算法 | ①. 推荐选择“R-ESRGAN 4x+”、“R-ESRGAN 4x+ Anime6B”这2个算法模型 |
5 | 点击“Generate”生成图片 |
1.2 “脚本插件”方案:
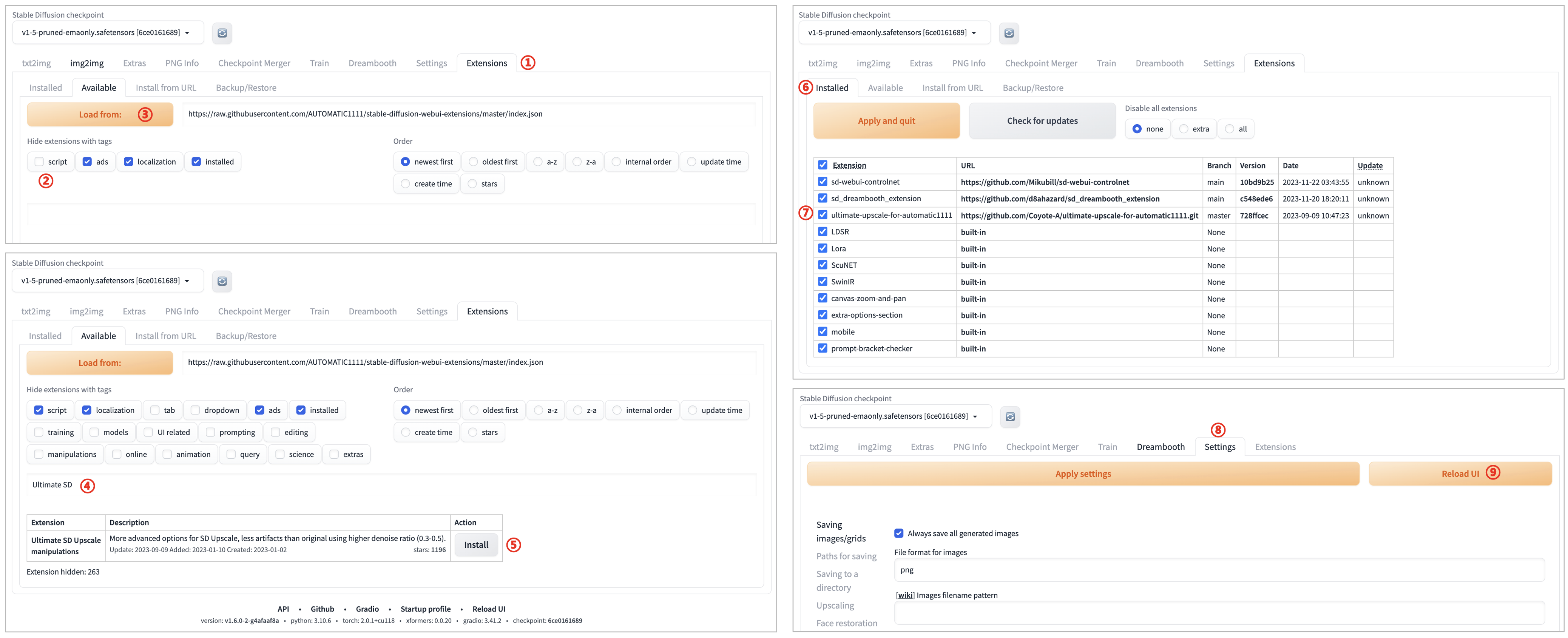
序号 | 操作 | 描述 |
|---|---|---|
1 | 点击“Extensions”选项卡 ①. 对应中文“扩展”,可以管理已安装的插件 | |
2 | 点击“script”脚本 | |
3 | 点击“Load form”加载扩展列表 | ①. 可以看到这个扩展列表是加速过的清单列表 |
4 | 在搜索区域搜索“Ultimate SD” | ①. 这里可以搜索已安装过的,或者没有下载过的插件 |
5 | 点击“Install”进行“Ultimate SD”插件的安装 | ①. 安装完成后,进入右上图片 |
6 | 在“Extensions”选项卡中,查看是否安装成功 | ①. 可以查看“Ultimate SD”插件是否安装成功 |
7 | “Ultimate SD”插件安装的信息 | |
8 | 切换到“Setting”设置选项卡中 | |
9 | 点击“Reload UI”进行重新启动 |
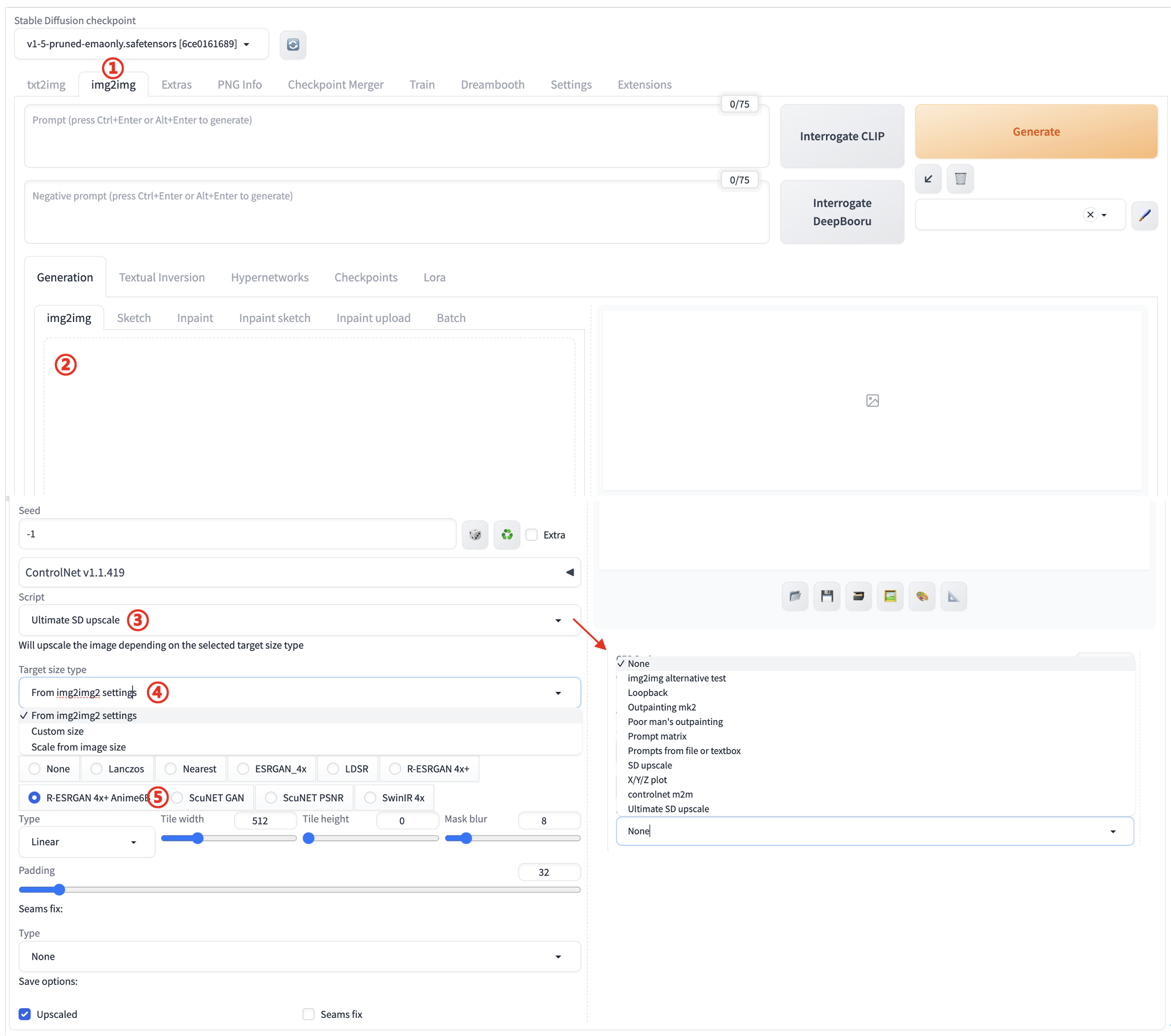
可以看到预期的结果,确实在处理的效果要好,但是有个问题是处理的过程太慢了,生成17M的图片需要近半个小时的时间,如果真的在生产阶段使用的话,可能需要更高的配置来支撑。

1.3 小结:
可以看出后期处理放大在细节上肯定比不上重绘的效果,不过它的优势在于简单、方便、速度快,而且可以处理任何图片,如果要求不高的话,它还挺好用的一个功能,相对于SD放大的脚本能得到更高的分辨率,细节也更丰富,但是处理时间需要久一点。

