- 前言:这里开始涉及到数据处理,例如给你几千行几千列的数据,对这些数据进行分类聚合
- 排序 sort_index sort_values
- 参数:ascending =False 倒序 axis=1 行索引 一般情况下对Series 值进行排序比较多
- 索引排序
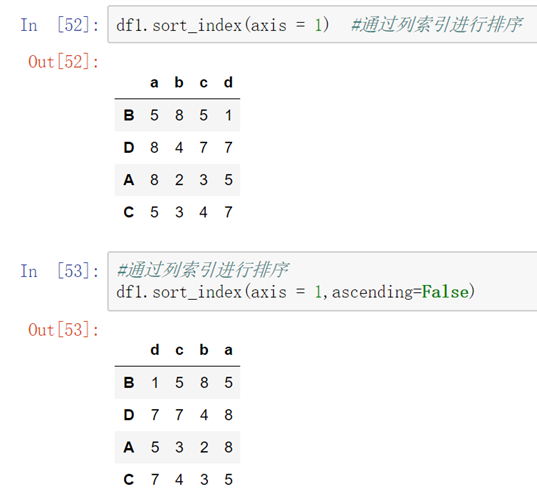
image.png
- 值排序 参数 默认对列值进行排序,加上by=" ",某一列 ascending =False倒序
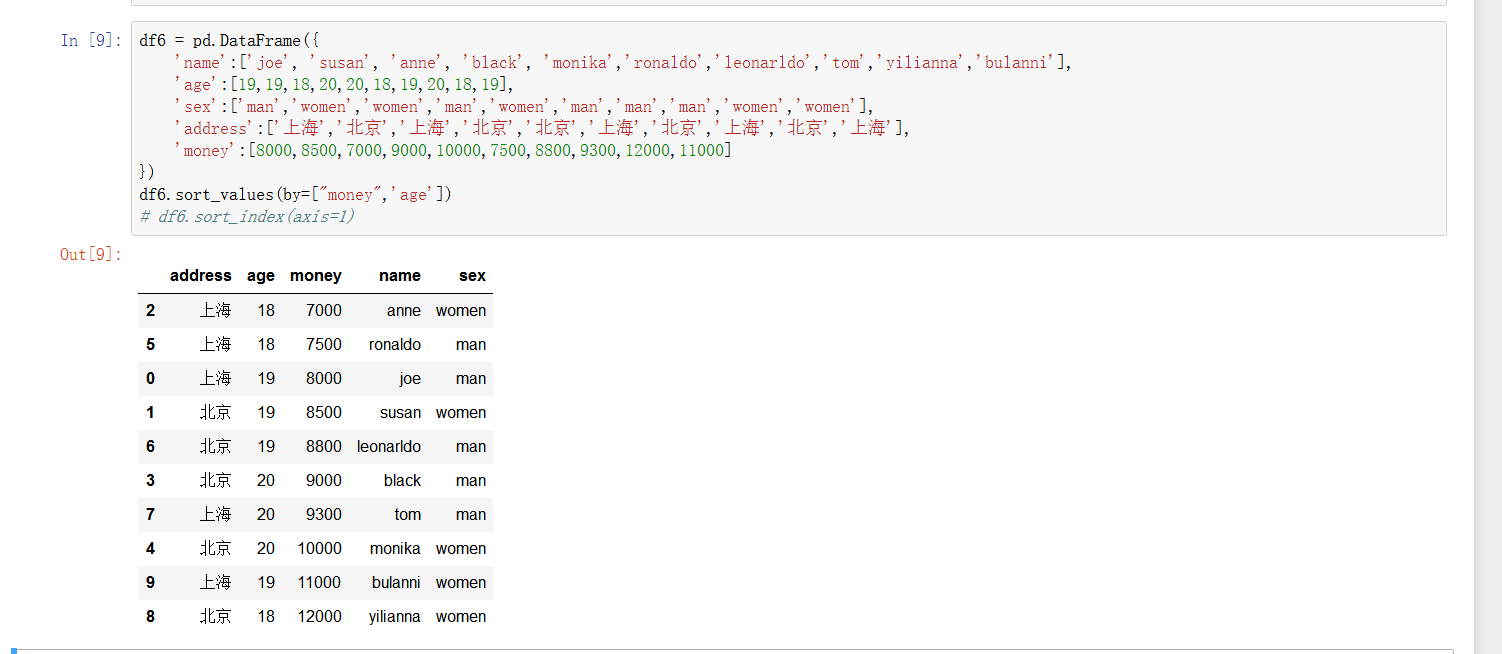
image.png
- rank 参数:method=“first”,默认按列进行排序
- 值计数value_counts
对值进行出现的次数统计
- groupby分组
返回一个可迭代对象,每次迭代结果是一个元组
参数:某一列的索引
取某一列,按照某一列进行排序。
代码语言:javascript
复制
s=df6[["name",'money']].groupby(df6["address"])
for i in s:
print(i)对这个可迭代对象就行聚合 .mean()
- apply聚合
类似于map()
参数:函数
代码语言:javascript
复制
行重新命名:df.columns=[" "]
把两个df合并:pd.concat([df1,df2])
new_ave=df.replace(0,int(averge))
list1=list(new_ave.columns)
list1.remove("Id")
list1.remove("zwyx")
list1
new_d=DataFrame([])
for i in list1:
d=new_ave[i].value_counts()
n_d=DataFrame(d)
n_d.columns=['values']
new_d = pd.concat([new_d,n_d])
new_d代码语言:javascript
复制
# 在 2010 年至 2012 年间人口平均量是怎么样的
df1 = pd.read_csv("census.csv")
df1 = df1[df1["SUMLEV"]==50]
def f(x):
pe= x[['ESTIMATESBASE2010','RDOMESTICMIG2011','RDOMESTICMIG2012']]
return pd.Series([x['CTYNAME'],pe.mean()])#把得到的结果也进行Series,更好看
df1.apply(f,axis=1)我的机器学习pandas篇
我的机器学习matplotlib篇
我的机器学习numpy篇*