生产环境使用数据库最怕的就是数据丢失了,下面针对各种数据丢失场景展开。
场景一:人为操作引起,包括:故意的删库跑路、手抖误操作。
应对方法:
- 有备无患,建立备份恢复体系,包括:每天自动备份、备份文件存到另外一台机器、备份文件无法删除(dba无备份文件删除权限)、从备份文件和binlog恢复数据。所以不要用云服务器自建数据库,而是直接使用云数据库,云数据库已经把这些都做好了,没必要去把别人踩过的坑再踩一遍。
- 做好监控,第一时间发现事故。可以是业务程序读写数据库异常时报警,也可以专门写监控程序监控全部表是否可读。
- 日常容灾演练,事故发生后不至于手忙脚乱。包括:数据恢复操作文档化、流程化,每个月或每个季度,在腾讯云测试环境练习一次。本文末尾附上腾讯云数据恢复操作方法。
- 做好权限管理,按最小化原则,只分配够用的最少权限,严控有删库权限的人数,减少事故发生。
- 生产环境操作之前,需要先对SQL评审和测试,减少事故发生。为了恢复数据时好恢复,表结构不要使用外键约束、日常最好不要跨表操作。
- 生产环境操作,需要在业务低谷时段操作。如果误操作需要恢复,对用户影响最小。
- 建立事故惩罚制度,惩罚力度与影响的数据量、故障时长相关。有惩罚,生产环境操作才会小心谨慎。
场景二:硬盘故障,而且坏的很彻底,硬盘数据完全读不出来了(binlog损毁,无法恢复全部数据)
应对方法:
- 搭建主从,全部数据存2份,2个硬盘同时故障的概率相比1个硬盘下降了几个数量级。所以还是建议:不要用云服务器自建数据库,而是直接使用云数据库高可用版。高可用版每台主实例包含主备双机,全部数据存2份,可靠性比单机高不少。
- 如果全部数据存2份还不放心,可以存第3份,比如:给高可用主实例添加只读实例、不买高可用版直接买金融版(一主两备3台机器)。
场景三:地震,多个硬盘同时故障(小概率事件真的发生了)
应对方法:
- 事先给主实例添加异地灾备,全部数据在另一个城市也存一份。有异地灾备后,达到金融级的“两地三中心”。如果是金融类、电商类业务,这是必需的。
- 省钱小窍门:如果只是为了备份,灾备实例可以选最低配置,等到容灾切换时再升级配置。
场景四:我们在编程时是不能假设要调用的接口工作完全正常,要考虑接口工作不正常时怎么处理。同样的,我们不能假设腾讯云可靠性达到100%,需要考虑腾讯云出故障了、腾讯云dba删库跑路、或者某个潜藏的bug未来某个时段爬起来删库。比如:现在(2020-04-18),腾讯云就有安全漏洞,web用户可以通过销毁/退货+立即下线将主实例、相关的只读实例、灾备实例、自动冷备文件全部删掉(删1个冷备文件是无法操作的,删全部数据却可以操作),而且整个过程不会发出短信或邮件通知,如果web帐号泄露或者dba恶意报复公司,就可以通过销毁/退货+立即下线删库跑路。(这个漏洞,腾讯云应该改为:允许web用户自助销毁,但在销毁时发短信或邮件通知,而且回收站数据库立即下线不可以自助操作)
应对方法:
- 可以每天手动将腾讯云备份文件下载,或者开通数据库外网访问,数据自动备份到其他云厂商,当然这么做有个前提:新的存储空间是安全的,数据不会泄露,不会被黑客或者内鬼拿走。特别说明下,每日自动备份文件和实时完整数据平均差0.5天。
附录:数据恢复操作流程
1 操作之前,告知业务团队,避免他们浪费人力排查问题
2 收回业务程序帐号的数据库写权限(从可读可写降级为只读)
