本文首先介绍了大数据架构平台的组件架构,让读者了解大数据平台的全貌,然后分别介绍数据集成、存储与计算、分布式调度、查询分析等方面的观点,最后是专家眼里大数据平台架构的发展趋势。
01
大数据平台架构
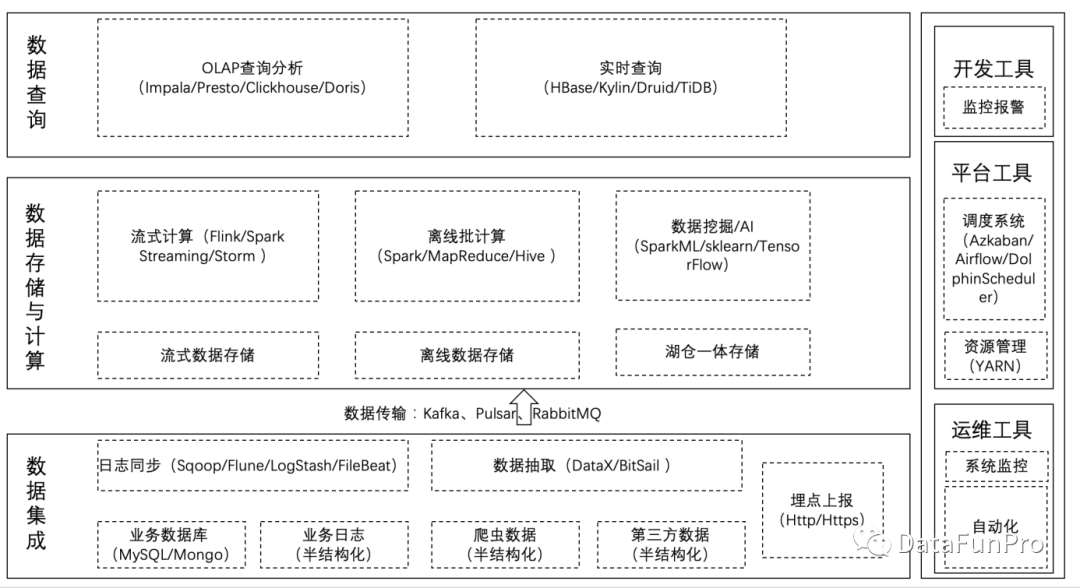
从图上可以看出,大数据架构平台分为:数据集成、存储与计算、分布式调度、查询分析等核心模块。我们就沿着这个架构图,来剖析大数据平台的核心技术。
02
数据集成

专家观点:
数据集成非常重要,因为跟业务方相关的第一个环节就是数据集成,数据集成如果出现问题比如速度慢、丢数据等,都会影响到业务方数据的使用,也会影响业务方对大数据平台的信任度。
3. 数据传输队列
数据传输有三种:
- Kafka:流式传输
- RabbitMQ:队列传输
- Pulsar:流式传输+队列传输
专家观点:
Kafka是Hadoop组件全家桶,名气更大,但是易用性还是差一点。 Pulsar 跟Kafka很像,不过架构比Kafka更先进,属于后起之秀。
更多:数据集成的 9大 ETL工具
03
数据处理:数据存储、计算

专家观点:
● Spark+数据湖是未来的发展方向。
● 离线的场景很丰富,但是缺乏处理的非常好的统一的计算引擎,hive和spark都无法做到,所以这一块未来还有很大的发挥空间。
(2)实时计算引擎优缺点及适用场景
实时计算引擎大体经过了三代,依次是:storm、spark streaming、Flink。其中storm和spark streaming现在用的很少,大部分公司都在用Flink。
专家观点:
● Flink的优点是:可以实时的进行计算,在处理流计算这个方向上是最好的组件,而且几乎可以替代近实时的业务场景。
● 缺点是对离线处理会略显不足,不太适合处理大批量的离线数据集。
● Flink的优化方向很多:
a. Flink在流处理稳定性上,虽然已经做到极细粒度,但是遇到阻塞时,会存在丢失数据的问题。需要加强稳定性。
b. 实时性的提升:实时的优化是无底洞,业务需求能到秒级别、毫秒级别,怎么能让Flink在业务场景用的好,提升速度的同时,保持数据一致性,是Flink面临的挑战。
04
数据调度

