GPU环境准备
GPU服务器选择
目前云服务厂商基本都有售卖GPU云服务器,在腾讯云上,登录这个网址:
https://cloud.tencent.com/product/gpu
点击【立即选购】可以进入选购页面。每种机型又对应不同的规格。基本上同机型(比如GN7)他们的显卡型号都是相同的,该机型下的不同规格(比如GN7.LARGE20、GN7.2XLARGE32)只是在CPU、内存、带宽以及显卡个数方面不同而已。下面简单列一下机型与显卡的对应关系(截至2022年5月):
机型 | 显卡 |
|---|---|
GN6 | Tesla P4 |
GN6S | Tesla P4 |
GN7 | NVIDIA T4 |
GN8 | Tesla P40 |
GN10X | Tesla V100 |
GN10Xp | Tesla V100 |
GI3X | NVIDIA T4 |
GT4 | NVIDIA A100 |
GI1 | Intel SG1加速卡 |
显卡型号知识
我们忽略Intel的那个,其余的显卡都是NVIDIA(英伟达)的显卡,也就是常说的N卡。NVIDIA牢牢抓住了人工智能爆发的浪潮,推出了CUDA、TensorRT等一系列开发框架,为GPU编程提供了便利,黄仁勋也因此赚的盆满钵满。
这里面没有我们日常所说的Geforce系列的GTX、RTX那种显卡。因为Geforce系列是桌面端的(笔记本/台式机)显卡,而这里面显卡是服务端(数据中心/工作站)的显卡。就好比我们个人电脑上的CPU是Intel酷睿(Core)系列,而公司服务器上的CPU是Intel至强(Xeon)系列。
当然并不能说服务端的这些显卡就一定比桌面端的显卡性能更好,具体还是要看算力,显卡的算力信息可以在NVIDIA的官网上查到:
https://developer.nvidia.com/cuda-gpus
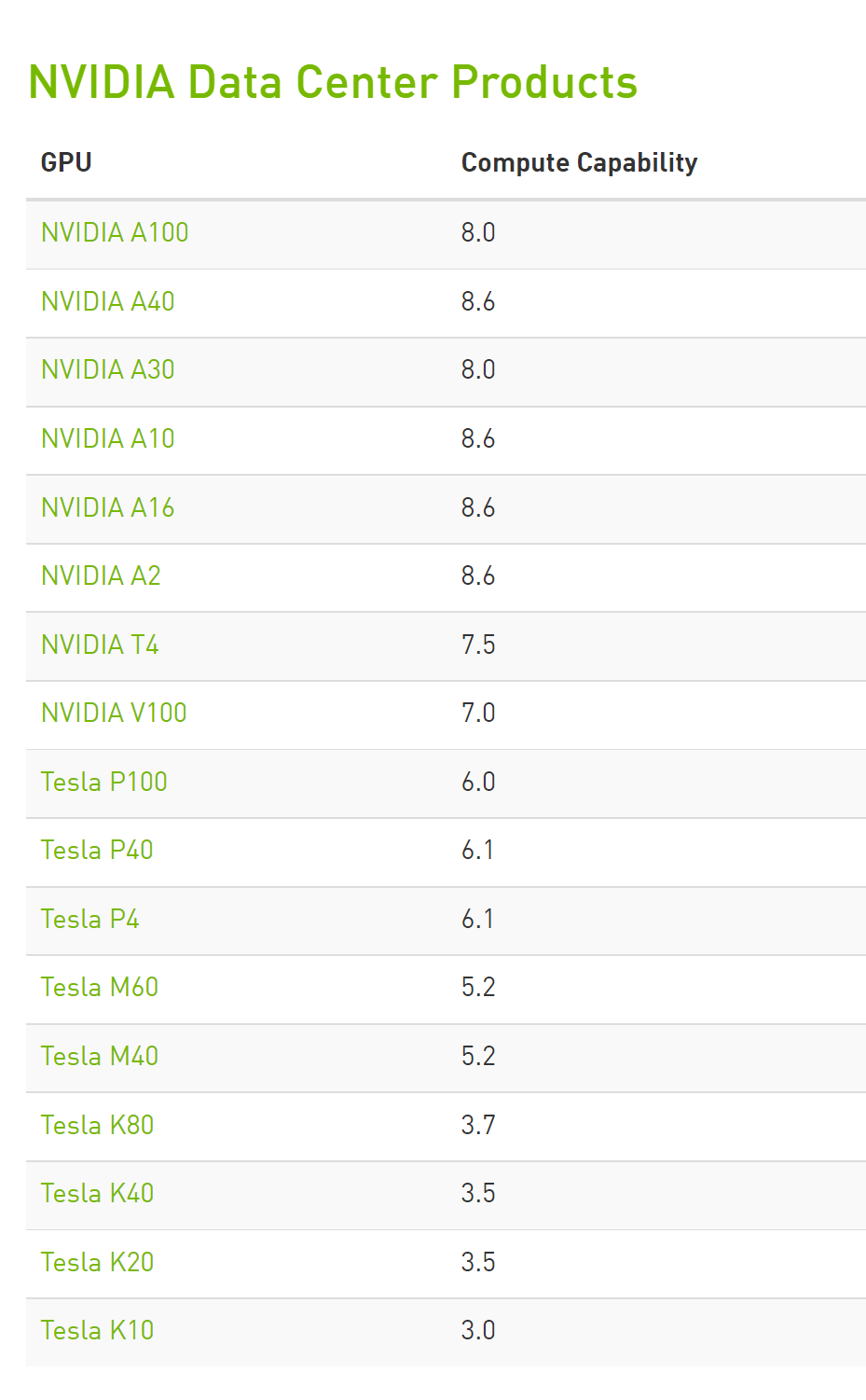
我的显卡是Tesla T4,算力是7.5。
好了,让我们略过服务器选购的具体细节,其实这一步最大的阻碍不是算力,而是钱啦。也略过云服务器初始化的步骤,那和普通的云服务器没有差别,都是选择一台Linux然后初始化一些配置而已。
另外如果你没有购买云服务器,而是有一个装有N卡的个人电脑,那么下面的内容同样适用于你。
驱动安装
新的GPU服务器虽然有显卡,但是是没有显卡驱动的。这里需要我们手动安装一下。首先去NVIDIA官网去下载驱动:
https://www.nvidia.cn/Download/index.aspx?lang=cn
主要根据你的系统类型以及你的显卡型号(产品系列与产品家族)来选择:

点【搜索】

点【下载】

这一步不用点【下载】,因为我们是给云服务器(或者你本地的Linux虚拟机)安装显卡。所以右键复制下载链接,然后再服务器上wget下载,然后运行:
wget https://cn.download.nvidia.com/tesla/510.47.03/NVIDIA-Linux-x86_64-510.47.03.runchmod a+x NVIDIA-Linux-x86_64-510.47.03.run
./NVIDIA-Linux-x86_64-510.47.03.run
执行以后就会开始安装,期间可能收到提示:服务器上gcc版本(比如gcc8.5)和编译kernel的gcc版本(比如gcc8.4)不一致的警告。版本号差异不大的话就忽略,否则可能需要重新安装一个同版本的gcc编译器。
执行完成后怎么确认驱动安装是OK的呢?我们可以执行一下nvidia-smi这个命令。
nvidia-smi