3 腾讯云恢复数据(也叫回档、回滚)
3.1 点击云数据库“备份恢复”面板的“回档”按钮
3.2 回档方式建议选择快速(普通方式比较慢,极速方式不支持整库恢复)
3.3 选择要恢复的库或者表:如果只需要恢复部分表,就不要勾选整个库,恢复会快很多
3.4 选择要恢复到过去哪个时间
3.5 验证恢复出来的数据是否正确、完整,补上恢复时间点之后业务程序正常的数据写入,这部分写入不应该被取消撤回(目前腾讯云不支持)
3.6 将恢复出来的库表上线(目前腾讯云不支持)
4 恢复业务程序帐号的数据库写权限
5 告知业务团队生产环境数据库已恢复正常
下面用2个案例说明第3步如何在腾讯云上恢复数据:
案例一:误删user表中的一行或一列
假设删除发生在09点00分00.5秒,00秒到00.5秒业务程序有3条正常写入sql,那么应该查看最近写入成功日志将回档时间定在00秒,并在恢复出来的库表运行那3条正常写入
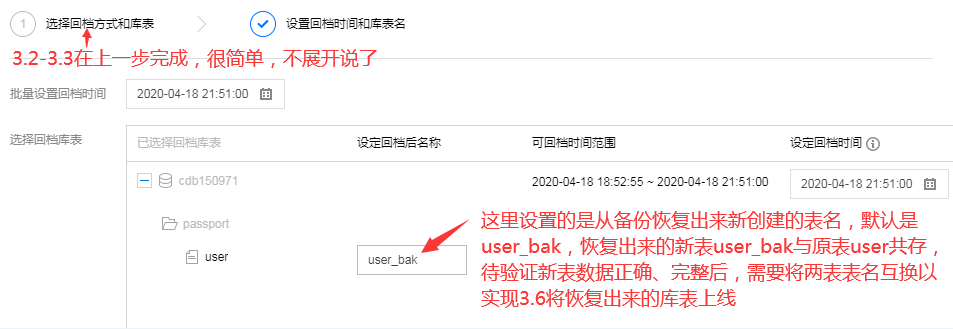
对腾讯云的建议1:
选择时间点会碰到一个问题,很多时候是不清楚需要撤回操作发生的准确时间点(比如:误操作后没有马上意识到误操作了,或者误操作者和恢复者不是同一人),如果时间点选择在事故时间点之后,那么恢复出来的数据还是错的,如果时间点选择在事故时间点之前,但是离的稍微远了些,那么后面补正常的数据改动工作会比较大。
所以建议:在选择时间点之前,提供查询该库表最后1000条运行成功的写sql,根据这个日志可以选事故时间点之前挨的最近的时间。
对腾讯云的建议2:希望有数据对比功能,比较恢复前和恢复后的数据差异。数据迁移那已有数据对比功能。
对腾讯云的建议3:数据对比出差异后希望有差异合入新库表功能,可以是在成功写入日志中选择恢复时间点之后业务程序正常写入sql到新库表批量执行。当然更好的交互方式是:放弃让用户选择回滚到哪个时间点,而是改为从成功写入日志中选择哪几条sql需要取消撤回(选中的sql在恢复回放时会被过滤忽略掉,未选中的按顺序全部执行),这种交互方式最后就不需要再做差异数据合入的。即:从版本回滚变为命令撤回,在云数据库世界,用户误删不再是通过操作系统命令对文件做删除,而是通过sql删除,背后都有1条待撤回的sql。
对腾讯云的建议4:将恢复出来的库表上线,需要进行名字互换,希望支持一键名字互换功能。线上运维需要提高自动化程度,减少手工操作,因为手工操作越多,误操作也越多。
案例二:误删整个库或者整张表
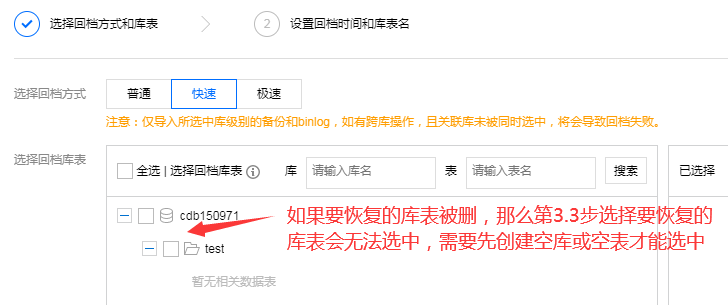
对腾讯云的建议5:如果是整库或整张表被误删,这时在选择库表时无法操作,需要换个工具先建空库或空表,操作被打断、不流畅,而且不熟悉的用户可能不知道要这么操作。建议:库表列表不是展示当下存在的库表,而是展示冷备文件里有记录的库表。如果库表当前不存在也可以恢复,那么恢复新建的库表名可以直接填原始名(不带_bak),这样第3.6步为了上线新库表的名字互换操作也可以省去。
腾讯云恢复功能给我的感觉是:提供了一个通用、简单、易操作的交互方案,但是设想的使用场景不够真实,真实场景是业务任何时候都有用户访问,不是每次线上操作都可以先业务停写,不是每次事故都是按计划制造出来的、都知道事故发生的准确时间,也不是业务正常写入和误操作泾渭分明、简单回滚到误操作前一个时间点就完事了。