10月27日,对售后服务经理来说又是一个不眠之夜。腾讯云汽车行业某头部客户的智能化应用--车联网业务故障了60min,期间APP功能完整性、蓝牙钥匙解锁失效;车机的音视频、导航、天气等周边服务不可用。
智能化是新能源汽车产业发展的主流和趋势,车联网业务是其中十分关键的一环,客户对此业务的安全性、可用性十分重视。所以针对此次故障,客户的运维联系腾讯云售后团队,一起做了深入的复盘,一致认为云防火墙产品、客户侧的高可用措施都是具备的,短板在应急体系:当不可避免的故障发生时,应急预案能否成功兜底,大家都没信心。
如何在没有故障时,尽可能贴近真实的验证应急能力呢?我们推荐了混沌工程这一利器。介绍了腾讯云的混沌工程专家服务后,客户当即和我们组成了联合项目,在云防火墙上,实施混沌工程。
经过了两个多月的协作,我们从腾讯云角度、客户业务角度,讨论制定了混沌方案并付诸实施。最终有如下提升:
1、客户的长、短链接场景都更好的利用了腾讯云高防产品的安全能力
2、客户对车联网业务的故障处理时长从60分钟降低到最低4min
3、客户具备了将混沌工程在公司内推广的能力等。
看着如此全面的提升,我想客户对自己核心产品--智能化业务的稳定性信心回来了。。。
1. 客户侧挑战
根据与该客户的沟通,在此场景实施混沌工程,有以下痛点:
1)合作时间窗口小
非自上而下的客户界面联合项目,极易受客户的工作安排影响,导致实际时间窗口很小。就需要我们的混沌方案,在充分覆盖目标系统的基础上,可以把最重要的事项优先执行以取得客户信任。
2)对混沌实验影响敏感
主要合作对象是客户运维,而运维只是客户公司内一环。如果混沌实验造成了较大影响(包括测试环境),那么整个项目就面临无限延期的可能。
3)实验的长期性
混沌实验方案可重复执行,可长期对系统的能力保鲜。
2. 解决方案整体设计
2.1 业界方法论分析和对比
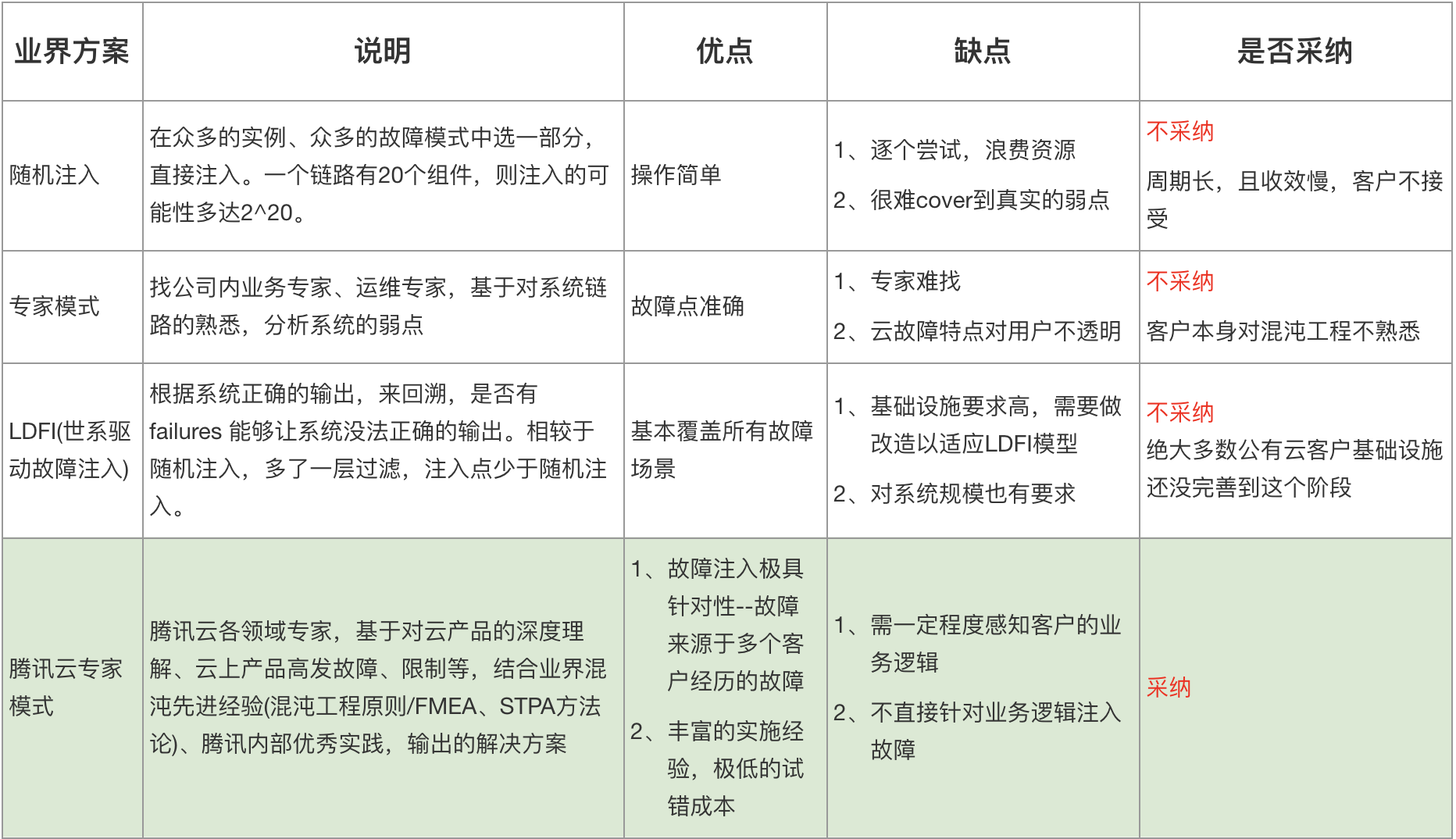
业界针对混沌实验的设计大概有三种流派:随机注入、专家模式、LDFI。
业界的这几种方式,在腾讯云客户服务的场景,都不符合要求,因为既没有在短时间内帮客户解决客户的诉求,也没有体现腾讯云专家的价值(如下表)。
最终结合对腾讯云产品深度理解、腾讯内丰富的混沌经验、业界的先进经验,输出了《腾讯云专家模式》的方法进行混沌工程建设。
各设计流派对比情况如下:
2.2 腾讯云专家模式具体思路
- 通过全面分析系统(明确目标系统、系统弱点探查),梳理出最有价值的实验项,弥补时间窗口小的问题
- 基于混沌工程原则设计混沌实验、Gameday设计,最小化混沌实验风险
- 单次实验的报告复盘、持续迭代来提升实验的长期性
2.3 腾讯云专家模式流程图

长文预警
下面行文分为两部分:混沌工程设计方法论(3.混沌工程设计方法论)和基于方法论的实战(4.某新能源汽车云防火墙混沌工程实战)。
逐段阅读可深入理解笔者的设计理念并通过实战加深理解。
喜欢看实战的读者可直接跳过方法论部分,先看实战是怎么执行的;然后带着问题再看设计理念,相信也会有不一样的收获。
3.混沌工程设计方法论
3.1 目标系统分析
无论要在单组件实施混沌工程,还是在多组件实施混沌工程,他们都服从于一个大前提:目标系统的SLA。
组件可用性能力最后支撑了目标系统的可用性能力,组件应该具备什么能力是目标系统决定的。
所以妥善分析系统边界、组成部分、主要特征、能力要求,然后把这些元素细化到该系统的具体研究对象,是混沌设计的第一步。
3.1.1 系统的运行环境拆解
一个系统运行,可能有如下依赖项:
- 互联网基础设施:DNS、HttpDNS、运营商网络等;
- 系统主体:业务服务、负载均衡/服务器/数据库等组件;
- 外部调用:外部系统调用、第三方调用;
- 业务链路:自身提供服务的链路等。
对于一个中型微服务系统,单组件就数千个;如果加上上千个微服务,整个梳理工作将十分巨大。
