
新智元报道
编辑:LRS
【新智元导读】计算图像感知相似度,模型分类准确率还不能太高!
计算图像之间的相似度是计算机视觉中的一个开放性问题。
在图像生成火遍全球的今天,如何定义「相似度」,也是评估生成图像真实度的关键问题。
虽然当下有一些相对直接的方法来计算图像相似度,比如测量像素上的差异(如FSIM, SSIM),但这种方法获得的相似性差异和人眼感知到的差异相去深远。
深度学习兴起后,一些研究人员发现一些神经网络分类器,如AlexNet, VGG, SqueezeNet等在ImageNet上训练后得到的中间表征可以用作感知相似性的计算。
也就是说,embedding比像素更贴近人对于多张图像相似的感知。

当然,这只是一个假设。
最近Google发表了一篇论文,专门研究了ImageNet分类器是否能够更好地评估感知相似度。

论文链接:https://openreview.net/pdf?id=qrGKGZZvH0
虽然已经有工作在2018年发布的BAPPS数据集基础上,在第一代ImageNet分类器上研究了感知评分(perceptual scores),为了进一步评估准确率和感知评分的相关性,以及各种超参数的影响,论文中增加了对最新ViT模型的研究结果。
准确率越高,感知相似度越差?
众所周知,通过在ImageNet上的训练学到的特性可以很好地迁移到许多下游任务,提升下游任务的性能,这也使得在ImageNet预训练成了一个标准操作。
此外,在ImageNet上取得更高的准确率通常意味着在一组多样化的下游任务上有更好的性能,例如对破损图片的鲁棒性、对out-of-distribution数据的泛化性能和对较小分类数据集的迁移学习。
但在感知相似度计算上,一切好像反过来了。
在ImageNet上获得高精度的模型反而具有更差的感知分数,而那些成绩「中游」的模型在感知相似度任务上性能最好。