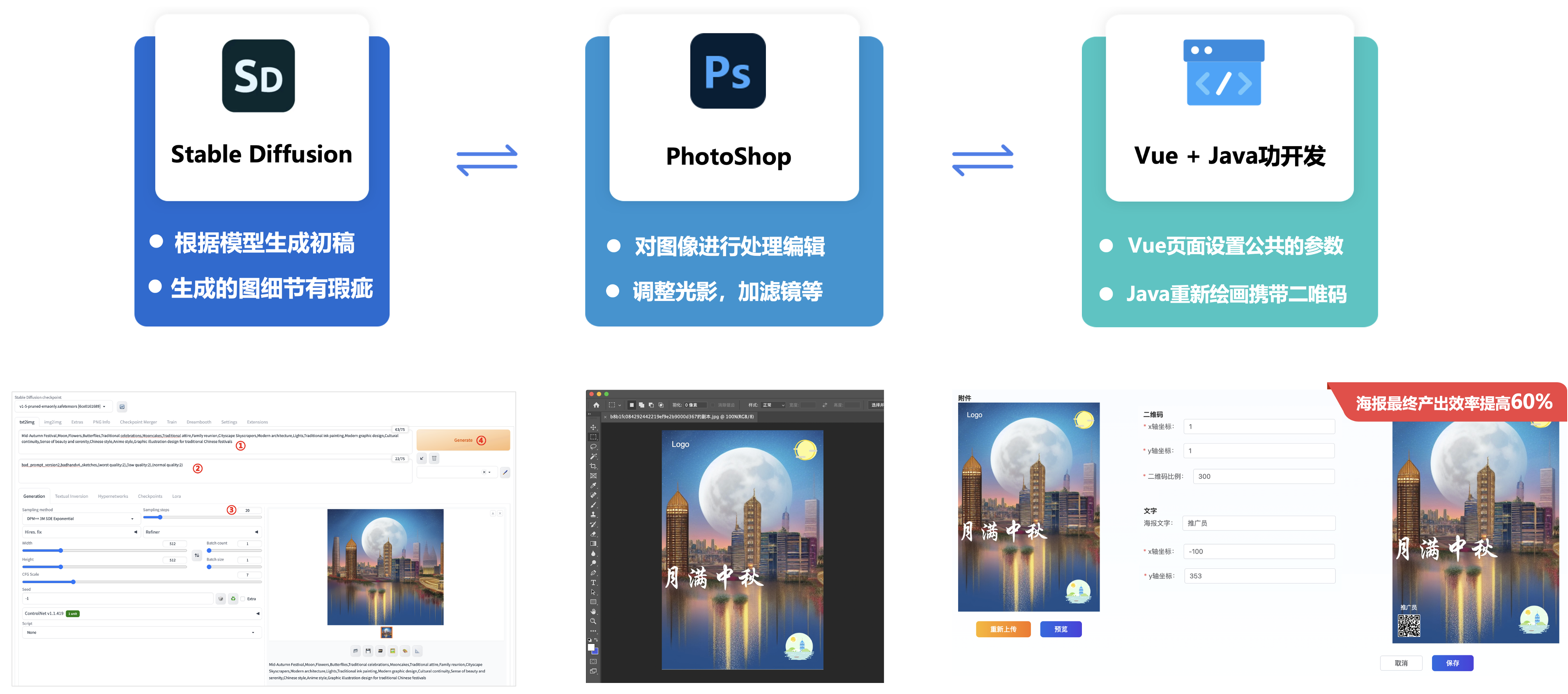
2. 业务推广海报生成:
在设计前期,设计师刚接到需求,了解到画面内容元素,设计风格后,会在花瓣等网站找对应的参考图给业务方确认,此时,可能还要配合适当的草图来表现画面的构图、元素等。
但这样的参考图往往不能很好的传达设计师的设计想法,且找到合适图的耗时都会比较长,这时候如果通过 Stable Diffusion输入相关关键词就可生成灵感参考图。
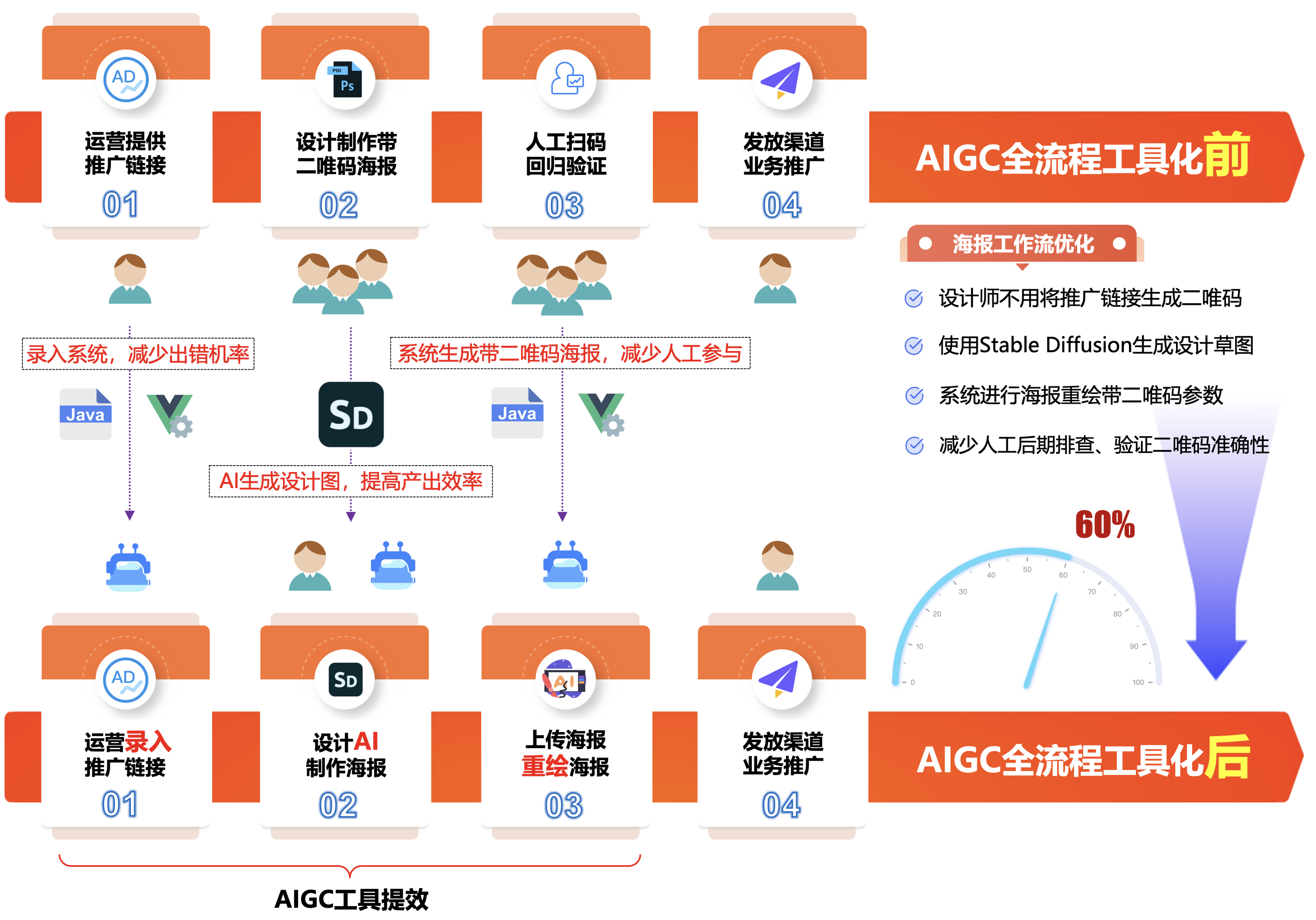
以上图,节日海报以中秋主题为例,生成一些海报分享朋友圈。可以利用Stable Diffusion的能力,通过“咒语”直接生成一些精美的节日素材图片,然后再设计排版添加下文案等素材。

