前言
最近很多人在讨论OpenStack,我也想写点东西。思来想去,云计算范畴实在广泛,自然就聊点最近话题异常火热,让广大云计算从业者爱之深、痛之切,想说一声爱你,不容易的OpenStack吧。
这里,仅从技术角度出发,谈谈OpenStack云平台在部署、架构和运维实施等方面的感想。
缘起,在2014年大二首次接触到OpenStack,当时国内外资料远没有当前这么丰富,为安装一个OpenStack H版环境(一台笔记本用VMware Workstation虚拟出2台虚拟机)愣是用了1个星期多,最后仍然创建虚拟机失败。后来为了学习OpenStack,临近毕业时特意去上海实习工作,不觉间已经四年了。
OpenStack涉及的东西太多太多,计算、存储、网络、架构、产品、运维、监控和性能优化、代码等等。这里就各抒已见,谈点自己四年以来对OpenStack的理解吧,也算是一个交代,如有差错,欢迎拍砖。
诚然,一个良好的架构设计和运维保障措施,能为OpenStack云平台的稳定健康运行,产生不可估量的积极影响。如果化繁为简,简单的来说,要部署一套生产环境级别的OpenStack云平台,至少会涉及到四个层次的内容,即物理基础设施层、存储层、OpenStack云服务层和用户应用层。如下图所示。
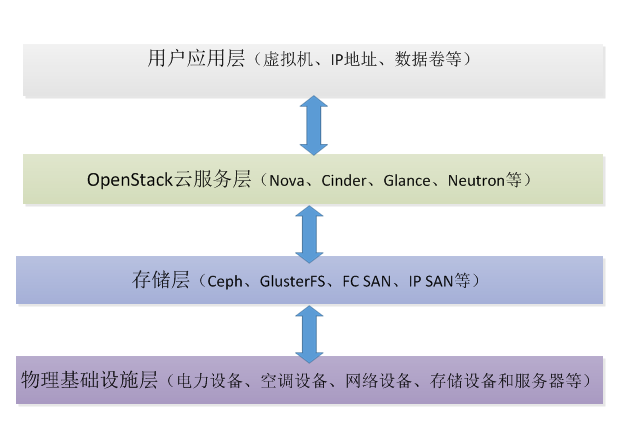
物理基础设施层
首先,从最底层开始说起,即“物理基础设施层”。一个基本的物理基础设施IT环境,包括了电力设备、空调和防火设备、网络设备(如交换机、路由器、防火墙、负载均衡设备等)、存储设备和服务器等。由于专业知识的限制,这里,只涉及交换机和服务器方面。一个基本的物理IT环境,如下图所示。
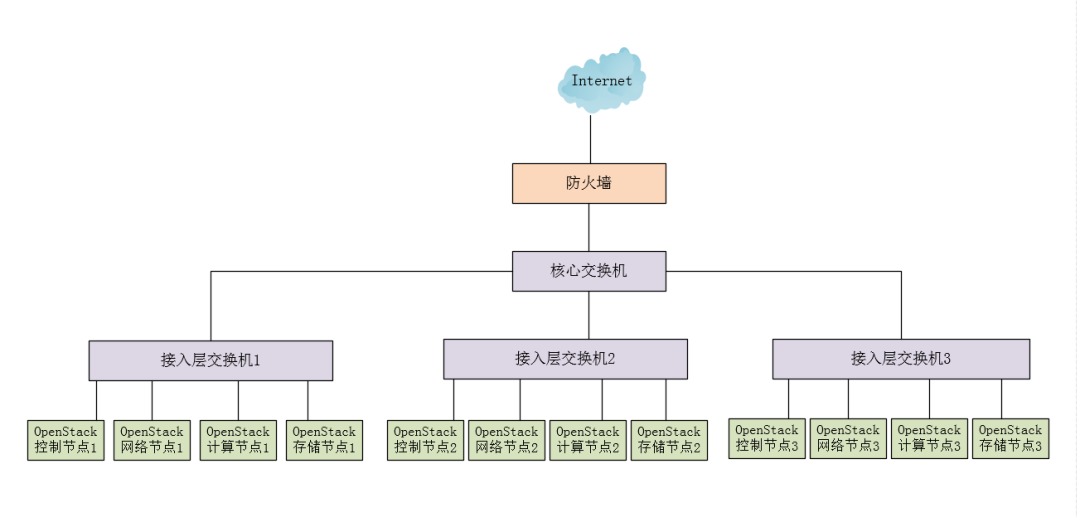
交换机设备
一般地,在OpenStack生产环境上,交换机端口应该做聚合(channel)。也就是将2个或多个物理端口组合在一起成为一条逻辑的链路从而增加交换机和网络节点之间的带宽,将属于这几个端口的带宽合并,给端口提供一个几倍于独立端口的独享的高带宽。Trunk是一种封装技术,它是一条点到点的链路,链路的两端可以都是交换机,也可以是交换机和路由器,还可以是主机和交换机或路由器。
服务器
网卡
OpenStack云平台涉及到的网络有管理网络(用于OpenStack各服务之间通信)、外部网络(提供floating ip)、存储网络(如ceph存储网络)和虚机网络(也称租户网络、业务网络)四种类型。
对应到每一种网络,服务器都应该做网卡Bond,来提供服务器网络的冗余、高可用和负载均衡的能力,根据实际需求,可以选择模式0或模式1。在网络流量较大的场景下推荐使用bond 0;在可靠性要求较高的场景下推荐使用bond 1。
二者优劣比较。

一般地,在小规模的私有云环境中,网络类型对应的带宽是:
• 管理网络:千兆网络
• 外部网络:千兆网络
• 存储网络:万兆网络
• 租户网络:千兆网络
如果是中大规模的私有云或公有云环境,则推荐尽量都使用万兆网络。
硬盘
服务器操作系统使用的系统盘,应该用2块硬盘来做RAID 1,以提供系统存储的高可靠性。且推荐使用高性能且成本可控的SAS硬盘,以提高操作系统、MySQL数据库和Docker容器(如果使用kolla部署openstack)的IO存储性能。
CPU
OpenStack各计算节点的CPU型号,必须一致,以保证虚拟机的迁移功能正常可用等。
内存
OpenStack各计算节点的内存大小,应该一致,以保证虚拟机创建管理的均衡调度等。同时,主机的Swap交换分区,应该科学合理的设置,不能使用系统默认创建的。
数据中心中少部分机器用于做控制节点,大部分机器都是需要运行虚拟化软件的,虚拟化平台上有大量的VM,而宿主机本身的系统也会跑一些服务,那么这就势必会造成vm之间资源抢占,vm与宿主机系统之间的资源抢占,我们需要通过设定规则,让他们在各自的界限内高效运行,减少冲突抢占。
我们可以让宿主机运行操作系统时候,更多的选择指定的几个核,这样就不会过多抢占虚拟化中虚机的vcpu调度,通过修改内核启动参数我们可以做到:
修改 /etc/default/grub文件,让系统只使用前三个核 隔离其余核。
GRUB_CMDLINE_LINUX_DEFAULT="isolcpus=4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31"
更新内核参数
# update-grub
# reboot
内存配置方面,网易私有云的实践是关闭 KVM 内存共享,打开透明大页:
echo 0 > /sys/kernel/mm/ksm/pages_shared
echo 0 > /sys/kernel/mm/ksm/pages_sharing
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo 0 > /sys/kernel/mm/transparent_hugepage/khugepaged/defrag
据说,经过 SPEC CPU2006 测试,这些配置对云主机 CPU 性能大概有7%左右的提升。
OpenStack云平台层
云平台高可用(HA)
高可用(HA)介绍
高可用性是指提供在本地系统单个组件故障情况下,能继续访问应用的能力,无论这个故障是业务流程、物理设施、IT软/硬件的故障。最好的可用性, 就是你的一台机器宕机了,但是使用你的服务的用户完全感觉不到。你的机器宕机了,在该机器上运行的服务肯定得做故障切换(failover),切换有两个维度的成本:RTO (Recovery Time Objective)和 RPO(Recovery Point Objective)。RTO 是服务恢复的时间,最佳的情况是 0,这意味着服务立即恢复;最坏是无穷大意味着服务永远恢复不了;RPO 是切换时向前恢复的数据的时间长度,0 意味着使用同步的数据,大于 0 意味着有数据丢失,比如 ” RPO = 1 天“ 意味着恢复时使用一天前的数据,那么一天之内的数据就丢失了。因此,恢复的最佳结果是 RTO = RPO = 0,但是这个太理想,或者要实现的话成本太高。
