前言
之前简单介绍过目标检测算法的一些评价标准,地址为目标检测算法之评价标准和常见数据集盘点。然而这篇文章仅仅只是从概念性的角度来阐述了常见的评价标准如Acc,Precision,Recall,AP等。并没有从源码的角度来分析具体的计算过程,这一篇推文的目的就是结合代码再次详细的解释目标检测算法中的常见评价标准如Precision,Recall,AP,mAP的具体计算过程。
评价指标
由于在上面那篇推文中已经详细解释过了,所以这里就只是简单的再回顾一下,详细的解释请移步那篇推文看看。为了方便理解,还是先说一下TP,TN,FP,FN的含义。
一个经典例子是存在一个测试集合,测试集合只有大雁和飞机两种图片组成,假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。然后就可以定义:
- True positives: 简称为TP,即正样本被正确识别为正样本,飞机的图片被正确的识别成了飞机。
- True negatives: 简称为TN,即负样本被正确识别为负样本,大雁的图片没有被识别出来,系统正确地认为它们是大雁。
- False Positives: 简称为FP,即负样本被错误识别为正样本,大雁的图片被错误地识别成了飞机。
- False negatives: 简称为FN,即正样本被错误识别为负样本,飞机的图片没有被识别出来,系统错误地认为它们是大雁。
接下来我们就开始定义一些评价标准:
- 准确率(Acc):准确率(Acc)的计算公式为,即预测正确的样本比例,代表测试的样本数。在检测任务中没有预测正确的负样本的概念,所以Acc自然用不到了。
- 查准率(Precision):查准率是针对某一个具体类别而言的,公式为:,其中N代表所有检测到的某个具体类的目标框个数。
- 召回率(Recall):召回率仍然是针对某一个具体类别而言的,公式为:,即预测正确的目标框和所有Ground Truth框的比值。
- F1 Score:定位Wie查准率和召回率的调和平均,公式如下:。
- IOU:先为计算mAP值做一个铺垫,即IOU阈值是如何影响Precision和Recall值的?比如在PASCAL VOC竞赛中采用的IoU阈值为0.5,而COCO竞赛中在计算mAP较复杂,其计算了一系列IoU阈值(0.05至0.95)下的mAP当成最后的mAP值。
- mAP:全称为Average Precision,AP值是Precision-Recall曲线下方的面积。那么问题来了,目标检测中PR曲线怎么来的?可以在这篇论文找到答案,截图如下:

我来解释一下,要得到Precision-Recall曲线(以下简称PR)曲线,首先要对检测模型的预测结果按照目标置信度降序排列。然后给定一个rank值,Recall和Precision仅在置信度高于该rank值的预测结果中计算,改变rank值会相应的改变Recall值和Precision值。这里选择了11个不同的rank值,也就得到了11组Precision和Recall值,然后AP值即定义为在这11个Recall下Precision值的平均值,其可以表征整个PR曲线下方的面积。即:
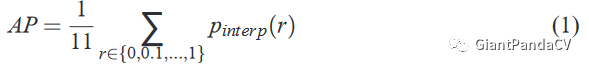
在这里插入图片描述
还有另外一种插值的计算方法,即对于某个Recall值r,Precision取所有Recall值大于r中的最大值,这样保证了PR曲线是单调递减的,避免曲线出现摇摆。另外需要注意的一点是在2010年后计算AP值时是取了所有的数据点,而不仅仅只是11个Recall值。我们在计算出AP之后,对所有类别求平均之后就是mAP值了,也是当前目标检测用的最多的评判标准。
- AP50,AP60,AP70等等代表什么意思?代表IOU阈值分别取0.5,0.6,0.7等对应的AP值。
代码解析
下面解析一下Faster-RCNN中对VOC数据集计算每个类别AP值的代码,mAP就是所有类的AP值平均值。代码来自py-faster-rcnn项目,链接见附录。代码解析如下:
# --------------------------------------------------------
# Fast/er R-CNN
# Licensed under The MIT License [see LICENSE for details]
# Written by Bharath Hariharan
# --------------------------------------------------------
import xml.etree.ElementTree as ET #读取xml文件
import os
import cPickle #序列化存储模块
import numpy as np
def parse_rec(filename):
""" Parse a PASCAL VOC xml file """
tree = ET.parse(filename)
objects = []
# 解析xml文件,将GT框信息放入一个列表
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
obj_struct['pose'] = obj.find('pose').text
obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
# 单个计算AP的函数,输入参数为精确率和召回率,原理见上面
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
# 如果使用2017年的计算AP的方式(插值的方式)
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# 使用2010年后的计算AP值的方式
# 这里是新增一个(0,0),方便计算
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
# 主函数
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.5,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: 产生的txt文件,里面是一张图片的各个检测框结果。
annopath: xml 文件与对应的图像相呼应。
imagesetfile: 一个txt文件,里面是每个图片的地址,每行一个地址。
classname: 种类的名字,即类别。
cachedir: 缓存标注的目录。
[ovthresh]: IOU阈值,默认为0.5,即mAP50。
[use_07_metric]: 是否使用2007的计算AP的方法,默认为Fasle
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
# 首先加载Ground Truth标注信息。
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
# 即将新建文件的路径
cachefile = os.path.join(cachedir, 'annots.pkl')
# 读取文本里的所有图片路径
with open(imagesetfile, 'r') as f:
lines = f.readlines()
# 获取文件名,strip用来去除头尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)
imagenames = [x.strip() for x in lines]
#如果cachefile文件不存在,则写入
if not os.path.isfile(cachefile):
# load annots
recs = {}
for i, imagename in enumerate(imagenames):
#annopath.format(imagename): label的xml文件所在的路径
recs[imagename] = parse_rec(annopath.format(imagename))
if i % 100 == 0:
print 'Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames))
# save
print 'Saving cached annotations to {:s}'.format(cachefile)
with open(cachefile, 'w') as f:
#写入cPickle文件里面。写入的是一个字典,左侧为xml文件名,右侧为文件里面个各个参数。
cPickle.dump(recs, f)
else:
# load
with open(cachefile, 'r') as f:
recs = cPickle.load(f)
# 对每张图片的xml获取函数指定类的bbox等
class_recs = {}# 保存的是 Ground Truth的数据
npos = 0
for imagename in imagenames:
# 获取Ground Truth每个文件中某种类别的物体
R = [obj for obj in recs[imagename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in R])
# different基本都为0/False
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult) #自增,~difficult取反,统计样本个数
# # 记录Ground Truth的内容
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets 读取某类别预测输出
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines]
image_ids = [x[0] for x in splitlines] # 图片ID
confidence = np.array([float(x[1]) for x in splitlines]) # IOU值
BB = np.array([[float(z) for z in x[2:]] for x in splitlines]) # bounding box数值
# 对confidence的index根据值大小进行降序排列。
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
#重排bbox,由大概率到小概率。
BB = BB[sorted_ind, :]
# 图片重排,由大概率到小概率。
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
这个脚本可以直接调用来计算mAP值,可以看一下附录中的最后一个链接。
附录
- http://host.robots.ox.ac.uk/pascal/VOC/pubs/everingham15.pdf
- http://homepages.inf.ed.ac.uk/ckiw/postscript/ijcv_voc09.pdf
- 代码链接:https://github.com/rbgirshick/py-faster-rcnn/blob/master/lib/datasets/voc_eval.py
- 在Darknet中调用上面的脚本来计算mAP值:https://blog.csdn.net/amusi1994/article/details/81564504