序号 | 操作 | 描述 | |
|---|---|---|---|
1 | 点击“txt2img”选项卡 | ①. 通过文字的描述生成图片 | |
2 | 输入“Prompt” | ①. 对所希望生成的图片的文本描述,一般使用英文描述可以获得更好的生成结果 | |
3 | 输入“Negative prompt” | ①. 描述的是用户希望生成的图片的特征 |
|
4 | 调整“Sampling Steps” | ①. 如果生成图片细节不满足要求,可适当增加采样步骤,但生成时间也会相应增加 | |
5 | 点击“Generate”生成图片 |
在通过PhotoShop添加相应的文案元素进行排版,得到一个氛围感满满的中秋节气的海报,为了降低设计师手动复制二唯码生成海报的痛点,如下使用Vue + Java开发了一套重绘二唯码参数的系统,用来减轻设计师的工作量,同时,也降低了出错的几率。
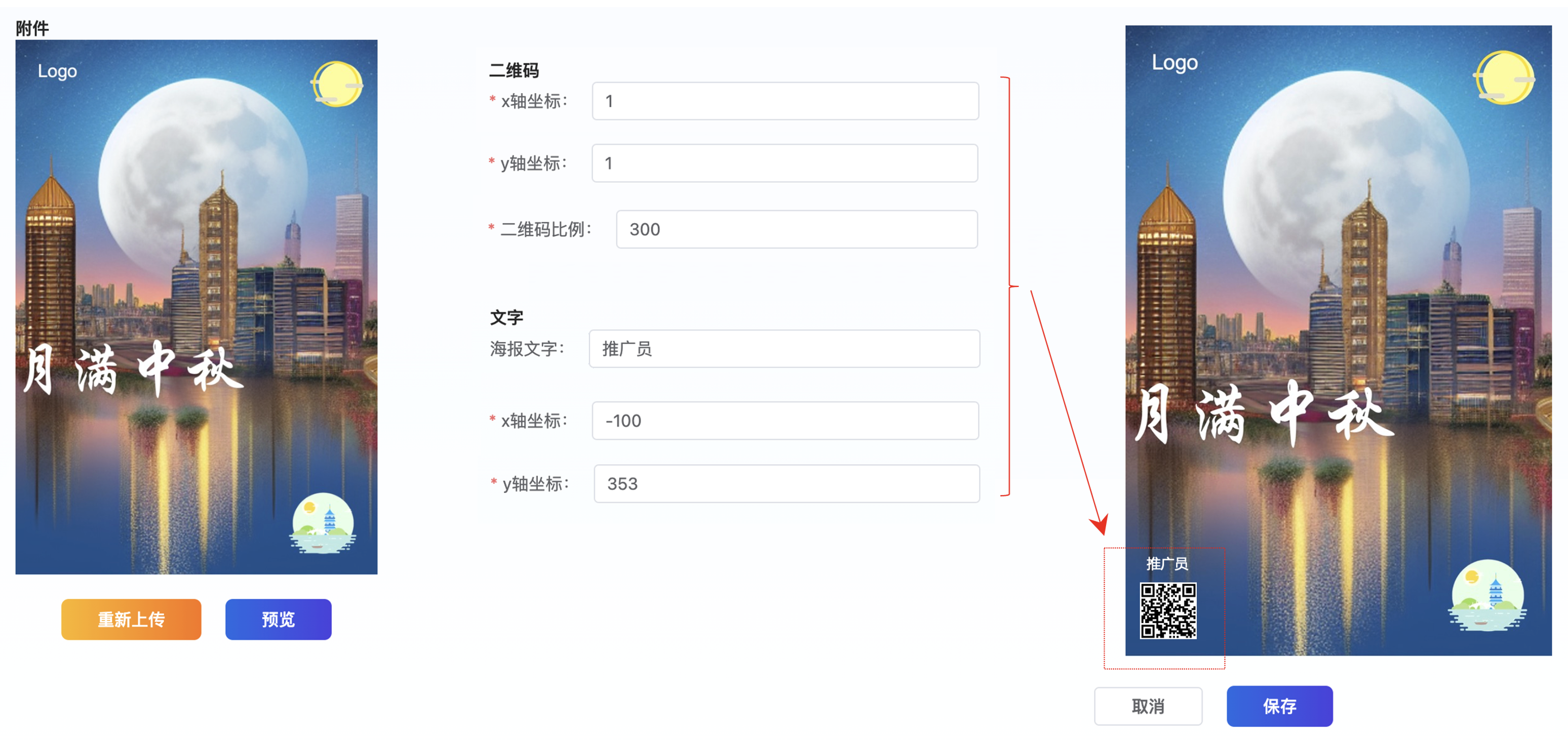
重绘携带二唯码海报相关java相关核心代码:
public static byte[] pressImage(ByteArrayInputStream input, FxPosterDTO poster,
float alpha, Map<String, String> textMap) {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
try {
// 海报图片
Image target = ImageIO.read(new URL(poster.getPosterUrl()));
int wideth = target.getWidth(null);
int height = target.getHeight(null);
BufferedImage image = new BufferedImage(wideth, height, 1);
Graphics2D g = image.createGraphics();
g.drawImage(target, 0, 0, wideth, height, null);// 二维码图片 Image src_other = ImageIO.read(input); int wideth_other = src_other.getWidth(null); int height_other = src_other.getHeight(null); int reX = (wideth - wideth_other) / 2; int reY = (height - height_other) / 2; g.setComposite(AlphaComposite.getInstance(10, alpha)); g.drawImage(src_other, reX + poster.getQrCodeX(), reY + poster.getQrCodeY(), null); // 码LOGO替换 if (HmbConstants.WECHAT_PROGRAM.equals(poster.getRemark1())) { int logoX = (wideth - 240) / 2; int logoY = (height - 240) / 2; Image logoIO = ImageIO.read(new URL(fxProject.getRemark1())); g.drawImage(logoIO, logoX + poster.getPointX() + LOGO_OFFSET, logoY + poster.getPointY() + LOGO_OFFSET, null); } // 海报文字 PosterQrcodeReq obFirst = JSON.parseObject(poster.getRemark4(), PosterQrcodeReq.class); PosterQrcodeReq obSecond = JSON.parseObject(poster.getRemark5(), PosterQrcodeReq.class); String contentFirst = Tools.isBlank(obFirst.getContentFirst()) ? "" : obFirst.getContentFirst(); String contentSecond = Tools.isBlank(obSecond.getContentSecond()) ? "" : obSecond.getContentSecond(); Color color = Color.WHITE; if (HmbConstants.POSTER_WORD_COLOR_B.equals(obSecond.getContentColor())) { color = Color.BLACK; } if (!Tools.isBlank(textMap)) { g.setRenderingHint(RenderingHints.KEY_TEXT_ANTIALIASING, RenderingHints.VALUE_TEXT_ANTIALIAS_ON); String waterMarkContent = textMap.get("userName") .concat(contentFirst); g.setColor(color); g.setBackground(Color.WHITE); g.setFont(new Font("Microsoft YaHei", Font.BOLD, 24)); // 字体、字型、字号 g.drawString(waterMarkContent, reX + obFirst.getXFirst(), reY + obFirst.getYFirst()); // 画文字 g.drawString(contentSecond, reX + obSecond.getXSecond(), reY + obSecond.getYSecond()); // 画文字 } } catch (Exception var14) { log.error(var14.getMessage(), var14); } return bos.toByteArray();}
private static void insertImage(BufferedImage source, InputStream imgPath, boolean needCompress) throws Exception {
if (imgPath == null) {
log.warn("文件不存在,imgPath", imgPath);
} else {
Image src = ImageIO.read(imgPath);
int width = (src).getWidth(null);
int height = (src).getHeight(null);
if (needCompress) {
// 压缩LOGO
if (width > WIDTH) {
width = WIDTH;
}
if (height > HEIGHT) {
height = HEIGHT;
}
Image image = (src).getScaledInstance(width, height, 4);
BufferedImage tag = new BufferedImage(width, height, 1);
Graphics g = tag.getGraphics();
g.drawImage(image, 0, 0, null);
g.dispose();
src = image;
}Graphics2D graph = source.createGraphics(); int x = (QRCODE_SIZE - width) / 2; int y = (QRCODE_SIZE - height) / 2; graph.drawImage(src, x, y, width, height, null); Shape shape = new RoundRectangle2D.Float((float) x, (float) y, (float) width, (float) width, 6.0F, 6.0F); graph.setStroke(new BasicStroke(3.0F)); graph.draw(shape); graph.dispose(); }}
public static byte[] pressImage(InputStream input, float f, FxPosterDTO req , boolean isFont) throws Exception {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Thread.currentThread().getContextClassLoader().getResource("").getPath();
Image target = ImageIO.read(new URL(req.getPosterUrl()));
int wideth = target.getWidth(null);
int height = target.getHeight(null);
BufferedImage image = new BufferedImage(wideth, height, 1);
Graphics2D g = image.createGraphics();
g.drawImage(target, 0, 0, wideth, height, null);Image src_other = ImageIO.read(input); int qrWidth = req.getQrCodeSize() == 0 ? 200 : 200 * req.getQrCodeSize() / 100; BufferedImage bufferedImageBef = createResizedCopy(src_other, qrWidth, qrWidth); int wideth_other = bufferedImageBef.getWidth(null); int height_other = bufferedImageBef.getHeight(null); int reX = (wideth - wideth_other) / 2; int reY = (height - height_other) / 2; BufferedImage bufferedImage = setClip(bufferedImageBef,20); g.setComposite(AlphaComposite.getInstance(10, f)); g.drawImage(bufferedImage,(wideth - 280) / 2 + req.getQrCodeX(), (height - 280) / 2 + req.getQrCodeY(),null); g.setRenderingHint(RenderingHints.KEY_TEXT_ANTIALIASING, RenderingHints.VALUE_TEXT_ANTIALIAS_ON); Color mycolor = POSTER_WORD_COLOR_B.equals(req.getFontColor()) ? Color.BLACK : Color.WHITE; g.setColor(mycolor); g.setBackground(Color.WHITE); if (!isFont){ g.setFont(new Font("AR PL UMing CN:style=Light", Font.BOLD, 30)); g.drawString(PbmCodeUtils.mask(req.getCreateName(),4,3), reX + req.getFontX(), reY + req.getFontY()); } g.dispose(); ImageIO.write(image, FORMAT_NAME, bos); return bos.toByteArray();
}
2.3 小结:
在导入Stable Diffusion后,再加上自己研发的系统对海报进行二次加工,可以达到海报批量快速产出的效果,加快了业务部分快速推广的作用,同时,也极大的减轻了设计师的工作量。
- 借助Stable Diffusion图片生成能力可以快速的基本素材的生成
- 借助PS软件专门用来进行图像处理的软件,通过它可以对图像修饰、对图形进行编辑,以及对图像的色彩处理,另外还有绘图和输出等功能,可以使图像产生特效,如果和其它工具或软件配合使用,还可以进行高质量的广告设计、美术创意和三维动画制作
- 借助自己开发的图片二次开发功能,可以有效的将不同渠道、不同业务的分销码,重绘到海报中携带二唯码参数
希望借助AIGC领域的工具,打造一个<font color="red"><b>全流程线上工具化</b></font>,运营人员通过配置节日、风格、形象、动作等即可自动生成运营图。
3.1 图生图 - 运营生成二唯码场景:
4. 总结:
“腾讯云高性能应用服务HAI”提供了Stable Diffusion快速部署及下载自定义模型功能,使用者不需要自己下载代码,不需要自己安装复杂的依赖,不需要了解Git、Python、Docker等技术,只需要在控制台图形界面点击几下鼠标就可以快速启动Stable Diffusion服务进行绘画,非技术同学也能轻松搞定。
与设计沟通后,通过上面的案例可以看出Stable Diffusion只能完成项目中的一部分,或者一些临时应急对设计需求要求并不高的项目,如果要求较高还是需要设计师二次创作及相应的优化。AIGC 本质上还是提效辅助的工具,设计师需要去掌握更高超的操作技能。
七、Pytorch模型AI图像识别实际案例参考:
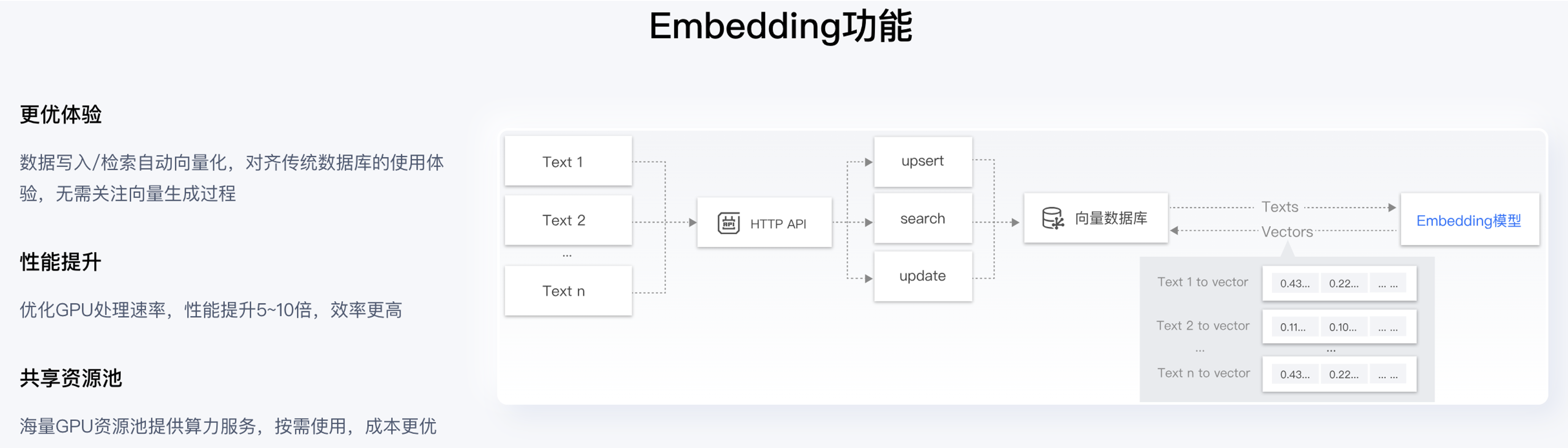
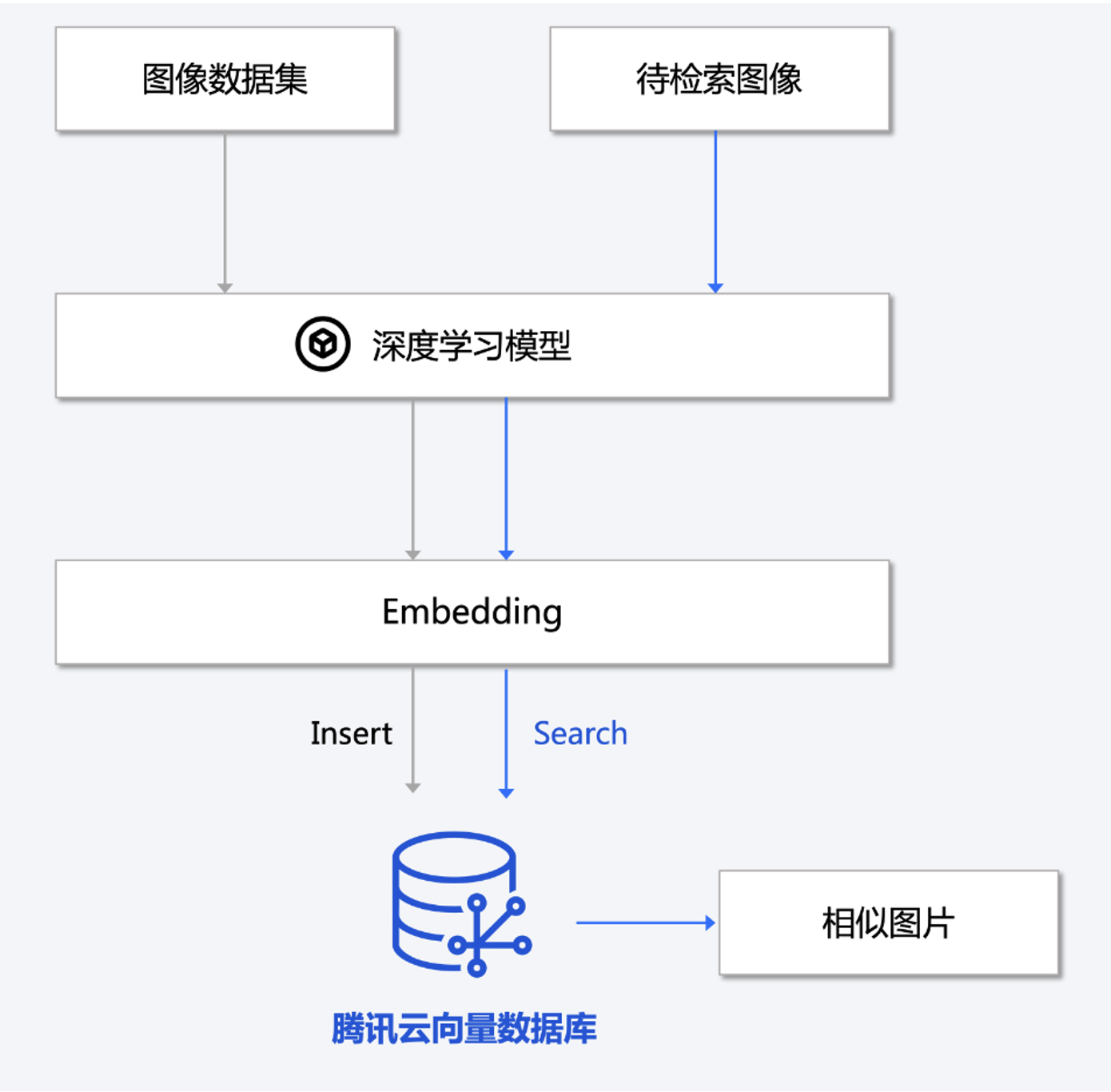
腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。
腾讯云的向量数据库中的“向量检索”是一种基于向量空间模型的信息检索方法,可以将非结构化的数据表示为向量存入向量数据库,向量检索通过计算查询向量与数据库中存储的向量的相似度来找到目标向量。