对 HA 来说,往往使用分布式存储,这样的话,RPO =0 ;同时使用 Active/Active (双活集群) HA 模式来使得 RTO 几乎为0,如果使用 Active/Passive HA模式的话,则需要将 RTO 减少到最小限度。HA 的计算公式是[ 1 - (宕机时间)/(宕机时间 + 运行时间)],我们常常用几个 9 表示可用性:
• 2 个9:99% = 1% 365 = 3.65 24 小时/年 = 87.6 小时/年的宕机时间
• 4 个9: 99.99% = 0.01% 365 24 * 60 = 52.56 分钟/年
• 5 个9:99.999% = 0.001% * 365 = 5.265 分钟/年的宕机时间,也就意味着每次停机时间在一到两分钟。
• 11 个 9:几年宕机几分钟。
服务的分类
HA 将服务分为两类:
• 有状态服务:后续对服务的请求依赖于之前对服务的请求。OpenStack中有状态的服务包括MySQL数据库和AMQP消息队列。对于有状态类服务的HA,如neutron-l3-agent、neutron-metadata-agent、nova-compute、cinder-volume等服务,最简便的方法就是多节点部署。比如某一节点上的nova-compute服务挂了,也并不会影响到整个云平台不能创建虚拟机,或者所在节点的虚拟机无法使用(比如ssh等)。
• 无状态服务:对服务的请求之间没有依赖关系,是完全独立的,基于冗余实例和负载均衡实现HA。OpenStack中无状态的服务包括nova-api、nova-conductor、glance-api、keystone-api、neutron-api、nova-scheduler等。由于API服务,属于无状态类服务,天然支持Active/Active HA模式。因此,一般使用 keepalived +HAProxy方案来做。
HA 的种类
HA 需要使用冗余的服务器组成集群来运行负载,包括应用和服务。这种冗余性也可以将 HA 分为两类:
• Active/Passive HA:即主备HA。在这种配置下,系统采用主和备用机器来提供服务,系统只在主设备上提供服务。在主设备故障时,备设备上的服务被启动来替代主设备提供的服务。典型地,可以采用 CRM 软件比如 Pacemaker 来控制主备设备之间的切换,并提供一个虚拟 IP 来提供服务。
• Active/Active HA:即主主HA,包括多节点时成为多主(Multi-master)。在这种配置下,系统在集群内所有服务器上运行同样的负载。以数据库为例,对一个实例的更新,会被同步到所有实例上。这种配置下往往采用负载均衡软件比如 HAProxy 来提供服务的虚拟 IP。
OpenStack云环境高可用(HA)
云环境是一个广泛的系统,包括了基础设施层、OpenStack云平台服务层、虚拟机和最终用户应用层。
云环境的 HA 包括:
• 用户应用的 HA
• 虚拟机的 HA
• OpenStack云平台服务的 HA
• 基础设施层的HA:电力、空调和防火设施、网络设备(如交换机、路由器)、服务器设备和存储设备等
仅就OpenStack云平台服务(如nova-api、nova-scheduler、nova-compute等)而言,少则几十,多则上百个。如果某一个服务挂了,则对应的功能便不能正常使用。因此,如何保障整体云环境的HA高可用,便成为了架构设计和运维的重中之重。
OpenStack HA高可用架构,如下图所示。
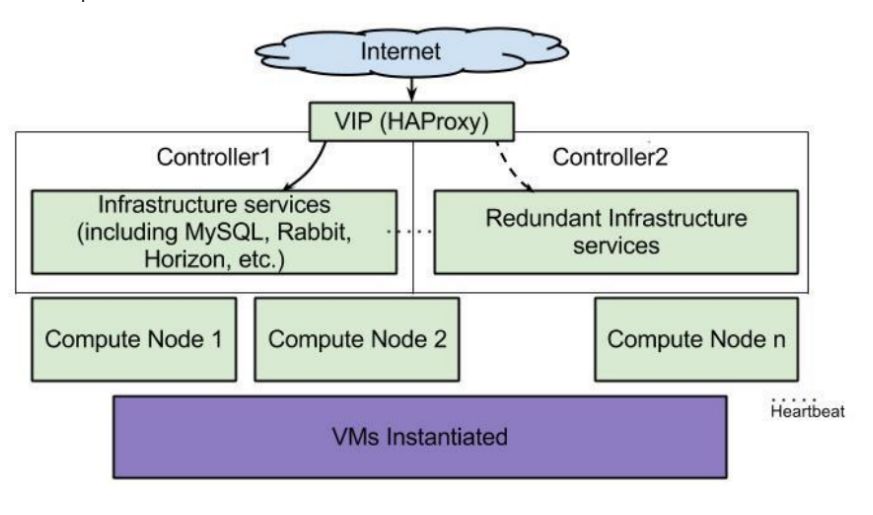
如果,从部署层面来划分,OpenStack高可用的内容包括:
• 控制节点(Rabbitmq、mariadb、Keystone、nova-api等)
• 网络节点(neutron_dhcp_agent、neutron_l3_agent、neutron_openvswitch_agent等)
• 计算节点(Nova-Compute、neutron_openvswitch_agent、虚拟机等)
• 存储节点(cinder-volume、swift等)
控制节点HA
在生产环境中,建议至少部署三台控制节点,其余可做计算节点、网络节点或存储节点。采用Haproxy + KeepAlived方式,代理数据库服务和OpenStack服务,对外暴露VIP提供API访问。
MySQL数据库HA
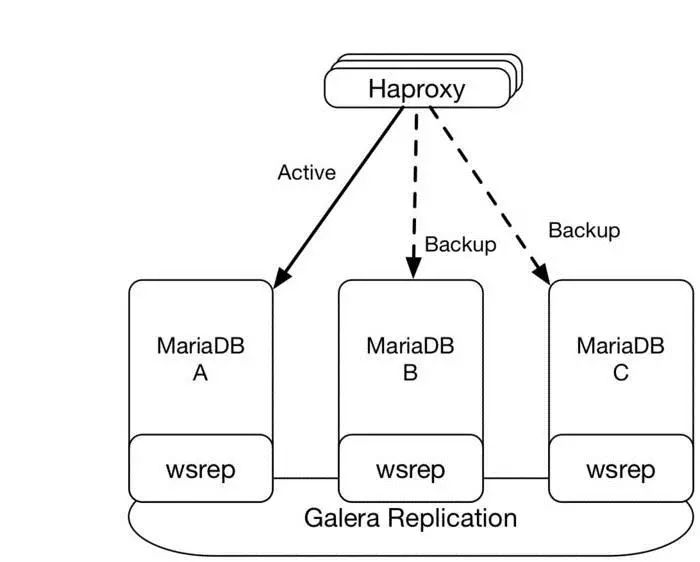
mysql 的HA 方案有很多,这里只讨论openstack 官方推荐的mariadb Galara 集群。Galera Cluster 是一套在innodb存储引擎上面实现multi-master及数据实时同步的系统架构,业务层面无需做读写分离工作,数据库读写压力都能按照既定的规则分发到各个节点上去。特点如下: 1)同步复制,(>=3)奇数个节点 2)Active-active的多主拓扑结构 3)集群任意节点可以读和写 4)自动身份控制,失败节点自动脱离集群 5)自动节点接入 6)真正的基于”行”级别和ID检查的并行复制 7)无单点故障,易扩展
采用MariaDB + Galera方案部署至少三个节点(最好节点数量为奇数),外部访问通过Haproxy的active + backend方式代理。平时主库为A,当A出现故障,则切换到B或C节点。如下图所示。
RabbitMQ 消息队列HA
