背景介绍
2022年下半年开始,从chatgpt的火爆出圈到今天各种好玩的模型、工具应用层出不穷,迭代更新速度更是日新月异,让普通用户也直观的感受到了AI技术的强大。
如果一个普通用户也想玩stable diffusion(SD), 想轻轻松松写些提示词就能出想要的美图,但是GPU机器昂贵的价格、复杂的网络配置、软件安装以及依赖管理和版本兼容性问题都是劝退师。。。好不容易燃起的进步的小火苗也被扑灭了。
无意中发现的腾讯的这个HAI真是天助我也,内置了stable diffusion模型和webui, 只需简单几步即可快速体验最火爆的AIGC能力,快来体验吧。
HAI
内测申请
腾讯云新上的这个HAI产品还在内测阶段,需要进行资格申请,填写申请后,大概1天会通过,通过后会给10元的代金券,就可以愉快的玩耍了。
申请地址: https://cloud.tencent.com/act/pro/hai
当然,申请通过后,也可以加入微信群,里面有官方这个产品的大佬,事无巨细,有问必答,服务周到👍🏻。
一键部署SD
- 进入算力管理页面:https://console.cloud.tencent.com/hai/instance?rid=1
- 点击新建
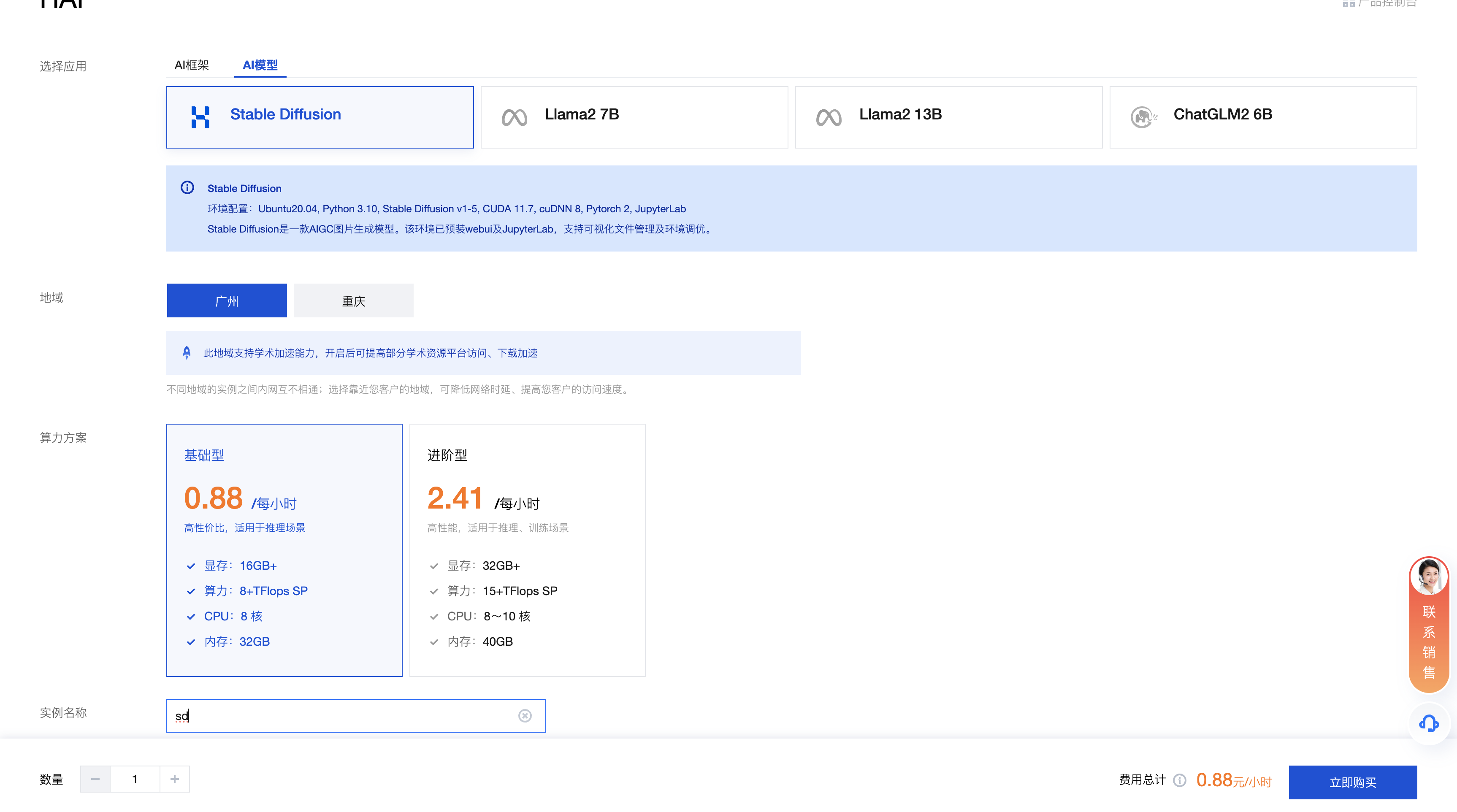
- 点击购买后,耐心等待8分钟左右,创建好服务器后会收到腾讯云通知短信。
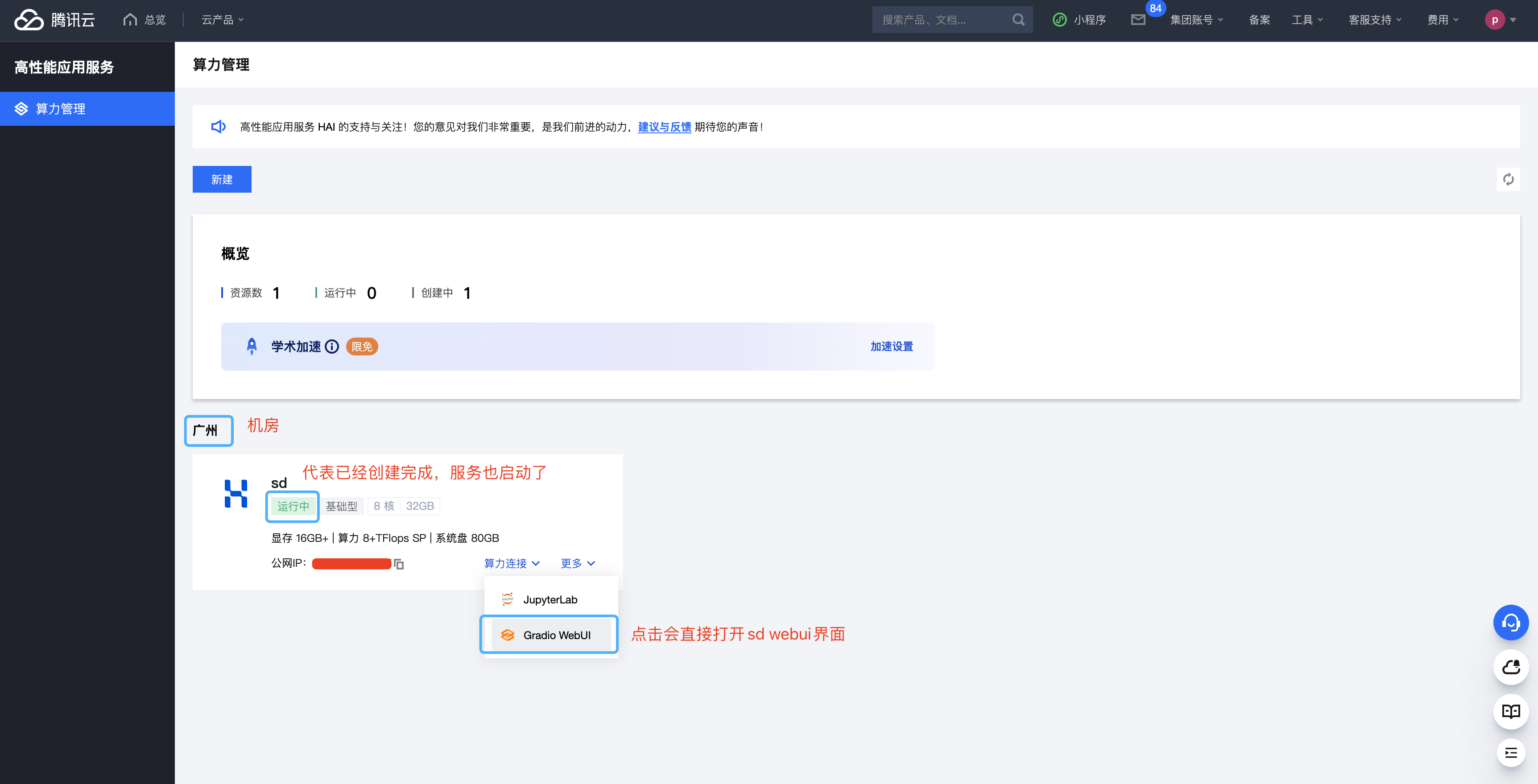
从创建好服务器后,就开始计费了,目前还没有上线停止服务器的功能,貌似开发中,这个功能耐心等等吧。如果有事离开不用服务器,可以先销毁。下次使用时再创建就行。- 算力连接,有两个选择。
- JupyterLab 可以进入ubuntu 终端操作界面,进行文件的上传、下载,手动启动、停止相关服务等。查看错误日志、排查问题等。
- Gradio WebUI 一键打开SD的webui界面,可以画图咯。啦啦啦。
SD WebUI 初体验
如何使用stable diffusion webui.
