
目录
大数据概论
大数据概念
为什么会有大数据
大数据的4v特征
大数据的来源
云计算与大数据
大数据发展历史
大数据技术原理
大数据的存储技术
大数据的计算技术
数据分析技术
Hadoop生态圈
大数据概论
大数据概念
大数据(Big Data),指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据就像矿石,需要汇聚,清洗 ,分析 ,挖掘等处理才能发挥蕴含的价值

为什么会有大数据
1、移动互联网带来的爆炸式的数据增长
2、数据作为一种资产越来越重要
3、存储技术和计算能力的飞速发展

大数据的4v特征
1) Volume 体量巨大
2)Variety 种类繁多
3)Value 价值密度低
4)Velocity 处理速度

大数据的来源

云计算与大数据
云计算提供计算的基础与设施,大数据则是运行在其上的应用
云计算想相当于电力系统,大数据则为电器设备

大数据发展历史
google分别在2003年、2004年以及2006年发布了大数据发展影响重大的三篇论文: 1、The Google File System,简称GFS; 2、MapReduce; 3、Bigtable。 分别论述文件系统、非关系型数据库、并行计算框架

大数据技术原理
将问题简化成一个更简单的能处理的问题 将问题拆分成多个可以简单求解的小问题
大数据的存储技术
先分块,在分散处理再各个结点上去。
存取时,,先从maser结点找到地址,在去slave结点去寻找。