RabbitMQ采用原生Cluster集群方案,所有节点同步镜像队列。小规模环境中,三台物理机,其中2个Mem节点主要提供服务,1个Disk节点用于持久化消息,客户端根据需求分别配置主从策略。据说使用ZeroMQ代替默认的RabbitMQ有助于提升集群消息队列性能。
OpenStack API服务HA
OpenStack控制节点上运行的基本上是API 无状态类服务,如nova-api、neutron-server、glance-registry、nova-novncproxy、keystone等。因此,可以由 HAProxy 提供负载均衡,将请求按照一定的算法转到某个节点上的 API 服务,并由KeepAlived提供 VIP。
网络节点HA
网络节点上运行的Neutron服务包括很多的组件,比如 L3 Agent,openvswitch Agent,LBaas,V**aas,FWaas,Metadata Agent 等,其中部分组件提供了原生的HA 支持。
• Openvswitch Agent HA: openvswitch agent 只在所在的网络或者计算节点上提供服务,因此它是不需要HA的
• L3 Agent HA:成熟主流的有VRRP 和DVR两种方案
• DHCP Agent HA:在多个网络节点上部署DHCP Agent,实现HA
• LBaas Agent HA:Pacemaker + 共享存储(放置 /var/lib/neutron/lbaas/ 目录) 的方式来部署 A/P 方式的 LBaas Agent HA
存储节点HA
存储节点的HA,主要是针对cinder-volume、cinder-backup服务做HA,最简便的方法就是部署多个存储节点,某一节点上的服务挂了,不至于影响到全局。
计算节点和虚拟机 HA
计算节点和虚拟机的HA,社区从2016年9月开始一直致力于一个虚拟机HA的统一方案,但目前仍然没有一个成熟的方案。实现计算节点和虚拟机HA,要做的事情基本有三件,即。
① 监控
监控主要做两个事情,一个是监控计算节点的硬件和软件故障。第二个是触发故障的处理事件,也就是隔离和恢复。
OpenStack 计算节点高可用,可以用pacemaker和pacemaker_remote来做。使用pacemaker_remote后,我们可以把所有的计算节点都加入到这个集群中,计算节点只需要安装pacemaker_remote即可。pacemaker集群会监控计算节点上的pacemaker_remote是否 “活着”,你可以定义什么是“活着”。比如在计算节点上监控nova-compute、neutron-ovs-agent、libvirt等进程,从而确定计算节点是否活着,亦或者租户网络和其他网络断了等。如果监控到某个pacemaker_remote有问题,可以马上触发之后的隔离和恢复事件。
② 隔离
隔离最主要的任务是将不能正常工作的计算节点从OpenStack集群环境中移除,nova-scheduler就不会在把create_instance的message发给该计算节点。
Pacemaker 已经集成了fence这个功能,因此我们可以使用fence_ipmilan来关闭计算节点。Pacemaker集群中fence_compute 会一直监控这个计算节点是否down了,因为nova只能在计算节点down了之后才可以执行host-evacuate来迁移虚拟机,期间等待的时间稍长。这里有个更好的办法,就是调用nova service-force-down 命令,直接把计算节点标记为down,方便更快的迁移虚拟机。
③ 恢复
恢复就是将状态为down的计算节点上的虚拟机迁移到其他计算节点上。Pacemaker集群会调用host-evacuate API将所有虚拟机迁移。host-evacuate最后是使用rebuild来迁移虚拟机,每个虚拟机都会通过scheduler调度在不同的计算节点上启动。
当然,还可以使用分布式健康检查服务Consul等。
虚拟机操作系统故障恢复
OpenStack 中的 libvirt/KVM 驱动已经能够很好地自动化处理这类问题。具体地,你可以在flavor的 extra_specs 或者镜像的属性中加上 hw:watchdog_action ,这样一个 watchdog 设备会配置到虚拟机上。如果 hw:watchdog_action 设置为 reset,那么虚拟机的操作系统一旦奔溃,watchdog 会将虚拟机自动重启。
OpenStack计算资源限制
设置内存
内存分配超售比例,默认是 1.5 倍,生产环境不建议开启超售
ram_allocation_ratio = 1
内存预留量,这部分内存不能被虚拟机使用,以便保证系统的正常运行
reserved_host_memory_mb = 10240 //如预留10GB
设置CPU
在虚拟化资源使用上,我们可以通过nova来控制,OpenStack提供了一些配置,修改文件nova.conf。虚拟机 vCPU 的绑定范围,可以防止虚拟机争抢宿主机进程的 CPU 资源,建议值是预留前几个物理 CPU
vcpu_pin_set = 4-31
物理 CPU 超售比例,默认是 16 倍,超线程也算作一个物理 CPU
cpu_allocation_ratio = 8
使用多Region和AZ
如果,OpenStack云平台需要跨机房或地区部署,可以使用多Region和 Availability Zone(以下简称AZ)的方案。这样,每个机房之间在地理位置上自然隔离,这对上层的应用来说是天然的容灾方法。
多区域(Region)部署
OpenStack支持依据地理位置划分为不同的Region,所有的Regino除了共享Keystone、Horizon服务外,每个Region都是一个完整的OpenStack环境,从整体上看,多个区域之间的部署相对独立,但可通过内网专线实现互通(如BGP-EV**)。其架构如下图所示。
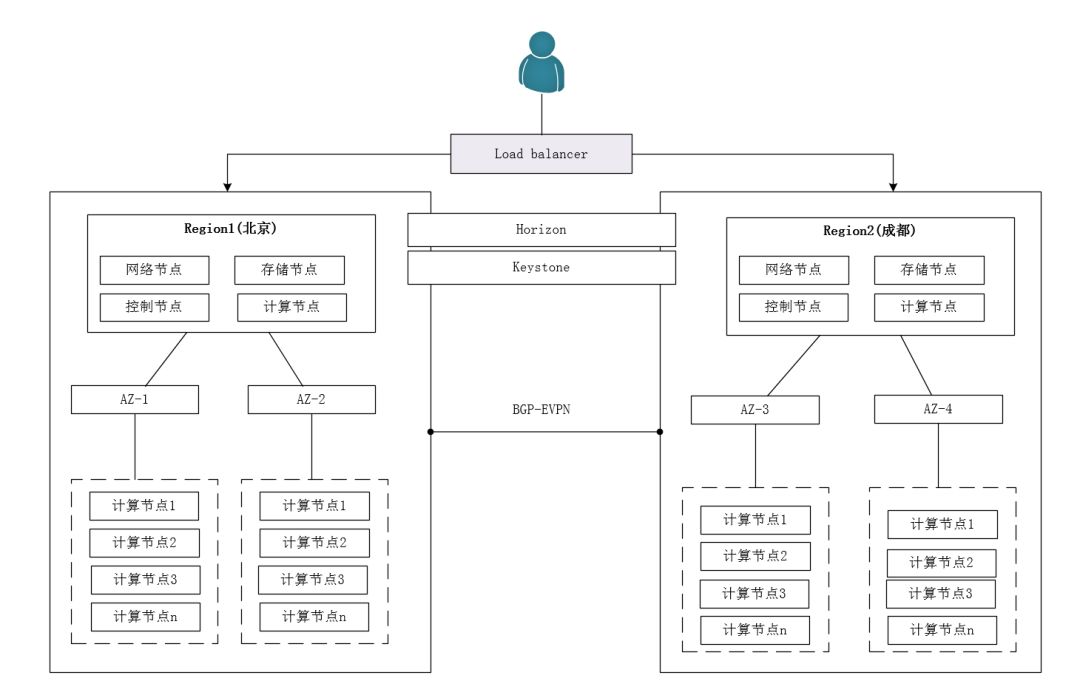
