公司内使用主干大仓开发的团队比较少,质疑一直不断,toB领域就更受争议,很多团队担心这担心那儿。腾讯云小微实战中,交付带宽严重不足,研发团队交付新任务的同时,还要维护大量老代码,但老代码很多时候是临时堆出来的,可维护性基本没有,团队成员为了解决一个老问题,往往要伤筋动骨好几天,这种背景下,新的交付必然受影响,为了赶交付时间,研发同学继续熬夜堆出更多的“垃圾”代码,没有时间提升技术力,同时强烈感受到产品骂娘,领导着急,苦不堪言。研发同学憋出内伤后,只好一走了之,接盘的同学继续“骗”与被“骗”,恶性循环。为了避免代码腐化和研发交付的“庞氏骗局”,腾讯云小微决定利用主干大仓将好处与坏处都放大的特点,面对质疑,不给自己留后路,从2020年3月开始在运用,很幸运,在主干大仓的逼迫下,团队进步很快,同时也拓宽了交付带宽,看到了希望。
今天分享的主要是下面几个点:
- devops理念和方法论
- 客户反馈处理效率提升
- 开发效率提升实践(主干+大仓)
- 快速定位效率提升实践(云监控+天机阁+大仓融合)
- 快速交付效率提升实践
- 代码设计基本原则和CR实践
1. DevOps理念
我们最基础核心的理念:可持续、自驱动、小迭代
1.1 正向循环
从开始制定Devops开始,我们围绕三步走的计划方案一一落实
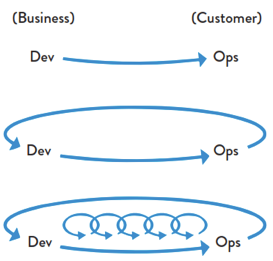
第一步
建立一个简单持续的CI/CD的流程。从Dev到Ops,一个简单的交付流程。
第二步
建立一个反馈环,客户的反馈可以通过很多渠道流转到我们开发,产品,测试这边。
然后我们再去迭代研发,迭代升级。使得我们的产品更加完善,客户反馈上更加积极主动。
第三步
就是在一个大循环之间,在用户反馈之前,我们内部先进行非常多的小迭代,这些小迭代通过以下行动项来保证用户得到是一个比以前更加稳定的产品
- 建立完善的质量检测机制
- 建立学习型组织
- 建立快速发布上线的机制
- 建立完善的代码质量拦截机制
当前,云小微正在逐步建设第三步阶段。虽然离完全完成还有不小的距离,只要方向正确,一定会走到终点。
1.2 演进障碍
不管是做什么变革,当你试图去改变一个部门或者一个小组固有的开发交付规范的时候。它都会有一个演进的障碍。
因为在我们所有的群体中,所有的人都可以分为五个派系。
- 先驱者
- 早期的实践者
- 早期的大多数
- 落后的大多数
- 固执者
面对这种情况,怎样在小组或者是在部门内快速推广一个DevOps的变革?
演进方法论
遵循两个步骤
- 找到这个群体里面的
创新者和实践者,说服他们一起参与的演进 - 建立起学习组织,邀请
早期的大多数参与
至于,落后的大多数和固执者,当使用人数超过一半后,他们也会被动接受这些变革。
1.3 应对关键
如何衡量一个devops是否做的好
- 客户满意度
- 研发幸福感
1.3.1 客户满意度
如果我们交付的产品没有任何的问题,肯定能够让客户满意,但这个现实吗?不现实!基于这个不现实的情况下,我们怎么能够最大化的提升一个客户的满意度?
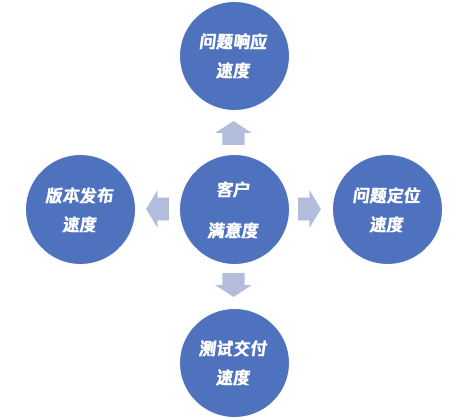
- 针对客户反馈的问题我们能够快速的响应
- 在响应之后能快速定位到故障的原因
- 安抚客户之后,我们再进行一个快速的测试、交付
- 有一个非常快速迭代发布
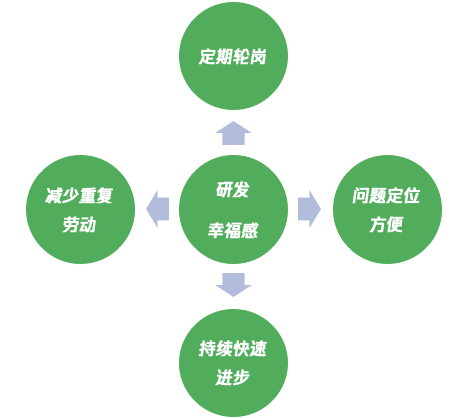
1.3.2 研发幸福感
很多人刚刚加入项目的时候,会有一定的新鲜感,所以做事情的时候也会富有创造力,激情。
然而几年过去,随着你当初加入这个项目的激情慢慢消退之后,很多研发就很难再对项目投入足够多的激情,甚至会造成人才的流失。
为什么会出现这个情况?出了物质方面的问题意外,我认为大致可以分为下面几个部分:
- 大量重复劳动的工作
- 无法定期轮岗
在我们部门以前几年的发展中,很多人接了一个服务之后,未来这三四年就一直维护这个服务,直到这个服务不再维护不再迭代,这个服务一直属于这个人。而且这个人在离开团队的时候交接给别人,交接的人也难以改动这些代码
- 定位问题非常的困难
我们智平以前定位问题已经困难到什么地步。就是我们客户反馈了一个问题,我们得需要通过很多步才能定位到原因:
1. 给这个客户的guid染个色
2. 然后再让客户重现一下bug
3. 客户重现之后,我们就可以查到简略日志
4. 查到简略日志之后,我们再去对应的容器里面去找它对应的详细日志
5. 分析,定位
定位一个问题往往需要1小时甚至1天之久,容易造成客户流式每个人他所有的技术发展曲线都是一个快速上升,然后在一个平稳稳定的一个状态。如果不作出对应的调整,技术就很难持续进步。基于这些我们云小微做了一些Devops演进方案
2. 客户反馈处理效率提升
我们部门2020年9月客户反馈响应速度是60+天,经常被客户投诉,已经到了不能不改的地步。所以我们决心在2021年H1将客户响应速度降为7天。
我们这半年来跟外部的团队去沟通了很多次,为什么他们能够做到很好的一个客户反馈?
比如我们普遍感知的就是腾讯云助手,蓝盾,PCG服务助手这些公共账号会给人一个反馈是非常正向的。
我认为主要是以下几点:
- 响应问题还是非常及时的
- 能够非常主动的push流程的跟进
- 上升机制
那为什么我们自己作为一个服务方,跟客户去交流问题的时候就很难做到这一点?
