题目描述:



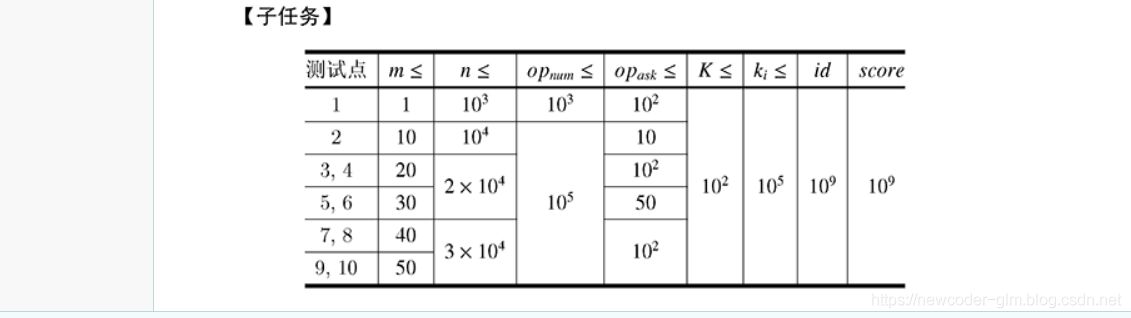
众所周知,CSP认证前两题经过一段时间的训练都不难在赛场上成功AC,而近些年来第三题(大模拟)的难度水涨船高,一年更甚一年,如果你是业余算法选手,对大模拟没有经过系统的训练,只掌握了基本的STL操作的话但是一直徘徊在200+的情况,我建议你把突破口放在第四题,事实上从历次认证的情况来看,第四题的得分率远比第三、第五高,而第四题一般是考啥呢?其实不一定,凭笔者(今年12月参加认证的话就是第三次)多次参加和刷历年真题的经验来看:无非是考字符串(KMP、AC自动机)、STL运用(set、map、vector的极高综合运用能力)、图(非常喜欢考prim和kruskal、极为钟爱floyd、dijkstra、spfa)
废话不多说,来看一下九月份的第四题,是一道STL要求能力极高的题目~
大致阅读题意后发现我们需要做的是:m类商品,每一类有n个,总的有m*n个商品;在这些商品中选出得分最大的k件商品,得出相同的先按类号从小到大排序,再按编号从小到大排序,看起来很简单,但是题目又有限制:每一类商品取的个数不得超过给出的具体数值,最后输出时同类也按分数优先、相同取编号小者的优先级,并且支持基本的增添和删除操作
1.总体思路:把输入的所有商品放入set,自定义排序优先级输出,但set存什么?存一个结构体,包含该商品是第几类第几个的信息,为方便起见,我们把它哈希唯一映射到一个大数,采用线性映射:第a类b个,hash值为a*1e10+b,逆hash过程就是a=hash/1e10,b=hash%1e10,之后自定义排序就很好写了,详见代码
2.一个很头疼的问题呼之欲出:我们怎么在set中查找到指定类第几个的节点呢?这里参考@日沉云起这位博主的做法,(用STL多年的我竟然不知道insert函数有两个返回值,惭愧惭愧)insert函数的返回值是一个pair,first成员就是指向新插入的元素在set中位置的迭代器,second成员是一个bool表示这次插入操作是否成功。这样我们创建一个map,注意这边map必须是无序的,有序一是没必要二是会超时!键为我们映射的大数,值为该大数代表的节点(包含分数和第几类第几个)在set中位置的迭代器,这样一番处理之后,插入和删除就很容易了
3.关于输出:题目中只说同类的商品按照编号从小到大的输出,但是如果在同类中只按这单一的优先级会得不到满分,所以从提交结果来看,题目的意思是同类中先按分数从小到大,同分按编号从小到大输出
ACcode
// luogu-judger-enable-o2 #include<bits/stdc++.h> #include<unordered_set> #define rg register ll #define inf 2147483647 #define min(a,b) (a<b?a:b) #define max(a,b) (a>b?a:b) #define ll long long #define maxn 1000005 #define lb(x) (x&(-x)) const double eps = 1e-6; using namespace std; inline ll read() { char ch = getchar(); ll s = 0, w = 1; while (ch < 48 || ch>57) { if (ch == '-')w = -1; ch = getchar(); } while (ch >= 48 && ch <= 57) { s = (s << 1) + (s << 3) + (ch ^ 48); ch = getchar(); } return s * w; } inline void write(ll x) { if (x < 0)putchar('-'), x = -x; if (x > 9)write(x / 10); putchar(x % 10 + 48); } struct good { ll id,val; good(ll id,ll val):id(id),val(val){} bool operator <(const good &a)const { return this->val==a.val?this->id <a.id:this->val>a.val; } }; set<good>goods; unordered_map<ll,set<good>::iterator>p; ll v[maxn]; const ll Hash=(ll)1e10; int main() { ll m=read(),n=read(); for(rg i=1;i<=n;i++) { ll id=read(),val=read(); for(rg j=0;j<m;j++) { ll val1=j*Hash+id; p[val1]=goods.insert(good(val1,val)).first; } } ll opps=read(); for(rg i=1;i<=opps;i++) { ll check=read(); if(check==1) { ll a=read(),b=read(),c=read(),m=a*Hash+b; p[m]=goods.insert(good(m,c)).first; } else if(check==2) { ll a=read(),b=read(),m=a*Hash+b; goods.erase(p[m]),p.erase(m); } else if(check==3) { ll sum=read(),cnt=0; vector<vector<ll>>ans(m); for(rg i=0;i<m;i++)v[i]=read(); for(auto it:goods) { ll lei=it.id/Hash,num=it.id%Hash; if(ans[lei].size()<v[lei]) { ans[lei].push_back(num); } cnt++; if(cnt==sum)break; } for(auto it:ans) { if(!it.empty()) { ll k=0; for(auto itt:it) { k++; k==it.size()?cout<<itt<<endl:cout<<itt<<" "; } } else cout<<-1<<endl; } }} //while(1)getchar(); return 0;
}
实话说,近几年的csp越来越难,对于那些中间分数段的同学,我建议突破口还是要放在第四第五题,要加强这方面的训练。因为大模拟题需要极为漫长的时间锻炼,这其实是一种读题的能力训练和对思维连贯性的极大考验,短期之内是很不容易练成的