为了做混沌工程,这些信息需要细到什么程度?我们就需要参考下面的系统画像梳理框架。
3.1.2 系统画像梳理框架
在混沌工程初级阶段,我们采用的原则是优先共性:即提炼系统的重要共性部分,不片面追求大而全,共性基本可以解决95%以上问题。
基于这个思路,可以采用如下框架梳理系统的工作环境:

上面这些信息梳理清楚后,我们就可以对系统有一个全面、深刻的认识,知道系统运行的基础组件、核心业务链路、与其他系统间关系、系统基本环境如何改变的、系统能力等,这些信息构成了系统的基本画像,为探查系统弱点提供了物理基础。
3.2 探查系统弱点
这里的弱点不是指脆弱点,而是说系统中潜在会发生故障的地方。我们要能识别出来弱点,然后想办法优化,降低故障概率,减小故障损失到不响系统目标可用性的地步。
所以根据客户资源大都在腾讯云的特点,我们采用下面的方式探查系统弱点:

3.2.1 多样化真实世界的事件
什么情况下,系统会出问题?根据日常工作,大概会在三个方面:
- 组件故障:包括硬件设备、互联网基础设施、第三方组件等。这里我们基于各产品专家的意见,整理了云产品故障域、高可用评分等,都是我们探查组件故障的通用素材。
- 业务缺陷:包括资源过度消耗、健壮性缺失等(降级、限流、熔断、重试、超时等)。这里基于客户开放程度和业界最佳实践分析。
- 配置管理:包括发布变更、clb配置修改、数据库配置修改等。
3.2.2 实验对象梳理:FMEA/STPA
参考奈飞/aws等混沌工程实战比较好的企业,都在使用FMEA/STPA方法论,来作为初期梳理系统弱点的方法。
备注:梳理出来的弱点的改善措施,可以参考下面的目标能力清晰化方法论部分。
FMEA简介
FMEA覆盖系统组件(底层设备、业务程序)故障时,系统的表现、能力分析,关注故障模式。对应上文故障域:组件故障、业务缺陷。具体实施可以参考下表:
功能 | 架构组件 | 故障模式 | 故障影响 | 严重程度 | 故障原因 | 故障概率 | 风险程度 | 已有措施 | 规避措施 | 解决措施 | 后续规划 | 备注 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
针对 梳理框架 - 业务架构图与主链路 部分分析出的主链路的每次请求,我们可以看成是时序的横向链路,所以此处的分析我称为横向分析。
注意:
- 全面性:从人的视角,观察系统发生了什么;组件故障模式尽可能的全面。可以求助腾讯云高可用专家,也可以跟自己的partner、业务研发讨论;腾讯云针对各种组件的故障模式总结。
- 优先级:设计时,一定要对严重程度、故障概率、风险程度做详细调研,以保证分析贴合系统的历史运行情况。
- 故障处理措施:详细列出当前的故障处理措施,实际代表了故障处理能力,便于定义下面的SLA/SLI及后续的实验方案设计、优化调整等。
- 组件隔离性:针对每个组件的故障模式原因的分析,记得在自己组件内闭环,避免各层组件相互关联,最终整个分析表可读性差。比如Nginx是一个组件,则Nginx延迟的故障模式,原因不应该包含下游realserver延迟。
- 最终全覆盖:分析出来的项目,建议最终都进行实验操作;故障影响、风险程度都是基于已有线索的假说,并不构成结论。
特别关注的字段:
故障影响,是从业务视角看到的问题。建议不要"发明"自己的故障影响术语,而是参考业界的最佳监控实践,设计故障影响,方便大家理解。建议根据混沌实验的目标不同,选择google的SRE四个黄金指标理论(资源受限、扩容受限的微服场景)、RED方法(prometheus+k8s微服务场景)、USE方法(性能分析)来定义故障影响。
STPA简介
STPA覆盖配置管理异常时,系统的表现、能力分析,关注控制危害。对应上文故障域:配置管理。具体实施可以参考下表:
架构组件 | 控制面 | 操作面 | 故障模式 | 故障影响 | 严重程度 | 故障原因 | 故障概率 | 风险程度 | 已有措施 | 规避措施 | 解决措施 | 后续规划 | 备注 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
针对 业务流程与控制结构 部分分析出的、对主链路的组件的管控动作,我们可以看成是瀑布式的纵向链路,所以此处的分析我称为纵向分析。
这里主要是分清楚操作面、控制面、数据面(即被操作组件/系统),其他的字段参考FMEA分析。
举例:通过腾讯云官网控制台,操作CDB安全组。数据面就是CDB系统,控制面是腾讯云官网,操作面是操作人。潜在故障模式包括不限于高峰期变更、控制台不可用
这里STPA方法,就是分析操作面、控制面的潜在故障模式,影响了数据面的可用性。
3.2.3 目标能力清晰化
为了应对生产上的故障,我们会采取整站高可用建设。下面套用的是某个业界较常用的一个高可用模型:
- 预防故障发生
- 预防故障扩散
- 故障快速发现
- 故障定位止损
- 灾难恢复
核心思想是如何在事前、事中、事后三个阶段保证业务受损时间最小化。
我们梳理出系统的弱点后,可以针对每个弱点,细化业务/运维/流程等方面具备什么能力以及将要建设什么能力。
针对不具备的能力,则转向高可用建设;针对已具备的能力,设计针对性的实验,通过实验结果的对照、验证我们系统具备的能力,学到新的东西。
3.2.4 组件SLA/SLI
通过FMEA/STPA分析后,目标系统各组件的SLA(故障预算或月度最大故障时长)、SLI(组件关注的故障影响)已经可以明确给出了
SLA:参考整体组件的故障频率、管理措施(变更、容量管理策略)、高可用能力、自愈程度等维度,给出待实验组件的SLA,也称为故障预算
SLI:参考待实验组件的故障模式(弱点梳理部分),即可看出来该组件的SLI包含哪些。
3.3 设计混沌实验
3.3.1 实验目标
实验目标是cover系统弱点的处理能力的,修复系统弱点能力的基本分类:
- 预防:验证基础系统的高可用措施、业务程序的健壮性、自愈能力按预期执行
- 识别:验证系统告警时效、收敛、准确性等
- 止损:验证运维的恢复能力
- 预案:验证系统的关键预案可执行性
- 灾难恢复
实际实验过程中,可以根据实际情况,选择一项或多项作为目标。
3.3.2 实验设计
围绕稳态的假说
上面涉及的目标分类、SLA/SLI/故障处理模型分析,其实都为了同一个目标:最终提升系统的韧性。
所以在制定实验目标时,无论实验重点在哪里,假说一定是以SLA/SLI为牵引目标,最终体现在系统的韧性上面:局部故障时,业务程序可兼容;运维可在SLA/SLI内恢复故障。
由于每次实验,根据参与人员、参与实验的系统/组件、实验背景的异同等,实验目标侧重点也会不一样。
比如某客户最近发生了多次基础设施SLA达标但业务程序原因导致SLA不达标的情况,且参与人主要是开发人员,那实验重点可能就是偏业务程序的健壮性、识别能力、止损能力;目标系统分析则更侧重业务系统的链路梳理、高可用措施细节等。
对于重点验证的能力,建议根据 目标能力清晰化 部分,进行有层次的细化,便于更好的度量目标达成度。
最小化爆炸半径
我们实验,最终的目标还是在生产环境执行。所以实验方案对在线用户的影响、对生产数据的影响,要做一些详细的控制,中间业界推荐的方法就是想办法减小爆炸半径。这里比较直观,最小化爆炸半径可以考虑下面的思路:

自动化执行实验
这里面背后的思考:
- 手动运行实验是劳动密集型的, 最终是不可持续的
- 考虑实验的标准化,通过自动程序将实验动作模版化,提升在不同团队的互操作性、重复执行性。
所以我们要把实验自动化并持续运行,混沌工程要在系统中构建自动化的编排和分析。
就需要系统提供相关API与公司内部系统结合或者平台本身支持编排能力。
3.3.3 实验评审