推诿和流转
2.1 困境
下面是我们团队用户反馈问题的一个解决时序
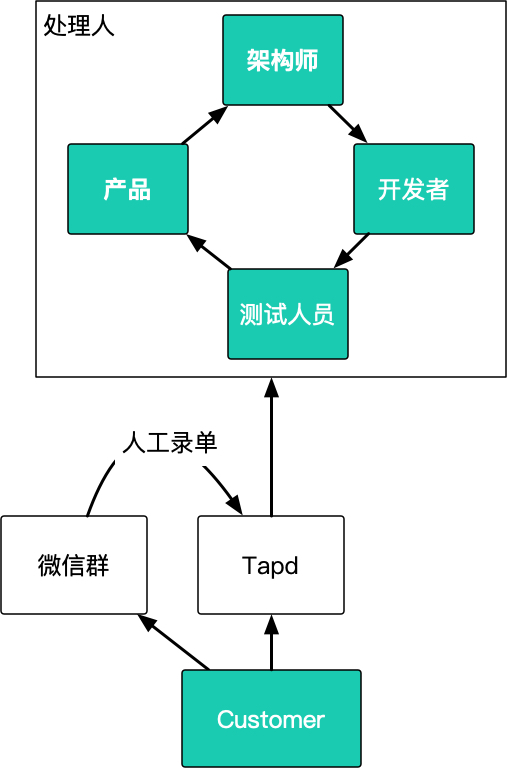
其实这个问题不只我们团队有,任何一个团队都会有。
比如一个常见的场景:
客户反馈问题
产品将问题分配给开发者
开发者认为这个不是我的问题,可能是测试的原因
测试认为是产品定位的问题又推给产品
产品非常懵,又转给开发这个看上去非常正常的流转的过程中,有个比较严正常问题就是:
流转是有时间间隔的
如果我们把流转时间加上,就非常明显了
客户反馈问题(立即)
(1 day)产品将问题分配给开发者
(1 day)开发者认为这个不是我的问题,可能是测试的原因
(1 day)测试认为是产品定位的问题又推给产品
(2 day)产品非常懵,又转给开发最后就导致客户得到的反馈是非常长,长期以往就会损害品牌印象
一个遗憾
基于这种情况我们去请教了安灯,智研这些客服体系平台,但是很遗憾的是,由于平台的种种原因,经过1个月的对接,最终也没能将这个功能打通。
2.2 Tapd的一个新功能
就在我们束手无策的情况下,我们意外在tapd上发现了一个刚上线的定时任务功能
这个功能它有什么用?就是你可以设置非常非常多的小任务,当满足什么条件时候触发,就举例子说。基于这个小功能,我们做了些客户反馈上的优化
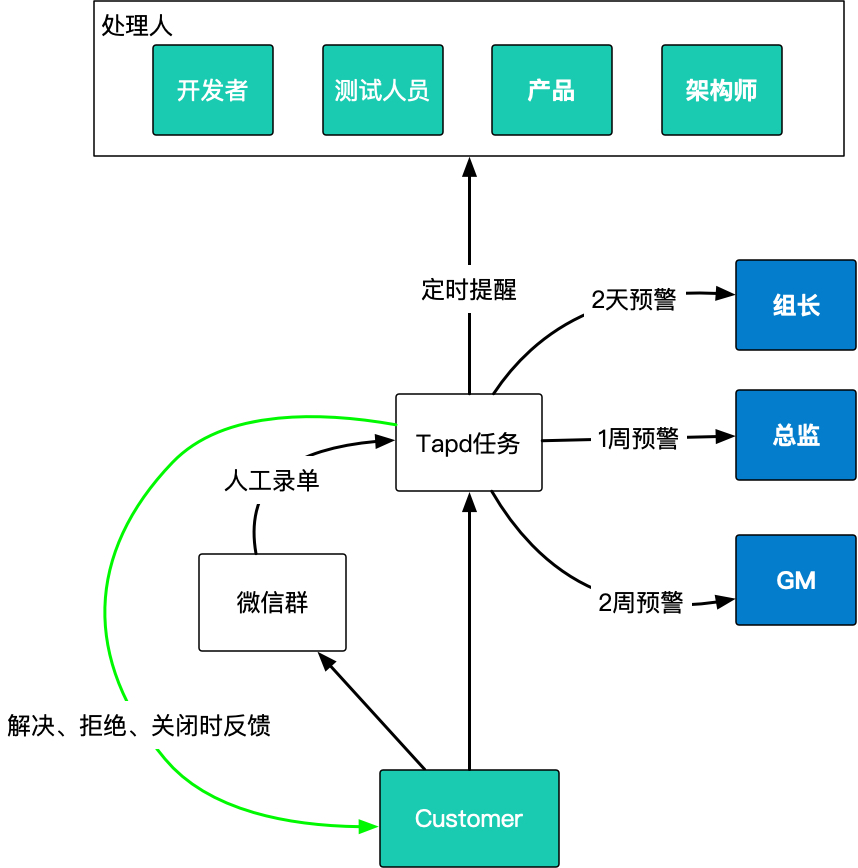
也就是:
客户反馈问题(立即)
tapd立即拉群通知产品人员
(1h)产品将问题分配给开发者
tapd立即拉群通知开发者
(1 h)开发者认为这个不是我的问题,可能是测试的原因
tapd立即拉群通知测试人员
(1 h)测试认为是产品定位的问题又推给产品
tapd立即通知产品人员
……
如果问题超过2天未解决,我们会自动上升通知到组长层
如果问题超过1周未解决,我们会自动上升预警到总监层
如果问题超过2周未解决,我们会自动上升预警到GM层目前我们已经在3个项目线上开始使用这个功能。
2.3 效果
我们从2020.09发现这个问题之后,原本客户反馈问题处理时间要64天,经常被投诉.
为此我们将客户反馈问题纳入到SLA体系每周过一遍,在这个措施下,我们看到客户反馈处理时长从64天逐步降到了11-14天,但是降到这个程度的时候,我们发现很难再提升了。
我们在2021年5月引入TAPD的自动任务的功能之后,2021年6月客户反馈处理时长首次突破7天下降到5. 01天。完成了上半年指定的目标!
同时到8月1日又再次下降到了 4.22天!
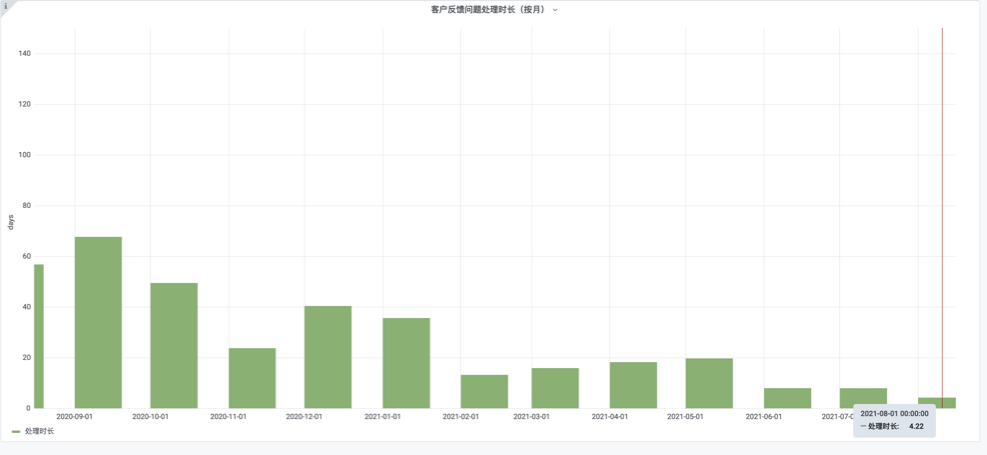
客户反馈处理时长其实涉及很多问题,比如说快速开发,快速定位,快速交付这些配套的解决方案。这些我就会在后面展开讲
3 敏捷开发
我们部门借鉴了整个PCG的一个epc的一个发展过程。通过研究他们是怎么去实践的,翻阅了大量的文章,还有几个同学,跟着腾讯文档的后台团队去做过数个月的实践然后总结得到一套方案
3.1 主干开发
先看下主干开发与分支开发的区别
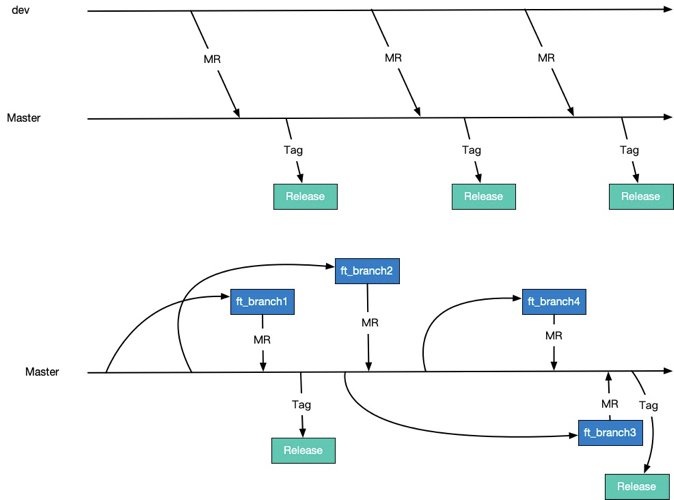
3.1.1 分支开发
我们以前是在使用一个分支合并的开发模式。
这种模式就是每个人有一个自己的小仓,然后每个人去维护自己的分支,然后定期的自己通过MR的方式Merge到master,然后自己打tag去触发。这样一个开发模式,有以下特点
代码熟悉
每个人对自己的一个项目,代码非常熟悉。但是其它同学对这个同学的代码完全是盲盒
CR交流少
为了打破代码CR缺失的情况,我们中心会组织1周1次轮流CR,相当于每个人的代码,1个月才会被CR一部分
发布速度慢
我们现在智平是每周一提单,周二审批,周三发布灰度,周四上正式环境。按照这个流程,我们每次修复一个问题至少得等一周,如果说中间有流程走的比较慢,或者开发人员自己忘记发正式的,可能又要等一周!