部署时只需要部署一套公共的Keystone和Horizon服务,其它服务按照单Region方式部署即可,通过Endpoint指定Region。用户在请求任何资源时必须指定具体的区域。采用这种方式能够把分布在不同的区域的资源统一管理起来,各个区域之间可以采取不同的部署架构甚至不同的版本。其优点如下:
• 部署简单,每个区域部署几乎不需要额外的配置,并且区域很容易实现横向扩展。
• 故障域隔离,各个区域之间互不影响。
• 灵活自由,各个区域可以使用不同的架构、存储、网络。
但该方案也存在明显的不足:
• 各个区域之间完全隔离,彼此之间不能共享资源。比如在Region A创建的Volume,不能挂载到Region B的虚拟机中。在Region A的资源,也不能分配到Region B中,可能出现Region负载不均衡问题。
• 各个区域之间完全独立,不支持跨区域迁移,其中一个区域集群发生故障,虚拟机不能疏散到另一个区域集群中。
• Keystone成为最主要的性能瓶颈,必须保证Keystone的可用性,否则将影响所有区域的服务。该问题可以通过部署多Keystone节点解决。
OpenStack多Region方案通过把一个大的集群划分为多个小集群统一管理起来,从而实现了大规模物理资源的统一管理,它特别适合跨数据中心并且分布在不同区域的场景,此时根据区域位置划分Region,比如北京和上海。而对于用户来说,还有以下好处:
• 用户能根据自己的位置选择离自己最近的区域,从而减少网络延迟,加快访问速度。
• 用户可以选择在不同的Region间实现异地容灾。当其中一个Region发生重大故障时,能够快速把业务迁移到另一个Region中。
多Availability Zone部署
如果,只是想在一个机房中部署OpenStack云环境。则只需要使用AZ方案即可。每个AZ有自己独立供电的机架,以及OpenStack计算节点。
Availability Zone
一个Region可以被细分为一个或多个物理隔离或逻辑隔离的availability zones(AZ)。启动虚拟机时,可以指定特定的AZ甚至特定AZ中的某一个节点来启动该虚拟机。AZ可以简单理解为一组节点的集合,这组节点具有独立的电力供应设备,比如一个个独立供电的机房,或一个个独立供电的机架都可以被划分成AZ。
然后将应用的多个虚拟机分别部署在Region的多个AZ上,提高虚拟机的容灾性和可用性。由于,AZ是物理隔离的,所以一个AZ挂了不会影响到其他的AZ。同时,还可以将挂了的AZ上的虚拟机,迁移到其他正常可用的AZ上,类似于异地双活。
Host Aggregate
除了AZ,计算节点也可以在逻辑上划分为主机聚合(Host Aggregates简称HA)。主机聚合使用元数据去标记计算节点组。一个计算节点可以同时属于一个主机聚合以及AZ而不会有冲突,它也可以属于多个主机聚合。
主机聚合的节点具有共同的属性,比如:cpu是特定类型的一组节点,disks是ssd的一组节点,os是linux或windows的一组节点等等。需要注意的是,Host Aggregates是用户不可见的概念,主要用来给nova-scheduler通过某一属性来进行instance的调度,比如讲数据库服务的 instances都调度到具有ssd属性的Host Aggregate中,又或者让某个flavor或某个image的instance调度到同一个Host Aggregates中。
简单的来说,Region、Availability Zone和Host Aggregate这三者是从大范围到小范围的关系,即前者包含了后者。一个地理区域Region包含多个可用区AZ (availability zone),同一个AZ中的计算节点又可以根据某种规则逻辑上的组合成一个组。例如在北京有一个Region,成都有一个Region,做容灾之用。同时,在北京Region下,有2个AZ可用区(如酒仙桥机房和石景山机房),每个AZ都有自己独立的网络和供电设备,以及OpenStack计算节点等,如果用户是在北京,那么用户在部署VM的时候选择北京,可以提高用户的访问速度和较好的SLA(服务等级协议)。
选择合适的网络方案
用户常困扰于到底应该使用何种网络方案,如VLAN、VXLAN和GRE等。VLAN和VXLAN的区别即在于,VLAN是一种大二层网络技术,不需要虚拟路由转换,性能相对VXLAN、GRE要好些,支持4094个网络,架构和运维简单。VXLAN是一种叠加的网络隧道技术,将二层数据帧封装在三层UDP数据包里传输,需要路由转换,封包和解包等,性能相对VLAN要差些,同时架构也更复杂,好处是支持1600多万个网络,扩展性好。
如果,企业用户在相当长的一段时间内,云平台规模都较小(比如在1万台虚拟机数量以下),且对多租户网络安全隔离性要求不高,那么可以使用VLAN网络。反之,如果网络安全隔离性需求压倒一切,或者云平台规模非常大,则可以使用VXLAN网络方案。
在VXLAN和VLAN网络通信,即租户私网和Floating IP外网路由转发通信背景下,默认在OpenStack传统的集中式路由环境中,南北流量和跨网络的东西流量都要经过网络节点,当计算节点规模越来越大的时候,网络节点很快会成为整个系统的瓶颈,为解决这个问题引入了Distribute Virtual Router (DVR)的概念。使用DVR方案,可以将路由分布到计算节点,南北流量和跨网段的东西流量由虚机所在计算节点上的虚拟路由进行路由,从而提高稳定性和性能。
备份云平台数据
俗话说,有备份在,睡觉也踏实。在一个实际的环境中,由于种种原因,可能发生数据被删除的情况。比如,云平台中的数据库、虚拟机、数据卷、镜像或底层存储被删除等,如果数据没有进行备份,则是灾难性的后果。
