今天跟大家分享的是2020年2月发表在NATURE BIOTECHNOLOGY(IF:36.558)杂志上的一篇文章"Butler enables rapid cloud-based analysis of thousands of human genomes".在文章中作者对基于云的大数据分析计算工具——Butler,作了大致的介绍,以及将其与现有工具PCAWG core pipeline进行了性能对比,彰显其节省时间和控制执行上的优越能力。
Butler enables rapid cloud-based analysis of thousands of human genomes
Butler:能够对数千个人类基因组进行快速云端分析
(分享者:科研菌-碎碎冰Chan)
一.研究背景
Butler,研究人员新开发的计算工具,可促进对公共云和学术云进行大规模基因组分析。Butler包含创新的异常检测和自我修复功能,与当前方法相比,该方法将数据处理和分析的效率提高了43%。Butler支持以全时高效且统一的方式处理全基因组泛癌分析(PCAWG)项目中的725 TB癌症基因组数据集。
二.分析流程

三.结果解读
1.Butler的框架结构
云计算可以轻松而经济地访问计算能力,来越多的生物数据集已经在各种云计算平台上进行了分析,借助公共云,私有云和混合云进行分析。
不过现有的基于云的Nextflow ,Toil 和GenomeVIP 之类的工具,主要集中在单个商业云计算环境,而对其他主要提供商却缺乏完整的功能。
相反,Butler对基于openstack(开源的云计算管理平台项目)的商业和学术云、Amazon Web服务、Microsoft Azure和谷歌计算平台提供全面支持,并因此能够开展国际合作,在不同的司法管辖区开展基于云计算的分布式计算。
与现有的工具相比,Butler提供了一个运营管理工具,可以快速发现并解决预期的和意外的故障(图1a,b)。

图1.Butler的框架结构
Butler的图形仪表板能及时向用户报告系统运行状况,同时支持高级查询功能以进行深入的故障排除。通过系统的日志收集和提取,来促进应用程序级别的监视(图S1)。
状态监视仪表板可以从数据库服务器上收集的日志确定SQL数据库的运行状况。图S1里的度量是在软件运行的2小时内收集的,用作可视化功能的示例。
- (a)查看响应时间;
- (b)查询按PgSQL(数据库系统)类型进行的计数;
- (c)查看数据库读写计数;
- (d)查看数据吞吐量。

图S1.SQL数据库状态监视仪表板
2.Butler与PCAWG核心管道的比较
接下来研究者们为了评估Butler在基因组分析领域的表现,将Butler与PCAWG联盟所采用的核心工作管道在全基因组泛癌分析(PCAWG)中的表现作深入的对比。
研究者们通过Butler对725 TB的原始PCAWG数据进行了多次大规模数据分析,对以下内容进行探究:
- 在正常基因组中挖掘种系单核苷酸变体(SNV)和small indels;
- 在1000 Genomes Project中,以次等位基因频率(MAF)> 1%发生的常见SNV的基因分型;
- 肿瘤和正常基因组中种系SNV和small indels的基因分型;
- 肿瘤和正常基因组中结构变体缺失的发现和基因分型(图S2);
- 肿瘤和正常基因组中结构变异重复的发现和基因分型(图S2)。

图S2.对PCAWG基因分型过程中,Butler计算群集性能指标
PCAWG核心管道集由五个管道(BWA,Sanger,Broad,DKFZ / EMBL和OxoG)组成,在PCAWG中的所有样本上运行了18个月;
而Butler的管道集由FreeBayes和Delly这两个管道组成。
接下来研究者基于为给定硬件分配的流程建立一个“最优”的进度率,来对管道性能进行评估。
首先根据完成时间将样本集分成20个bin(每个bin占所有样本的5%)。定义每个管道的最优进展率为处理一个bin的所有样本所需的时间占总分析时间的最小比例(比例缩放到1%),算法如下:
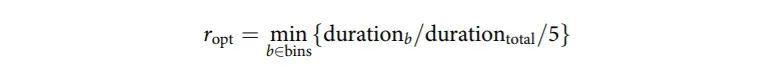
作者在分析结果中观察到,Butler流程的平均ropt值(0.46)高于核心PCAWG流程的ropt值(0.13)。
接着对于每条管道和每1%的分析样本,计算指标e(指标e定义为实际实现的ropt的比例,指示有效性),来对比核心PCAWG和Butler流程的有效性(图2a-c)。算法如下:
结果显示PCAWG流程的平均有效性较低(0.49),而Butler流程的平均有效性较高(0.70)。
紧接着对两者的预计持续时间作分析,算法如下:
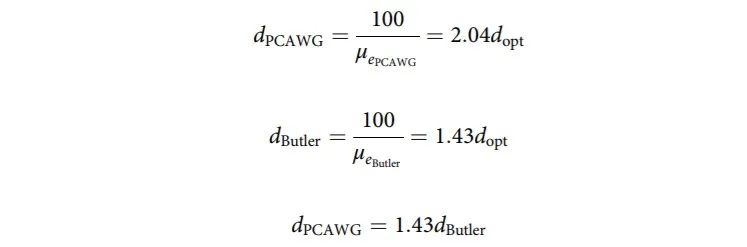
分析发现PCAWG流程的预计持续时间要比Butler长43%。
图2a-b:分别计算了实际处理速度与目标处理速度的比率(图a:PCAWG core Pipeline,图b:Butler);
图2c:将两者进行比较:比起PCAWG核心管道(平均实际/目标比率0.490),Butler实际处理速率显著高于前者(平均实际/目标比率0.696);
图2e:不过,PCAWG核心管道显示出高度不均匀的处理速率,与理想的均匀处理轨迹相比,平均偏离了23.1%(最小为0.0%,最大为57.8%,s.d.为15.0%)。
图2f:而基于Butler的管道以更均匀的方式执行,与同一样本集相比平均相差仅4.0%(最小0.0%,最大15.6%,s.d.为3.7%)。

图2:Butler性能评估
总的来说,Butler有助于克服影响分析持续时间的关键挑战——及时自主检测、并诊断和解决问题的能力。从而使得研究人员能减少花在错误操作上的时间,大大减少分析时间和成本。不仅如此,其在节省时间和控制执行上有更优越能力,与PCAWG的核心管道相比不仅预计持续时间更短,进度均匀性也更稳定。
Butler可以应用于任何大规模分析,并且可以很容易地扩展到诸如GTEx,ENCODE。标准的Butler工作流通常跨经数千个VM(虚拟机)并行执行R脚本,这也有助于Butler在其他研究环境和其他数据类型。例如,包括单细胞组学、微生物组学数据中的使用。Butler毫无疑问是用于现代全球基于云的大数据分析的高效和可伸缩的解决方案。
点击「阅读原文」,即可获取今天小编为大家解读的文献。本期的分享就到这里啦,一起期待下一期的精彩分享吧~