通过这个特性,我们可以利用PyTorch的transforms模块和预训练的模型ResNet50将一张输入图像转化为一个特征向量,存放到向量数据库,再通过“Embedding”功能匹配相似值的score权重来进行由高到低排序,越大表示相似度越高。
1. 首先,按照官方的要求进行安装向量数据库的SDK:
安装完成后,可以看到安装的速度是非常的快,最大是2.0M每秒,内部做了学术加速。
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
2. 下载ResNet50模型:
ResNet50是一种深度卷积神经网络,用于图像分类和对象检测,是一种基于深度卷积神经网络(Convolutional Neural Network,CNN)的图像分类算法。
3. 通过ptyhon脚本进行图片的特征向量入库操作:
import torchvision.transforms as transforms
from PIL import Image
import pandas as pd
import torch
import torchvision.models as models
from glob import glob
from pathlib import Path
from torchvision.models import ResNet50_Weights
import tcvectordb
from tcvectordb.model.document import Document, SearchParams, Filter
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParamsdisable/enable http request log print
tcvectordb.debug.DebugEnable = False
client = tcvectordb.VectorDBClient(url='http://xxx.tencentclb.com', username='root', key='xxxx', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
print(client)
Test Image Path
TEST_IMAGE_PATH = './images/*.jpg'
Initialize model
model = models.resnet50(pretrained=True)
model = models.resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
Set model to eval mode
model = model.eval()
model = torch.nn.Sequential(*(list(model.children())[:-1]))Load image path
def load_image(x):
if x.endswith('csv'):
with open(x) as f:
reader = csv.reader(f)
next(reader)
for item in reader:
yield item[1]
else:
for item in glob(x):
yield itemEmbedding: Function to extract features from an image
def extract_features(image_path):
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# Read the image Ensure the image is read as RGB
img = Image.open(image_path).convert('RGB')
img = transform(img)
img = img.unsqueeze(0)
feature = model(img)
# Reshape the features to 2D
feature = feature.view(feature.shape[0], -1)
return feature.detach().numpy()def display_multiple_embeddings(image_path_pattern):
# Use glob to get all matching image paths
image_paths = load_image(image_path_pattern)
# Process each image and collect the results
results = []
print(image_paths)
for index, img_path in enumerate(image_paths):
feature = extract_features(img_path)
# Convert features to a pandas DataFrame
d = pd.DataFrame(feature)
upsert_data(str(index), img_path, d)
# results.append(d)def create_db_and_collection():
database = 'ai'
coll_name = 'ai_images'
coll_alias = 'ai_images_alias'# 创建DB db = client.create_database(database) # 创建 Collection # 第一步,设计索引(不是设计 Collection 的结构) # 1. 【重要的事】向量对应的文本字段不要建立索引,会浪费较大的内存,并且没有任何作用。 # 2. 【必须的索引】:主键id、向量字段 vector 这两个字段目前是固定且必须的,参考下面的例子; # 3. 【其他索引】:检索时需作为条件查询的字段,比如要按书籍的作者进行过滤,这个时候 author 字段就需要建立索引, # 否则无法在查询的时候对 author 字段进行过滤,不需要过滤的字段无需加索引,会浪费内存; # 4. 向量数据库支持动态 Schema,写入数据时可以写入任何字段,无需提前定义,类似 MongoDB. # 5. 例子中创建一个书籍片段的索引,例如书籍片段的信息包括 {id, vector, segment, bookName, author, page}, # id 为主键需要全局唯一,segment 为文本片段, vector 字段需要建立向量索引,假如我们在查询的时候要查询指定书籍 # 名称的内容,这个时候需要对 imageUrl 建立索引,其他字段没有条件查询的需要,无需建立索引。 index = Index() index.add(VectorIndex('vector', 2048, IndexType.HNSW, MetricType.COSINE, HNSWParams(m=16, efconstruction=200))) index.add(FilterIndex('id', FieldType.String, IndexType.PRIMARY_KEY)) index.add(FilterIndex('imageUrl', FieldType.String, IndexType.FILTER)) # 第二步:创建 Collection db.create_collection( name=coll_name, shard=3, replicas=0, description='ai images collection', index=index, embedding=None, timeout=20 ) # 设置 Collection 的 alias db.set_alias(coll_name, coll_alias)def upsert_data(index, img_path, d):
# 获取 Collection 对象
db = client.database('ai')
coll = db.collection('ai_images')# upsert 写入数据,可能会有一定延迟 # 1. 支持动态 Schema,除了 id、vector 字段必须写入,可以写入其他任意字段; # 2. upsert 会执行覆盖写,若文档id已存在,则新数据会直接覆盖原有数据(删除原有数据,再插入新数据) document_list = [ Document(id=index, vector=[0.2123, 0.21, 0.213], imageUrl=img_path) ] coll.upsert(documents=document_list)if name == 'main':
create_db_and_collection()display_multiple_embeddings(TEST_IMAGE_PATH)</code></pre></div></div><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:auto"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723349591304563294.png" /></div></div></div></figure><h3 id="bk1ak" name="4.-%E6%8F%90%E4%BE%9B%E6%9F%A5%E8%AF%A2API%E6%8E%A5%E5%8F%A3%E7%9B%B8%E5%85%B3%E9%80%BB%E8%BE%91%EF%BC%9A">4. 提供查询API接口相关逻辑:</h3><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0">def query_data(self, vector): # 获取 Collection 对象 db = self._client.database('book') coll = db.collection('book_segments') # 批量相似性查询,根据指定的多个向量查找多个 Top K 个相似性结果 res = coll.search( vectors=[ vector], # 指定检索向量,最多指定20个 params=SearchParams(ef=200), # 若使用HNSW索引,则需要指定参数ef,ef越大,召回率越高,但也会影响检索速度 retrieve_vector=False, # 是否需要返回向量字段,False:不返回,True:返回 limit=10 # 指定 Top K 的 K 值 ) # 输出相似性检索结果,检索结果为二维数组,每一位为一组返回结果,分别对应search时指定的多个向量 print_object(res)</code></pre></div></div><p>接口返回图片的相关信息,如大小、类型、分辨率、时间,最重要的是score的值:</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:auto"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723349591789701590.png" /></div></div></div></figure><p>前端页面显示逻辑:</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0"><template><scroll-view
class="media-view"
scroll-y
@scrolltolower="loadMore"
>
<unicloud-db
ref="mediaUdb"
v-slot:default="{data, loading, error, pagination}"
:collection="collection"
orderby="createDate desc"
loadtime="manual"
:page-size="50"
@load="onMediaListLoad"
>
<view v-if="(loading || processing) && pagination.current === 1" class="loading">
<uni-icons class="icon" type="spinner-cycle" size="30" color="#000"></uni-icons>
</view>
<view class="items" v-else-if="mediaList.length">
<view
class="media-item"
:class="{active: mediaItem.active, selected: mediaItem.selected}"
v-for="(mediaItem, index) in mediaList"
@click="onSelect(index)"
:key="mediaItem._id"
>
<view class="image" v-if="mediaItem.type === 'image'">
<image :src="mediaItem.isUploading ? mediaItem.src: mediaItem.thumb.listCover" mode="aspectFill" class="img"></image>
</view>
<view class="image" v-if="mediaItem.type === 'video'">
<video
class="v"
:src="mediaItem.src"
:controls="false"
:show-center-play-btn="false"
v-if="mediaItem.isUploading || /^cloud:///.test(mediaItem._src)"
></video>
<image v-else :src="mediaItem.thumb.listCover" mode="aspectFill" class="img"></image>
</view>
<view class="mask" v-if="mediaItem.isUploading">
<view class="progress">
<view class="inner" :style="{width: mediaItem.progress + '%'}"></view>
</view>
<view class="tip">{{mediaItem.tip}}</view>
</view>
</view>
</view>
<view class="media-library-isnull" v-else>
<uni-icons type="images" size="60" color="#ccc"></uni-icons>
<view class="text">媒体库资源为空,是否上传资源?</view>
<button
type="primary"
size="mini"
@click="$emit('onUploadMedia');"
>上传媒体资源</button>
</view>
</unicloud-db>
</scroll-view>
</template>
如下为页面的效果显示,可以看到通过一张图片搜索,可以将类似的图片查找出来,非常的实用。

