大家好,我是历小冰。ElasticSearch 作为一个分布式的开源搜索和分析引擎,不仅能够进行全文匹配搜索,还可以进行聚合分析。
今天,我们就来了解一下其聚合分析中较为常见的 percentiles 百分位数分析。n 个数据按数值大小排列,处于 p% 位置的值称第 p 百分位数。
比如说,ElasticSearch 记录了每次网站请求访问的耗时,需要统计其 TP99,也就是整体请求中的 99% 的请求的最长耗时。
近似算法
当数据量较小或者数据集中存储在同一位置时,进行类似 TP99 这样的百分位数分析就很容易。
但当数据量不断增长时,对于数据进行聚合分析就需要在数据量,精确度和实时性三个方面进行取舍,只能满足其中两项。
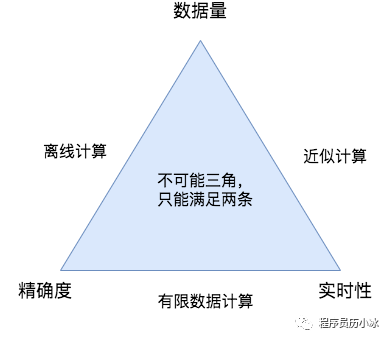
如上图所示,我们一共有三种选择方案:
- 有限数据计算:选择了精确度高和实时性,必然不能处理较大量级的数据,比如 MySQL 对单机数据进行统计分析;
- 离线计算:选择了大数据量和精确度高,导致实时性较差,比如 Hadoop 可以在 PB 级别数据上提供精确分析,但是可能要很长时间;
- 近似计算:选择了大数据量和实时性,但会损失一定的精确度,比如0.5%,但提供相对准确的分析结果。
Elasticsearch 目前支持两种近似算法,分别是 cardinality 和 percentiles。
cardinality 用于计算字段的基数,即该字段的 distinct 或者 unique 值的数量。cardinality 基于 HyperLogLog(HLL)算法实现。
HLL 会先对数据进行哈希运算,然后根据哈希运算的结果中的位数做概率估算从而得到基数。有关 HLL 算法的细节可以阅读《Redis HyperLogLog 详解》一文。
而 percentiles 则是本文的重点。
百分位数
ElasticSearch 可以使用 percentiles 来分析指定字段的百分位数,具体请求如下所示,分析 logs 索引下的 latency 字段的百分位数,也就是计算网站请求的延迟百分位数。
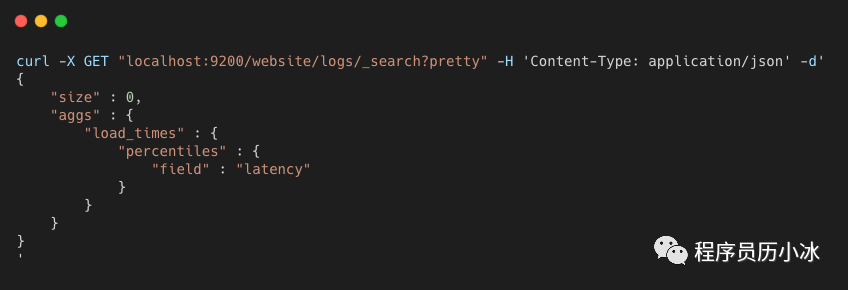
percentiles 默认情况下会返回一组预设的百分位数值,分别是 [1, 5, 25, 50, 75, 95, 99] 。它们表示了人们感兴趣的常用百分位数值,极端的百分位数在范围的两边,其他的一些处于中部。
具体的返回值如下图所示,我们可以看到最小延时在 75ms 左右,而最大延时差不多有 600ms。与之形成对比的是,平均延时在 200ms 左右。

和前文的 cardinality 基数一样,计算百分位数需要一个近似算法。
对于少量数据,在内存中维护一个所有值的有序列表, 就可以计算各类百分位数,但是当有几十亿数据分布在几十个节点时,这类算法是不现实的。
因此,percentiles 使用 TDigest 算法,它是一种近似算法,对不同百分位数的计算精确度不同,较为极端的百分位数范围更加准确,比如说 1% 或 99% 的百分位要比 50% 的百分位要准确。这是一个好的特性,因为多数人只关心极端的百分位。
TDigest 算法
TDigest 是一个简单,快速,精确度高,可并行化的近似百分位算法,被 ElastichSearch、Spark 和 Kylin 等系统使用。TDigest 主要有两种实现算法,一种是 buffer-and-merge 算法,一种是 AV L树的聚类算法。
TDigest 使用的思想是近似算法常用的 Sketch,也就是素描,用一部分数据来刻画整体数据集的特征,就像我们日常的素描画一样,虽然和实物有差距,但是却看着和实物很像,能够展现实物的特征。
下面,我们来介绍一下 TDigest 的原理。比如有 500 个 -30 ~ 30 间的数字,我们可以使用概率密度函数(PDF)来表示这一数据集。
该函数上的某一点的 y 值就是其 x 值在整体数据集中的出现概率,整个函数的面积相加就正好为 1 ,可以说它刻画了数据在数据集中的分布态势(大家较为熟悉的正太分布示意图展示的就是该函数)。