微服务架构下,在高内聚、低耦合的思想下,系统变得愈发复杂,逐渐超出了人类的认知范围。由单一人或小组设计的实验,潜在存在对系统认知不全的情况。
所以,在实验评审时,尽可能根据目标系统的分析,将干系人都约起来,然后进行评审。通过集中式评审,完善实验方案、补齐相关人认知、给支持孤岛提供浮现的机会。
从实际经验来看,大多数时候,可以和GameDay设计一起。
评审维度参考表:
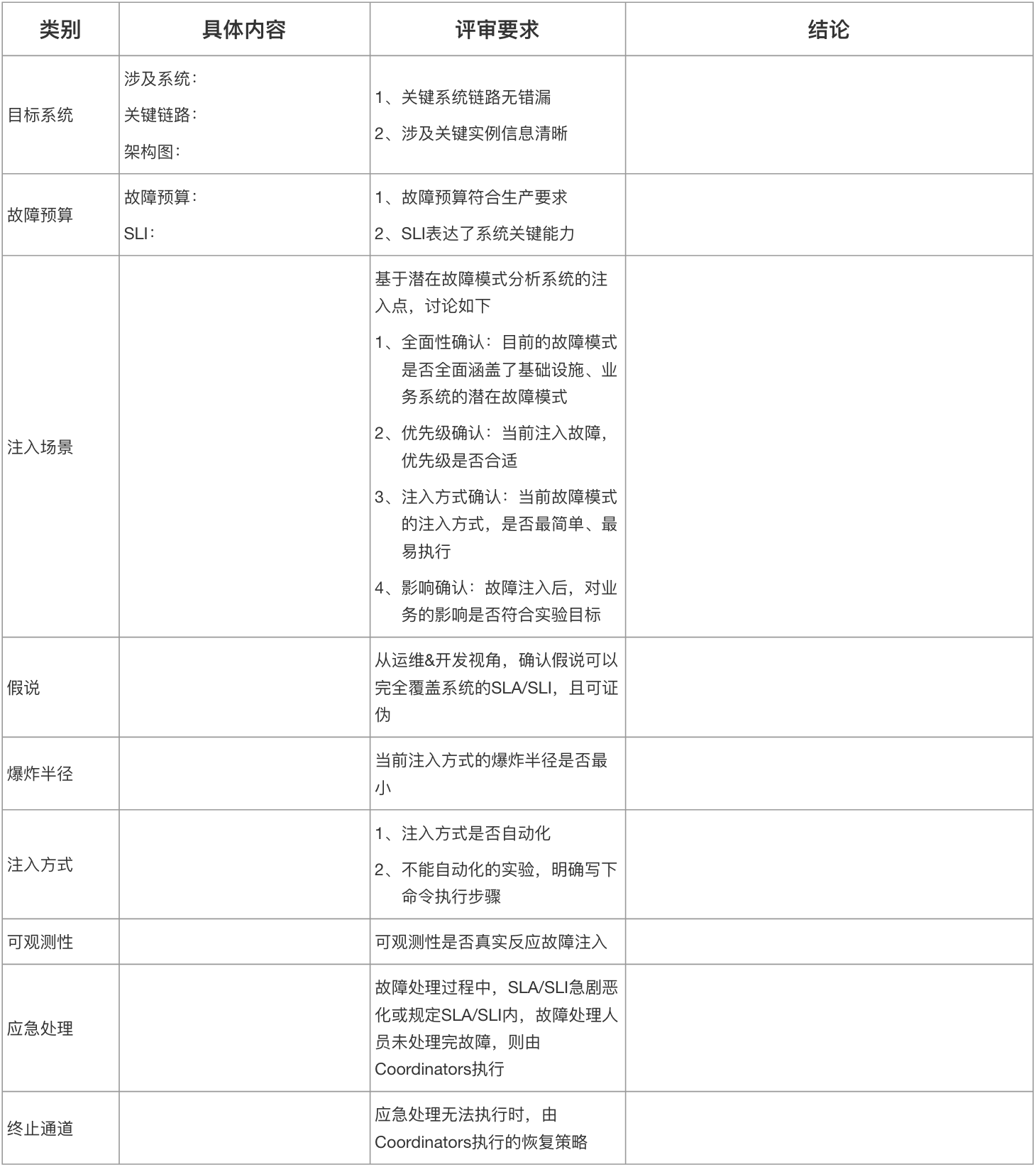
备注:如果实验项关联性很大,可整体评估;如果关联性小或是不同类型的实验项,则分开评估。
3.4 GameDay
3.4.1 GameDay设计
GameDay关键人梳理
Gameday包含两部分:实验处理人(Owners、Coordinators、Reporters、Observers)和故障处理人。
实验处理人主要用途:拉通方案里面的运维、研发、IT等干系人,通过多部门联动、知识互补,评审方案信息准确性、完整度、合理性及可执行性。
故障处理人主要用途:被动接受告警信息,并根据自己掌握的技能,处理告警。
故障处理人员不与Gameday其他角色重合也不参与评审,目的是尽可能真实的反映业务系统的健壮性、运维/开发的故障处理水平,以便发现系统真实的弱点。
信息表可参考下文:
角色 | 人员 | 职责 |
|---|---|---|
负责人(Owners) | 决定了计划、时间表以及是否停止实验 | |
协调员(Coordinators) | 协调其他参与角色,并执行对应用程序中发起攻击 | |
报告者(Reporters) | 负责记录实验的关键异常、填写执行记录表、关键结果记录并输出报告 | |
观察者(Observers) | 从可观测性基础设施收集数据,并将主要观察结果告知其他参与者,并验证结果。 | |
故障处理(Others) | 感知系统问题、按故障处理流程定位恢复故障。 |
备注:由于方案论证可能持续多次,这里也可以考虑根据实际情况进行再次实验评审
制定执行计划
执行计划主要包括三个部分:前置准备工作、实验执行、收尾工作。主要是让整个实验过程更有
1、前置准备工作。完成实验过程中用到的必要脚本、预先配置调研等工作。参考下表:
项目 | 工作内容 | 进度 | 备注 |
|---|---|---|---|
XXX | XXXX | 完成 |
2、实验执行。根据实验设计表,详细记录实验过程中的实际情况。参考下表:
场景 | 对应故障模式 | 操作人 | 时间点(观察者记录) | 操作 |
|---|---|---|---|---|
3、收尾工作。实验结束后的操作,包括特殊配置清楚、数据修复等。参考下表:
工作内容 | 进度 | 备注 |
|---|---|---|
防火墙取消阻止智行访问SSP-CLB10.XX.XX.XX策略 | 完成 |
3.4.2 实验计划公告
从上面梳理的系统对象、实验目标、实验对象、干系人等信息,协商执行时间等,输出实验的计划,说明在什么时间会做什么样的事情。
此步是可选的,根据实际实验规模、实验环境而定,可以考虑将计划在公司内同步,将影响提前周知、潜在有更多人评审的目的。
3.4.3 GameDay执行
GameDay执行,相对清晰。需关注的是:
- 非故障处理角色,集中办公。可以是在同一个会议室,也可以是在线会议。
- 实验方案不要按顺序执行,可采用随机挑选的模式执行。目的是担心有故障处理人员通过意外渠道获取详情执行计划,导致学到的运维/开发系统故障处理能力失真的情况发生。
3.5 复盘提升
混沌工程要在一家公司成功,主要有几个要素:
- 低成本:开始实验,是小部分人带动,大部分人不熟悉,中间有很多低效、冗余工作。从长期来看,最好能针对公司内尽可能多的系统、尽可能多的场景,进行不定期、自动化、无人值守的盲演。
- 高价值:通过实验,确实能发现团队、流程等高价值缺陷,并能够量化成对系统核心指标的贡献。