05
大数据查询
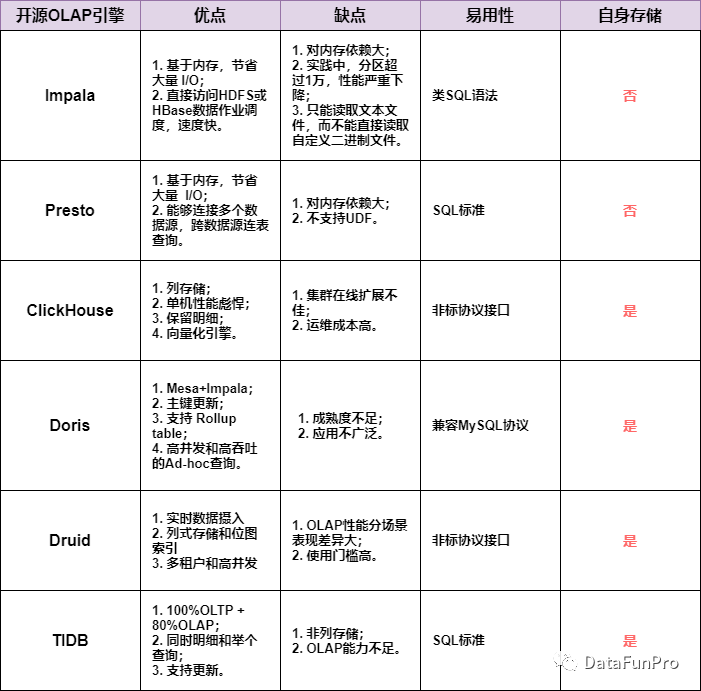
1. 大数据查询引擎
常用的OLAP引擎对比:

2. 大数据查询优化工具
大数据查询优化工具包括 Alluxio、JuiceFS 和 JindoFS。
专家观点:
Alluxio:
数据编排最为强大,市面上常见的存储系统、云存储服务均可以直接接入,也可以自行实现相关 api 以接入其他自研存储系统,可以说 Alluxio 最为通用,既可用于云存储服务的缓存接入或数据编排,也可作为传统 HDFS 的多集群数据编排。
JuiceFS:
● 提供了和 Alluxio 非常相似的功能,如元数据与数据分离的存储、数据编排、与 Hadoop API 兼容、Fuse 等特性;
● JuiceFS 也有不错的数据编排特性,元数据存储的方式比 Alluxio 更多元,主要用于云存储场景。
JindoFS:
● 局限于阿里云 oss 场景的分布式存储系统;
● 支持与 Alluxio 非常相似的功能,也能提供内存级的缓存加速;
● 但场景局限于 oss 内。
06
大数据平台架构的发展趋势
最后,我们请专家们聊了一下大数据平台架构的发展趋势,专家们发表了以下看法:
1. Olap 场景是大数据平台架构整体的重点,未来的发展趋势如下:
- 如何算得更快;
- 如何存得弹性:如何做的像单机数据库,可以快速的线性扩展;
- Olap 基于云原生的架构体系,基础系统构建 ok,无限弹性。计算资源也无限弹性。
2. 对象存储
过去 3 年,很多用户纷纷选用对象存储系统保存数据,不仅是因为其自身的价格优势,还可以减少维护的麻烦。对象存储适用的场景非常多,包括:存算分离、数据分层、多数据源分类以及应用于数据湖等等。
3. 云原生
我们知道,云原生具有很好的弹性、可拓展能力,在未来必定会越来越受到重视。结合当下发展,仍然存在一些待解决的问题:
- 云原生要考虑到分布式技术、编排、上云方式等,稳定性和上云集成是目前的挑战。目前云上不是特别稳定,需要继续观察。
- 高性能的硬件设施,例如高性能 CPU 以及超大规模的内存的结合。
- 基础架构改造提升。
4. 实时计算
实时计算仍然处于发展期,即便对于 Flink,也存在一定的提升空间。
专家介绍:
1. 张耀东:小米高级研发工程师,先前就职于百度、武汉安天从事后端和移动安全大数据平台相关研发,目前在小米大数据中台部门负责 OLAP 服务研发工作。
2. 祝江华:网易资深大数据工程师,现网易大数据平台离线存储组,目前主要针对 Hadoop&HDFS 集群的开发,优化及改进落地工作。有多年大数据开发,大数据平台研发经验,目前专注于分布式存储与计算工作。
3. 范禹辰:网易高级服务端开发工程师,2020 年加入网易工作至今,主要负责分布式数据编排系统 Alluxio 和分布式查询引擎 Impala 的开发工作