在一个由OpenStack+Ceph架构组成的云平台环境中,有N种数据备份方案。如OpenStack有自带的Karbor、Freezer云服务,Ceph也有相关的备份方案,也有其他商业的备份方案等。实际上,OpenStack云平台本身也提供了一些较好易用的备份功能,比如虚拟机快照/备份、数据卷快照/备份,在使用时也倡导通过将数据卷挂载给虚拟机,从而将数据写入到云盘中,间接的实现数据容灾备份。
如果因为某些原因,没有跨物理机房或地区的Region和AZ。那么OpenStack云平台相关的数据备份,则是必须要做的。比如MySQL数据库等,可以根据实际需求,每隔几小时进行一次备份。而备份的数据,建议存放到其他机器上。关于Ceph的底层存储备份方案,可以使用RBD Mirroring方案。
RBD Mirroring是Ceph新的异步备份功能。支持配置两个Ceph Cluster之间的rbd同步。在此方案下,Master Cluster使用性能较高的存储设备,提供给OpenStack的Glance、Cinder(cinder-volume、cinder-backup)和Nova服务使用;而Backup Cluster则使用容量空间大且廉价的存储设备(如SATA盘)来备份Ceph数据。不同的Ceph Cluster集群,可以根据实际需要,选择是否跨物理机房备份。如下图所示。
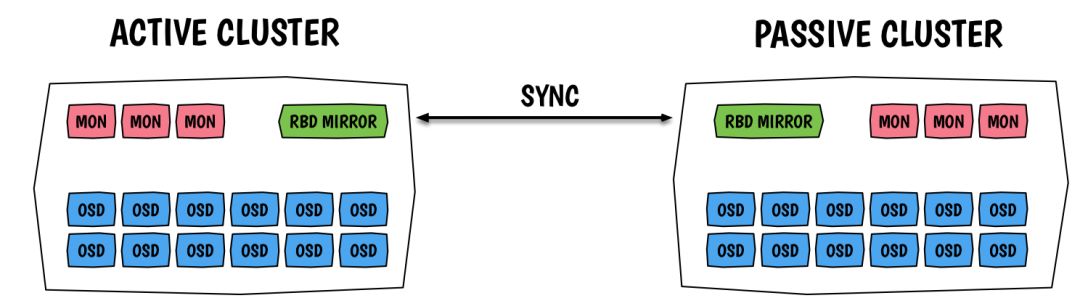
优点:
• Ceph新的功能,不需要额外开发
• 同步的粒度比较小,为一个块设备的transaction
• 保证了Crash consistency
• 可配置pool的备份,也可单独指定image备份
• 同步备份,不同机房的Ceph集群,底层存储的跨机房容灾
使用合适的Docker存储
如果,OpenStack云平台是用kolla容器化部署和管理的。那么选择一个正确、合适的Docker存储,关乎你的平台稳定和性能。
Docker 使用存储驱动来管理镜像每层内容及可读写的容器层,存储驱动有 devicemapper、aufs、overlay、overlay2、btrfs、zfs 等,不同的存储驱动实现方式有差异,镜像组织形式可能也稍有不同,但都采用栈式存储,并采用 Copy-on-Write(CoW) 策略。且存储驱动采用热插拔架构,可动态调整。那么,存储驱动那么多,该如何选择合适的呢?大致可从以下几方面考虑:
• 若内核支持多种存储驱动,且没有显式配置,Docker 会根据它内部设置的优先级来选择。优先级为 aufs > btrfs/zfs > overlay2 > overlay > devicemapper。若使用 devicemapper 的话,在生产环境,一定要选择 direct-lvm, loopback-lvm 性能非常差。
• 选择会受限于 Docker 版本、操作系统、系统版本等。例如,aufs 只能用于 Ubuntu 或 Debian 系统,btrfs 只能用于 SLES (SUSE Linux Enterprise Server, 仅 Docker EE 支持)。
• 有些存储驱动依赖于后端的文件系统。例如,btrfs 只能运行于后端文件系统 btrfs 上。
• 不同的存储驱动在不同的应用场景下性能不同。例如,aufs、overlay、overlay2 操作在文件级别,内存使用相对更高效,但大文件读写时,容器层会变得很大;devicemapper、btrfs、zfs 操作在块级别,适合工作在写负载高的场景;容器层数多,且写小文件频繁时,overlay2 效率比 overlay更高;btrfs、zfs 更耗内存。
Docker 容器其实是在镜像的最上层加了一层读写层,通常也称为容器层。在运行中的容器里做的所有改动,如写新文件、修改已有文件、删除文件等操作其实都写到了容器层。存储驱动决定了镜像及容器在文件系统中的存储方式及组织形式。在我们的生产环境中,使用的是Centos 7.4系统及其4.15内核版本+Docker 1.13.1版本。因此使用的是overlay2存储。下面对overlay2作一些简单介绍。
Overlay介绍
OverlayFS 是一种类似 AUFS 的联合文件系统,但实现更简单,性能更优。OverlayFS 严格来说是 Linux 内核的一种文件系统,对应的 Docker 存储驱动为 overlay 或者 overlay2,overlay2 需 要Linux 内核 4.0 及以上,overlay 需内核 3.18 及以上。且目前仅 Docker 社区版支持。条件许可的话,尽量使用 overlay2,与 overlay 相比,它的 inode 利用率更高。
和AUFS的多层不同的是Overlay只有两层:一个upper文件系统和一个lower文件系统,分别代表Docker的容器层和镜像层。当需要修改一个文件时,使用CoW将文件从只读的lower复制到可写的upper进行修改,结果也保存在upper层。在Docker中,底下的只读层就是image,可写层就是Container。结构如下图所示:
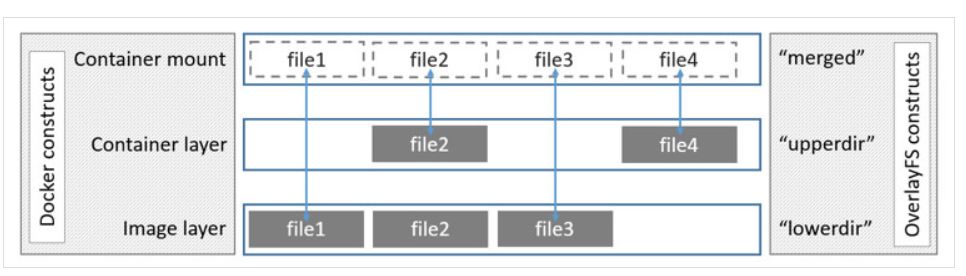
分析
• 从kernel 3.18进入主流Linux内核。设计简单,速度快,比AUFS和Device mapper速度快。在某些情况下,也比Btrfs速度快。是Docker存储方式选择的未来。因为OverlayFS只有两层,不是多层,所以OverlayFS “copy-up”操作快于AUFS。以此可以减少操作延时。
• OverlayFS支持页缓存共享,多个容器访问同一个文件能共享一个页缓存,以此提高内存使用率。
• OverlayFS消耗inode,随着镜像和容器增加,inode会遇到瓶颈。Overlay2能解决这个问题。在Overlay下,为了解决inode问题,可以考虑将/var/lib/docker挂在单独的文件系统上,或者增加系统inode设置。
使用分布式存储