- 认同和文化:公司不同角色会不会自发在软件生命周期的不同阶段采用混沌工程。
- 成熟度标准:评估混沌工程是否合适的基线,牵引不同团队混沌工程水平。
所以我们在一次实验结束后,可以从上面角度分析,本次实验哪些地方可以优化,发现的哪些知识可以转化成系统能力,如何评价本次实验活动以及如何让更多人任何。
这里推荐采用定期实验报告的形式,将发现的知识进行晾晒。
认同和文化方面,可以考虑采用Kirkpatrick模型
成熟度度量可以参考greemlin的可靠性评分
4.某新能源汽车云防火墙混沌工程实战
4.1 目标系统分析
客户业务主要分布在XX、 YY两个地域,其中:XX地域主要业务是客户智行APP、智慧服务平台(SSP),客户智行APP可从各大应用商店下载,给车主提供各种APP常见功能,SSP平台给各车主提供配件,售后,充电桩等车辆周边服务;YY地域是车联网业务,主要承载车辆远程启停、车机控制、日志、订阅等服务。两个地域通过云联网打通;两地环境规划、部署架构、运维系统、开发环境基本一致。
一个业务系统故障源,大概来自两方面:组成架构的组件(硬件故障、负载异常、丢包等)发生故障以及对组件的管理动作造成故障。下面分析这两部分的能力现状。
4.1.1 业务架构图与主链路
YY地域车联网业务系统,整体架构图如下:

车联网是经典的互联网业务三层模型,主要的业务链路有:
链路名称 | 经过组件 | 涉及服务列表 |
|---|---|---|
1、汽车车机请求链路 | WAF/CLB/互联网墙/VPC墙/TKE/VPC墙 | 车机车控、启停日志、订阅服务、电池管理、空调门窗等服务 |
2、车联网内部微服务间调用联路 | TKE/VPC子网墙 | —— |
3、车联网内部微服务调用外部第三方服务/合作伙伴通过NAT暴露的内部服务地址访问联路 | TKE/NAT墙 | 喜泊车:https://b2c.xx.com.cn |
4、XX地域智行服务通过云联网调用YY地域车联网服务 | XX地域TKE/云联网/VPC墙/YY地域TKE | XX地域智慧服务平台(ssp)、YY地域订阅服务 |
4.1.2 业务流程与控制结构
目前防火墙规则,都是人工通过控制台增减。
操作面:人工
控制面:官网控制台
数据面:云防产品

4.1.3 系统当前高可用能力汇总
整体具备可用区级及组件级容灾能力,从部署架构上来看,整体SLA是可以达到99.95%。需要关注的是高可用措施按预期执行、配置管理错误以及级联故障。
架构层级 | 组件 | 能力项 |
|---|---|---|
接入层 | WAF | 旁路WAF,WAF故障时对业务无损严格变更流程:测试环境验证,生产变更后值守 |
CLB | 腾讯云的跨区高可用能力 | |
业务逻辑层 | TKE | node节点平均分布在YY地域一区/二区istio gateway反亲和性,保证一区/二区数量平均且每个pod在一个node节点 |
数据层 | CDB/CRS | 腾讯云PaaS产品跨可用区高可用能力 |
云防火墙 | 互联网墙 | 配置层面:极少规则,且变更频率极低云产品层面:旁路功能,故障对业务无损 |
VPC墙 | 配置层面:1、明确VPC墙仅控制VPC内流量;2、变更顺序为小段、子网、VPC;3、生产变更后值守云产品层面:1、跨区高可用产品;2、一键Bypaas产品能力 | |
NAT墙 | 配置层面:1、明确NAT墙仅控制进出公网流量;2、生产变更后值守云产品层面:1、跨区高可用产品;2、一键Bypaas产品能力 | |
企业安全组 | 配置层面:1、明确企业安全组应用场景为重要实例的独立控制;2、生产变更后值守云产品层面:管理系统故障,对已有安全组无影响 |
4.2 探查系统弱点
4.2.1 FMEA分析