但是这种开发模式是非常适合那些终端团队。因为他们是每周固定的发版上OTA,然后客户可以在当天指定的时间得到一个更新,他们不需要投入很高的代价就能得到一个稳定的发版节奏
3.1.2 主干开发
针对后台服务,我个人认为主干开发可能是会更适合的一种开发模式。
架构熟悉
这种模式每个同学对代码的掌握可能只有70%,但是对整体架构非常熟悉
CR交流频繁
我们主干合并开发是强制CR的,我们过去在一年里,发起了2800+次CR,平均每天就有8次CR被触发。
发布速度非常快
因为走了CR,再加上其他的质量保障措施,你其实可以做到随时release版本。
而且我们云小微团队目前已经做到了:
从发现问题,到修复问题到发布到生产环境,整体的时间甚至最快的时候都不超过半小时,相比以前的一周或者两周的发布速度已经不在一个量级了。
3.2 协作开发
主干开发跟monorepo是配套的,当你想用主干合并开发是,搭配monorepo可以使你的开发模式有个工业级的提升。

3.2.1 联动式开发
什么是联动式开发?
举例说:
我们以前每个同学可能会负责一个主模块,然后若干个业务模块,这种开发模式的话,如果我们需要开发一个功能,就需要三个同学联动去开发。
开发慢
这种开发有个比较致命的问题是:
很多情况下每个同学有自己的一个开发节奏和优先级
经常出现张三开发完了,等着李四开发,李四开发完了等着王五开发,然后再约定一个时间联调,有时候明明就是加一个字段,却要等上三四周!
轮岗困难
把其中两个同学的工作交换一下,首先他们有个非常长的一个适应期,而且还不能无缝地接
最要命的是,由于代码风格和编码习惯不统一,交换代码之后会互相看不起,最后就导致组内的矛盾其实并没有解决,反而会更加加深。
轮岗最后就导致着,浪费了大量的交接过期时间,但是效果反而不如不交接
没有全局视野
我不知道在线教育的同学是怎么样子,反正在我们部门就经常出现一个现象,就是每当答辩季到来,就经常看到同学拿着笔记本或者搬着电脑。就过来问一个同学你这个模块是干什么的,中间有什么东西,然后做了哪些优化或者用了什么样的组件,性能怎么样,有没有性能瓶颈。他们对整体的一个架构只有非常粗糙的认知。
3.2.2 协作式开发
我们从2020年3月28日开始使用monoRepo进行协作式开发
这种模式就是把所有的大型组件,所有的业务全部放在一个大仓里面。开发一个功能,只需要一个同学全程投入即可了。
开发快
大量的组件复用,开发一个feature,只需要投入一个同学,进行全链路的修改即可。其它同学只需要参与CR
轮岗方便
其实根本也没有轮岗一说了,每个同学去开发另外一个未知的服务,基本没有什么门槛,怼上去开发就行了。还有另外一个点是,基本不存在工作交接了。举个不恰当的例子,我们之前有个核心开发人员转岗了,在大仓里面涉及过十几个模块的开发,而这些都不需要任何交接
架构清晰
当你把所有业务都放在一个大仓里面的时候,不敢说对所有的整个部门的整理业务大致了解。但是对当前一个项目,比如说教育项目,比如说行业平台项目,成员对整体的架构是非常非常清晰了解的。
细节不清晰
当然这个开发模式也会有一些的问题,就是部分模块的细节不会特别清楚。
3.3 协作式开发
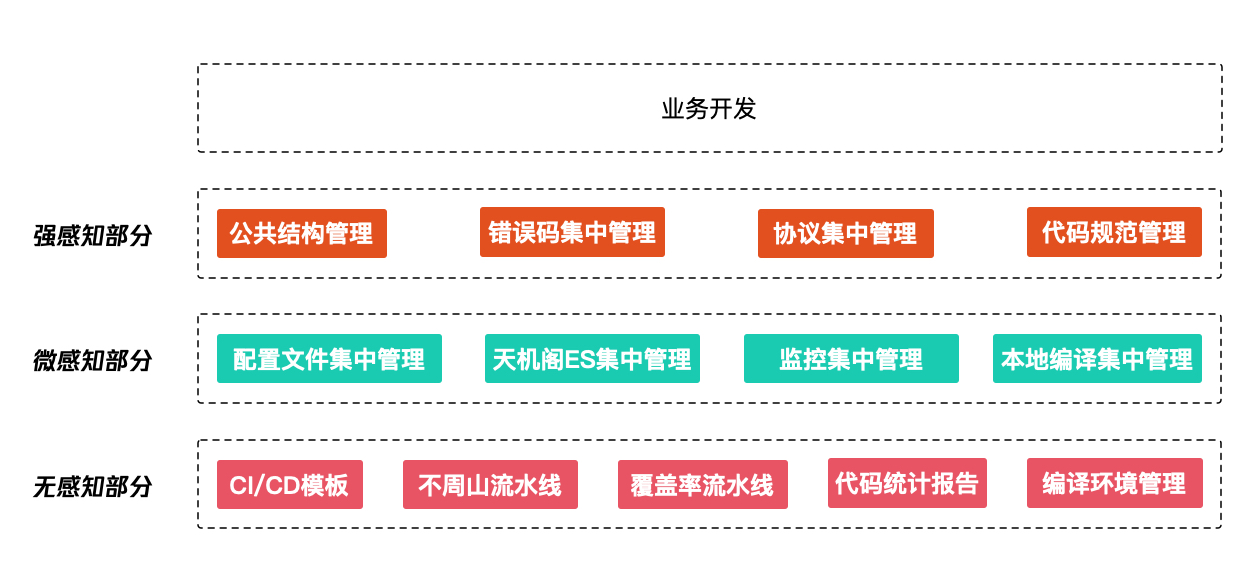
就基于这种monorepo 的思想,这是我们目前大仓的一个整架构图。
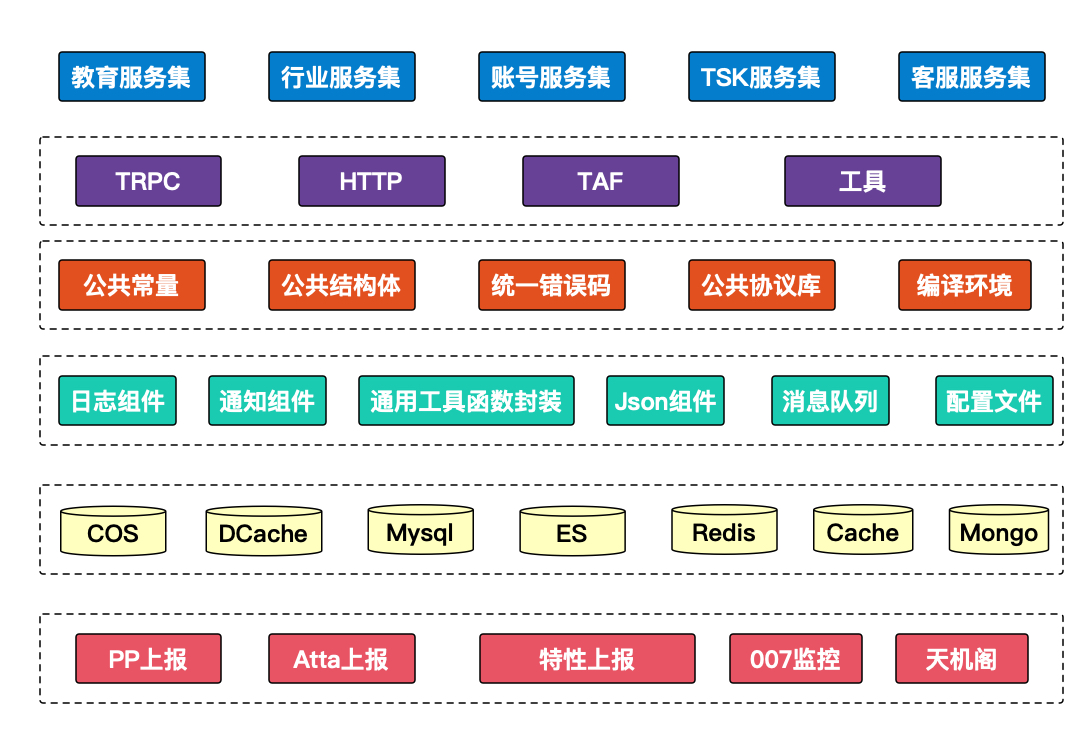
从下往上看,我们针对大家常用的一些监控全部进行了一个封装。
常用的存储我们也进行了一个大部分的封装。
还有大家常用的日志、通知、函数、常用组件,基本都有封装了。
在这之上就是一些公共约定了。比如公共常量、结构体、错误码、协议库和编译环境。
第二层就是一些框架层的适配了。我们现在去写trpc代码或者写taf代码,在编码层面上,大家基本上感知不到的差异的。
当我们做完这种搭建之后,我们发现就会实现非常多的利于团队的事情。
3.3.1 快速搭建环境
以前新来的员工,我们都会预留一周的时间让他搭环境。但目前的话,可能只要半个小时到一个小时。
我上次电脑自己坏了,自己试了一次,大概是十分钟就把整体的环境搭建起来了。
3.3.2 统一错误码
统一错误码其实是仿造美国航天局的维修手册。我们经常看到,空间站出了问题,宇航员手忙脚乱地拿出说明书,找到那个错误码,然后找到对应的操作,然后去把这个问题解决。
我们统一错误码,其实是想做到一个最终状态:
只要是我们云小微的一个用户,只要告诉我们一个返回码,我们就能够大概的知道到底是一个什么问题
3.3.3 统一的CI/CD
所有基于大仓的流水线是统一的。新服务只要复制别人的流水线,改其中两个参数就可以了
3.3.4 学习型组织
我认为整个开发模式给大家一个最大帮助就是,建立了一个学习型组织。
