
作者 | 蔡芳芳
过去几年,数据仓库和数据湖方案在快速演进和弥补自身缺陷的同时,二者之间的边界也逐渐淡化。云原生的新一代数据架构不再遵循数据湖或数据仓库的单一经典架构,而是在一定程度上结合二者的优势重新构建。在云厂商和开源技术方案的共同推动之下,2021 年我们将会看到更多“湖仓一体”的实际落地案例。InfoQ 希望通过选题的方式对数据湖和数仓融合架构在不同企业的落地情况、实践过程、改进优化方案等内容进行呈现。本文,InfoQ 采访了 OPPO 云数架构部部长鲍永成,请他与我们分享 OPPO 引入数据湖和数仓融合架构的探索工作和实践中的一些思考。
1当我们谈数据湖,谈的是什么?
InfoQ:数据湖和数仓融合架构是当下大数据领域非常重要的议题之一,不仅各大云厂商先后提出了自己的技术方案,开源社区也有一些项目(包括 DeltaLake、Iceberg 和 Hudi)非常活跃。其实数据湖这个概念诞生至今有挺长时间了,在您看来,目前业内对数据湖的定义和重要性是否已经达成一致?云厂商的产品和开源项目之间有什么差异吗?
鲍永成:回答这个问题之前,我们得明确仓与湖的主要区别。仓里的数据,有明确的表、字段定义,表与表之间的关系清晰。湖里的数据,样式就多了,有结构化、半结构化(JSON、XML 等)、非结构化(图片、视频、音乐)。数据入仓,我们要预先定义好 schema。数据入湖,则没有这样的要求,只需要将原始数据写入指定存储即可(通常是对象存储),当真正需要使用的时候,我们再设法定义 schema,进行分析应用。显然,数据入湖比入仓要方便快捷。
回到我们的话题,云厂商的数据湖产品,通常积极推广他们的低成本云存储(S3、OSS 等),吸引用户将数据上云。一旦数据上云,进而吸引用户使用他们多年完善的大数据体系产品(计算引擎、依赖调度、质量管理、血缘管理、数据治理等),为用户提供数据开发、分析、应用的附加服务。其次,很多企业出于数据安全的考虑,并不愿意将自己的数据上云,一套兼容各类存储的仓湖融合方案,是云厂商对市场的迎合。
开源的几个数据产品 Delta Lake、Apache Iceberg、Apache Hudi 更多可以理解为一种 TableFormat,这种 TableFormat 可以灵活定制 Schema,对对象存储友好,同时可以实时处理数据,支持 Update、Insert、Upsert 特性。企业应用好他们,可以助力自身构建批流一体、仓湖融合的大数据架构。
2仓湖融合架构升级的三个阶段
InfoQ:OPPO 是什么时候决定要引入数据湖和数仓融合架构的?能否介绍下当时的整个背景情况?是希望解决什么样的问题或痛点?
鲍永成:OPPO 在 2020 年初引入数据湖的架构方案,这是建立在 OPPO 进军 IoT 领域的大背景下。随着公司不断推出 IoT 产品,IoT 设备产生的数据源源不断,设备的智能化服务需要我们对这些数据做更深层次的挖掘。海量的数据如何高效存储、高效利用是大数据部门必须要解决的问题。数据湖方案可以帮助我们快速收集保存数据,有效支持我们做数据分析、市场预测,以及智能服务的算法训练。
InfoQ:为什么选择引入 Apache Iceberg?你们前期做了哪些技术选型和评估工作?
