点击蓝字 关注我们
导语
负载均衡(Cloud Load Balancer,CLB)提供安全快捷的流量分发服务,访问流量经由 CLB 可以自动分配到云中的多台云服务器上,扩展系统的服务能力并消除单点故障。负载均衡支持亿级连接和千万级并发,可轻松应对大流量访问,满足业务需求。
CLB 访问日志当前支持基于 7 层负载均衡,访问日志内容丰富,可以涵盖多种场景的内容。
「CLS数据淘金第一期」介绍过 CLB 两大主要场景:运维监控场景与运营统计场景;本期我们将对运维监控场景做进一步的补充,并将重磅推出腾讯云 CLB 日志降本增效的独家利器 - CLB 日志抽样。
运维监控场景
请求 QPS 趋势对比
系统的性能和可用性对在线业务来说至关重要,如在网站或应用程序流量激增时,需要确保系统能够承受负载并提供稳定的性能;在线上支付、金融交易等场景中,需要确保系统在高负载情况下仍能保持高可用性和可靠性。
为了实现这些目标,我们需要监控每秒请求率(QPS)以确保在请求率陡增时能够及时感知并采取相应措施。通过结合 CLB 访问日志和 CLS 时序仪表盘,我们可以使用 SQL 分析语句查看每个时间点的请求 QPS ,并通过趋势图清晰的展示出来。
QPS趋势分析SQL语句:
* | select histogram(cast(__TIMESTAMP__ as timestamp),interval 1 second) as time, count(*) as "QPS" group by time order by time desc limit 10000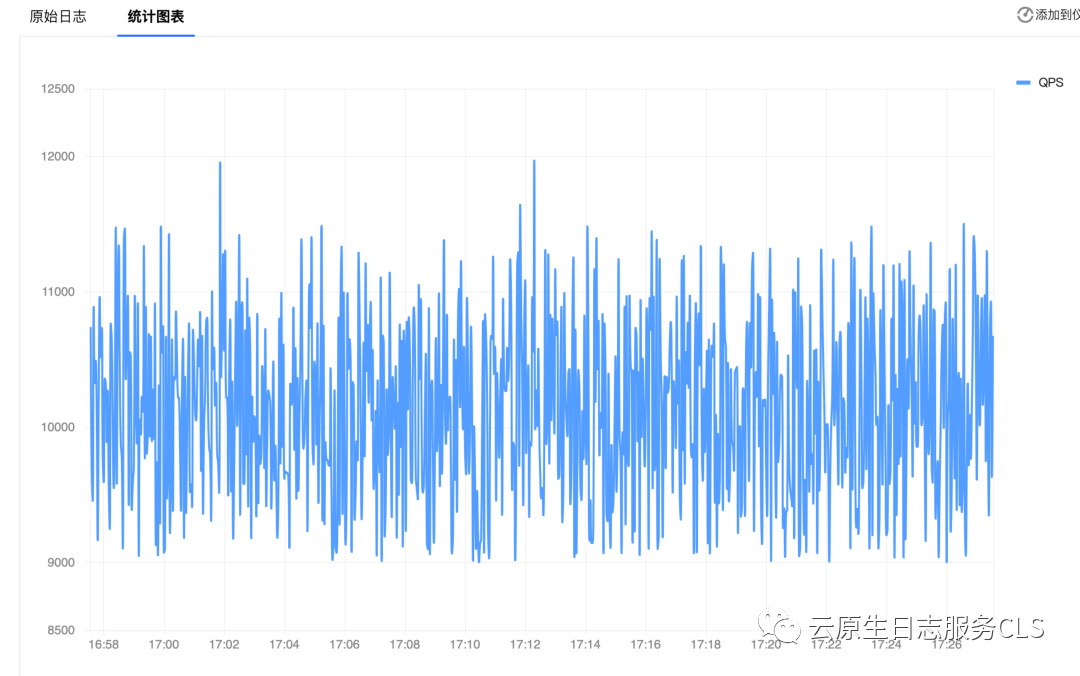
QPS趋势图