小结:
通过“高性能应用服务HAI”中的PyTorch框架和腾讯云向量数据库相结合,将文本/图像检索任务是指在大规模文本/图像数据库中搜索出与指定图像最相似的结果,在检索时使用到的<font color="red"><b>文本/图像特征可以存储在向量数据库中</b></font>,通过高性能的索引存储实现高效的相似度计算,进而返回<font color="red"><b>和检索内容相匹配的文本/图像结果</b></font>。
八、垂直领域“汽车保险”AI智能客服实际案例参考:
绝大多数提供互联网应用的公司都会存在在线客服的岗位,以往客服单位需要招在大量专业人员,经过内部培训一段周期再上岗作业,往往会存在一些问题:
序号 | 分类 | 描述 |
|---|---|---|
1 | 人工座席高强负荷运转 | 人工座席无法应对高峰期海量访客,造成服务响应缓慢、排队等待过长及服务专业性不足等各种情况 |
2 | 核心数据外泄风险 | 人工座席能够触及的客户资料数据覆盖面广,部分敏感业务数据存在暴露风险,可能导致数据信息外泄 |
3 | 7*24服务 | 很多时候,客服人员在下班或者休假的时候,还要频繁工作,导致客服工作时长久 |
4 | 业务“Serverless化服务” | 当遇到业务比较忙时,需要招大量的人力来支撑业务发展,当业务低谷期,又需要减员来保证公司的正常支出 |
根据第二个实验手册:未来对话:HAI创作个人专属的知识宇宙,里面第5点“高性能应用服务HAI 快速部署 ChatGLM2-6B-int4 本地模型及基于 P-Tuning v2 的微调”,对于现有的业务有帮助,准备自己的训练集进行微调 ChatGLM2-6B 模型(基于 P-Tuning v2 ),创建<font color="red"><b>企业垂直领域的专属知识库</b></font>。
以下为测试需要的训练集,以最新一个项目的QA为例,收集以下的list:
[
{"content": "车保赔巨王卡", "summary": "车保赔巨王卡是xx公司推出的一种综合保险服务,主要服务于xx城市中所有的车辆服务,投保期间只有一年,2026年1月1号到2026年12月30号。"},
{"content": "车保赔巨王卡投保时间", "summary": "投保期间只有一年,2026年1月1号到2026年12月30号。"},
{"content": "车保赔巨王卡如何理赔", "summary": "关注公众号'某某车保险',输入'理赔'即可进行理赔的相关操作。"},
]执行“sh train_chat.sh”命令进行训练:
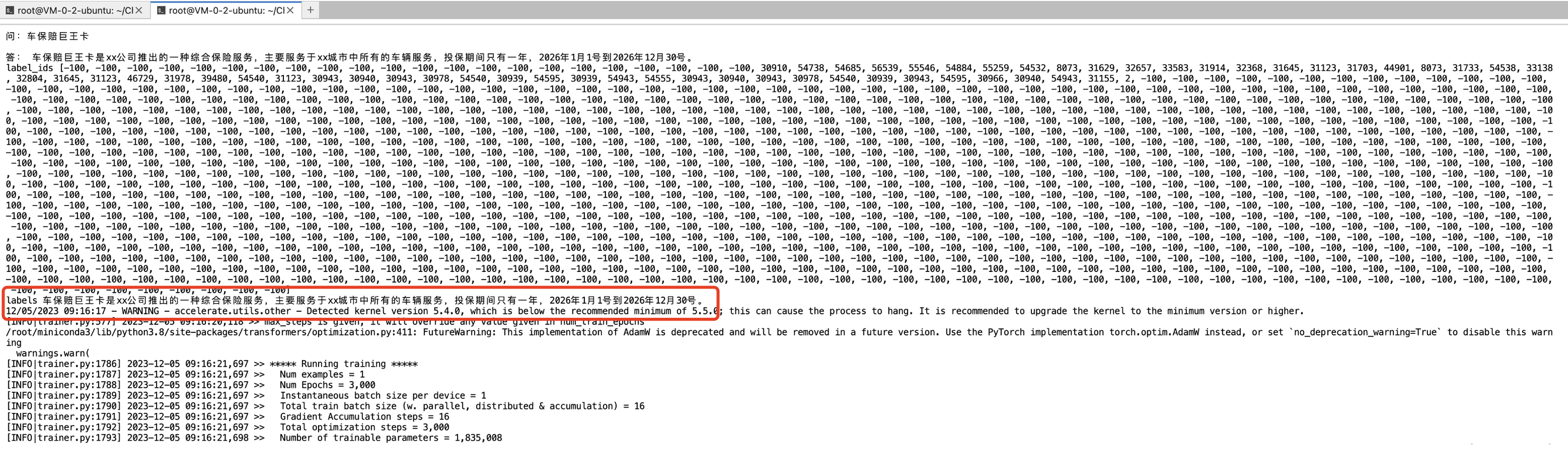
模型开始训练,数据集越多耗时越长,目前测试的三条训练集、验证集大约需要1个小时左右训练完成。

可以看到快速部署 ChatGLM2-6B-int4 本地模型及基于 P-Tuning v2 的微调前后的对比:

基于 P-Tuning v2 的微调可以看出回答的结果更贴近业务垂直领域的结果,但是让客户使用这个界面必然是不现实的,下面我们通过API的方式来集成到我们的客服系统中,看看是否能“模拟”人工客服,从而降低对客服人员的成本诉求。
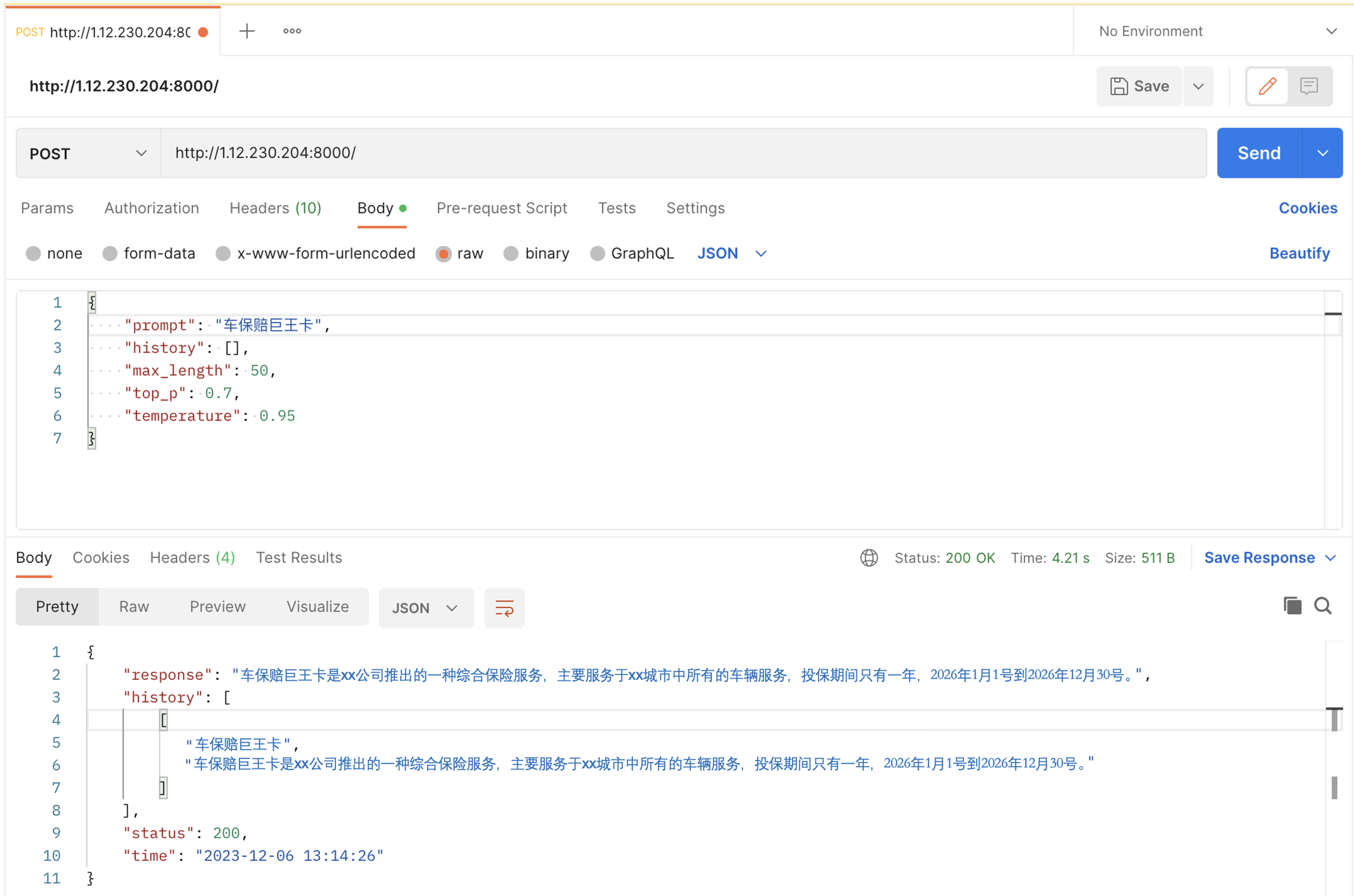
根据手册输入命令,用于开启 API 服务:
cd ./ChatGLM2-6B
python api.py通过postman进行发送请求一个post请求,可以看到是可以请求成功的。
使用开发好的客服系统可以进行对接,如下为vue相关代码:
<template>
<view>
<scroll-view scroll-with-animation scroll-y="true" @touchmove="hideKey"
style="width: 750rpx;" :style="{'height':srcollHeight}" :scroll-top="go" >
<view id="okk" scroll-with-animation >
<view class="flex-column-start" v-for="(x,i) in msgList" :key="i">
<view v-if="x.my" class="flex justify-end padding-right one-show align-start padding-top" >
<view class="flex justify-end" style="width: 400rpx;">
<view class="margin-left padding-chat bg-cyan" style="border-radius: 35rpx;">
<text style="word-break: break-all;">{{x.msg}}</text>
</view>
</view>
</view>
<view v-if="!x.my" class="flex-row-start margin-left margin-top one-show" >
<view class="chat-img flex-row-center">
<image style="height: 75rpx;width: 75rpx;" src="../../static/image/ke.png" mode="aspectFit"></image>
</view>
<view class="flex" style="width: 500rpx;">
<view class="margin-left padding-chat flex-column-start" style="border-radius: 35rpx;background-color: #f9f9f9;">
<text style="word-break: break-all;" >{{x.msg}}</text>
<view class="flex-column-start" v-if="x.type==1" style="color: #2fa39b;">
<text style="color: #838383;font-size: 22rpx;margin-top: 15rpx;">以下是常见问题,可以点击查看:</text>
<text @click="answer(index)" style="margin-top: 30rpx;"
v-for="(item,index) in x.questionList" :key="index" >{{item}}</text>
</view>
</view>
</view>
</view>
</view>
<view v-show="msgLoad" class="flex-row-start margin-left margin-top">
<view class="chat-img flex-row-center">
<image style="height: 75rpx;width: 75rpx;" src="../../static/image/robt.png" mode="aspectFit"></image>
</view>
<view class="flex" style="width: 500rpx;">
<view class="margin-left padding-chat flex-column-start"
style="border-radius: 35rpx;background-color: #f9f9f9;">
<view class="cuIcon-loading turn-load" style="font-size: 35rpx;color: #3e9982;"></view> </view> </view> </view> <view style="height: 120rpx;"> </view> </view> </scroll-view> <view class="flex-column-center" style="position: fixed;bottom: -180px;" :animation="animationData" > <view class="bottom-dh-char flex-row-around" style="font-size: 55rpx;"> <input v-model="msg" class="dh-input" type="text" style="background-color: #f0f0f0;" @confirm="sendMsg" confirm-type="search" placeholder-class="my-neirong-sm" placeholder="说点什么吧..." /> <view @click="sendMsg" class="cu-tag bg-cyan round"> 发送消息 </view> <text @click="ckAdd" class="cuIcon-roundaddfill text-brown"></text> </view> </view> </view>
</template>
本地通过proxy代理一下,请求到AI ChatGLM2 6B的服务器,可以完成集成到开发客服系统中来。

以下为AI ChatGLM2 6B的服务器的日志相关信息。

小结:
通过快速部署 ChatGLM2-6B-int4 本地模型及基于 P-Tuning v2 的微调,可以搭建属于企业垂直领域的私域客服知识体系。帮助理解用户的问题,并提供准确、及时的回答和解决方案。从而基于人工智能技术的自动化客户服务系统,旨在提高客户满意度和降低企业成本。

目前主要应用在客户咨询等场景,可以帮助企业大幅提升服务效率,提高服务质量,降低人工成本,成为企业提升服务效率、降低成本的重要方式,也可以帮助企业更好地应对日益复杂的客户需求和市场变化。