鲍永成:引入 Iceberg 构建我们的数据湖方案,主要出于两点考虑。
- 一. 云数融合:OPPO 已经基于 K8S, 构建了自己的云平台,主要数据存在对象存储 OCS 上。大数据依靠 Yarn 调度,HDFS 做存储,目前云与大数据正在逐步完成融合,做到调度融合,存储融合,统一运维,进而降低成本。
- 二是在与 Delta Lake、Hudi,Iceberg 对比中,虽然 Hudi 的实时特性最完备,但与 Spark 耦合太紧,Schema 的定义缺乏灵活性。Iceberg 对 Upsert、Insert、Delete 的支持没有 Hudi 完备,但社区在积极跟进。摆脱了具体计算引擎的束缚,Iceberg 专注于数据湖 TableFormat 标准的制定,这个标准正在慢慢被各家计算引擎所接受,未来会赢得更多的用户认可。
InfoQ:能否详细介绍一下 OPPO 整体的数据平台架构或数据处理流水线?在引入 Iceberg 前后,有哪些变化和演进?
鲍永成:下图是 OPPO 的大数据架构,我们目前主要在推进两项工作。
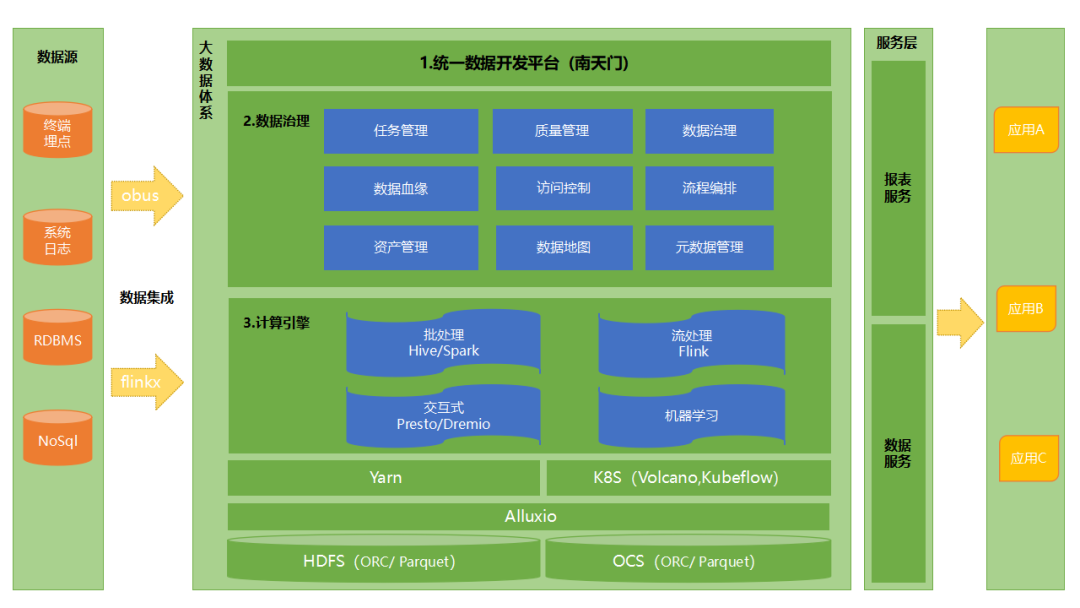