通过FMEA(Failure Mode & Effect Analysis)分析法,针对业务的主要四条调用链(横向)涉及的组件自身发生异常时,业务的故障模式、原因进行全面分析,并针对风险程度进行排名,用以确认哪些异常需要优先重点关注:

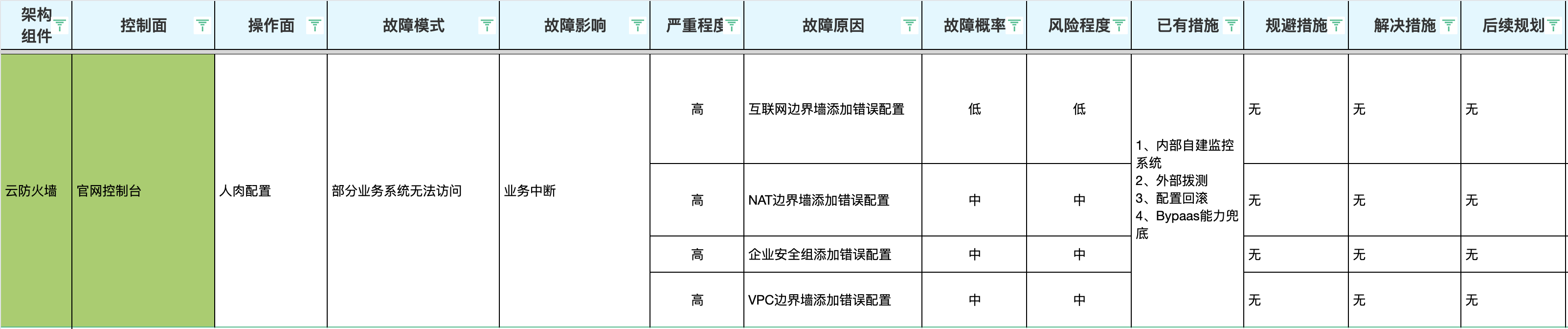
4.2.2 STPA分析
通过STPA(Systems Theoretic Process Analysis)分析法,针对业务的主要四条调用链(纵向)涉及的组件,在发生非预期变更时,业务的故障模式、原因进行全面分析,并针对风险排名,用以确认哪些变更异常需要优先重点关注:
4.2.3 组件SLA/SLI分析
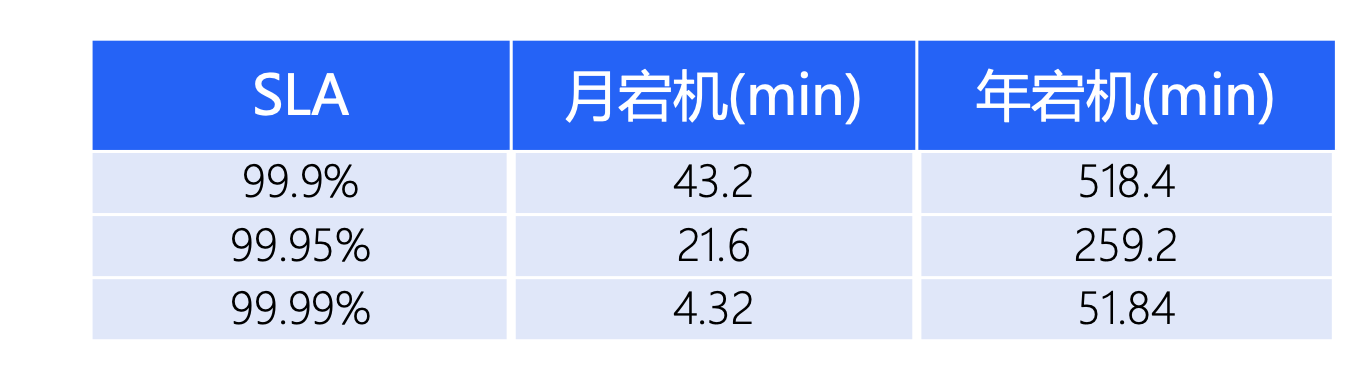
从上面FMEA/STPA分析可以看出,当前云防故障场景考核的核心指标有两个:该组件的故障恢复时长和SLI-延迟。其中延迟SLI的业务指标是1s
故障预算,参考历史故障频率、管理措施(变更、容量管理策略)、高可用能力、自愈程度等维度,输出如下故障预算表:
最终云防故障的整体故障预算为月度5min

4.3 设计混沌实验
4.3.1 实验目标
- 验证当云防故障发生时,客户业务系统可兼容、不崩溃,且对用户有恰当引导
- 验证客户运维可通过恰当的方式在5min内恢复云防故障
- 验证兜底措施Bypaas功能是否按预期work
恰当恢复方式定义:

备注:Bypaas是腾讯云的产品能力,开启Bypaas意味着访问联路将绕行该防火墙,该墙的所有规则失效。
云防产品总共有三个墙:VPC墙、NAT墙、互联网墙。在客户整站故障时,精准定位到具体的错误并解决的处理能力,显然优于Bypaas某个防火墙;Bypaas某个防火墙即可解决的处理能力,显然优于Bypaas所有防火墙。
4.3.2 实验设计

以上2、4、5、16的故障注入方法、注入点一样;3、18的故障注入方法、注入点一样;合并的主要原因:2、3、4、5涉及组件级故障,需通过腾讯云底层模拟,爆炸半径过大,不利于发现客户业务能力、运维能力缺陷。
仅选择四个业务链路注入故障,是因为这四条链路可以代表客户整体的形态。
随着后面实验方法、模式、可观测性及小规模实验暴露出来的问题,客户侧都熟悉且改善后,可考虑提高实验覆盖的业务场景、组件、爆炸半径
此处隐藏了低优先级的实验项
4.3.3 最终设计方案
场景 | 对应故障模式 | 时间点 | 操作 |
|---|---|---|---|
1,智行通过内网调用内部预约维保服务故障(XX地域本地VPC间):源服务——智行后端服务 --> 目标接口 XX.xx.cn (10.XX.XX) | 3、18 | 防火墙内网间阻止智行访问SSP-CLB10.XX.XX | |
接收业务故障通知 | |||
等待告警通知 | |||
防火墙关闭vpc-XX(VPC-DEV&xxxxx)->vpc-qdiXX(VPC- XX)【VPC10.XX.XX->10.XX.XX】—— 智行uat至DevOps-pp两个VPC间Bypass | |||
通知业务观察故障是否恢复 | |||
业务恢复,确定影响面【】 | |||
2,智行通过内网调用TSP故障(XX地域到YY地域VPC间): 源服务——智行后端服务 --> 目标接口 https://xx.xx.com (10.XX.XX) | 8 | 通过混沌平台对xx.xx.com(10.XX.XX)注入2s延迟响应 | |
接收业务故障通知 | |||
等待告警通知 | |||
去除接口延迟注入——14:11分定位到问题 | |||
通知业务观察故障是否恢复 | |||
业务恢复,确定影响面【】 | |||
3,智行通过公网调用喜泊车故障(NAT边界) :源服务——智行后端服务 --> 目标接口 https://xx.com.cn | 2、4、5、16 | NAT出口限制对https://b2c.xx.com.cn(10.XX.XX)的访问 | |