输出如下:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA Tesla T4 On | 00000000:00:08.0 Off | 0 |
| N/A 62C P8 10W / 70W | 3MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
能展示出信息,就是驱动安装OK了。怎么来解读这个信息呢。以中间的空行分隔,可以把整个信息分成三个部分。
先说第一部分,也就是第一行:
- nvidia-smi命令的版本
- 显卡驱动的版本
- cuda的版本
第二部分,也就是第二行到空行之间的部分,这是一个显卡新的表格,===这行上面是表头,下面是表数据。这里只有一张显卡,如果有多张显卡,下面会追加几行。上图的第二部分,我换个形式会更好理解:
表头 | 数据 | 含义 |
|---|---|---|
GPU | 0 | 显卡ID,从0计数 |
Fan | N/A | 风扇转速 |
Name | Tesla T4 | 显卡型号 |
Temp | 62C | 温度 |
Perf | P8 | 性能级别,从大到小为P0~P12 |
Persistence-M | Off | 是否是持续模式 |
Pwr:Usage/Cap | 10W / 70W | 能耗 |
Bus-Id | 00000000:00:08.0 | GPU总线ID |
Disap.A | Off | Disaplay Active,GPU的显示是否初始化 |
Memory-Usage | 0MiB/15109MiB | 显存使用率 |
Volatile GPU-Util | 0 | GPU利用率 |
Uncorr. ECC | 0 | ECC,错误检查与纠正 |
Compute M. | Default | 计算模式 |
MIG M. | N/A | MIG模式 |
Persistence-M(持续模式)开启之后能耗会增加,但是新GPU程序启动的耗时会减少。如果它的状态是Off,可以使用这个命令来开启:
nvidia-smi -pm 1注意Memory-Usage(显存使用率)和GPU-Util(GPU利用率)没有必要联系。就好比内存使用率和CPU的使用率也没有必然联系一样!
MIG M.是一个比较新的数据,在老版本的nvidia-smi上是没有这个信息的,对我们来说不用特别关注,感兴趣的可以阅读:
https://docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html
nvidia-smi的第三部分,比较好理解,就是当前使用了GPU的进程信息。由于我们还没有使用GPU跑程序,所以这里是空的:
表头 | 含义 |
|---|---|
GPU | 显卡ID |
PID | 进程ID |
TYPE | 类型。C:计算进程,G:图形进程,C+G:计算与图形都有 |
Process name | 进程名 |
GPU Memory Usage | 进程的显卡使用率 |
GI ID、CI ID目前没找到资料,这个也是新版本nvidia-smi新加的,旧版本都是没有的。暂时忽略。
跑一个机器学习任务
conda安装
说到机器学习,自然少不了python。而conda也少不了。conda是一个python的环境管理器,也包含包管理功能,比pip更强大。一般有图形界面的个人电脑上装Anaconda比较好,因为有GUI,各种操作比较方便。但是云服务器上就没必要装Anaconda了,直接装无图形界面miniconda就好了。地址如下:
https://docs.conda.io/en/latest/miniconda.html
同样使用右键复制下来下载地址,然后在服务器上下载并执行:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.shchmod a+x Miniconda3-latest-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh
这也就完成了安装,接着加载一下环境变量。
比如:
source ~/.bashrc或者
source ~/.zshrc添加国内conda源
可以给conda添加国内的源来加快下载速度。比如清华的源。之前也有中科大的源,目前好像已经失效了。
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/创建一个conda环境
接下来我们要跑pytorch程序,所以使用conda创建一个环境,名称任意,我这里叫 pytorch_gpu
conda create -n pytorch_gpu
conda activate pytorch_gpu
目前是一个空环境,还没有安装pytorch
安装pytorch
执行如下命令,来安装pytorch及其依赖环境:
conda install pytorch torchvision torchaudio cudatoolkit=11.3实际本机cuda是11.6,但是pytorch当前(2022年5月)最新的还是11.3。应该没关系。后续大家动态调整适合的版本即可。
也可以参考官网的指引:
https://pytorch.org/get-started/locally/
选择相应的环境,会生成对应的命令。

但官网上的conda命令还有一个 -c pytorch。-c是指定一个conda channel的意思,这里表示指定pytorch的channel,但是这个channel下载太慢了,实测去掉-c pytorch会使得下载提速。
conda命令完成执行,测试是否安装成功。可以编写如下python脚本来执行,或者直接打开python交互式命令:
import torch
print(torch.cuda.is_available())import能成功,并且第二行代码返回True。表示安装成功,并且是支持GPU的pytorch。
训练模型
由于我本人并不是机器学习方面的专家,所以我决定直接网上找一个能用的pytorch训练模型的代码。这里我选择了BERT模型,BERT模型是谷歌提出的一个NLP领域的经典模型。这里不展开这些背景知识。
经过一番简单的搜索,我在Github上找到了这个排名比较靠前的pytorch bert相关的项目:
https://github.com/649453932/Bert-Chinese-Text-Classification-Pytorch
将项目clone下来,然后依据README,下载所需要的数据文件:一个是预训练的pytorch模型文件bert-base-chinese.tar.gz,另外一个是词典文件bert-base-chinese-vocab.txt。
模型文件解压后其实得到2个文件,一个是二进制的模型文件本身pytorch_model.bin,另外一个是模型的配置文件bert_config.json。都拷贝到项目的bert_pretrain目录中。词典文件改名成vocab.txt也放到bert_pretrain目录中。
在正式使用之前,我们在环境中再安装几个依赖的库:
conda install scikit-learn boto3 regex tqdm接着创建一个目录:
mkdir -p THUCNews/saved_dictBERT模型的训练过程一般分为预训练(Pre-training)+ 微调(Fine-tuning)两步。我们下载的模型已经是预训练模型了,但他还不是最终的模型,还需要继续训练,也就是微调。
运行脚本,开始训练:
python run.py --model bert这一步其实挺慢的。原作者说他2080Ti的显卡,要跑20分钟。
2080Ti是桌面端的显卡,通过前文提到的算力查看网站,能看到2080Ti的算力是7.5,比我云服务器的Tesla P4还高……

我们此时可以再次执行nvidia-smi命令来查看一下:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA Tesla T4 On | 00000000:00:08.0 Off | 0 |
| N/A 71C P0 67W / 70W | 7106MiB / 15109MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 11742 C python 7103MiB |
可以发现第三部分的进程信息不再是空了,能看到一个PID为11742的进程在使用GPU,进程名是python占用显存7103MB。总的Memory-Usage是7106MB。二者几乎一样,虽然显存只用了一半,但GPU利用率(Gpu-Util)已经到达100%了。性能等级也变成了P0。
最终在我的云服务器上跑了60分钟…… 好吧。
模型预测
上面的脚本执行完成后,会训练出一个最终的模型,保存到THUCNews/saved_dict/bert.ckpt中。
接下来我们尝试使用这个模型做一下预测。原项目中作者没有封装预测的代码,但我们可以从项目issue中找到其他人分享的预测代码。比如这个:Issue #72 · 649453932/Bert-Chinese-Text-Classification-Pytorch
把代码复制下来保存成 pred.py 。
另外这个issue中的预测代码运行过程中可能报这个错
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0
and cpu! (when checking argument for argument index in method wrapper__index_select)
同样参考issue中其他网友提供的解决方案。修改build_predict_text() 方法中的ids、token、mask的代码,加上.cuda()即可:
ids = torch.LongTensor([token_ids]).cuda()
seq_len = torch.LongTensor([seq_len]).cuda()
mask = torch.LongTensor([mask]).cuda()由于训练模型时用的数据集是新闻及其分类,所以模型的预测功能就是对新闻做分类。现在我们找一条最近的新闻来做一下预测。
热搜里找到一条新闻:【兰州野生动物园观光车侧翻事故新进展:2人经抢救无效死亡】新闻时间是2022年5月2日,模型训练用的数据集是2019年的,所以肯定不包含这条新闻。让我们来看看它能不能准确分类。修改main函数:
if name == 'main':
print(predict("兰州野生动物园观光车侧翻事故新进展:2人经抢救无效死亡"))运行一下我们的pred.py得到结果:
society
也就是社会新闻,还是比较准的。