1. 云数融合:OPPO 已经基于 K8s 构建了自己的云平台,主要数据存在对象存储 OCS 上。大数据平台依靠 Yarn 调度,HDFS 做存储,后续二者将统一调度与存储,统一运维,降低成本。云数融合的一期重点,会通过我们自研的 ADLS 支持数据湖存储。ADLS 的冷热分层,全局缓存特性在数据湖落地的过程中,可以有效降低存储成本,减轻存算分离后的性能影响。
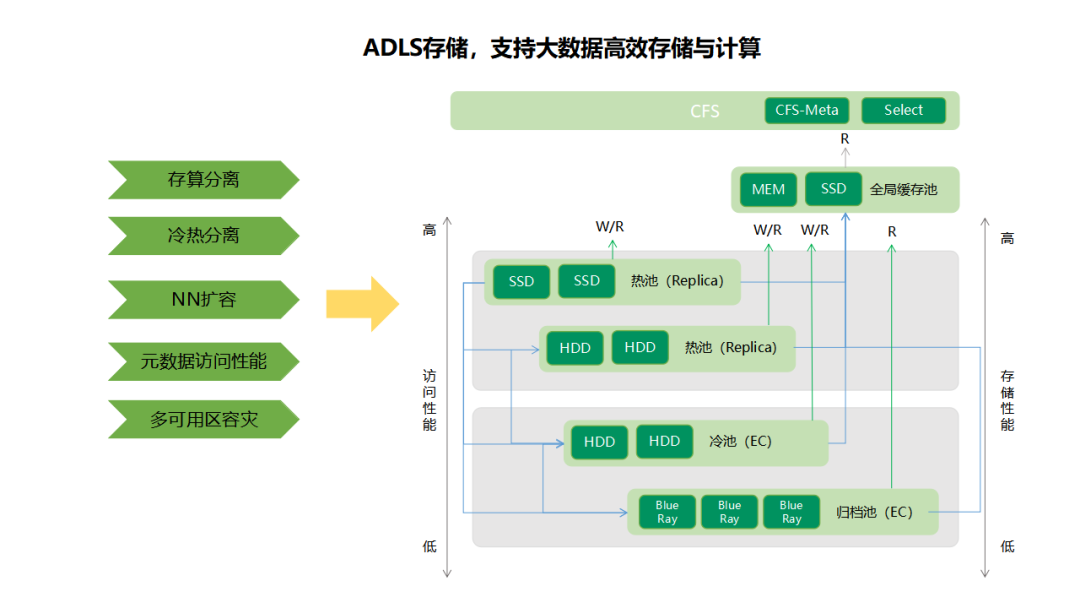
2. 流批一体、仓湖融合的架构升级
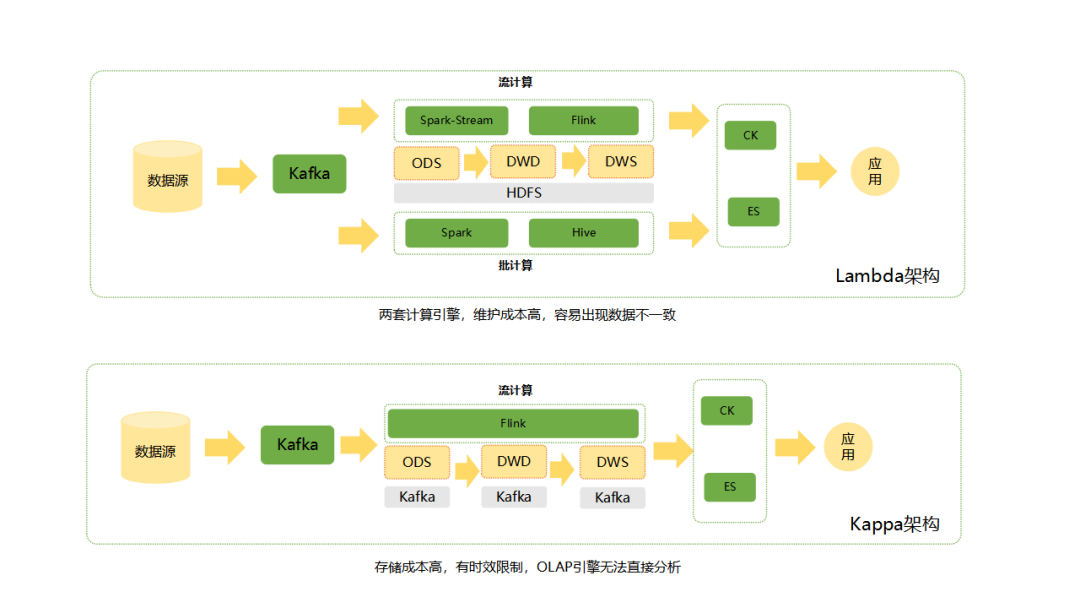
对于传统的 Lambda 架构,流与批是单独的两条数据处理链路,维护成本高,且容易出现数据不一致的情况。新的 Kappa 架构使用 Kafka 作为存储,简化了架构,但 Kafka 数据承载能力有限,且数据格式并不利于计算引擎分析。
我们在以下两个方面,对传统架构进行了改造。
1)针对公司原来的数据埋点链路,我们引入了 Iceberg,将实时数仓库的 Kafka 替换成 IcebergFormat,通过 Spark/Presto 引擎做数据查询,增加数据仓库的实时性。
