我们做政企客户的解决方案支撑工作,一直在跟客户提到“大数据”,通过大数据就能将数据转化成推动精准营销、精准管理的利器。但实际,我们对大数据的理解有多少,今天我们用几张图帮助建立对大数据的技术理解。
一、我们对大数据的误解
在接触大数据之前,我们会简单将系统运行过程中产生的数据,经过分析后呈现出来,称为大数据。但以前,我一直在想这与Mysql、甚至一个简单的Excel存储数据后,再将查询数据吐出来,有什么区别?
二、大数据与传统数据分析的区别
1、数据量大:大数据量级一般会上到PB级别,而一般数据分析在GB、TB级别。
2、数据种类多:大数据一般涉及表格、图像等,而传统数据分析一般是规则的表格化数据。
3、数据增长快:像FaceBook一天就像增长500TB数据量,而传统数据分析基于表格数据,数据量每天增长在MB级别。
4、数据价值低:正是因为有视频图像有很多大量数据,真正有用的数据需要分析后才能知道,单位数据的价值量较低。
三、大数据技术架构与传统数据分析的架构有很大区别
我们做解决方案,有业务出身的人会强调大数据对客户的价值,比如分析某时段加油站岛的利用率分布情况,用于优化加油站岛的布局。但对后台的大数据的架构比较吃力。今天我们用几张的形象图形来展示大数据技术架构。
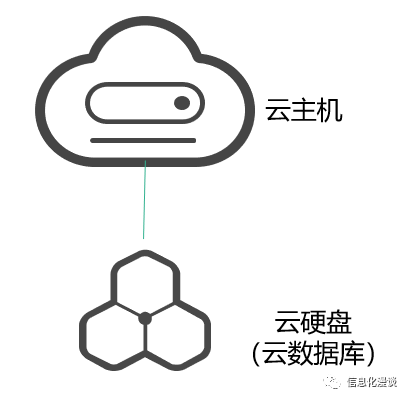
1、传统数据分析基于单机的存储或计算,性能存在瓶颈。
传统的数据量因为不大,而且主要基于表格等关系型数据,一般用一个性能较好的云主机+容量较大的硬盘或云关系型数据库能解决。
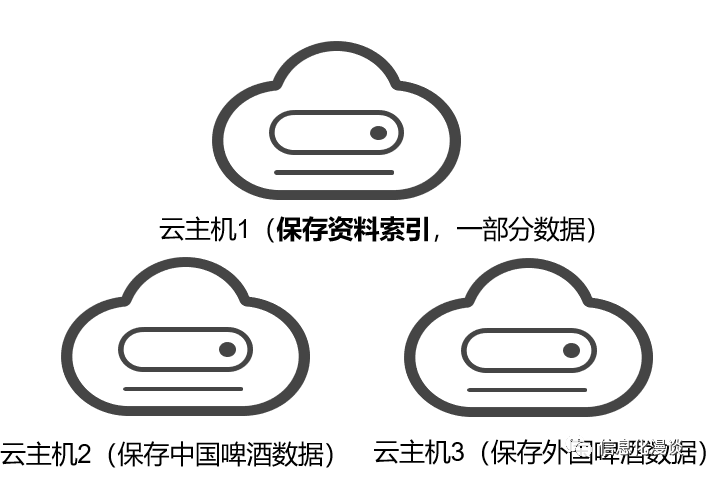
2、随着数据量的增长,总会面临存储的瓶颈,实现分布式存储。
硬盘的容量总有上限、计算机的处理能力也有上限,面临这样的问题,大数据提出将数据保存至不同的服务器中,实现横向扩展。
如下图,云主机2保存“中国啤酒”库存的资料,而云主机3只保存”外国啤酒“库存的资料,而云主机1保存以下资料的索引,这样数据量可以灵活的扩容。
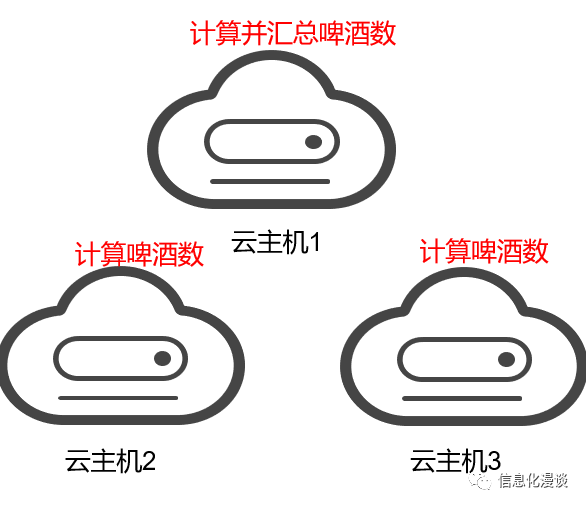
3、在分布式存储的基础上,实现分布式计算,加快大型数据量的计算结果。
如果这时候我们统计各库存的啤酒数量,传统方式是依靠单机的性能,而大数据的方式是实现在存储数据的服务器上进行分布式计算,最后汇总即可。
此方式,对大数据量的计算,采用此方式很快,相当把一个大活分给了许多人同时干。但对于一些小型数据量的实时计算业务,该方式不适用,应采用另一种架构模型(实时计算)。
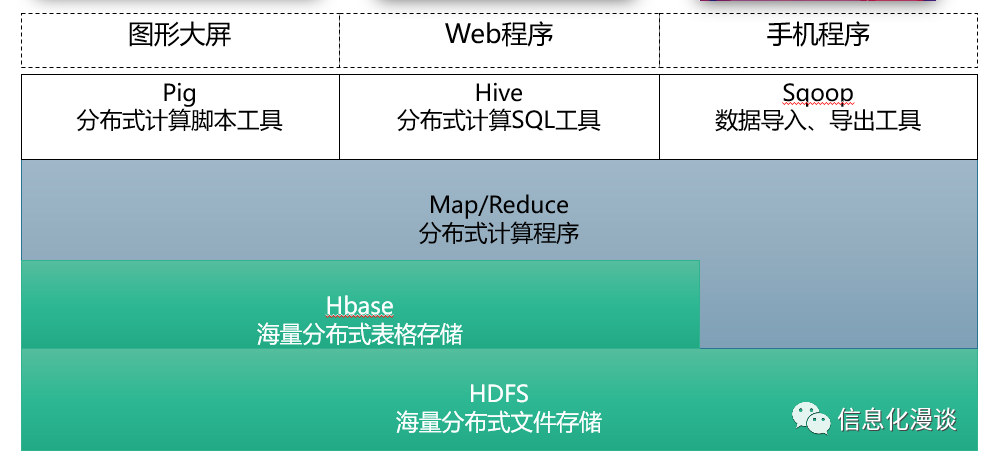
4、在云上,服务商提供了很多基于hadoop的paas软件,客户不用在云主机自行搭建大数据底层软件了。
搭建hadoop的底层环境也不是一个容易的事情,开源软件不同的版本存在兼容性问题,而且不同的应用场景也需要对hadoop进行针对性调优。
在今天的快时代,如果业务应用场景没有太大的个性化,建议尽量采用云服务商的hadoop套件。