如果OpenStack云平台使用开源的分布式存储系统,如Ceph、GlusterFS等。如何保证存储系统的冗余容灾性、可靠性、安全性和性能,便显得尤为重要。这里,以Ceph开源分布式存储为例进行讲解。
Mon节点和OSD节点部署
一般地,在生产环境中,至少需要部署有3个Ceph Mon节点(数量最好为奇数)以及多个OSD节点。
开启CephX认证
同时,开启CephX认证方式,以提高数据存储的安全性,防范被攻击。如下所示。
# cat /etc/ceph/ceph.conf
[global]
fsid = e10d7336-23e8-4dac-a07a-d012d9208ae1
mon_initial_members = computer1, computer2, computer3
mon_host = 172.17.51.54,172.17.51.55,172.17.51.56
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
………
网络配置
如果Ceph存储节点规模较小,Ceph公共网络(即Public Network)使用千兆网络,集群网络(即Cluster Network)使用万兆网络即可。如果Ceph节点规模较大,且业务负载较高,则尽量都使用万兆网络,在重要的环境上,Ceph公共网络和集群网络,都应该单独分开。需要注意的是,Ceph存储节点使用的网卡,必须要做网卡Bond,防止网卡因故障而导致网络中断。
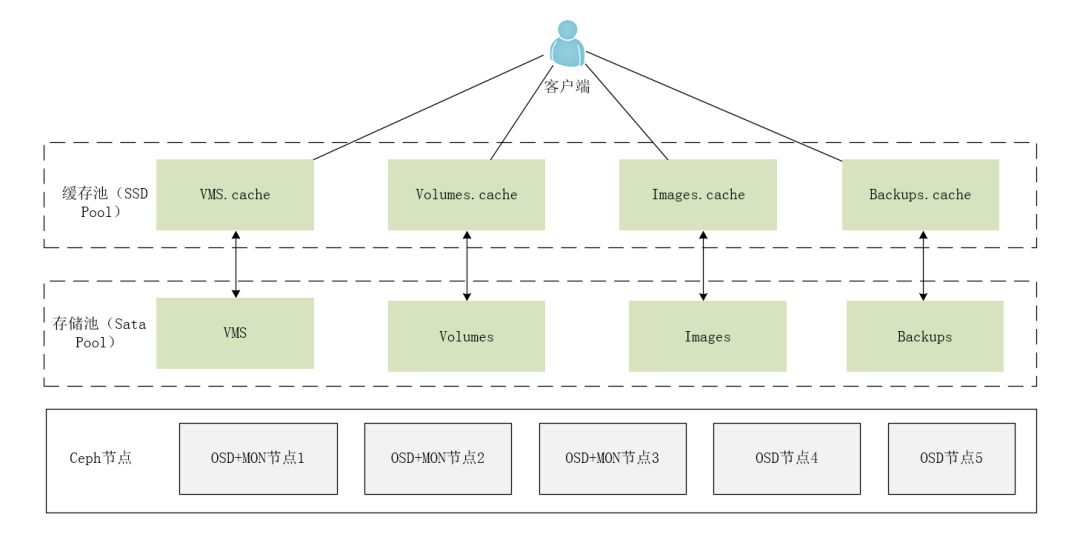
使用Cache Tier
在一个云存储环境中,出于成本的考虑,基本会少量使用SSD硬盘,大量使用SATA硬盘。在OpenStack集成Ceph的云环境中,如何使用SSD和SATA硬盘。一般有两种使用方法。
第一种:分别创建独立的SSD和SATA存储资源集群。然后,Cinder块存储服务对接这两套Ceph后端存储,这样云平台便可以同时创建和使用SSD介质和SATA介质的云硬盘。
第二种:使用SSD硬盘创建容量相对较小但性能高的缓存池(Cache tier),SATA硬盘创建容量大的但性能较低的存储池(Storage tier)。
这里,以第二种方式为例进行讲解。当客户端访问操作数据时,会优先读写cache tier数据(当然要根据cache mode来决定),如果数据在storage tier 则会提升到cache tier中,在cache tier中会有请求命中算法、缓存刷写算法、缓存淘汰算法等,将热数据提升到cache tier中,将冷数据下放到storage tier中。
缓存层代理自动处理缓存层和后端存储之间的数据迁移。在使用过程中,我们可以根据自己的需要,来配置迁移规则,主要有两种场景:
• 回写模式: 管理员把缓存层配置为 writeback 模式时, Ceph 客户端们会把数据写入缓存层、并收到缓存层发来的 ACK ;写入缓存层的数据会被迁移到存储层、然后从缓存层刷掉。直观地看,缓存层位于后端存储层的“前面”,当 Ceph 客户端要读取的数据位于存储层时,缓存层代理会把这些数据迁移到缓存层,然后再发往 Ceph 客户端。从此, Ceph 客户端将与缓存层进行 I/O 操作,直到数据不再被读写。此模式对于易变数据来说较理想(如照片/视频编辑、事务数据等)。
• 只读模式: 管理员把缓存层配置为 readonly 模式时, Ceph 直接把数据写入后端。读取时, Ceph 把相应对象从后端复制到缓存层,根据已定义策略、脏对象会被缓存层踢出。此模式适合不变数据(如社交网络上展示的图片/视频、 DNA 数据、 X-Ray 照片等),因为从缓存层读出的数据可能包含过期数据,即一致性较差。对易变数据不要用 readonly 模式。
独立使用Pool
Ceph可以统一OpenStack Cinder块存储服务(cinder-volume、cinder-backup)、Nova计算服务和Glance镜像服务的后端存储。在生产环境上,建议单独创建4个存储资源池(Pool)以分别对应OpenStack的4种服务存储。同时,每个Pool的副本数建议设置为3份,如下表所示。
Openstack服务 | Ceph存储池 | |
|---|---|---|
Cinder-volumes | volumes | |
Cinder-backups | backups | |
Nova | vms | |
Glance | images |
最后,Ceph分布式存储部署架构,如下图所示。
用户应用层
在相当多的业务中,都会涉及到服务高可用。而一般的高可用的实现都是通过VIP(Vitrual IP)实现。VIP不像IP一样,对应一个实际的网络接口(网卡),它是虚拟出来的IP地址,所以利用其特性可以实现服务的容错和迁移工作。
在常见节点中VIP配置非常简单,没有多大的限制。但OpenStack实例中,一个IP对应一个Port设备。并且Neutron 有“Allowed address pairs”限制,该功能要求 Port 的MAC/IP 相互对应,那么该IP才能连通。对Port设备的进行操作可以实现下面几个功能:
• 一个Port设备添加多组Allowed address Pairs,允许多个IP通过该Port连通。
• 一个IP对应多组MAC地址。
• 一个MAC地址对应多个IP
另外在OpenStack创建的实例中建立VIP并使其能正常工作可以使用下面方法:
• 创建VIP的Port设备(防止该VIP被再次分配)
• 更新Port设备的Allowed address pairs
第一步,创建Port设备
#source admin-openrc.sh //导入租户环境变量
#openstack network list //查看现有网络,从中选择创建port设备的网络