当然,AI客服人工智能仍然有其局限性,无法完全取代人类客服。因此,人与AI对话的合作将是未来客户服务的发展方向,共同为用户提供更好的服务。
与传统的客户服务相比,基于“高性能应用服务HAI”应用式AI功能能够利用自然语言提示词进行自动化机器人程序开发,在大语言模型(LLM)的加持下,提升智能化问题解决效率,加速问题的有效处理。
有些同学可能是第一次接触GPU这个概念,接下来我就来普及一下GPU是什么?有什么样的一些特点?为什么在AI、深度训练和图像处理等领域大受欢迎呢?
九、什么是GPU?GPU与CPU有什么区别吗?GPU有哪些应用场景?
1. 什么是GPU?
GPU,全称为图形处理器,是一种专门设计用于处理计算机图形和图像的处理器。它可以加速计算机图形渲染和处理操作,提高计算机图形和图像的性能和质量。GPU相对于CPU而言,具有更多的处理单元和更高的并行处理能力,因此可以更快地处理大量的图形和图像数据。
GPU的主要功能包括图形渲染、图像处理、计算加速等。
- 在游戏、动画、视觉效果等领域中,GPU是实现高质量图形和图像的必要组件。
- 在科学计算、深度学习等领域中,GPU也可以作为计算加速器来使用,可以大幅提高计算速度和效率。
GPU的工作原理是通过多个处理单元并行处理图形、图像和计算任务来提高处理速度和效率。这些处理单元分布在不同的计算核心和计算单元中,可以同时处理多个任务。此外,GPU还使用了高速缓存、显存等技术来优化数据存储和访问,进一步提高了性能和速度。
2. CPU与GPU的不同特点:

3. 显卡是GPU吗?
通常所说的显卡(Graphics Card)指的是安装了 GPU 的设备。
上图所示,显卡除了包含 GPU 之外,还包括显存、供电模块、总线、风扇、显卡 BIOS、外围设备等部件。显卡通过将 CPU 传输的数据转换为图像信号,控制显示器输出图像。
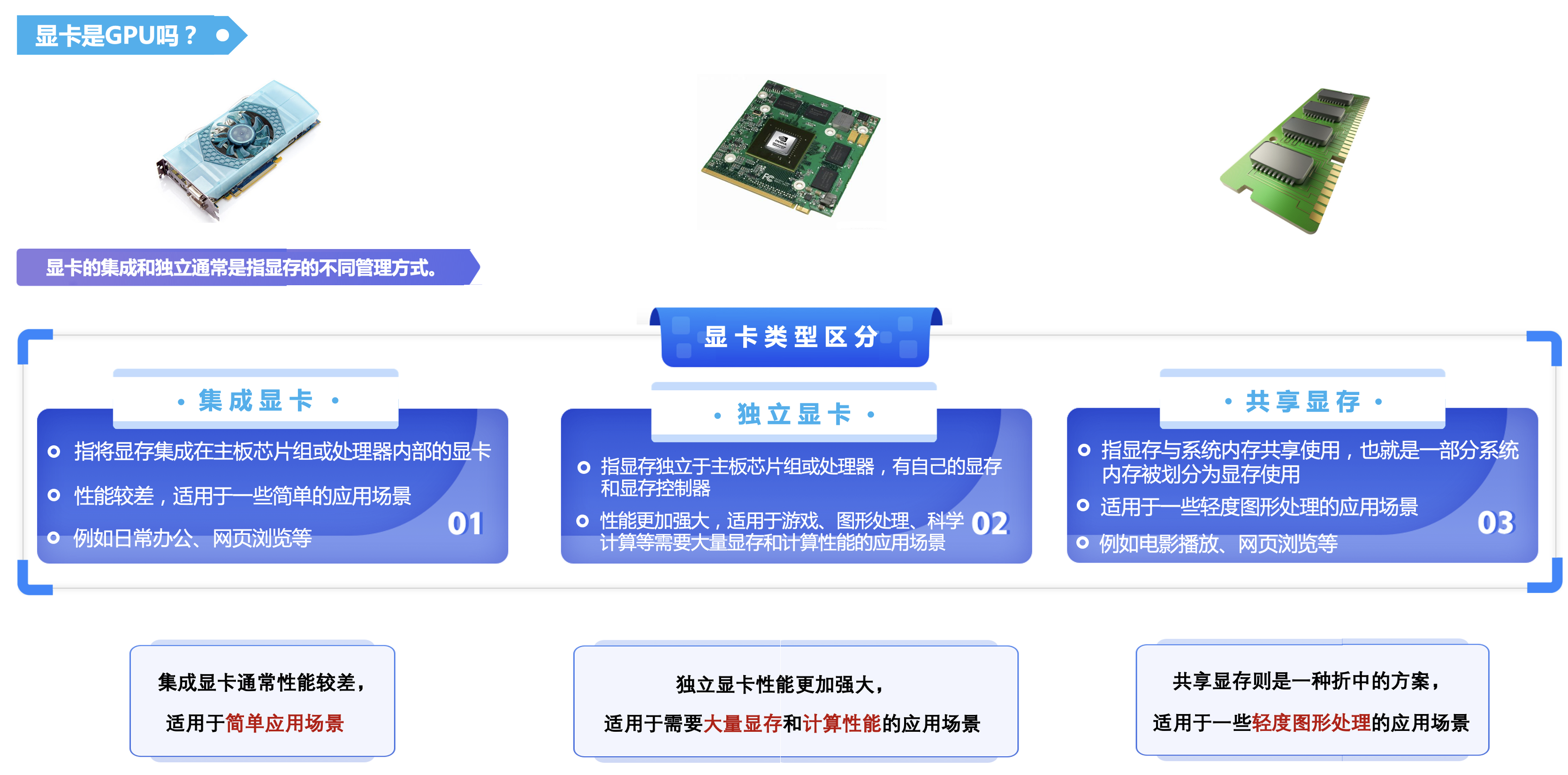
可以看出,在一些需要大量图像处理或计算的应用场景中,GPU 可以比 CPU 更高效地完成任务。因此,现代的显卡也广泛应用于机器学习、深度学习、AI人工智能等领域的加速计算,甚至被用于科学计算、天文学、地质学、气象学、量子学等众多领域。
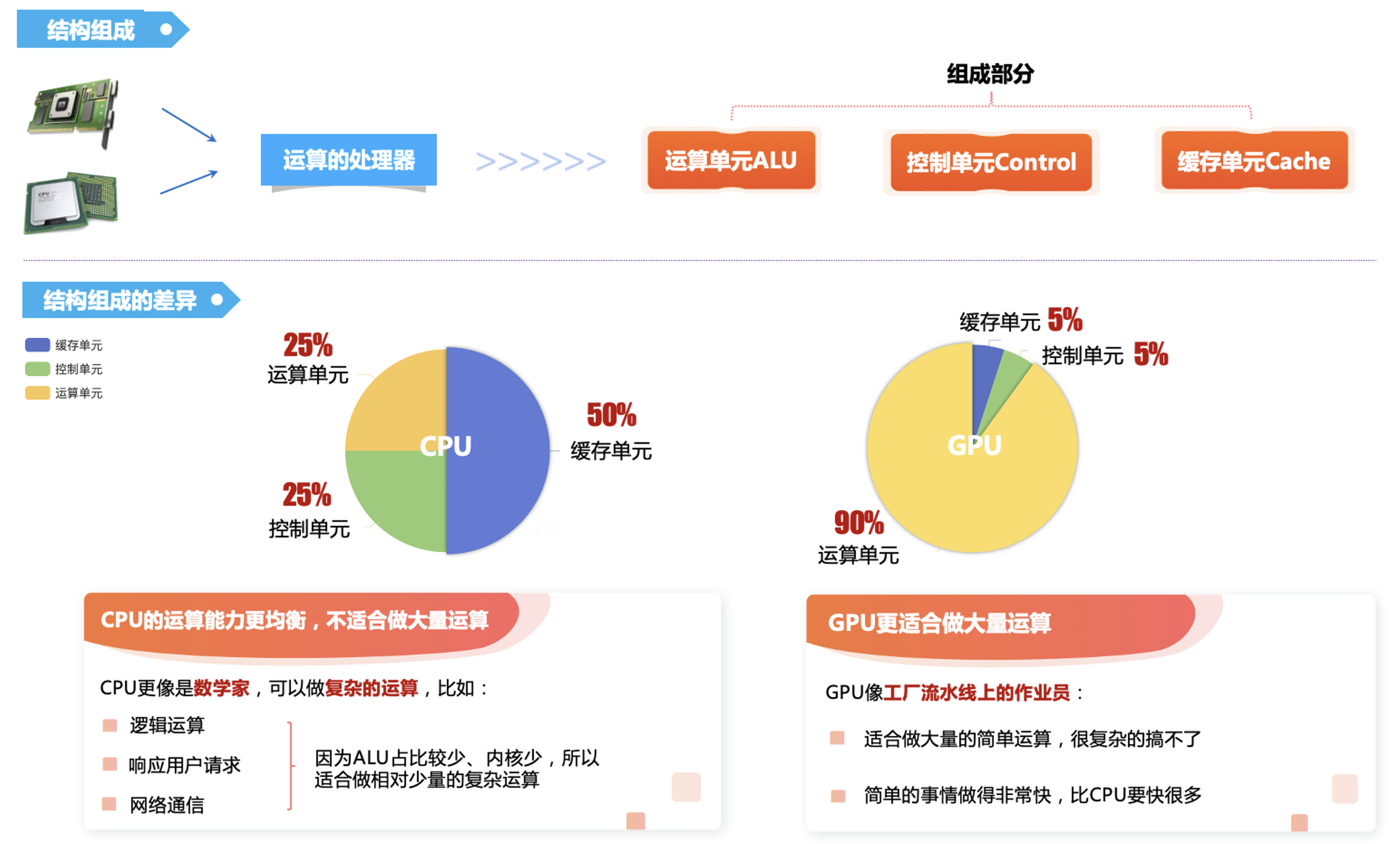
4. 不同的结构组成:
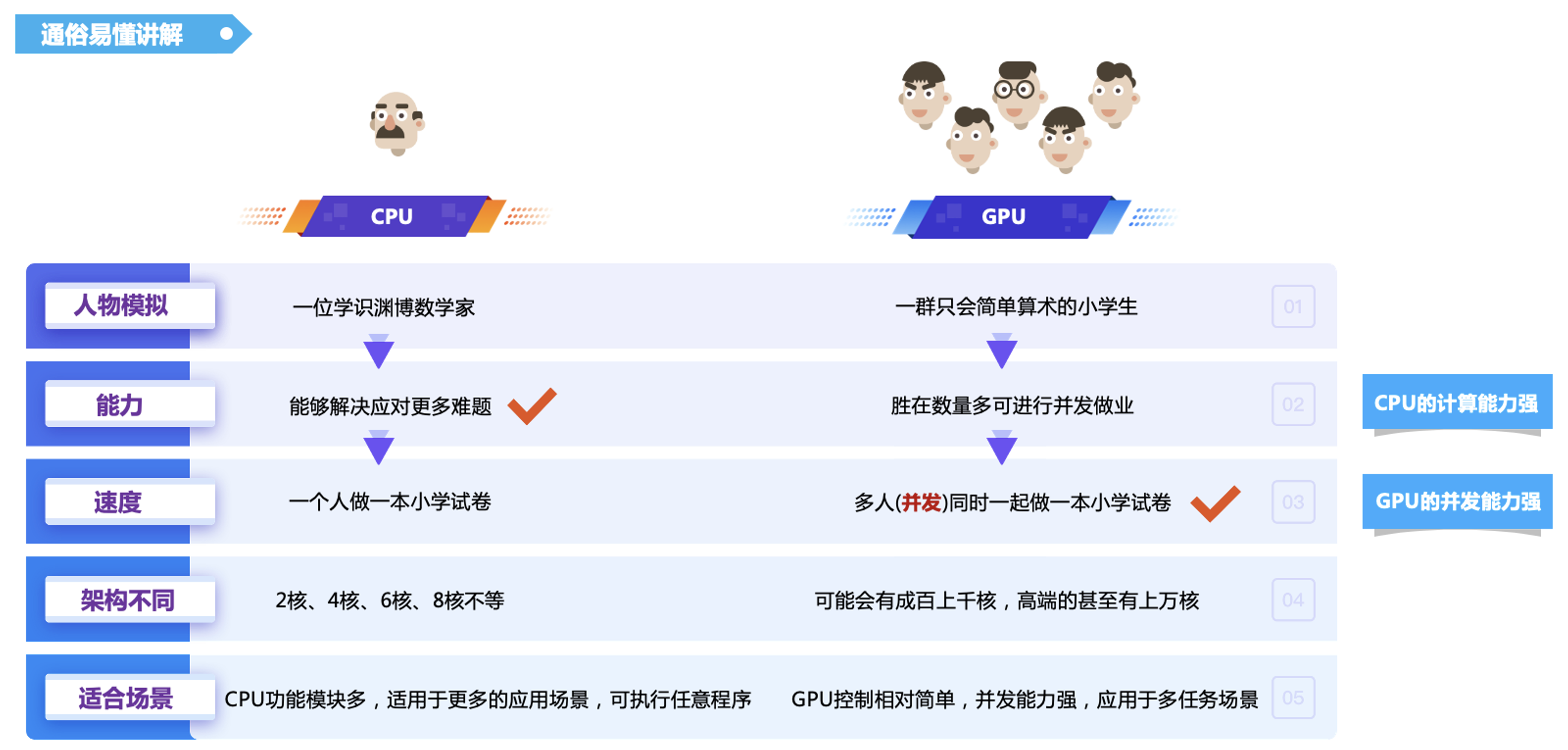
5. 白话文区别:
6. Nvidia 产品矩阵:

十、公司AIGC业务降本增效之路考量:
AIGC是一种新的人工智能技术,它的全称是Artificial Intelligence Generative Content,即人工智能生成内容。现阶段AIGC多以单模型应用的形式出现,主要分为文本生成、图像生成、视频生成、音频生成,其中文本生成成为其他内容生成的基础。
通过“腾讯云高性能应用服务HAI”实践了AI作画、AI深度学习、AI LLM模型的案例,可以体验到简易部署、便捷维护,减少工作量、步骤繁琐、效率低和时间成本的问题,同时提升系统整体性能和用户体验。
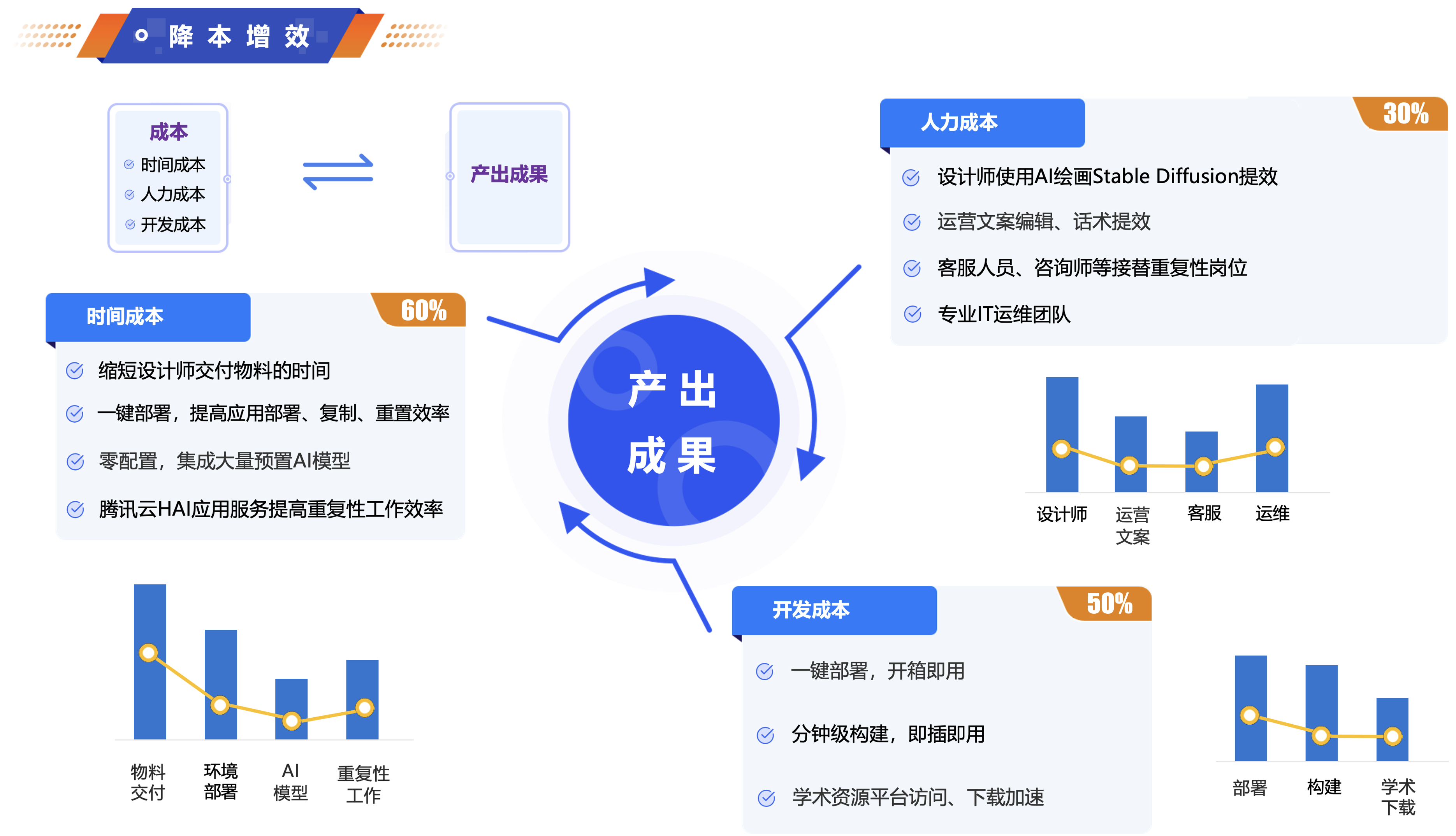
以下为在体验过程中,个人觉得非常提效的几个点:

同时,在体验AIGC的应用中,可以通过“腾讯云高性能应用服务HAI”的应用大幅提高内容生成的速度,节省时间和资源,“腾讯云高性能应用服务HAI”可以轻松应对大规模的内容生成需求。
序号 | 分类 | 描述 |
|---|---|---|
1 | 提升生产效率 | “腾讯云高性能应用服务HAI”大幅提高生产效率,进一步优化生产流程,提高生产效率。 |
2 | 降低运营成本 | “腾讯云高性能应用服务HAI”可以降低企业的运营成本,帮助企业做出更加精准的生产决策, |
3 | 优化资源利用 | “腾讯云高性能应用服务HAI”可以帮助企业优化资源利用,可以帮助企业更好地规划生产和资源分配,提高资源利用效率。 |
当然,并非是AI取代了人,而是会用AI对话模型、AI绘画工具的人,替换掉不会驾驭AI工具,传统的作业方式的人。让使用“腾讯云高性能应用服务HAI”的在企业中,实现“一个人顶一个组”、“支撑以前2-3倍的业务体量”。

