
论文链接:https://crgjournals.com/robotics-and-mechanical-engineering/articles/pallet-localization-techniques-of-forklift-robot-a-review-of-recent-progress
摘要
托盘广泛应用在仓库和零售店中,对于叉车机器人和托盘拣选设备,托盘的自动定位和识别技术对于非常值得研究。由于托盘类型在实际场景中变化很大,因此很难研发单一的解决方案来检测所有类型的托盘。
本文概述了工业叉车机器人和托盘拣选设备上的托盘识别和定位技术。回顾和比较了一些现代计算机视觉技术。特别的,深度神经网络(DNN)通常用于RGB图像中托盘的检测和定位;点云方法用于标记二维范围数据中的感兴趣区域(ROI),并提取托盘的特征,该方法能够提供托盘的精确定位。此外,还介绍了托盘识别和定位算法(PILA)模型,该方法可以在没有任何人工辅助的情况下提供高精度的托盘方位角和中心位置,利用RGB图像和点云数据,配合低成本的硬件来平衡定位精度和运行时间。
实验结果表明,托盘在3m距离处的3D定位精度为1cm,角度分辨率为0.4度,运行时间小于700ms。PILA 是一种有效的解决方案,可用于自动托盘拣选设备和叉车自主导航应用。
简介
近十年来,无人工业自动化技术引起了足够的关注,尤其是在物流行业应用中。随着 COVID-19 大流行并继续在世界范围内蔓延,通过无人驾驶叉车机器人和 AGV 来拣选托盘变得更加需要 [1]。托盘检测和定位的主要挑战是:
1、托盘中心的x、y、z值和方位角。
2、“实时”操作要求,保证托盘拣选。
3、托盘类型和尺寸在实际应用中可能会有很大差异,而典型的基于模型的托盘定位方法并不能正确处理所有情况。
托盘检测和定位问题从 80 年代就开始研究。在早期阶段,红外传感器或RFID用于提供托盘的距离,但只能在叉车上实现点对点测量[2]。随着基于嵌入式系统硬件的视觉技术的发展,可以利用物体检测算法对人工特征进行定位,从而实现更精确的托盘识别和定位。然而,这种方法很难在仓库中实施,因为它需要进行大量修改,并且会显著增加成本 [3, 4]。2D 激光测距仪或 3D 深度相机是另一种定位托盘的方法。然而,从 2D 深度信息中捕获足够的特征信息很有挑战性 [5-8]。相应的,3D 点云数据的平面分割可以通过模板匹配方法 [9] 提供更精确的结果。遗憾的是,该方法受检测速度的限制,识别精度受托盘类型和点云数据质量的严重影响,可能会对深度图像硬件和计算单元提出严格的要求。众所周知,所有现有的托盘识别和定位方法中,使用 RGB 图像或点云等单一数据源,要么导致错误定位的概率很高,要么消耗大量计算能力并大幅提高成本 ,在本文最后一部分我们介绍了第三种方法,它基于 2D 图像对象检测和 3D 点云处理,可以提供精确的位置数据。这种综合解决方案,我们称之为托盘识别和定位算法(PILA),使用低成本的硬件,只需要很少的计算资源。在该方案中,使用深度神经网络 (DNN) [10, 11] 方法检测 RGB 图像中的托盘,并将点云数据与 RGB 图像的感兴趣区域 (RoI) 对齐。然后通过从点云数据中提取的几何特征提取托盘的位置和角度。综上所述,DNN 方法旨在以高速率识别托盘,并利用点云数据以更少的计算时间或资源提供精确的定位结果。结果表明,3D定位精度在1cm左右,姿态估计误差在0.4度以下,在托盘识别方面表现出色。
本文第 2 部分介绍了托盘的视觉检测技术和一些神经网络模型,如 RCNN、Fast-RCNN、SSD 和 YOLO。 第三部分介绍了点云方法,并通过一些示例进行了解释。第 4 部分介绍了 综合解决方法——PILA 模型,实验结果表明 PILA 在某些方面优于其他两种方法(图 1)。
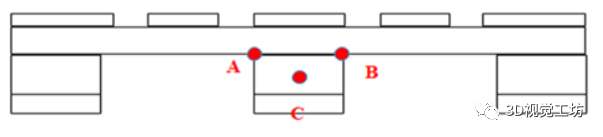
图 1:仓库中使用的普通托盘的前视图
基于视觉的托盘检测
作为计算机视觉中的热门话题,目标检测已经被公认为近十年来最热门的话题之一,并且已经进行了大量密集的研究。传统的基于模型的目标检测技术需要手动设计策略来分割托盘的几何形状并识别每个块。这个过程需要大量的人力,比如挑选特征描述符,如 Haar 特征和 Ad boost 算法来级联多个分类器 [12]。然而,基于深度学习的目标检测器的分层特征生成是一个自动过程,与其他方法相比,在识别和分类方面显示出巨大的潜力。通常有两种主要的目标检测框架。一种是单阶段检测模型SSD和YOLO。另一种是两阶段检测模型RPN,R-CNN 和 Faster R-CNN [13]。单阶段检测模型包含一个前馈全卷积网络,该网络直接为对象分类提供处理区域。对于Two-stage的目标检测网络,主要通过一个卷积神经网络来完成目标检测过程,其提取的是CNN卷积特征,在训练网络时,其主要训练两个部分,第一步是训练RPN网络,第二步是训练目标区域检测的网络。网络的准确度高、速度相对One-stage慢[14]。
托盘识别中的神经网络架构
作为典型的单阶段检测模型,YOLO 将整个目标检测问题视为回归问题。输入图像被划分为一组网格单元。每个网格单元预测一个固定数量的边界框,其置信度得分是通过将目标检测概率乘以并集上的交集(IoU)来计算的,其中 IoU 是预测的边界框面积与 ground truth 的重叠率 边界框,边界框的类别概率最终来自IoU分数。如式(1)所示,如果IoU分数大于0.5,则匹配值m为1,表示正匹配。相反,零匹配或负匹配表示对象是否被检测到。
与 YOLO 不同的是,SSD 接收整个图像作为输入并将其传递给多个卷积层,并利用卷积特征图来预测边界框。该模型生成用于预测边界框的对象类概率向量。本案例中使用的架构如图 3 所示,这是一个在 Image Net 上预训练的 VGG-16 模型,用于图像分类。前馈卷积网络用于生成一组固定大小的边界框,并为这些框中存在的对象类实例给出分数。SSD 模型不是预测潜在对象的得分值,而是直接给出一个类出现在边界框中的可能性。
Faster R-CNN 是两阶段架构,它通过结合分类和边界框回归并利用多任务学习过程来解决检测问题。该系统通常包括两个阶段,即用RPN进行感兴趣区域的获取,和 Fast R-CNN,该网络采用卷积作为主干网络并从输入图片中提取高级特征。Faster R-CNN 替代了 RPN 原始算法中的 Selective Search 方法 [15]。在第一阶段,为了生成候选框,RPN 在主干网络生成的特征图上使用了一个滑动窗口。在特征图上使用多尺度锚框来预测多个候选框。锚框定义为各种比例和纵横比,以识别任意对象。判断功能决定锚框是前景还是背景,然后使用边界回归对其进行修改以获得精确的候选框。接下来使用从特征提取器的中间层派生的 RoI 池化层来裁剪排名靠前的候选对象,这可以解决输入到具有完全连接层的网络的不同大小的特征图的问题。在第二阶段,每个候选框都经过最终分类和框细化过程 [16, 17]。
大量结果表明,与 YOLO 相比,Faster R-CNN 和 SSD 的性能可以提供更好的检测精度。但是,YOLO 比 SSD 和 Faster R-CNN 检测速度更快。