为什么说是一个学习型组织?因为我们每个人发现的问题都会在群里去反馈,然后发起的CR也会在群里去发起,然后邀请大家来CR自己代码。而不是像以前一样自己偷偷的Merge。
另外一个好处就是可以促进我们的技术栈演进,以前我们会有一个平台小组专门去推进这个大仓的组件封装,现在就是开始成员自觉将一些好用的组件封装到我们的公共库里面去。像敏感词检测、卡夫卡等组件。其它的好处就是,从单兵作战演变为群体作战,可以群策群力的去快速的战胜一些问题和解决一些问题。
3.3.5 Code Search
100+服务案例参考,100+组件封装支持,服务开发可以规模化和流程化
3.4 协作式问题
大家听我吹了这么久的一个协作式开发,有些人就会反感,大仓难道是一个包治百病的东西吗?如果是的话,为什么整个公司没推进起来,就你们这一个小部门在搞。
首先我们明晰一点就是:大仓加主干开发并不是一个银弹,而是一个代码工程实践的放大器。其实这个在km或者乐问上已经讨论过很多次。
为什么说他是个放大器,是因为:
!!#ff0000 当你大仓做的好的时候,你的优势将会无限的被放大
但是当你这个大仓做的差,那么问题也会无限的放大!!
3.5 成员反馈
从2020年3月底开始去做这个实践了。在21年3月底的时候,做过一次问卷调查,邀请了当时参与主干开发的16个同学做反馈统计,下面就是一个反馈的占比。
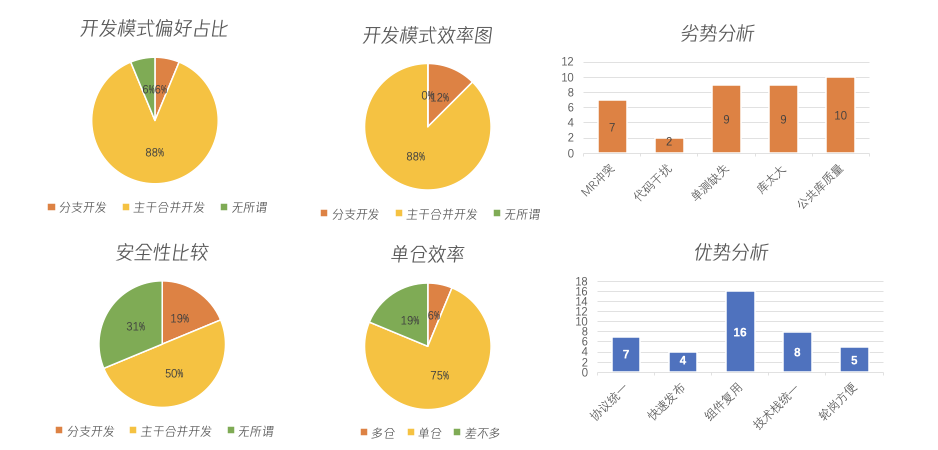
PS:
做这个课程分享前后,我做了一个课前课后检查:
课前是 23人投票 20人愿意尝试使用,占比87%
课后是 32个人投票 31个人愿意尝试使用,占比97%!
相信所有人内心都向往一个幸福开发的模式!
3.6 挑战与解决
从上面成员反馈来说,我们看到有比较多的负面反馈。那如何解决这个问题?
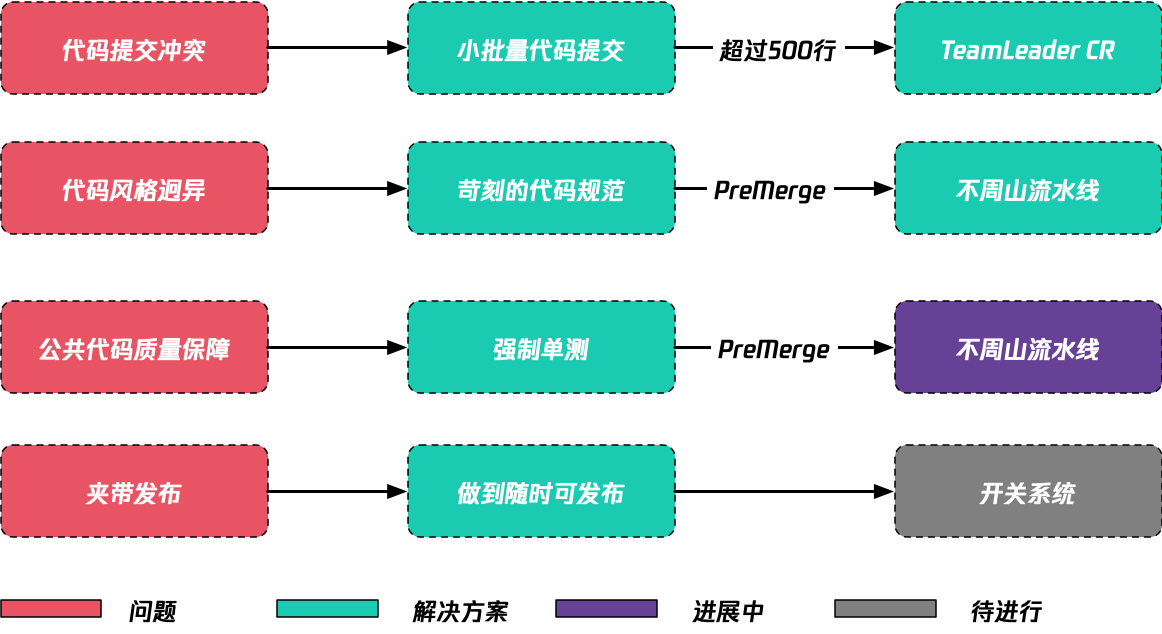
3.6.1 代码提交冲突
我们现在要求是:每一次提交就务必是做到200行以内,最高不能超过500行。如果超过500行,就自己去总监CR,然后其他同学就不参与了。
3.6.2 代码风格迥异
我们做了很多很多的规范:首先估计google的golint这个规范可能其他团队都没有完全遵守,但我们是非常苛刻的。
为什么说苛刻?因为golint检查已经集成到编译命令中去,即:golint的问题在编译的时候就会被检测出来。除此之外,我们还做了非常多的关卡保障所有人写出来代码都想流水线生产的代码一样。后面会有专门的讲解。
3.6.3 公共库代码质量保证
这个是我们大仓实践中做得最不好的一点,我们以前由于需要赶进度,写公共库的时候没有写单测,所以导致着我们公共库的单测代码覆盖率才到30%左右,我们从2021年4月开始实施公共库强制单测CR制度,并且制定了一条流水线去扫描单测覆盖率。(目前单测覆盖率扫描一次需要50min,所以暂时未做准出红线)
3.6.4 夹带发布
这其实是一个老大难的问题。因为我们目前是五十万的代码,将近100个服务在一起在开发,夹带发布是不可避免的情况,我们要做是,如何降低夹带发布引入的风险,我们说两个解决案例吧:
- Google,要求所有合入主线都可以直接发布到线上,如果做不到,就自己加代码关闭掉,到可以打开的时候,再删掉关闭。这种做法就是对工程人员的素养要求极高,还需要有非常快的风险应对方案。
- 腾讯广告,做了一个强大的开关系统。所有的特性代码都有开关控制,也有完善的通知删除体系。他们这种做法有个好处就是所有的代码都是可控的,也尽量减少了夹带发布的情况。 更多详情可以内网搜索《腾讯广告如何在3000多万行的大代码库上实施主干开发和天级自动发布的》 那这两种方案孰优孰劣?笔者认为 google的方案是最优方案,而腾讯广告的方案是最适合我们腾讯的方案。为什么这么说? 首先,我们不得不承认的是我们腾讯技术人员的平均工程素养是低于google的,我们很难做到不加开关的前提下,就能保证代码可以直接发布到线上,所以他们的方案并不适合我们。 而至于为什么说腾讯广告的方案不是最优的方案呢?因为这种方案是会将一个本来就非常复杂的大仓里面的代码复杂度进行了一个拔高,很有可能随着业务需求度复杂度满满累计升高,导致业务里面随处可见的开关,后面接手的代码的人看到十几个开关,整个人都是懵逼的,后面维护的人又不敢随意删除,这样就会导致代码腐化加速。 而我们智能平台产品部,现在是要求每个同学尽可能的做到随时可发布,但是不是说每个同学都能保证这个点,得益于我们是5-10人小团队协作模式,目前还是在可控范围内。整体上,这种问题的解法,我们还是在探索的一个阶段。
3.7 代码质量保障
然后就是重点讲代码风格迥异的解决方案。我们做了一个非常严苛的代码质量保证,已经严格到什么地步?