#openstack subnet list //查看网络下存在子网,从中选择port设备所处子网
#openstack port create --network NetWork_Name --fixed-ip subnet=SubNet_Name,
ip-address=IP Port_Name
#openstack port show Port_Name
此时Port设备已经创建,但该Port设备与需要建立VIP的实例没有任何关系,在该实例上创建VIP也是不能工作的。原因在于下面
#neutron port-list |grep Instance-IP //找到需要配置VIP的实例的Port ID
查看该Port的详细信息
#neutron port-show 17b580e8-1733-4e2e-b248-cde4863f4985
此时的allowed_address_pairs为空,就算在该实例中创建VIP,其MAC/IP也是不对应,不能工作的。那么就要进行第二步,即更新Port的allowed_address_pairs信息
#neutron port-update Port-ID --allowed_address_pair list-true type=dict ip_address=IP
例如
#neutron port-update 17b580e8-1733-4e2e-b248-cde4863f4985
--allowed_address_pairs list=true type=dict ip_address=172.24.1.202
现在再来查看实例Port信息
#neutron port-show 17b580e8-1733-4e2e-b248-cde4863f4985
此时在虚拟机中创建VIP,就能够正常工作了。
运维平台建设
监控是整个运维乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供详实的数据用于追查定位问题。目前业界有很多不错的开源产品可供选择。选择一些开源的监控系统,是一个省时省力,效率最高的方案。
使用Kolla容器化部署和管理OpenStack云平台,已成为主流趋势。这里,我们以容器化部署和管理OpenStack云平台为背景,聊聊云平台相关的运维平台建设。
监控目标
我们先来了解什么是监控、监控的重要性以及监控的目标,当然每个人所在的行业不同、公司不同、业务不同、岗位不同,对监控的理解也不同,但是我们需要注意,监控是需要站在公司的业务角度去考虑,而不是针对某个监控技术的使用。
监控的目标,包括:
1)对系统不间断实时监控:实际上是对系统不间断的实时监控(这就是监控); 2)实时反馈系统当前状态:我们监控某个硬件、或者某个系统,都是需要能实时看到当前系统的状态,是正常、异常、或者故障; 3)保证服务可靠性安全性:我们监控的目的就是要保证系统、服务、业务正常运行; 4)保证业务持续稳定运行:如果我们的监控做得很完善,即使出现故障,能第一时间接收到故障报警,在第一时间处理解决,从而保证业务持续性的稳定运行。
监控体系分层
监控有赖于运维各专业条线协同完善,通过将监控体系进行分层、分类,各专业条线再去有重点的丰富监控指标。监控的对象,主要有基础设施硬件类和应用软件类等,如下图所示:
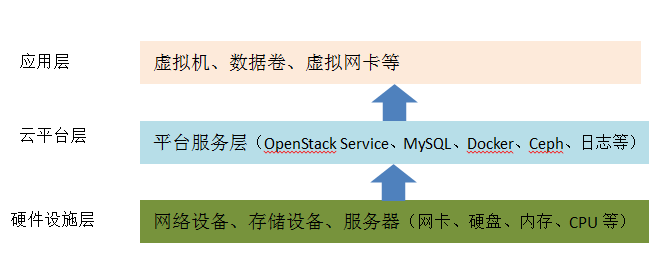
• 硬件设施层:交换机、路由器、负载均衡设备、防火墙、服务器(硬盘、CPU、内存和网卡)等。
• 云平台层:日志、数据库、消息队列、操作系统、OpenStack服务、Ceph存储、Docker容器、系统和应用负载等。
• 应用层:虚拟机、数据卷、虚拟网卡等。
监控手段
通常情况下,随着系统的运行,操作系统会产生系统日志,应用程序会产生应用程序的访问日志、错误日志、运行日志、网络日志,我们可以使用 EFK 来进行日志监控。对于日志监控来说,最常见的需求就是收集、存储、查询、展示。
除了对日志进行监控外,我们还需要对系统和应用的运行状况进行实时监控。不同的监控目标,有不同的监控手段。OpenStack云资源的监控,如虚拟机、镜像、数据卷、虚拟网卡等,天然的可以由OpenStack自带的Ceilometer+Gnocchi+Aodh等服务来做(PS:ceilometer可以将采集数据交给gnocchi做数据聚合,最后用grafana展现报表)。
如果,OpenStack云平台是基于Kolla容器化部署和运行管理的。那么诸如Docker容器、操作系统负载、存储空间等,又该使用什么来运维监控并告警呢。自然,TPIG栈便呼之欲出了。
什么是TPIG栈。即由Telegraf + Influxdb + Grafana + Prometheus组合成的一套运维监控工具集合。它们之间的关系是: Prometheus/Telegraf(收集数据) —-> Influxdb(保存数据) —-> Grafana(显示数据)
说明: Prometheus和Telegraf不是必须同时部署使用的,你可以根据自己的需要,选择二者都部署,也可以二者选其一。
如下几种开源工具或方案,Kolla社区都是默认支持的。最重要的是,如何去使用、完善它们。
• 日志收集和分析处理的开源方案有EFK栈:fluentd/filebeat + elasticsearch +kibana
• 性能采集和分析处理的开源方案有TPIG栈:telegraf + influxdb + grafana + Prometheus
监控方法
了解监控对象:我们要监控的对象你是否了解呢?比如硬盘的IOPS? 对象性能指标:我们要监控这个东西的什么属性?比如 CPU 的使用率、负载、用户态、内核态、上下文切换。 报警阈值定义:怎么样才算是故障,要报警呢?比如 CPU 的负载到底多少算高,用户态、内核态分别跑多少算高? 故障处理流程:收到了故障报警,我们怎么处理呢?有什么更高效的处理流程吗?