而对于某些业务来说,QPS 的提高可能不是瞬间发生的,我们就需要通过比较更早的趋势来判断当前周期内的 QPS 是否整体高于过去历史趋势。通过 CLS 时序仪表盘内置的环比功能,我们可以比较不同时间维度下(例如环比1天/7天/前1小时)的 QPS 变化趋势,以判断是否需要整体提高请求处理性能以满足用户请求整体量的提升。
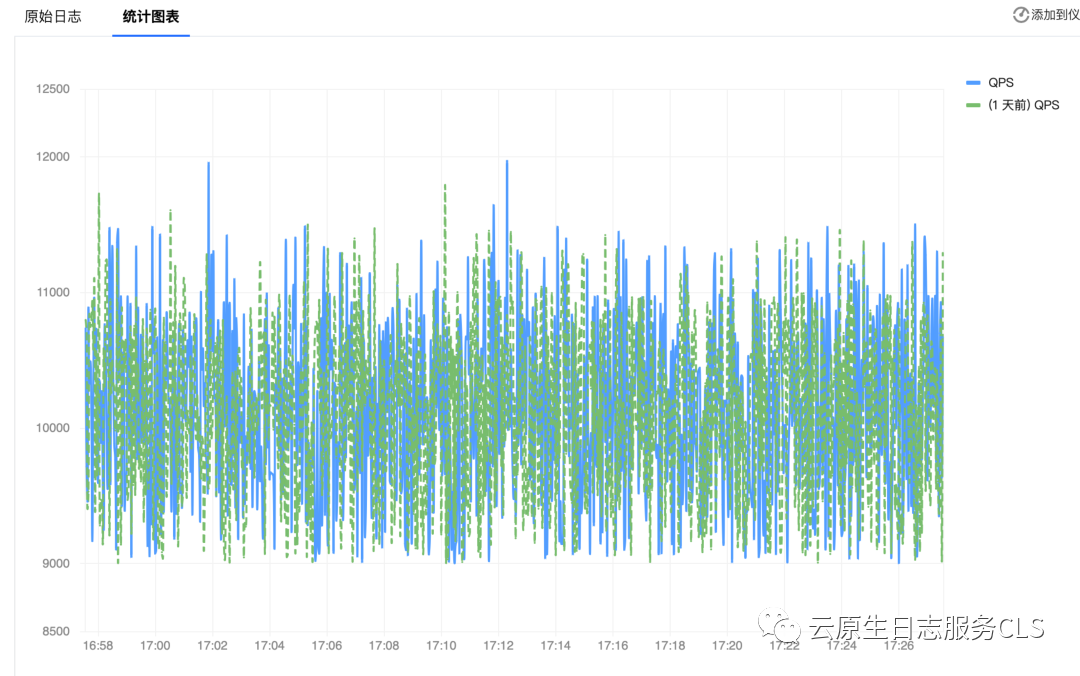
QPS同环比趋势图
请求耗时分布趋势
一般而言一条服务请求链路由客户端、CLB 和服务器组成。在该过程中,不同类型的延迟影响着整个请求的处理时间,例如网络延迟、CLB 本身处理时间和 RS 处理时间等。因此,当一条请求的总处理时间超过平均水平时,我们需要进一步定位是请求链路中的哪个环节出现了异常延迟,以便有针对性地分析并修复延迟点。
CLB 访问日志中针对每一条访问记录提供以下了多种耗时数据:

我们也可以从以下拓扑图进一步理解这些耗时数据:
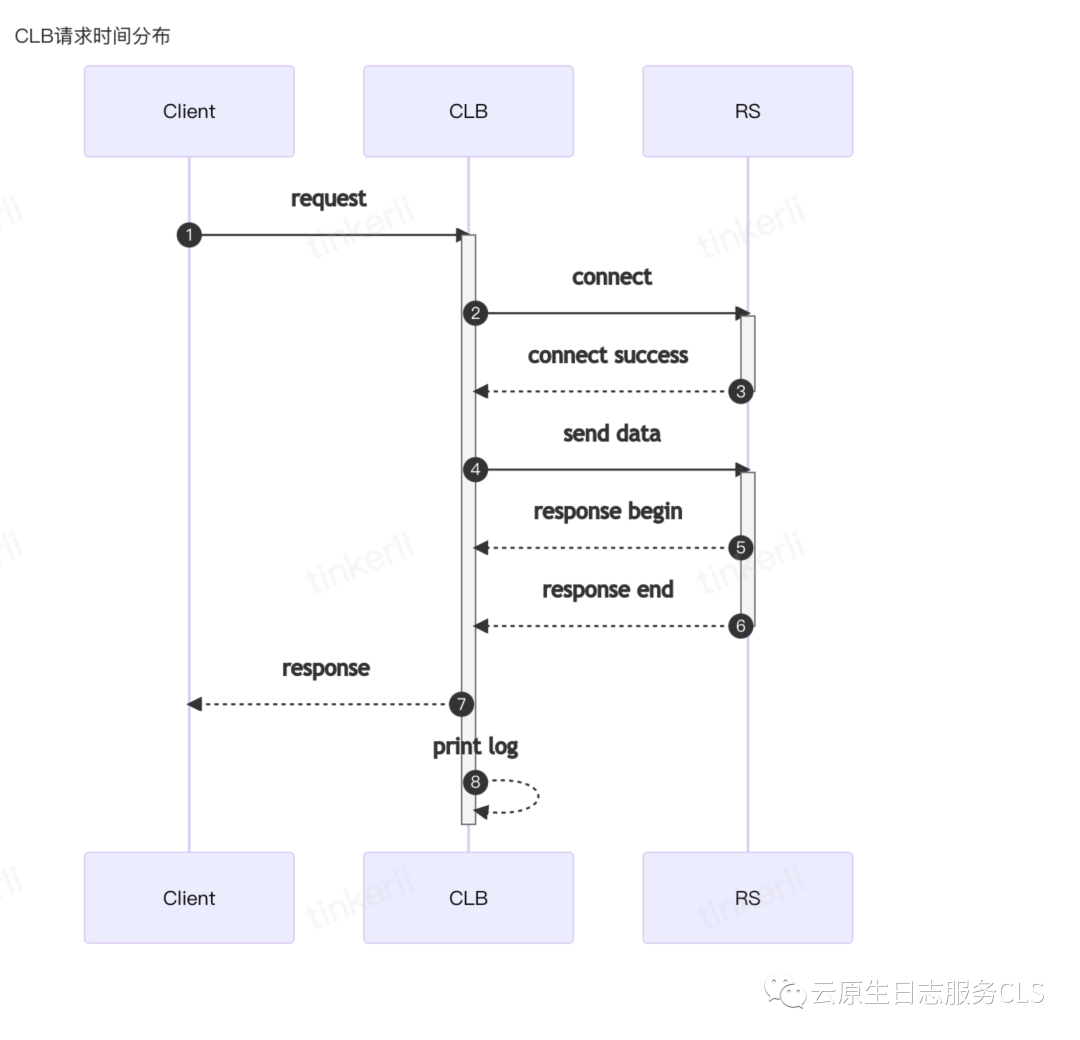
基于以上图片, CLB访问日志中记录的不同耗时数据分别代表:
request_time:编号1-8 的时间
upstream_connect_time:编号2-3的时间
upstream_header_time:编号2-5的时间
upstream_response_time:编号2-6的时间
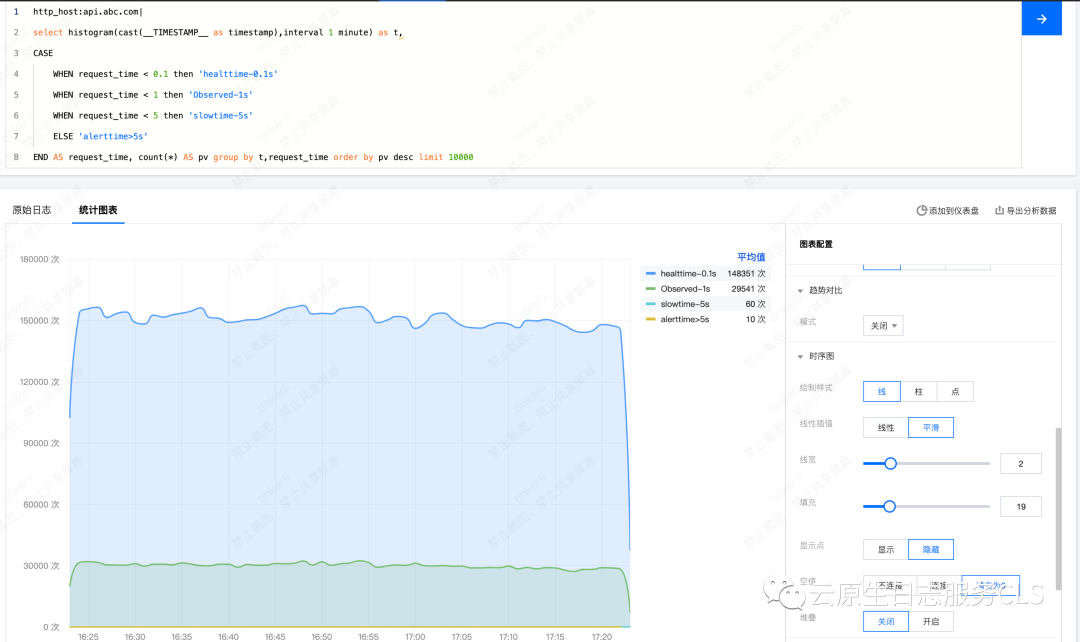
明白了 CLB 访问日志中不同耗时记录的含义, 我们可以使用以下 SQL 分语句对 CLB 访问日志的耗时记录做进一步的计算与趋势分析:
* | select histogram(cast(__TIMESTAMP__ as timestamp),interval 1 minute) as t,round((avg(request_time) - avg(upstream_response_time))*1000,2) as lb_time, round((avg(upstream_header_time) - avg(upstream_connect_time))*1000,2) as sszie_time,round((avg(upstream_response_time) - avg(upstream_header_time))*1000,2) as bigsize_time, round(avg(upstream_connect_time)*1000,2) as net_time,round(avg(request_time)*1000,2) as request_time group by t order by t desc limit 10000- 通过计算 request_time 与 upstream_response_time 之间的差并命名为 lb_time, 我们可以得知 CLB 处理请求的耗时。通常如果 lb_time 过高, 说明 CLB 实例存在问题。
- 通过计算 upstream_header_time 与 upstream_connect_time 之间的差并命名为 sszie_time, 我们可以得知请求从 CLB 到到服务器的耗时。通常如果 sszie_time 过高, 有可能是 POST 上传大文件时本身业务逻辑耗时就长。
- 通过计算 upstream_response_time 与 upstream_header_time 之间的差并命名 bigsize_time, 我们可以得知响应从服务端到到 CLB 的耗时。通常如果 bigsize_time 过高, 大概率是 GET 请求的数据量较大,导致较高的传输与处理耗时。