同时,在对上面手册的实操,和自己企业内部的一些需求调研过程,也是“腾讯云高性能应用服务HAI”在实际应用中有一些SWOT的思考:
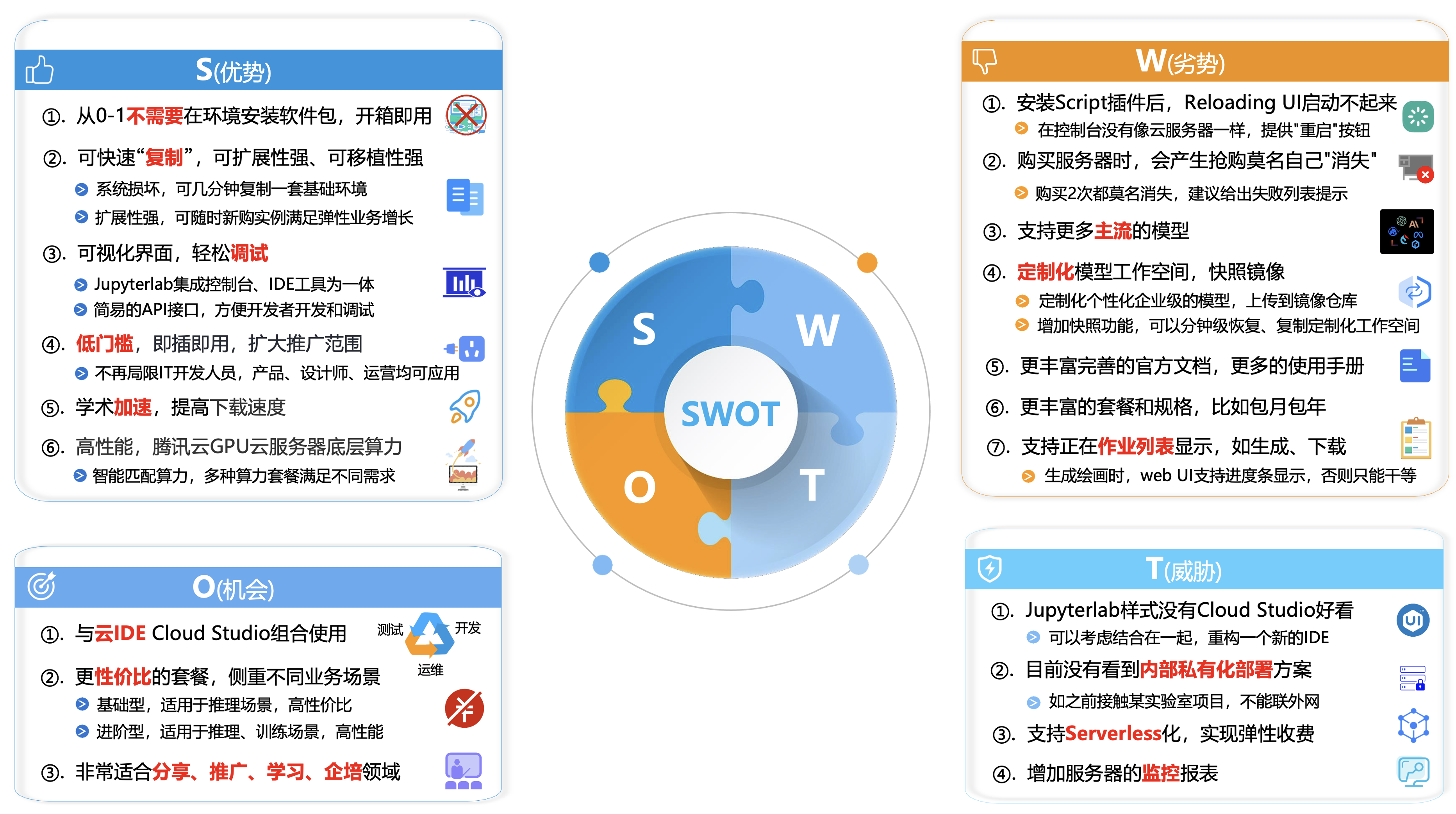
十一、公司业务其它AI场景的未来展望:
在新的AIGC技术浪潮之中,“腾讯云高性能应用服务HAI”的实践方案过程中,在公司推广技术导入方案会面临着这样的问题:
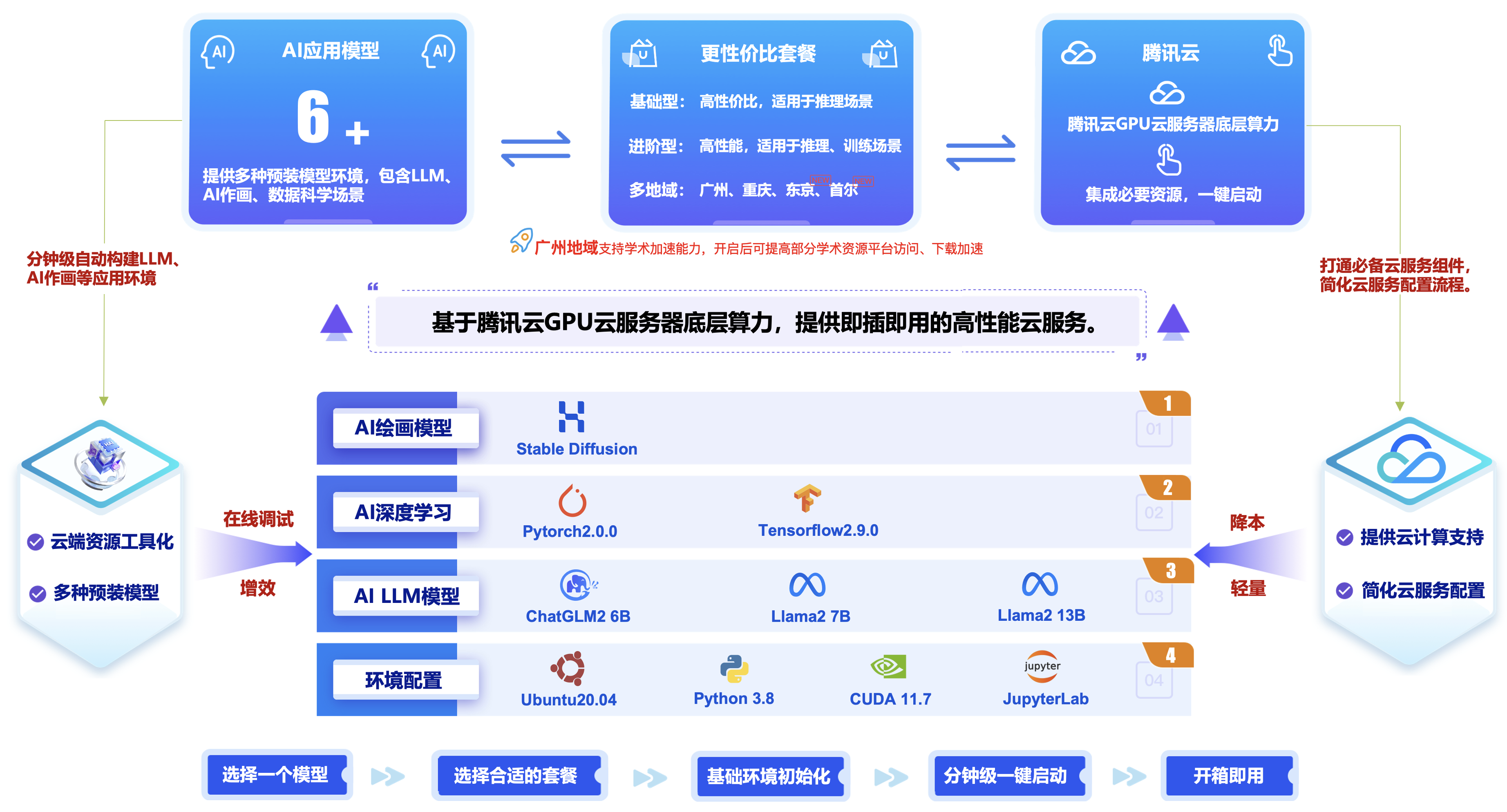
- 在的业务上应用“腾讯云高性能应用服务HAI”能获得什么?
- 如何快速、平滑地从传统的体系基础上完成“腾讯云高性能应用服务HAI”切换?
- 站在机器学习算法设计的角度,又会带来什么影响和改变?
- 在众多的AIGC生态下,众多的技术路线和架构选型中,如何确定“腾讯云高性能应用服务HAI”是一条比较适合自身场景的路径?
以下是公司经过了初创期、爬坡期,在行业内快速的吸引客户,并且占有一定的业务量,后续在原有的业务基础上,提高市场的竞争力,以及对公司一些CostDown原则的实施,希望能通过更多的AIGC的工具链路,帮助企业实施AI的战略布局。

事实上,通过以上对AIGC的一些工具Stable Diffusion和Pytorch、ChatGLM2-6B的案例,可以看到在原有的人工传统作业方式,通过AIGC的工具体系,来加速业务的处理效率。
十二、总结:
高性能应用服务(Hyper Application Inventor,HAI)是一款面向AI、科学计算的GPU应用服务产品,提供即插即用的澎湃算力与常见环境。助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用,原生集成配套的开发工具与组件,大幅提高应用层的开发生产效率、降低运营成本、提高产品质量和优化资源利用等。

序号 | 分类 | 描述 |
|---|---|---|
1 | 简单易用 | 通过简化计算、网络和存储等基础设施的配置流程,大幅降低了云服务操作和管理的复杂度。 |
2 | 应用环境快速部署 | 支持多种 AI 环境快速部署,如 ChatGLM-6B、StableDiffusion 等,使用户可专注业务及应用场景创新。 |
3 | 高灵活性 | 支持用户登录实例,对 AI 模型及实例环境进行灵活配置。可进行内部开发、业务测试,或对外提供业务服务。 |
4 | 多种登录方式 | 除传统连接方式外,支持通过 jupyterlab、WebUI 等方式一键启动,提供更贴合使用场景的登录方式。 |
5 | 算力种类丰富 | 提供多种算力套餐选择,未来还将加入更多种类供用户选择。 |
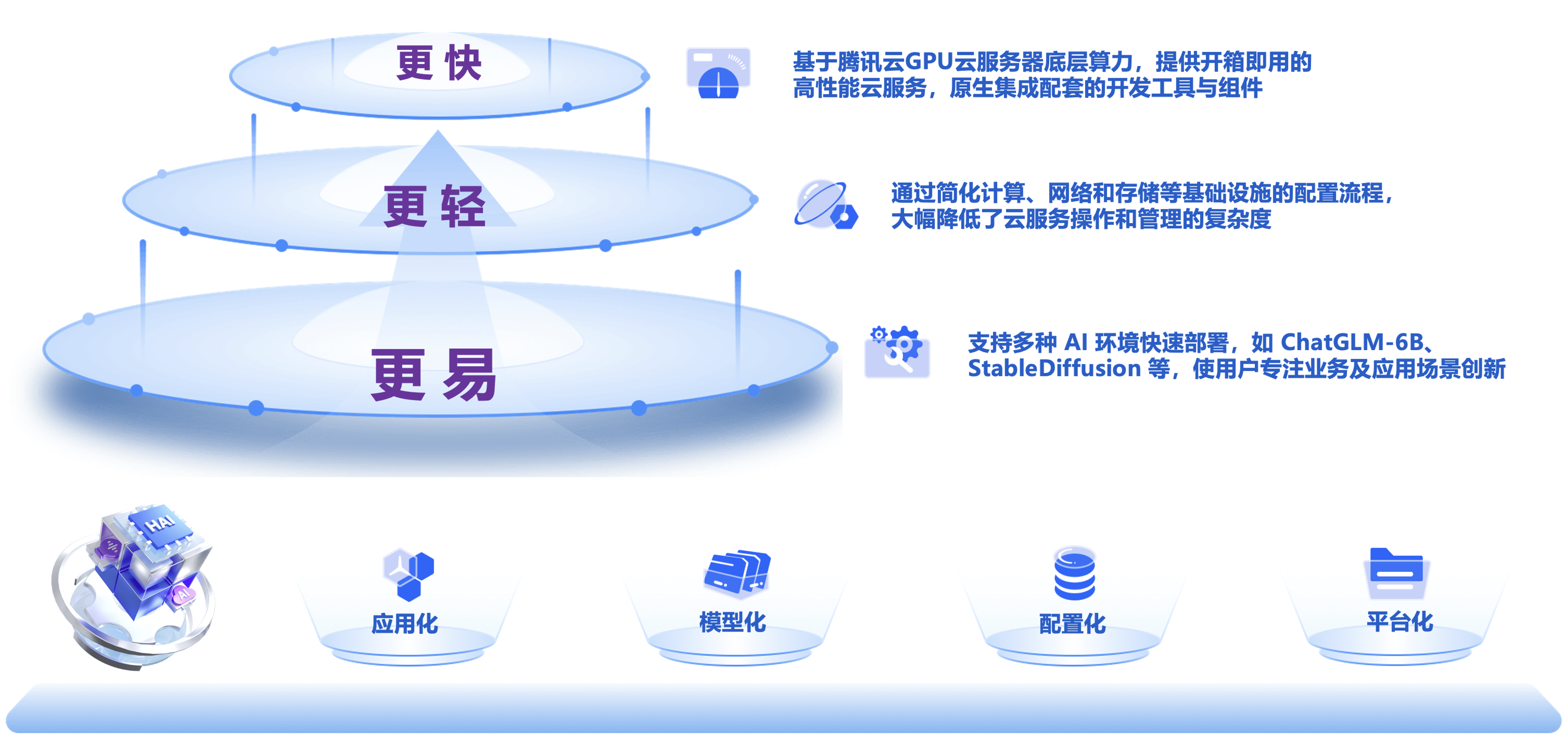
得益于人工智能技术的不断迭代与突破式发展,高性能应用服务HAI应运而生,应用式AI可以驱动各行各业,如营销与销售、产品与研发和客户运营等业务职能,帮助企业增强客户体验、提升员工生产力和创造力、优化业务流程,腾讯云致力于推动生成式AI普惠化,赋能千行百业持续创新。