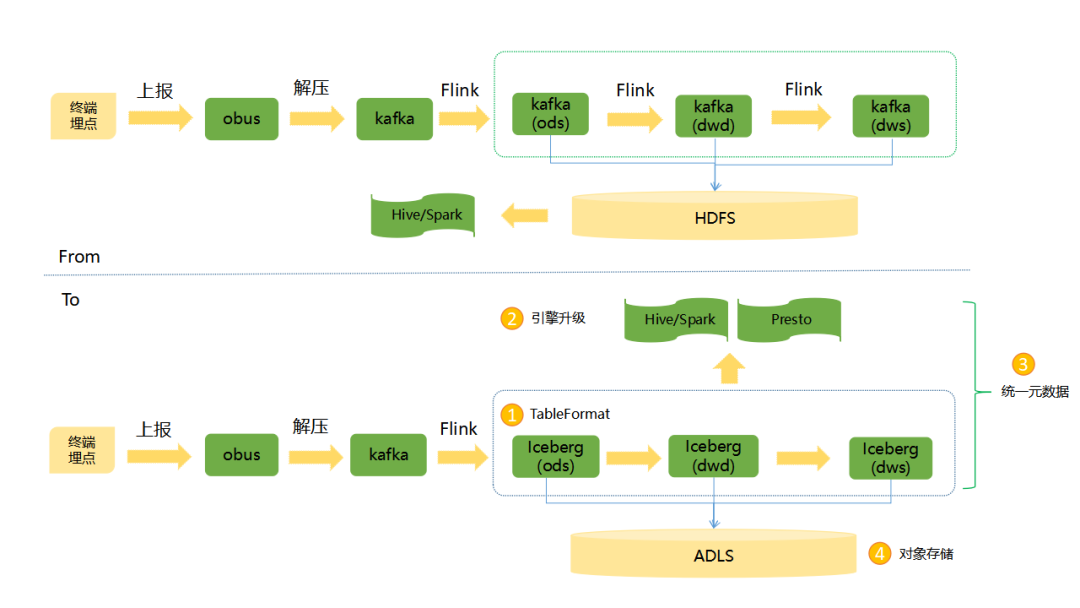
2)公司原有的数据库入仓链路通过 Flinkx 完成数据同步, 无法支持 CDC。目前 Flink 已经原生支持 CDC 数据解析,binlog 通过 flink-cdc-connector 拉取可以自动转化成 INSERT、DELETE、UPDATE_BEFORE、UPDATE_AFTER 消息,结合 Iceberg 支持的 Update、Delete 特性,可以高效准确地将数据库同步到数仓,方便计算引擎进行分析。

OPPO 的一些数据,存储在 Oracle,SqlServer 等数据库中,Flink 对这些数据库的数据的拉取并没有提供支持。我们封装了 Obus-DB 的组件,来适配各类数据库,将数据同步到 Kafka 中,支持后续数据入湖的消费。
InfoQ:你们是如何将基于 Apache Iceberg 的数据湖方案,与 OPPO 已有的数据仓库融合的(分哪些阶段、关键工作等)?改造过程中存在哪些难点和挑战?你们是如何解决的?