先看看下图
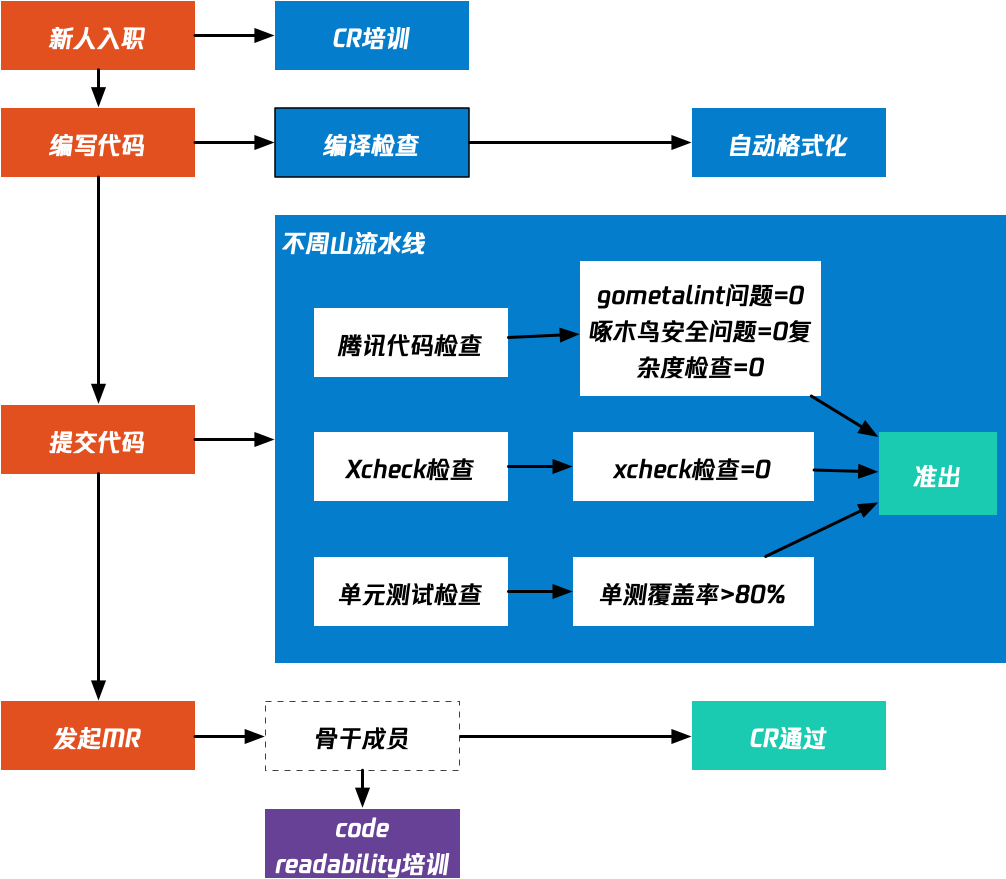
从新人入职到合入代码到主线,我们制定了非常严格的4道关卡
3.7.1 第一关:新人培养
首先我们新人入职,无论你是社招还是校招,进来之后我们都会做一个代码CR的一个培训:
- 代码该怎么设计?
- 大仓+主干怎么开发?
- 环境如何快速搭建?
- 团队的代码氛围快速培养
- 有哪些代码规范?
每次大概在一个小时到两个小时之间。
3.7.2 第二关:编码检查
然后在编写代码的时候,我们的makefile里面已经集成了 golint检查和go fmt 自动格式化。只要你编译,就会提示golint检查,并且做代码自动格式化,这些都是在新人完全无感知的情况下去做的
3.7.3 第三关:PreMerge
我们在大家发起MR之后,自动开始执行不周山流水线 (我们devops小组,叫共工。所以将这种基础支撑流水线叫做不周山) ,这个不周山有哪些功能
- 腾讯代码检查
+ 啄木鸟安全检查+ gometalint检查+ 圈复杂度检查- xcheck检查
- 单元测试检查(doing)
3.7.4 第四关:CR
我们是强制要求CR的,至少有一个人CR通过之后,才能合入master的,而参与CR的同学都是我们核心开发骨干,我们后面也在计划针对这些核心开发骨干做一些Code ReadAbility培训,目前已经参照PCG的EPC的做法,在制定Code ReadAbility培训计划了。
一个代码合入到master,如果由于代码导致后续出了问题,我们目前鉴定是 开发人员90%责任,10%CR同学的责任。
3.7.5 代码治理成绩:
我们在2020年4月大仓项目成立之初就严格执行了 golint规范+《腾讯代码规范》,但是即便我们完全遵守了代码规范,也很难保证我们的代码就完全没问题。一年后也就是在2021年4月,我们再次加入了腾讯代码检查+xcheck检查,让我意想不到的是,当我们开启这些东西之后,原本问题数为0,竟然飙升到了1500+!
很多东西我们原来并不在意,但是在深刻思考后,确实发现这些规范如果不遵守会导致代码加速腐化。于是我们就开始修复,经过三个月的修复,当前问题数已经降为了24个。
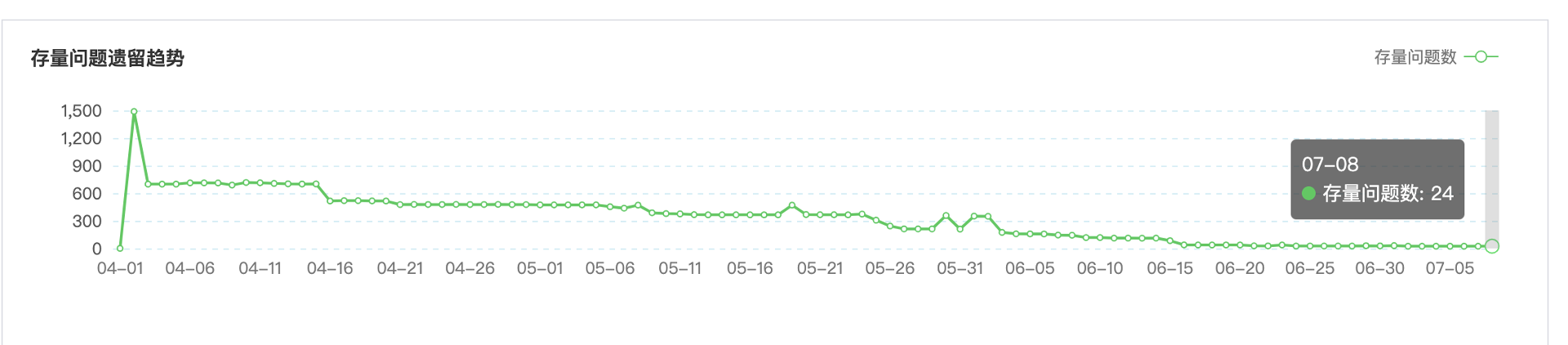
剩下的这24个全部都是复杂度的问题,这种问题比较难修。举例子来说:一个函数里面200多行代码,要优化到每个函数不能超过80行。可能大家会认为这种问题不修复也没关系,只要写好注释和文档,照样能够保证代码可读性非常好。但事情真的是这样吗?并不是!因为当你这一个函数的代码超过80行之后,轮岗的人接触你的代码,或者说要修改你代码就很难受,那他到底改不改造?如果不改造,就接着扩充行数,代码就会开始腐化,如果改造,那会不会引入新的问题?