有了数据集对应的 PDF 函数,数据集的百分位数也能用 PDF 函数的面积表示。如下图所示,75% 百分位数就是面积占了 75% 时对应的 x 坐标。

我们知道,PDF 函数曲线中的点都对应着数据集中的数据,当数据量较少时,我们可以使用数据集的所有点来计算该函数,但是当数据量较大时,我们只有通过少量数据来代替数据集的所有数据。
这里,我们需要将数据集进行分组,相邻的数据分为一组,用 平均数(Mean)和 个数(Weight)来代替这一组数。这两个数合称为 Centroid(质心数),然后用这个质心数来计算 PDF,这就是 TDigest 算法的核心思想。

如上图所示,质心数的平均值作为 x 值,个数作为 y 值,可以通过这组质心数大致绘制出这个数据集的 PDF 函数。
对应的,计算百分位数也只需要从这些质心数中找到对应的位置的质心数,它的平均值就是百分位数值。
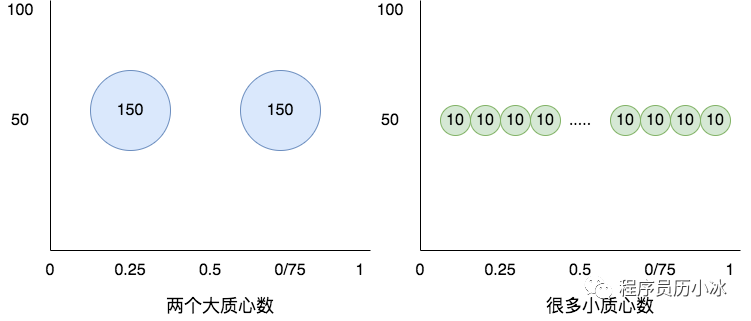
很明显,质心数的个数值越大,表达它代表的数据越多,丢失的信息越大,也就越不精准。如上图所示,太大的质心数丢失精准度太多,太小的质心数则有消耗内存等资源较大,达不到近似算法实时性高的效果。
所以,TDigest 在压缩比率(压缩比率越大,质心数代表的数据就要越多)的基础上,按照百分位数来控制各个质心数代表的数据的多少,在两侧的质心数较小,精准度更高,而在中间的质心数则较大,以此达到前文所说的 1% 或 99% 的百分位要比 50% 的百分位要准确的效果。
源码分析
ElasticSearch 直接使用了 TDigest 的开源实现 t-digest,其 github 地址为 https://github.com/tdunning/t-digest,我们可以在 ElastichSearch 的 TDigestState 类看到其对 t-digest 实现的封装。
t-digest 提供了两种 TDigest 算法的实现:
MergingDigest对应上文所说的 buffer-and-merge 算法AVLGroupTree对应 AVL 树的聚类算法。
MergingDigest用于数据集已经排序的场景,可以直接根据压缩比率计算质心数,而 AVLGroupTree 则需要使用 AVL 树来自信对数据根据其”接近程度“进行判断,然后计算质心数。
MergingDigest的实现较为简单,顾名思义,其算法名称叫做 buffer-and-merge,所以实现上使用 tempWeight 和 tempMean 两个数组来代表质心数数组,将数据和保存的质心数进行 merge,然后如果超出 weight 上限,则创建新的质心数,否则修改当前质心数的平均值和个数。
而 AVLGroupTree 与 MergingDigest 相比,多了一步通过 AVL 二叉平衡树搜索数据最靠近质心数的步骤,找到最靠近的质心数后,也是将二者进行 merge,然后判断是否超过 weight 上线,进行修改或者创建操作。
下面,我们直接来看 AVLGroupTree 的 add 方法。

当 ElasticSearch 处理一个数据集时,就是不断将数据集中的数据通过调用 add 函数加入到质心数中,然后统计完毕后,调用其 quantile 来计算百分位数。
后记
欢迎大家继续关注程序员历小冰,后续会继续为大家带来有关数据存储,数据分析,分布式相关的文章。下一篇文章我们回来学习一下 ElasticSearch 的其他聚合分析操作的实现原理。
-关注我
推荐阅读
TCP/IP的底层队列
基于Redis和Lua的分布式限流
AbstractQueuedSynchronizer超详细原理解析
参考
- https://blog.bcmeng.com/post/tdigest.html
- https://blog.bcmeng.com/pdf/TDigest.pdf
- https://github.com/tdunning/t-digest
- https://op8867555.github.io/posts/2018-04-09-tdigest.html