在上期,我们提到,对于AI计算服务器的组网需求,实际上是需要解决三个问题:
- 云业务网络通道,包括用户登录各台DGX A100主机操作系统,云平台管理各台宿主机(Underlay)、虚拟机或容器(Overlay或Underlay)之间的互访;
- GPU到专用的高性能存储之间的互访通道;
- 多块训练型GPU的跨节点互访。
对小H这个对吃和玩更感兴趣的调皮孩子而言,这几个问题好像有点难,所以小H暂且挂起这个问题,跑出去玩几天找找灵感。
那么,小H最近又跑到哪里玩了呢?
原来,小H跑去了哈尔滨旅游,而且还被忽悠去了滑雪场,在经过教练半天的指导后,小H觉得滑雪很简单,就自行去了高级道。
由于高级道的坡度比较陡,小H发现无论如何都减不下速度,眼看前面有个弯……小H突然想到了《王者荣耀》里面孙尚香的核心技能,也就是翻跟斗。
与游戏里面不同的是,小H滚翻以后,雪板飞出去了,一直飞到护栏外面,也就是成为了开局就挂了而且爆装备的玩家。

工作人员把小H劝退了,告诉小H:
“这里是高级道,你看看自己啥水平,去该去的雪道吧!”
方老师听说了小H的光辉事迹,并没有嘲笑小H,而是引导了一下:
你想一想,云管理与业务的通道,和大规模数据交换的通道,差异在什么地方呢?
小H还是一时没想出来。
原来,AI训练场景下,其实与较为传统的HPC类似,存在管理网络,计算网络和存储网络。
管理网络用于调度分配计算任务,以及云计算平台租户面部署的前端,后端和数据库之间的互访。这部分一般数据流量不大,一般在Gbps级别,允许较高的网络收敛比。
计算网络涉及到GPU卡间的高速GPU direct over RDMA数据交换,任何丢包都会造成效率严重下降,也就是需要所谓的无阻塞交换(non-blocking switch)。
存储网络在AI学习中不是必须独立的,可以和业务网络公用,对于使用gluster fs 或lustre fs等大型分布式文件系统的用户而言,也可以增加专用的支持RDMA的网络,提升存储访问效率。
基于这三个原则,我们就可以设计AI大平台训练的网络了。
首先我们解决最容易的问题:实现云业务网络通道。
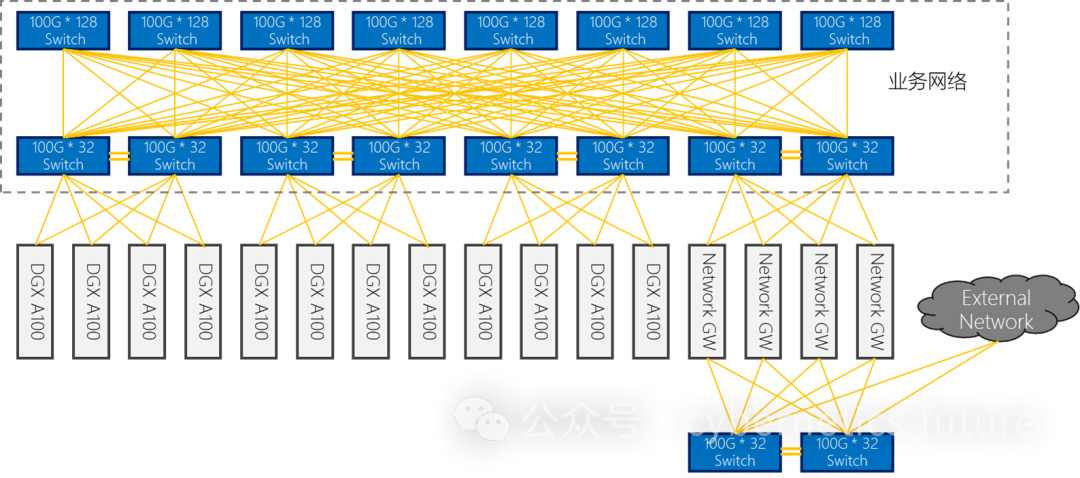
如图,由于DGX A100的业务网卡为100GE QSFP28,我们需要用支持QSPF28 (Serdes 25G)的TD3 芯片的交换机,如32口100G。
在大规模组网的情况下,每台32口100G交换机可以使用28个100G作为下行,4个100G作为上行,或24个100G作为下行,8个100G作为上行。此种组网的收敛比分别为1:7/1:3。
特别的,对连接云外网络,可以经过专用的外网区。
这样,每组两台32G 100G交换机可以连接24台DGX A100,核心层使用128口100G交换机,8台可连接60组以上的接入层,可容纳的DGX A100台数可达1200台以上。如果集群的数量进一步增加,还可以将网络扩展到三层网络,实现10000台以上的集群。
但对于计算网络的实现,我们需要在更严苛的约束下,解决更多的问题……