ImageNet 64 × 64验证精度(x 轴) ,64 × 64 BAPPS 数据集上的感知评分(y 轴),每个蓝点代表一个 ImageNet 分类器
可以看到,更好的 ImageNet 分类器在一定程度上实现了更好的感知评分,但超过某一阈值,提高准确性反而会降低感知评分,分类器的准确度适中(20.0-40.0) ,可以获得最佳的感知评分。
文中同时研究了神经网络超参数对感知分数的影响,如宽度、深度、训练步数、权重衰减、标签平滑和dropout
对于每个超参数,存在一个最优精度,提高精度可以改善感知评分,但这个最优值相当低,并且在超参数扫描中很早就可以达到。
除此之外,分类器精度的提高会导致更差的感知评分。
举个例子,文中给出了感知评分相对于两个超参数的变化: ResNets中的训练steps和ViTs中的宽度。
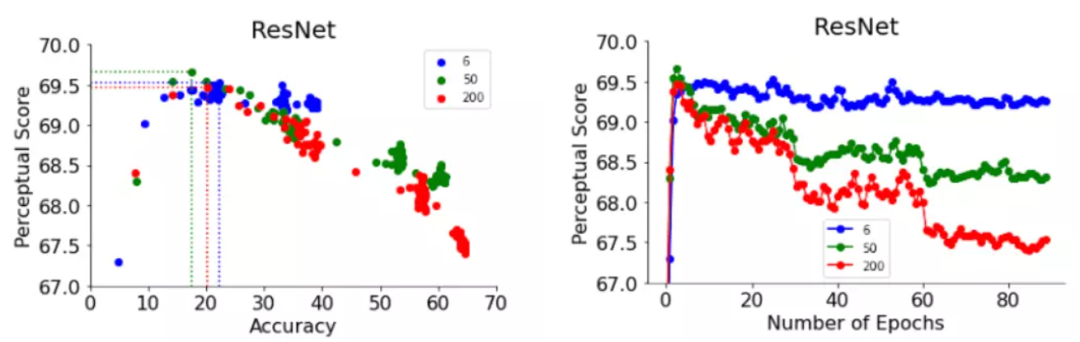
提前停止的ResNets在6, 50和200的不同深度设置下获得了最佳感知评分
ResNet-50和ResNet-200的感知评分在训练的前几个epoch达到最高值,但在峰值后,性能更好的分类器感知评分值下降更为剧烈。
结果显示,ResNets的训练与学习率调整可以随step增加提升模型的准确性。同样,在峰值之后,模型也表现出与这种逐步提高的精度相匹配的感知相似度评分逐步下降。
ViTs由应用于输入图像的一组Transformer块组成,ViT模型的宽度是单个Transformer块的输出神经元数,增加宽度可以有效提高模型的精度。
研究人员通过更换两个ViT变体的宽度,获得两个模型B/8(即Base-ViT模型,patch尺寸为4)和L/4(即Large-ViT模型) ,并评估准确性和感知评分。
结果还是与提前停止的ResNets观察结果相似,精度较低的较窄的ViT比默认宽度表现得更好。
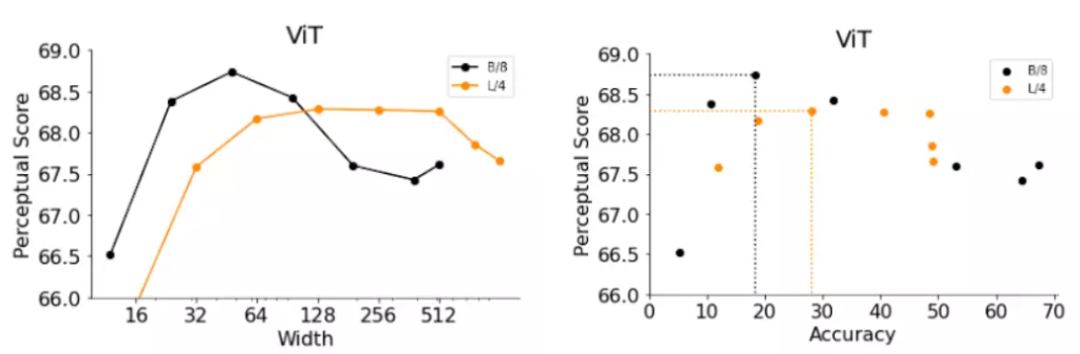
不过ViT-B/8和 ViT-L/4的最佳宽度分别是它们默认宽度的6% 和12% ,论文中还提供了对于其他超参数的更详细实验列表,如宽度、深度、训练步数、权重衰减、标签平滑和跨 ResNet 和 ViTs 的dropout。
所以想提升感知相似度,那策略就简单了,适当降低准确率即可。
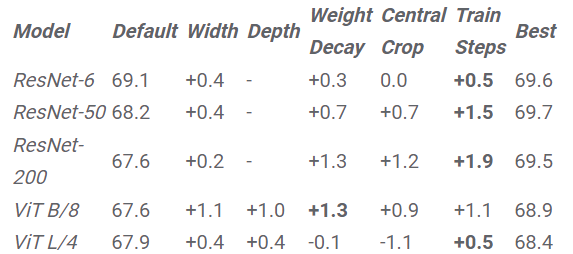
通过缩小ImageNet模型来提高感知评分,表格中的值表示通过在带有默认超参数的模型上缩放给定超参数的模型而获得的改进
根据上述结论,文中提出了一个简单的策略来改善架构的感知评分:缩小模型来降低准确性,直至达到最佳的感知得分。
在实验结果中还可以看到,通过在每个超参数上缩小每个模型所获得的感知评分改进。除了 ViT-L/4,提前停止可以在所有架构中产生最高的评分改进度,并且提前停止是最有效的策略,不需要进行费时的网格搜索。
全局感知函数
在先前的工作中,感知相似度函数使用跨图像空间维度的欧氏距离来计算。
这种方式假定了像素之间存在直接对应关系,但这种对应关系可能不适用于弯曲、平移或旋转的图像。
在这篇文章中,研究人员采用了两个依赖于图像全局表示的感知函数,即捕捉两个图像之间的风格相似性的神经风格迁移工作中的风格损失函数和归一化的平均池距离函数。
样式损失函数比较两幅图像之间的通道间cross-correlation矩阵,而平均池函数比较空间平均的全局表示。
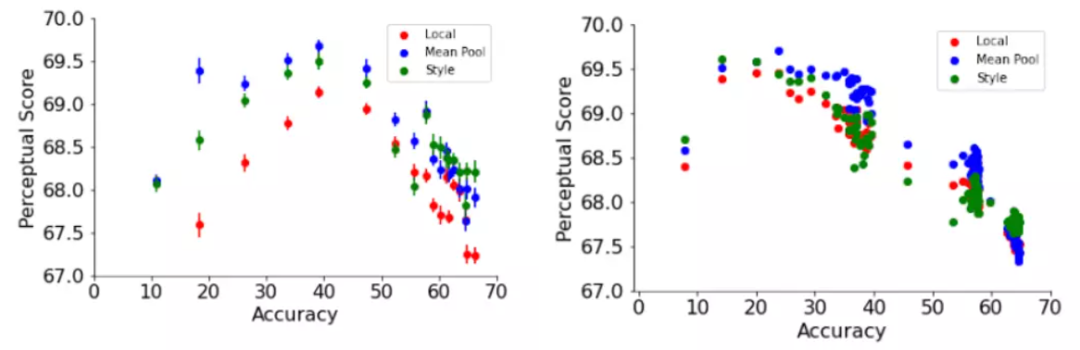
全局感知函数一致地改善了两个网络训练的默认超参数和ResNet-200作为训练epoch函数的感知评分
文中还探讨了一些假设来解释精确度和感知评分之间的关系,并得出了一些额外的见解。
例如,没有常用的skip连接的模型准确性也与感知评分成反比,与接近输入的层相比,更接近输出的层平均具有较低的感知评分。
同时还进一步探索了失真灵敏度(distortion sensitivity)、 ImageNet类别粒度和空间频率灵敏度。
总之,这篇论文探讨了提高分类精度是否会产生更好的感知度量的问题,研究了不同超参数下ResNets和ViTs上精度与感知评分之间的关系,发现感知评分与精度呈现倒U型关系,其中精度与感知评分在一定程度上相关,呈现倒U型关系。
最后,文章详细讨论了精度与感知评分之间的关系,包括skip连接、全局相似函数、失真敏感度、分层感知得分、空间频率敏感度和ImageNet类别粒度。
虽然对于ImageNet精确度和感知相似度之间的权衡现象的确切解释仍然是一个谜,但这篇论文向前迈出了第一步。
参考资料:
https://ai.googleblog.com/2022/10/do-modern-imagenet-classifiers.html