我们目前的大仓是强制开启了规范检查。当你单个函数代码超过80行之后,就没办法merge到我们的master分支,从而保证了我们大仓整体代码的干净。
当然我们这种做法能不能根治代码腐化呢?不能!我们只能延缓代码的腐化进度。别人两年就需要做代码重构,而我们只能保证这个代码可能要五年之后才需要去做代码重构,而且最重要的是,五年之后去做代码重构,重构起来一定会非常的轻松,不会出现一边重构一边骂娘这种情况。
3.8 工业级开发
这是非常非常大的命题,我认为我们做这个主干开发最大和最好的收获是实现了项目开始往一个工业级开发过渡的阶段。
何为工业级开发:
开发具有规模化、标准化、创造力
3.8.1 规模化
在规模化这一块,我认为我们已经是做的非常成熟了。
我们有统一的CI/CD流水线,你要做的就是基于模板修改3-5个参数就能完成CI/CD体系的打通
我们有统一的代码检测系统,你只要正常开发,编译,MR就能接入到完善的代码检测系统
我们有统一的编译环境,无论你用osx还是linux抑或windows,都能快速搭建编译环境进行编译发布
我们有100+的公共组件封装,99%的功能都已经封装好了,只等你去使用,这个数字,还在以每个月10+的速度增长
这些无感知的部分,恰恰是工业级开发的基础底座。设想:这些东西每个开发人员在进来的时候都是微感知甚至无感知的。举例子说配置文件,天极阁这些,开发人员不需要关心权限管理,功能分割,分组,后续的迭代升级,组件的架构原理,就能无障碍的使用起来。那是不是就可以将全部精力投入到业务开发里面去,创造更大的价值呢?
3.8.2 标准化
得益于我们规模化的应用,我们标准化也做得非常扎实
比如代码标准化,保证每个同学看到代码不会产生隔阂,如果有,就是CR做得还不够细致
比如编码标准化,应该要接入那些组件,应该要如何设计一个高效的函数架构,这些在日常CR中,都会有代码交流促进所有人快速成长
比如输出标准化,我们对日志的输出做了很多培训和讨论,如果做一个高效的日志输出也在日常CR中有体现
3.8.3 创造力
在补足规模化和标准化之后,所有的工程师就能在这之上发挥创造力。比如说:
- 快速解决一些问题
- 推动公共组件的一些完善
- 还有整体的一个技术栈迭代,快速的向云原生发展靠齐。
- 把很多局部优化的东西转变成全局优化
以上这些都是我们目前在做在演进的一个地方,而且在群策群力这一块,已经做得相当不错。
3.8.4 成果
目前腾讯云小微能够支持40+个不同KA端的特殊特性,数百种客户bot,以及8种不同功能特性的政务交通等场景的私有化发布
企点项目上,西安支撑域的开发同学,可以按照云小微代码与质量规范入仓参战,高质量的完成了功能开发以及开发之后的代码交接,间接拓展了交付带宽;
3.9 经验和教训
我们实行主干开发以来,也不是一帆风顺,下面是我们的一些经验和教训

3.9.1 经验总结
日志封装:
从我们最初实现的一个日志封装开始,每个人就开始在用的一个组件。我们后面兼容RPC,支持atta上报,支持天机阁trace日志上报这些功能,所有使用人员都是无感吃的。大家甚至都不知道为什么他打了一行日志,就可以去天机阁、鹰眼上查询。
天机阁封装
天机阁在我们大仓里面接入有多简单。只需要一个人,只需要10分钟,就能完成70+服务的接入和上线。效率非常恐怖
CR交流
在所有的经验里面,我认为是对大家的一个技术成长、持续进步帮助最大的是CR的交流体系,我们所有的代码想要merge到主分支都是强制CR的,在这种机制下,我们的代码交流变得非常频繁,当然在这个交流过程中也有很多一些问题,这些问题也倒逼着我们逐渐的规范化,逐步形成一个统一的开发模式。
3.9.2 问题总结
公共组件的质量问题
举例子来说,作为天机阁Oteam成员,经常会跟进天机阁的升级,由于我们天机阁是独立部署,也就导致着我们升级到最新的天机阁版本之后,偶尔会出现一些问题。