图 3:SSD模型架构图

三种托盘的识别率如表2所示,平均识别率在98%以上,对于仓库作业来说相当耐用。带有标记的托盘 RoI 的托盘检测结果如图 4 所示。无论卡盒是否存在,都可以很好地识别场景中是否存在多个托盘或托盘的倾斜。

表2:SSD模型托盘检测结果

图4: 托盘图像 (a) 检测场景中有多个托盘 (b) 倾斜的木质托盘 (c) 倾斜的塑料托盘
基于点云的托盘形状检测
通常,2D LRF 主要用于移动机器人 SLAM。随着在无人机器人导航中的广泛应用,有一些基于LRF设备的托盘检测和定位方法。与基于视觉的解决方案相比,这种方法不会受到可能导致错误检测或特征错误检测的成像失真、照明条件或缩放问题的影响。在早期的工作中,激光扫描数据被用于场景分割、物体检测和物体识别。该方法基于 3D 点云数据,用于 3D 对象检测和分类 [18]。但是,3D方案对硬件和算法的条件要求更严格,成本会大大增加。
为了利用成熟的目标检测技术并获得快速处理,将 2D 激光扫描仪数据转换为2D图像,可以采用 DNN 技术 [19, 20]。图 5 中描述了基于 2D 激光扫描仪数据 [21] 的托盘检测流程。它由数据准备、训练和测试以及托盘跟踪三个阶段组成。数据准备阶段用于将 2D 激光扫描仪数据转换为 2D 图像。然后,训练和测试阶段将 2D 图像作为输入。一旦模型经过微调和验证,就会执行跟踪阶段以检测并持续跟踪场景中所有可能的托盘。用于获取距离数据的 2D 激光扫描仪如图 6 (a)所示,使用距离数据进行托盘跟踪的 RoI 如图 6 (b)所示。激光扫描仪数据在采集后转换为位图,并由训练好的模型检测。如果大于某个阈值,则将其识别为托盘。