数据文件先分块,在分布式存储到各个文件
典型的Hadoop 的HDFS存储框架采用文件拆分存储在多个结点,每个拆分出的文件存储3个副本的形式存储
大数据的计算技术
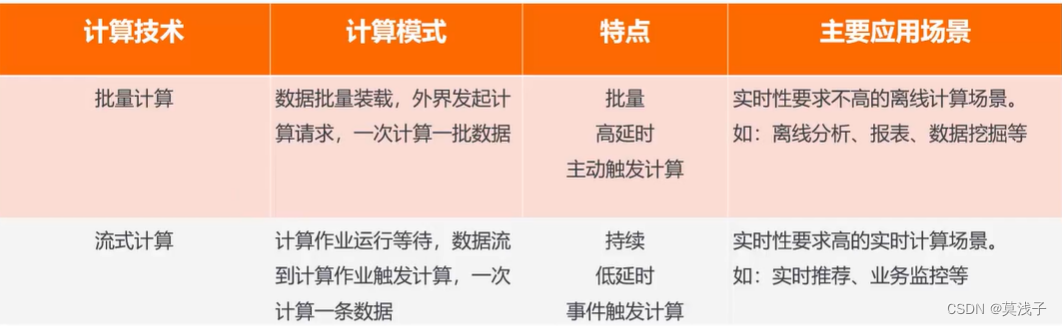
数据计算类型的分类
1)离线批处理
2)实时交互计算(流计算)
3)在线计算
数据分析技术
数据分析技术是基于商业目的,有目的的进行收集,整理,加工和分析数据,提炼有价值信息的过程
Hadoop生态圈
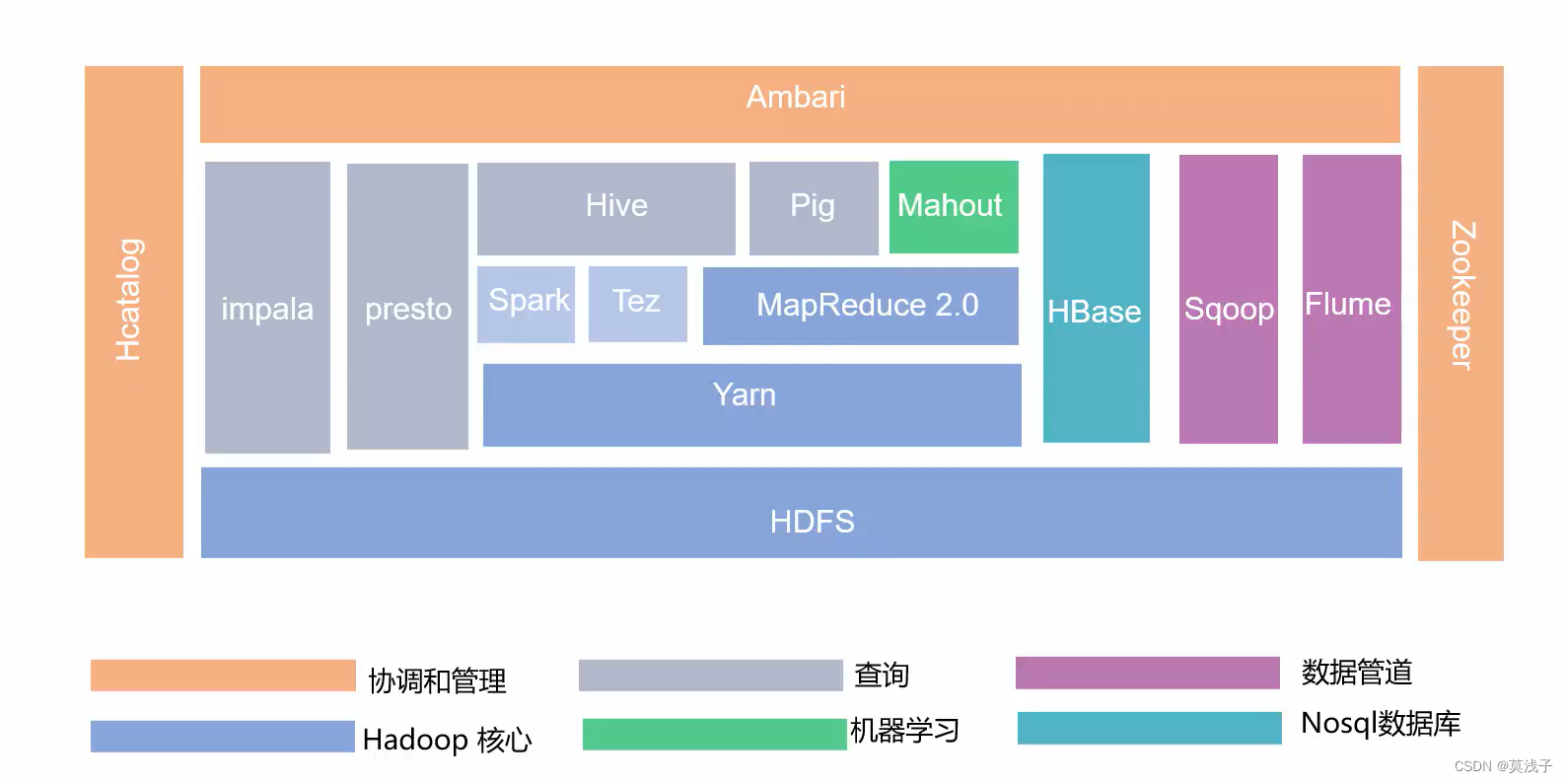
Hadoop的分布式存储技术是HDFS;分布式存储不要求底层服务器高性能,多台服务器同时提供服务;冗余存储,副本技术,保障数据安全;分布式存储Hive即为结构化存储
1、HDFS(分布式文件系统) 2、MapReduce (分布式计算框架) 3、Spark(分布式计算框架) 4、Flink(分布式计算框架) 5、Yarn/Mesos (分布式资源管理器) 6、Zookeeper (分布式协作服务) 7、Sqoop (数据同步工具) 8、Hive/lmpala(基于Hadoop的数据仓库) 9、HBase (分布式列存储数据库)10、Flume (日志收集工具) 11、Kafka(分布式消息队列) 12、Oozie (工作流调度器)
采用分步式的方式存储数据时,要考虑数据复制时一致性问题,数据复制与一致性基本原则和设计理念CAP 、ACID 、BASE 等