监控流程
• 数据采集:通过telegraf/Prometheus等对系统和应用进行数据采集;
• 数据存储:监控数据存储在MySQL、influxdb上,也可以存储在其他数据库中;
• 数据分析:当我们事后需要分析故障时,EFK栈 能给我们提供图形以及时间等相关信息,方面我们确定故障所在;
• 数据展示:web 界面展示;
• 监控报警:电话报警、邮件报警、微信报警、短信报警、报警升级机制等(无论什么报警都可以);
• 报警处理:当接收到报警,我们需要根据故障的级别进行处理,比如:重要紧急、重要不紧急等。根据故障的级别,配合相关的人员进行快速处理;
监控告警
当监控的对象超过了某一阈值或者某一服务出现了异常时,便自动发送邮件、短信或微信给相关人员进行告警。
事件应急响应
运维最基本的指标就是保证系统的可用性,应急恢复的时效性是系统可用性的关键指标。通常来讲应急恢复的方法有不少,比如:
• 服务整体性能下降或异常,可以考虑重启服务;
• 应用做过变更,可以考虑是否需要回切变更;
• 资源不足,可以考虑应急扩容;
• 应用性能问题,可以考虑调整应用参数、日志参数;
• 数据库繁忙,可以考虑通过数据库快照分析,优化SQL;
• 应用功能设计有误,可以考虑紧急关闭功能菜单;
• 还有很多……
一些所见所想
现实中,不乏遇到一些拿来主义。即将Hadoop/Spark大数据业务跑在虚拟机中运行,然后到了线上出现各种坑。如磁盘IO性能非常差,虚拟机抢占宿主机资源,导致其CPU使用率超过700%等等,最后掉入自己挖的坑里。
须知,云计算的本质是虚拟化,虚拟化的本质是一虚多,即将一个个物理的计算资源、网络资源和存储资源等虚拟化成多个逻辑资源(如KVM、openvswitch、ceph),再由资源调度管理系统(如OpenStack)抽象化提供给用户使用。而大数据的本质是多虚一,将多个计算、存储和网络资源统一管理集中起来提供给大数据业务使用。
OpenStack可以统一管理虚拟机和裸机。推荐的做法应是将大数据放在裸机上跑,而不是放在虚拟机上跑。违背了技术的本质,注定过程会很痛苦。
有的用户在上云或用云过程中,时常会纠结到底使用什么方案才好?比如使用OpenvSwitch还是LinuxBridge?使用VLAN还是VXLAN、GRE?使用Ceph还是GlusterFS、商业存储?要不要做二次开发等?须知,从来不是技术决定需求,而是需求决定技术选型。同样的,选择使用什么技术,应该由你的实际需求来决定。适合自己的才是最好的。只能说二者各有优缺点,用户需要做的是根据实际需求,规避掉风险点最大的,选择优势最明显的那个方案。
在准备使用OpenStack时,一定要明确OpenStack是一个知识密集型的开源云框架,记住是一个框架,而不是一个开箱即用的产品。所需要的各方面技术人才和技术储备是非常广泛的,企业通常会面临人才缺乏问题,一方面很难从外部招到有经验的人,另一方面是企业培养内部人才耗时耗力。如果企业只是将OpenStack做私有云供自己使用,功能需求或业务并不复杂,比如用来代替价格昂贵的VMware提供虚拟机业务,那么一般不需要进行二次开发。反之,将OpenStack作为一个云产品提供给第三方用户使用或者满足自身复杂业务需求,那么进行二次开发是必要的,比如统一云资源管理、资源逻辑调度、运维监控告警、Iaas+PaaS+SaaS统一支持等。实际中,一些企业负责人把OpenStack定位成阿里云、AWS来开发,要么是高估了自己的能力,要么是低估了OpenStack的难度,觉得只是修改一个Dashboard而已,最后陷入死循环。
最后
随着技术的演化,平台复杂化+用户简单化的趋势将越来越明显。这就要求最终呈现给用户使用的系统必须是极简的。我相信,OpenStack朝着这方面努力,把企业用户的刚需转变为现实可操作性,前途会更光明!
最后,感谢OpenStack和引领我入门的前公司领导和同事,为我打开了一扇走进云计算的大门!同时也希望,有那么一日,OpenStack云计算能从大企业才能享用的舶来品,进入寻常企业家。
OpenStack正值青年,有理由一路走下去!
>>> Sammy写在最后:
我对徐超不是那么熟悉,但对他印象最深刻的是,刚毕业没两年,居然就出了一本OpenStack书。这让我们这些毕业十几年一书无成的人情何以堪啊!因此,可以看出来,徐超做技术非常认真和专注。这文章也写得非常认真,思路和调理非常清晰。这小伙前途无量啊,赞!其实,OpenStack如果也想前途无量,安心做该做的技术才是王道。
谢谢您的阅读
作者介绍:
徐超,OpenStack、Kubernetes、Docker、CI/CD从业者和学习者,《OpenStack最佳实践-测试与CI/CD》一书作者,OpenStack开源社区参与者。个人博客:https://xuchao918.github.io