接收业务故障通知 | |||
等待告警通知 | |||
防火墙实例cfwnat-xx NAT出口开启Bypass | |||
通知业务观察故障是否恢复 | |||
业务恢复,确定影响面【】 | |||
4、智行调用后端数据库被拒绝 | 17 | 防火墙企业安全组阻止10.XX.XX访问后端数据库10.XX.XX:3306 | |
接收业务故障通知 | |||
等待告警通知 | |||
去除“防火墙阻止10.XX.XX访问后端数据库10.XX.XX” | |||
通知业务观察故障是否恢复 | |||
业务恢复,确定影响面【】 | |||
5、还原所有操作 | 防火墙取消阻止智行访问SSP-CLB10.XX.XX策略 | ||
防火墙关闭vpc-xx(VPC-xx)->vpc-xx(VPC-xx) | |||
防火墙实例cfwnat-xx NAT出口关闭Bypass | |||
NAT出口开发对https://b2c.xx.com.cn的访问,删除智行访问115.10.XX.XX策略 |
4.4 Gameday
4.4.1 Gameday设计
角色 | 人员 | 职责 |
|---|---|---|
负责人(Owners) | 吴XX、周XX | 决定了计划、时间表以及是否停止实验 |
协调员(Coordinators) | 吴XX | 协调其他参与角色,并执行对应用程序中发起攻击 |
报告者(Reporters) | 吴XX | 负责记录实验的关键异常、填写执行记录表、关键结果记录并输出报告 |
观察者(Observers) | 李XX、蒋XX、逯XX | 从可观测性基础设施收集数据,并将主要观察结果告知其他参与者,并验证结果。 |
故障处理(Others) | 测试人员、业务开发、运维 | 感知系统问题、按故障处理流程定位恢复故障。 |
备注:故障处理人员不在Gameday关键角色也不参与评审,目的是尽可能真实的反映业务系统的健壮性、运维/开发的故障处理水平。
客户场景做法:
- 故障处理人员需单独留出时间参与gamenday
- 仅被通知gameday时间段,混沌实验用例的执行顺序、注入目标、注入方法不会同步给他们
- 如果注入故障后,系统的故障时间超过预定的故障预算,则由协调员直接执行终止实验的能力,以保证业务稳定性
4.4.2 执行计划
执行前准备、执行计划、收尾工作有较多的客户侧信息且与执行部分信息重叠,此处略。参考生命周期中的模版
4.4.3 Gameday执行
下面是执行过程中,关于执行计划的执行记录。

4.5 实验总结
4.5.1 实验价值
发现6项客户侧改进事项;2项云产品改进事项;2条GameDay经验总结。
业务系统表现
符合预期
- 核心链路(如访问cdb)的业务兼容性仍需加强,本次给cdb注入故障,发现智行APP业务整体受损符合预期,但用户体感强烈。
- 在云防故障场景下,大部分业务场景,业务侧均没有扩大化,仅是当前能力不可用,且对用户有较好的提示。
- 建议业务在出错默认页面、友好提示方面增加投入
- 业务监控方面,监控粒度不够细,导致故障定位仍需人工排查时间。
运维处理能力
不符合预期
- 部分时效不达标。
- 故障处理没有流程化、标准化,仍依靠个人能力处理,导致故障时长不稳定。
云防火墙Bypass能力
不符合预期
- VPC墙Bypaas后路由错乱,导致idc到云联网路由环路
- NAT墙Bypaas后,长链接业务有2min+时间不可用
4.5.2 问题及经验总结
问题总结 | |||||||
|---|---|---|---|---|---|---|---|
组件模块 | 序号 | 问题 | 解决方案 | 负责人 | 解决时间 | ||