鲍永成:仓湖融合可以分为 3 个阶段,目标是做到 3 个统一:统一数据、统一元数据、统一计算引擎。
1)统一数据
大数据 Lambda 架构分实时离线两条链路,两条链路可能造成数据不一致。Kappa 架构虽然统一了链路,但 kafka 的特征注定了这套架构对历史分析并不友好。引入 Iceberg 换掉 kafka,可以认为是 Kappa 架构的升级,简称 Kappa+,可以做到在一条链路上完成数据入仓,支撑流批数据分析。Iceberg Commit Snapshot 架构实时性不及 Kafka。目前我们采用 Iceberg 备份 Kafka 数据,同时缩短 Kafka 数据的存储时间,以满足用户的实时性需求,并为后续的 Iceberg 优化预留空间。
2)统一元数据
目前大数据的元数据基本都存储在 HiveMetaStore 中,Iceberg 构建表,需要融合其中。Flink 1.9 版本以前,是自己管理元数据,基于此,OPPO 的元数据也分离线和实时两套;Flink 1.11 版本后,对 HiveMetaStore 的集成已经比较成熟,我们正在将实时链路的元数据逐部迁移到 HiveMetaStore。
3)统一引擎
Iceberg 目前可以支撑 Flink、Spark、Presto 的查询,这虽然给了用户更多的选择,但同时也给用户带来了选择困难。在引擎层,可以做到一套引擎出口,根据数据特征通过 HBO 灵活选择执行引擎。这项工作目前正在规划中。
目前数据埋点入仓与数据库 CDC 入仓两条链路已经完成了数据湖架构改造,但 OPPO 每天入仓的数据量巨大,Iceberg 性能还需要优化。
3没有完备的数据体系,空谈湖仓之争没意义
InfoQ:您认为现阶段 Iceberg 还存在哪些不足待改进?你们有没有什么踩坑经验可以分享?
鲍永成:Iceberg 目前虽然有基于文件的统计信息,方便做谓词下推的数据过滤,但还缺少细致的索引规范来加速文件检索。同时 Row-level delete 的性能也不够高效,还有优化空间。
InfoQ:接下来对于数据湖引擎和调度平台的建设,以及湖仓融合架构改造,你们还有哪些规划?
鲍永成:谈论数据湖和数据仓库,立足点应该建立提供更好的数据服务上。完备的数据体系,包括数据存储、多模态计算引擎、依赖调度、质量管理、血缘管理、任务诊断、数据集成、统一元数据、数据安全、数据服务等多方面内容,只有这些方面的能力完备,才能提供优质的数据服务,这是 OPPO 数据中心的核心工作。无论是数据湖,还是数据仓库的数据,只有运转在这套体系下,才能得到高效利用。在上述能力具备的条件下,解决好湖数据快速构建 schema、湖与仓的元数据统一问题,仓湖自然融合。上述能力不完备,空谈湖与仓之争,没有太多意义,孤岛问题不可避免,数据利用率低,使用成本高。
InfoQ:您怎么看数据湖和数仓融合架构未来的发展趋势?企业或业务团队该从哪些方面去评估自己是否需要引入湖仓融合架构?
鲍永成:仓湖融合的架构是个必然趋势。数据时代,人们产生和接触的数据越来越多样,数据服务的要求也越来越高。快速而又低成本的利用数据,数据湖有着较为明显的优势。如果企业与团队面临这样的挑战,可以引入仓湖融合的架构。但要做到仓湖融合,可以结合自身的情况,参考上一个问题的回答。
采访嘉宾介绍
鲍永成,OPPO 云数架构 & 个人云负责人。曾服务于土豆网、思科、京东、头条等公司。长期负责云计算平台、大数据平台的研发与技术演进。带领团队先后在京东商城、OPPO 实施完成了全量业务上云战略。目前致力于打造 OPPO 开放的云与大数据能力,在跨场景、多终端的超大空间为用户提供智慧服务。
点击文末【阅读原文】移步InfoQ官网,内容更多更精彩!
本周好文推荐
谷歌“宠爱”升级,Rust 大步跨入 Android 平台
Mesos已死,容器永生
90亿美元Java纠纷案反转:安卓中复制的代码属于合理使用
Java 微服务能像 Go 一样快吗?
点个在看少个 bug 👇