有一次我升级完之后,这个天机阁由于api变化,没有经过大范围的测试。导致了我们所有的服务的上报全部都失败了,虽然这个问题出现之后能够通过快速回滚去解决,也没有影响到线上,但是也警示了我们再对待公共组件的升级上一定要慎重。
成员不规范操作问题
一个同学改了公共库,改完自己没有编译就直接提上去了,并且发起了MR。CR的同学看了一下,逻辑上改动是正常的,也符合代码规范,就给通过合入到master了。后面就导致别人都无法编译通过,直到后面进行统一fix才解决这个问题。这种问题也在警示我们,提交上去代码一定要先编译通过,走单测通过,功能验证通过才能合入到master
4. 快速定位
讲完快速开发之后,我们便开始着手做快速定位体系
4.1 监控体系
我们从去年四月份就开始去构造一整套完善监控体系。
在整个过渡期间,整体监控体系是非常乱的。大家看到图中上半部分就是我们这些时间接入的监控体系:
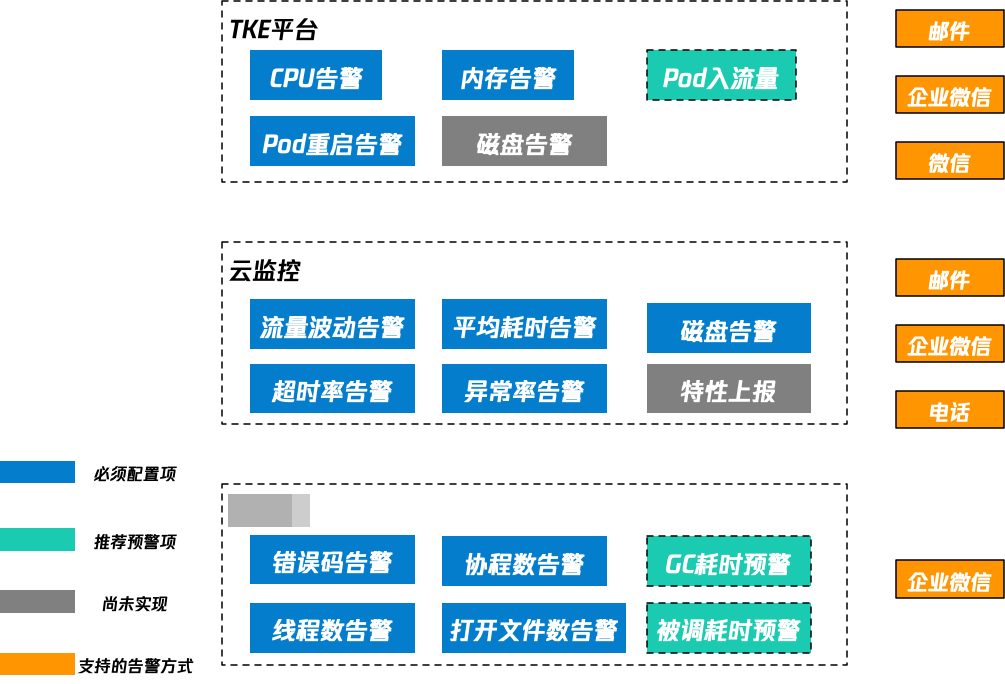
原来TAF就自带了一个服务监控/PP监控/特性监控,随后我们发现天机阁好用,后面我们公司在主推007统一监控告警体系,所以我们也统一进行了007监控上报。
在我们接入了这么多监控告警之后,发现数据上报的冗余是比较多的,但是由于我们采用的是大仓的开发模式,目前已经收拢到云监控以及天机阁了。
目前所有的框架、存储都是走统一的云监控和天机阁的监控告警。

4.2 天机阁快速定位
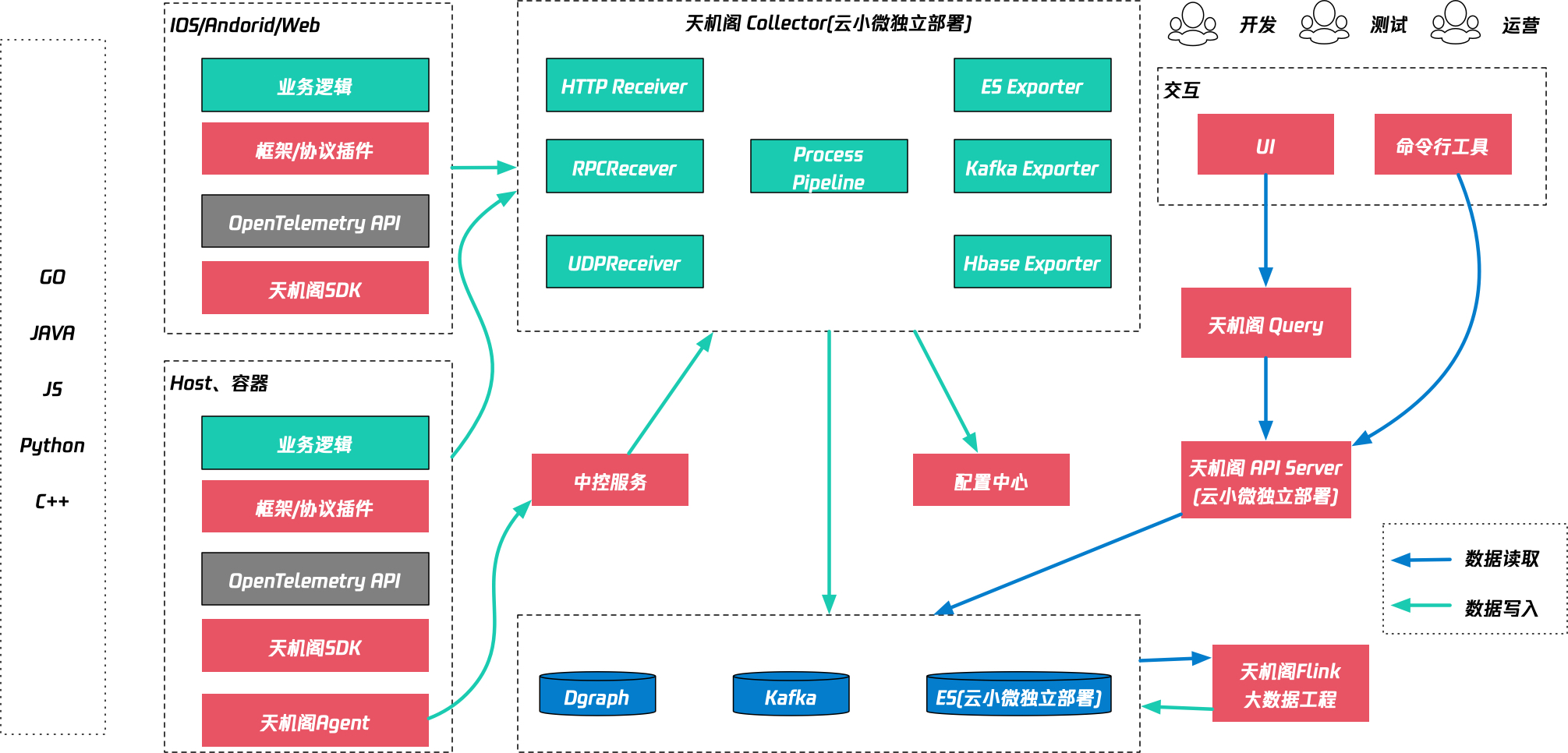
公司的天机阁真的挺好用,而我们部门作为一个天机阁主要贡献部门,贡献了taf-cpp,taf-go,taf-java,taf-nodejs的代码和组件封装。
同时,由于天机阁的TPS非常大(1000W/TPS),所以我们将天机阁的一些重要的模块进行了独立部署。比如图中collector,ES存储以及它的API Server都已经独立部署到云上了。这种独立部署的方式能够保证我们天机阁的稳定性,即便天机阁出线了大范围的故障和大范围的变更,我们也不会受影响。
天机阁如何使用:
我们直接在群聊里面直接就是现场抓一个SessionID的,直接去打开天机阁,就可以看到链路日志。只需要把找到的问题截个图丢到群里,然后就可以快速回复了。整个的过程的话,就四五十秒的时间就完全足够了。
关于天机阁,由于我们之前已经特意请过天机阁主负责人的tensorchen来跟我们讲解架构和功能,所以我们这里就不赘述了。
4.3 日志体系
大仓做这个日志体系真的是非常快。如下图所说,开发人员就只需要一行代码,就能无感知的接入非常庞大的日志体系
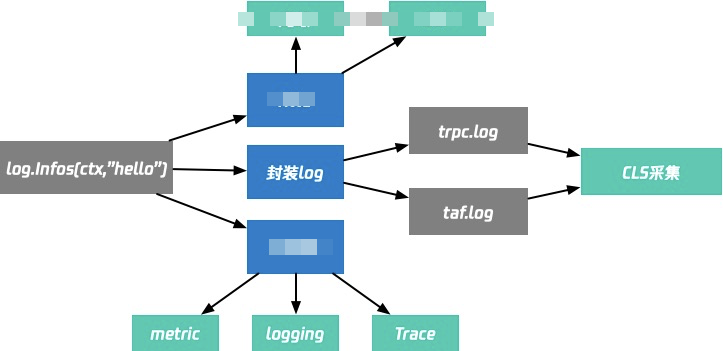
有的同学其实都不知道他后端的原理是什么样子,对所有同学来说,他就打了日志而已,竟然就可以去天机阁和鹰眼去查询到了。而这就是大仓的一个好处。
5. 快速交付
我们在做交付体系的时候,会发现一个问题,就是我们每一次发布就必须要走提单发布审批这一流程,而这个流程会卷入很多无关人员的审批
举例子说:
我们将一个功能关闭掉,对应代码里面就一个布尔值的修改,按照我们原来的交付体系,就得提单,需要设计人员,测试人员,产品人员,商务同学审批,他们一般都不会看,而且他们有时候忙起来没时间审批,整个流程可能要卡个两三天。
根据这个情况,我们就做了一个二人交付体系。
5.1 二人交付体系
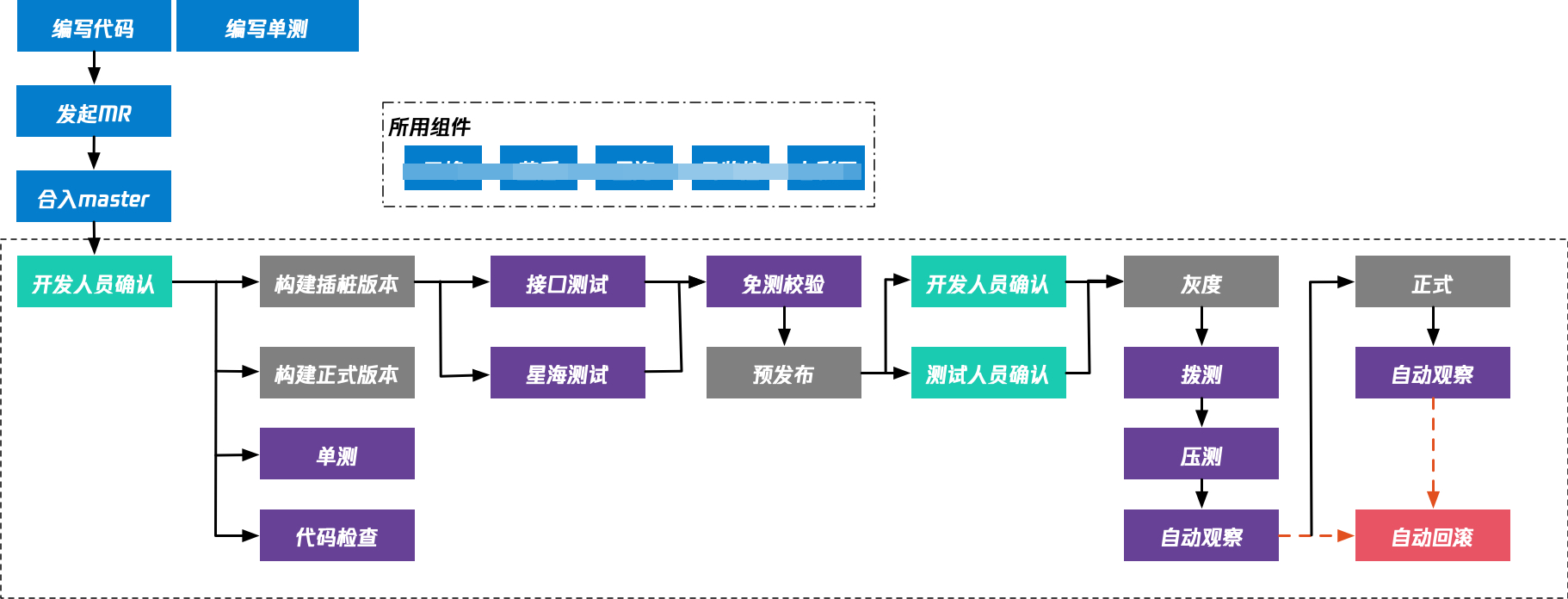
我们从发起MR到最后发布到正式环境,整体的一个流程。
大概最快的是28分钟,最慢也是在四五十分钟的样子,而大部分的时间,是耗费在其中自动观察阶段。这个阶段我们要耽误20分钟的时间去观察服务的超时率,异常率吗如果有问题还要进行自动回滚。
整个流程卷入的人员就只有两个人,第一个就是开发人员自己,第二个就是测试人员。接入的人少,无需测试,发布速度是非常敏捷的。
那有的同学会问:这个交付体系怎样去保证交付质量?毕竟你半小时左右就上生产环境了,肯定也没时间去提测了,代码质量如何保证?