图5: 激光扫描数据的托盘检测流程

图6: (a) 工业2D激光线扫相机S3000 (b)2D激光数据组成的托盘形状
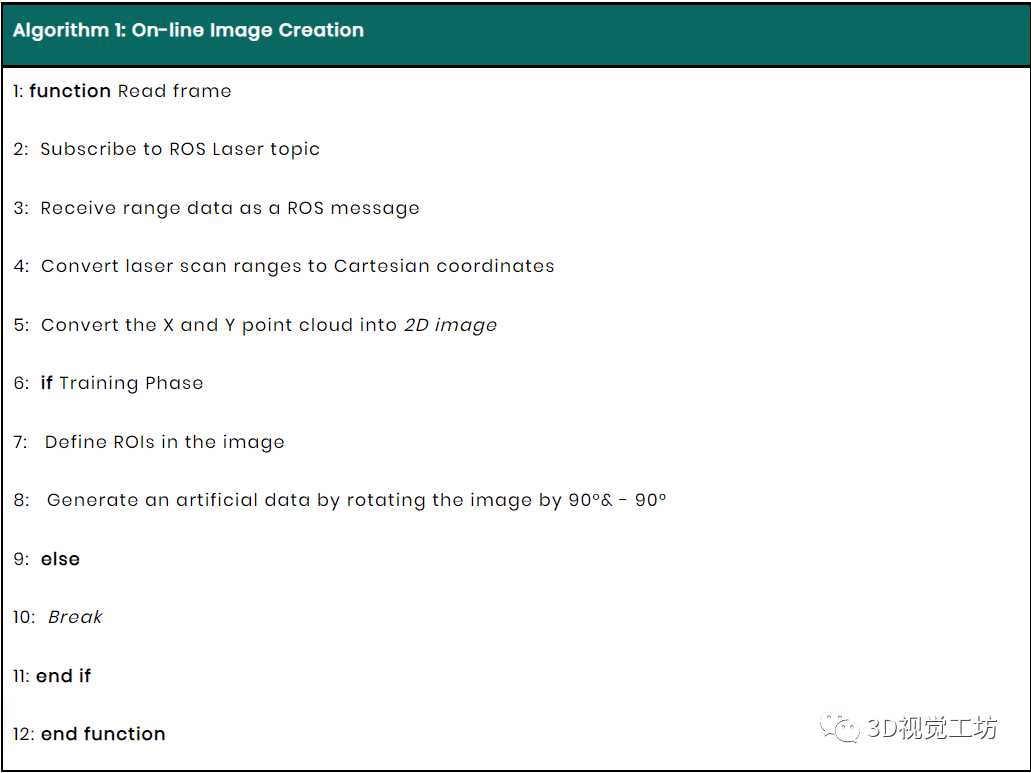
算法 1 描述了整个检测流程。读取激光扫描仪数据,然后将 X 和 Y 距离数据转换为 2D 图像进行图像处理。采集和训练 2D 图像数据集以识别 激光扫描仪数据中可能的存在的托盘。
PILA描述
本部分介绍了 PILA 综合解决方案的两阶段架构。图 7 相应地显示了 PILA 架构的流程图。深度神经网络用于从场景的 RGB 图像中识别可能存在的托盘。该模型是通过离线训练生成的,迁移的模型用于相机的在线检测。该算法分为3个功能阶段。在第一阶段,检测托盘并给出检测的置信度分数。在第二阶段,RGB-Depth 图像用于将 RGB 图像中的托盘与深度图像对齐。第三阶段,利用点云数据提取托盘正面平面,提取线段定位托盘中心的“T形”。特别是,根据托盘形状检测托盘边缘的水平(x)和垂直(y)线段,这可能因不同的托盘类型而异,此处使用的决策规则旨在找到托盘中心的“T形截面” ,可以作为更通用的解决方案。最后,可以得到托盘正面的中心位置x、y和z值和方位角。
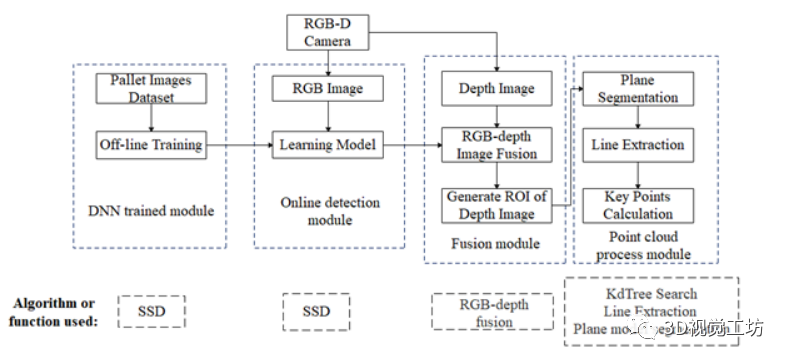
图 7: 托盘定位流程图, 由DNN训练模型,在线检测模型,多传感器融合模块、点云处理模块组成
点云处理
这部分,点云数据被处理以实现更精确的托盘定位 [22],如算法 2 中所述。点云数据在经过滤波、分割和提取等一系列操作后变得更精简。通过这种算法设计,可以高效地提高计算速度和定位精度。