- 通过 upstream_connect_time, 我们可以得知 CLB 和后端建立 TCP 连接所花费时间。如果这个时间高, 有可能是网络丢包,或者连接 RS 不上。
基于上述定义, 我们使用 CLS 仪表盘中的趋势图将 SQL 语句分析结果展示出来。这样, 我们就可以清晰的看到不同环节的耗时情况, 并在任意环节的耗时异常增加时第一时间感知。
降本增效大利器
对于多数企业来说,当用户数量不断增长时、成本也会相应提高。特别是在一些热门服务场景中,服务请求量可能达到上亿级别,导致负载均衡访问日志数量增加数倍。在这种情况下,在不影响基于 CLB 访问日志进行运维分析的前提下实现降本、增效两手抓成为了紧迫的需求。
CLB 访问日志通常用于请求态势分析,但对于多数业务来说、全量日志不是必需的。通过对 CLB 访问日志进行随机抽样,我们也可以了解当前服务请求的响应情况。为此,CLS 与 CLB 联合推出了业界独有日志抽样采集的功能,通过设置一定的抽样比例,不仅不影响整体的统计结果,而且还大大降低了采集总量,实现了在保证运维分析结果准确性的同时,用户 TCO 成本随抽样比例线性下降。
CLB 日志采集抽样比配置方法如下:

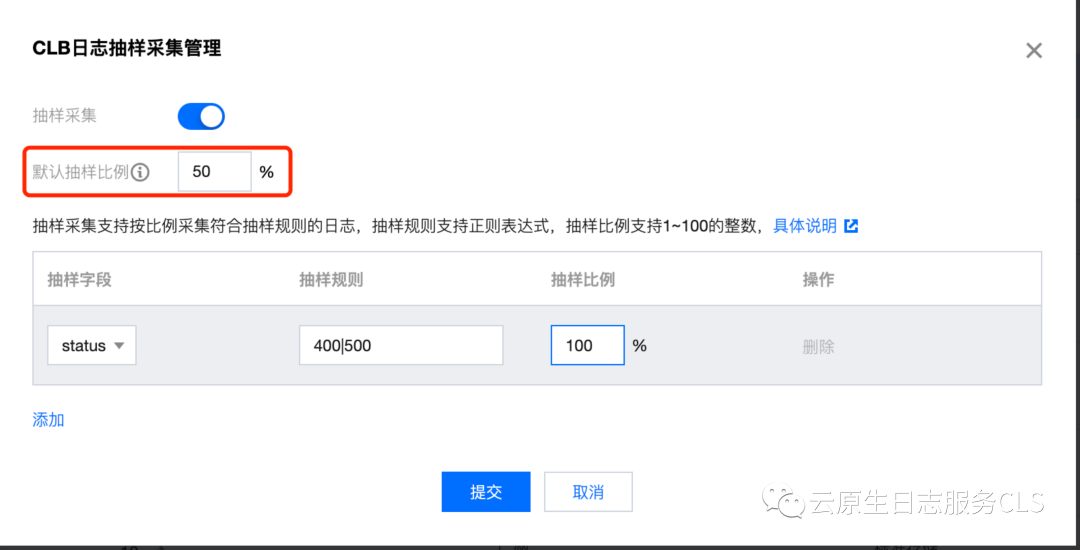
图中,「默认抽样比例」为对 CLB 整体日志的抽样率,如设置50%、系统将按照50%的比例每两条日志上报一条。这样就能极大地减少冗余日志数,在保证整体统计结果的前提下,降低日志采集成本。
然而,用户可能会担心另一个问题:在抽样采集的场景下,如何确保针对重要的错误日志实现高保真采集,同时仍能进行其他日志的抽样采集?