有的:图中紫色的模块,就是一些质量保障的模块。除了这些模块保障意外,还有一个非常严格的免测校验。
5.2 免测前提
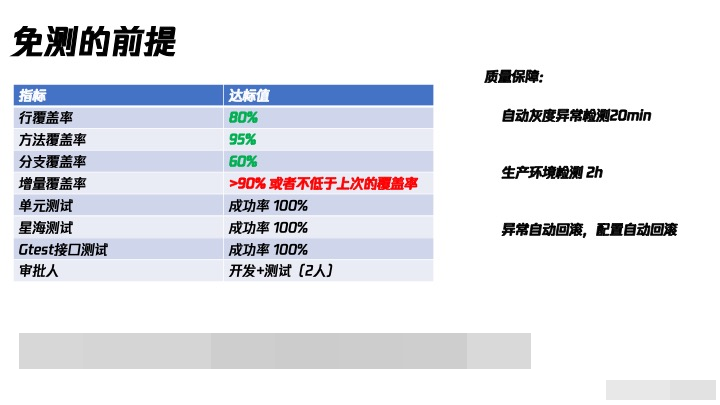
单从行覆盖率跟方法覆盖率来说,我们其实比腾讯广告,腾讯文档,应用宝更加严苛的,但是行覆盖率跟方法覆盖率我们认为说明不了什么。因为即便当我们的行覆盖率达到了90%,我们的分支覆盖率可能才30%不到。所以所有覆盖率指标中,最重要的的是分支覆盖率。而我们敢做免测发布,底气从哪里来?,把分支覆盖率做上来。
将分支覆盖率做到60%有多难?
举例子说:你写了700行单测,行覆盖率85%,但是分支覆盖率才20%左右。为了达到这个及格线,你可能需要额外补充3000行单测的代码才能做到!
除此之外,我们还要求,每次发布 行覆盖率+方法覆盖率+分支覆盖率的指标数据不能比上一次低
我们当前已经完成了58条免测流水线的建设,有58个服务,已经开始走这种绿色通道快速的对外发布服务了。
6 编码实践
编码实践我们大概实践了1年多,经过这一年多的反复CR,现在除了刚入职的同学,现在提交的代码都是非常规范了。
6.1 MR规范

1.每次提交代码不能超过200行。超过200行低于500行,别人心情好的时候可能会帮你过一下。但是你超过了500行那你就只能去找总监去CR 了
- 不允许提交二进制文件,这样才能才能保证仓库容量膨胀太快。二进制,doc文档等其它,统统存放到 腾讯软件源和iwiki上去。
- 不并行写代码。就是当你开发完一段代码,发起CR后,不要紧接着去做另一个feature开发。正确的做法是催着别人CR你的代码,然后你根据他人的CR尽快修复,合入到主分支,再从主分支拉出新的分支进行新的开发
6.2 代码设计
代码设计这个东西比较玄乎,大家可以去看看Cheaterlin的一些文章。
我这边主要重点说下面这几个点。

- 别打那么多日志。我们有的服务一天一个异常都没有,但是1天就有80G的debug日志打出来,造成了资源的极大浪费 2.打关键信息,日志打了几千行,关键的一些信息都没有,打了个寂寞 3.别用魔法数字,别用魔法字符串,用了不留注释,代码直接腐化
- 代码洁癖,发现看着不爽的地方就列举出来,尽快处理
- 主动修复,在CR之外发现问题,顺手修复掉。并且留下注释,交流心得。整个团队氛围才会好起来
6.3 代码CR实战
我们部门在CR的时候都是在CR一下什么东西,实战演习一下。
我们看下面这个代码,从12行到32行,短短20行里面可以CR出多少东西出来

CR举例:

修改后的代码:

6.4 代码规范
最后就是我们现在遵循的代码规范

7 Q&A
Q:就这大仓推进过程中,你们也不是一帆风顺的。肯定有遇到过很多坎坷,有没有记录下来,遇到过哪些问题是怎么解决的。然后我们也可以借鉴一下。
A:很遗憾我们当时在做这些事情的时候,没有做一些纸上的一些记录。但是基本上所有的一些问题在解决之后,都会保留进那个大仓的提交信息里面去
Q:那你印象比较大的一些问题有吗?
A: 其实就是工程师代码素养的问题。这是我认为最大的一个挑战。不是说每个人都会按照你的规范来,他们可能自己修改代码之后由于粗心或者其他一些原因,会导致其他人编译不过,其次不能做到立即发布到线上的代码,被夹带发布的情况,这些其实都是在大仓实践遇到的一些问题。然后偶尔会有这种事情发生,但是目前来说还没有造成过线上事故。
Q:但是我是很担心出现比较大的事故,比如你刚开始应该也是没有很多单测,没有自动化的用例吧?那个时候怎么保证代码质量呢?
A:对。就是在做大仓之前,我们单测是比较缺失的,每个人自己玩自己的,当进入大仓之后,这些管控非常严格,也在要求大家将单测慢慢补齐,我们花了大半年时间,所有的服务的单测从20%补充到80%,分支覆盖率从10%补充到60%,确实投入了很多人力心力去做这个事情
Q:刚才那个你讲的那个CR实践。比较表面的问题。那这种有没有利用一些工具或者什么的方法去保障?
A:是这样,就是我们的工具肯定是有的。而且有三套检测,但是工具不是万能的,涉及到一些代码设计上的问题就得需要我们自己去看了。工具能解决掉90%的问题,但是还会有10%的问题需要你去看,而这10%,往往是最重要的。
Q:我们旧代码进大仓有什么好的经验吗?难道都要全部重构掉吗?还是说旧的先放过掉,然后只是针对新增的代码做CR?
A:这个其实我们前段时间是在正在做的一个事情。我们从其他的同学那边接手了一批代码,这部分代码我们最近是在迁移到大仓过程中,我们安排实习生,应届生,或者刚入职的同学进行迁移。利用把代码规范化的一个过程让新手自己去熟悉代码,全部修复后再合入到大仓,而不是先合进去后面再修复。
如果是先合入后治理,极有可能就是一两年之后了。所以我们在准入这方面是非常严格的。
Q:CR这个问题。我再问一下,比如说我们开发一个可能比较大的一个功能,这个大的功能可能会写很多代码。你们规定是每次CR代码不能超过200行,但是即便就就200行,我整个框架都写不完。就像这种情况怎么办?
A:那这种情况就说明你们的拆分还不够细。当你拆分到一个原子化的时候,所有东西都是能够在一个函数内去解决的。我们腾讯员工一个开发一天的代码平均提交量是多少?是167行。所以200行刚好是一个同学一天的工作量。超过200行再提交,CR的人是很难关注你的代码逻辑的。
每个工作都是可以细拆的,你不要想着是一个很大的需求我一股脑的写完了,提交上去,会很有成就感,这种长时间编码会让人慢慢变得疲倦,反而容易出现质量问题。