业务监控 | 1 | 告警信息看不到直观告警,如喜泊车接口的访问次数、数据库不可访问信息 | 按照Google sre提出的四个黄金指标的思路,来建设业务监控告警信息里面带上关联的资源层监控信息 | 吴XX | |||
业务熟悉度 | 2 | 运维故障处理人员,不熟悉业务服务调用数据库信息,导致故障处理在信息查找方面耗时严重 | 建设配置中心可视化工具,辅助快速查找 | 吴XX | |||
告警处理流程 | 3 | 没有告警处理流程,告警处理人员未能快速定位到哪个环节出问题 | 构建变更回滚/子网放通/vpc放通/bypaas的处理能力模型每个环节流转有明确的条件 | 吴XX | |||
防火墙管理规范 | 4 | 故障处理人员对防火墙的四个墙应用场景不熟悉,导致故障定位方向偏离拉长了故障处理时间 | 规划清楚四个墙的适用范围规整当前规则,避免有重叠 | 吴XX | |||
实验人员设置 | 5 | 故障处理人员,也能知道实验进度信息,导致故障处理能力失真 | 故障处理人员,不参与gameday制定 | 吴XX | |||
环境隔离性 | 6 | 目前存在单云防实例故障影响所有环境的情况 | 每个环境除了资源数量外都做组件对等部署 | 吴XX | |||
云防Bypaas能力 | 7 | NAT墙开启bypaas后,2min+时间,公网访问全部失败 | 产研跟进中 | XXX | |||
云防VPC墙开关 | 8 | 关闭、开启VPC间防火墙后,发现路由错乱,导致客户IDC环境访问云环境不同 | 产品bug已修复 | XXX | |||
经验总结 | |||||||
组件模块 | 序号 | 经验 | 适用场景 | 分享人 | 说明 | ||
Gameday人员设置 | 1 | 故障处理人员,尽可能和Gameday其他人在方案评审、信息同步方面隔离,且不是同一波人 | 业务/运维能力验证 | XXX | 避免故障处理人了解gameday细节,导致学习到的故障处理能力失真 | ||
实验执行顺序 | 2 | 实验用例的执行顺序,应该尽量随机 | 全场景 | XXX | 尽可能避免故障处理人员因提前获取实验方案,导致学习到的故障处理能力失真 | ||
5.小结
本文主要介绍和客户共建混沌工程的阶段,如何界定待实验系统、提炼业务指标、设计混沌实验、Gameday及实验总结的重点内容。
需要注意的是,本文推荐先通过FMEA/STPA方法论全面弱点探查,再开展混沌实验。
这样做,一方面可以通过混沌工程解决系统紧要问题,体现混沌工程价值;另一方面也通过具体的实战提升客户侧的混沌工程能力。
等这些能力具备后,可以考虑引入更多系统、更多场景,提升客户公司内对混沌工程的认同,构建混沌工程文化。
最后再考虑建设混沌工程标准化、混沌成熟度等,将混沌工程引入软件生命周期的更多环节。
另外,笔者能力有限,文章中的思路、方法难免有错漏,还请各位混沌工程大佬不吝赐教,共同碰撞出优秀的实践案例。
后面也会逐步针对提到的每个关键技术,做深入的分享。
6.参考资料
LDFI参考:https://people.ucsc.edu/~palvaro/molly.pdf
Kirkpatrick模型:https://kirkpatrickpartners.com/the-kirkpatrick-model/
greemlin的可靠性评分:https://www.gremlin.com/blog/how-gremlins-reliability-score-works/
云防火墙原理:云防火墙 相关概念-产品简介-文档中心-腾讯云
FMEA/STPA案例:https://d1.awsstatic.com/events/reinvent/2019/REPEAT_1_Designing_for_failure_Architecting_resilient_systems_on_AWS_ARC335-R1.pdf
腾讯云混沌平台:混沌演练平台_故障演练平台- 腾讯云