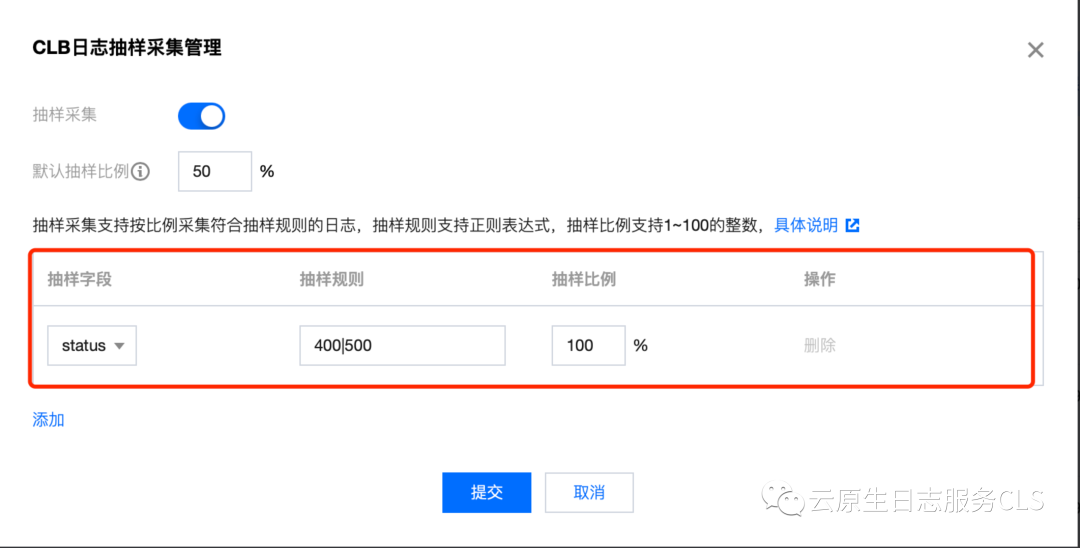
针对这种情况,CLS提供了完善的解决方案。CLS支持在整体抽样比的基础上,还可以配置个性化的特定过滤条件。例如,可以将状态为400或500的异常情况进行过滤,并将抽样比设置为100%,以确保重要的日志完全被采集上来。
结语
不论是运维监控场景亦或是运营统计,CLB + CLS 的强强组合的目的、都是竭尽所能为用户创造最大化价值;CLB 日志抽样采集管理功能,支持用户根据自身业务状态、自定义设置抽样采集比例,有效提升了日志价值密度、降低日志采集成本;对于某些业务场景,CLS 还支持个性化的特定条件抽样比,保证用户关键日志完整采集不丢失。
产品使用问题、技术咨询欢迎加入 CLS 粉丝群,直接跟日志专家 1v1 对话,更有超多粉丝福利,快来加入我们吧。

更多日志服务相关前沿技术与实现、产品动态,戳下方关注腾讯云 CLS 公众号。
往期推荐:
【CLS 数据淘金第一期】CLB 日志可视化分析大洞察
【CLS数据淘金第二期】云原生日志服务之 TKE 运维指北
【CLS数据淘金第三期】CDN访问日志质量分析
【CLS数据淘金第四期】网络流日志-云联网日志分析