点云滤波后,从平滑的点云数据中提取水平 (x) 和垂直 (y) 线分段,以定位托盘凹槽部分。首先,点云数据经过直通滤波,以确保 Z 值(距离)为0.5 m 和 3 m 之间的所有点。此步骤的目的是避免叉车臂、行人或地面反射激光束造成高度遮挡的情况。然后去除外点并对表面数据去平均。最后,采用降采样来降低计算成本。由于叉车机器人总是搬运地面或货架上的托盘,因此需要提取垂直平面作为托盘的正面。提取垂直面的流程如图8所示。点云分割后,从投影过滤后的 Z 方向的内点中提取一个或几个 2D 平面,根据质心的得分可以找到最可能的平面。点云数据的质心计算是确定最可能的托盘平面的关键方法。在此步骤之前,对 2D 点云进行下采样以加快计算过程。
最后,发现凹槽处的x和y线形成“T形”并定位托盘中心。作为该方法的决定性部分,我们提出了一种基于托盘一般几何关系的通用决策规则。“T形”是根据托盘顶部的底线(x线)和中柱外边界(y线)的组合找到的。找线提取和托盘定位的流程如图 9 所示。提取x和y方向的水平边界点和垂直边界点。然后通过 KdTree 搜索方法提取 x 和 y 线,并且 x 线和 y 线段中的点数必须分别大于阈值。在对所有的x和y线进行排序后,发现最接近粗略中心点的x线和y线形成图10(d)中的“T形”。无论托盘几何形状如何,这种方法都带有一定的鲁棒性。最后确定A、B(相交点)和C点,如图图10(d),图10是PILA的四个主要步骤的图形表示。(a)和(b)是RGB图像和点云数据,(c)和(d)是通过托盘识别和点云处理生成的,用于定位托盘中心。

图 8:垂直面提取流程。点云分割后,投影点云滤波后的内点并生成二维点云。最后,对 2D 点云进行下采样,然后生成垂直平面。

Figure 9: 找线提取和托盘定位的流程
图 9:线路提取和托盘定位的管道。首先提取x和y方向的水平边界点和垂直边界点。通过 KdTree 搜索方法执行 x 和 y 行,并选择最靠近中心的 x 行中的 1 行和 y 行中的 2 行。

图 10:PILA 四个主要步骤的图像表示。(a) 托盘的 RGB 图像,(b) 从深度图像转换的原始点云数据,(c) 根据托盘识别过滤的点云数据,(d) 托盘位置的最终点云数据。
实验结果表明,PILA 能够识别和定位 3D场景下的 托盘,平均绝对误差如表 3 中的 1 cm 或 0.65 度以内。识别平均耗时为 700 ms, 从而满足叉车机器人运行的“实时性”要求。实验上,PILA 的准确性和速度比使用专有数据源作为 RGB 图像或托盘定位的深度数据的那些更高和更快[23-25]。表 3 显示了 PILA 与工业机器人市场中主要商业解决方案的比较,PILA 在速度、精度和工作距离方面表现出色。

表3:不同解决方案间的对比
总结和讨论
本文综述了托盘识别技术,包括基于视觉的托盘检测、点云方法以及基于目标识别和点云相关技术相结合的托盘识别和定位算法(PILA)。对于视觉方法,我们简要回顾了基于 DNN 方法的RGB 图像识别。YOLO、SDD和Faster RCNN作为典型例子进行了详细描述。然后引入 RGB 和深度图像相结合的技术,构建 3D 托盘颜色模型,以获得更准确的定位性能。PILA 已针对实用的托盘拣选设备和自动叉车应用进行了实施和验证,并在精度、速度和工作距离方面表现出出色的效率。结果表明,托盘正确识别率高达90%,托盘中心定位误差和定位角度误差小于1厘米或0.4度。此外,与大多数基于计算机视觉或深度图像的解决方案相比,PILA在实际物流仓库中的叉车机器人应用中已被证明是可行的。
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区
本文仅做学术分享,如有侵权,请联系删文。