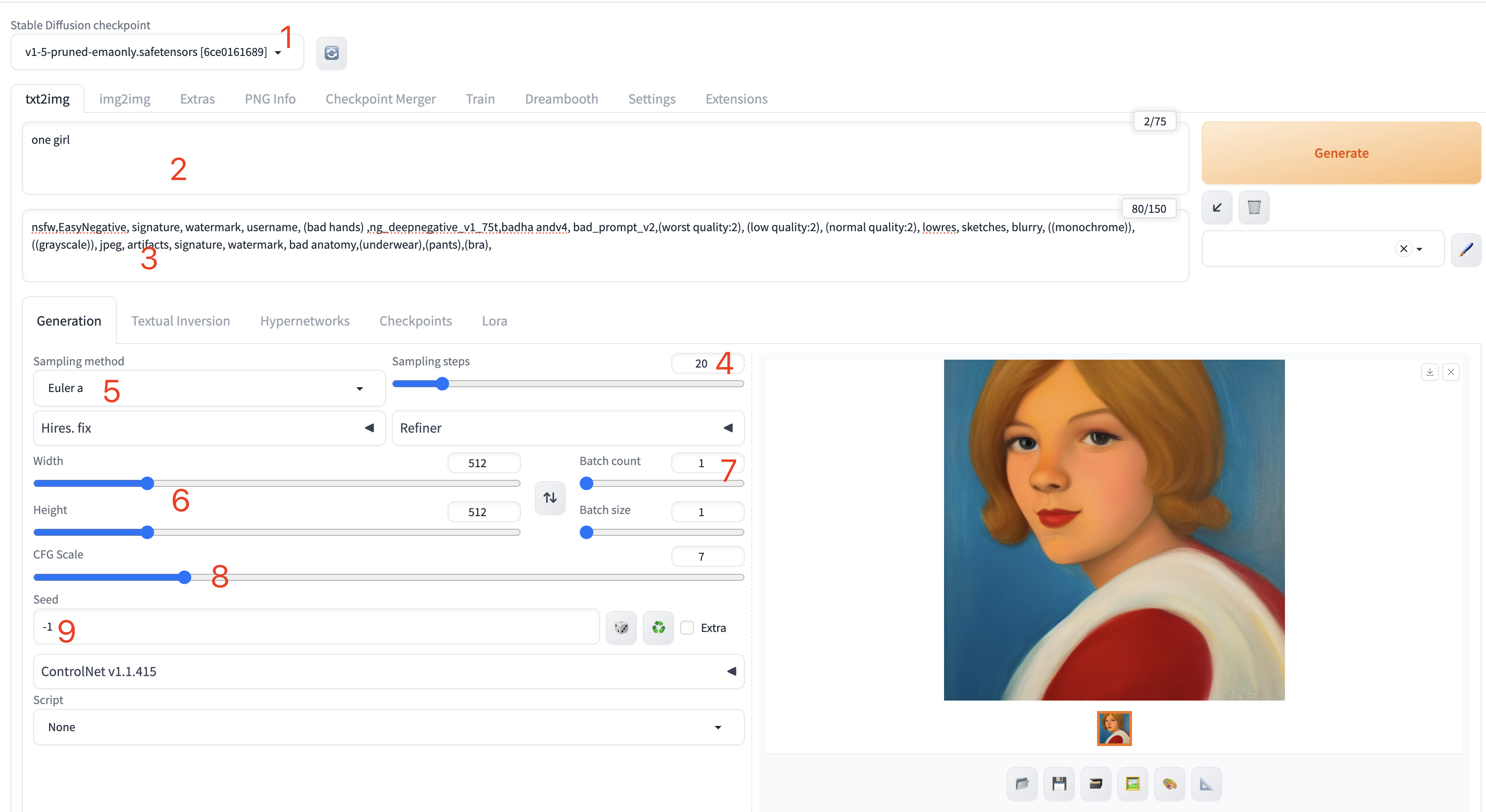
- 1 - sd 大模型选择,默认安装的只有v1-5-pruned,后面自己下的大模型,会在这里展示的
- 2 - 提示词,用于描述图片中希望出现的内容,也就是咒语本咒😄
- 3 - 反向提示词,用于描述图片中不希望出现的内容,应该算反向咒语吧。
- 4 - 采样迭代步数,希望出图时,采样器计算多少步数来出图,并发步数越多越好,大部分情况下20-30就够了的
- 5 - 采样方法,影响生成随机图像、去除图像噪声的效果,一般选择Euler a即可。
- 6 - 出图尺寸,width, height, 默认即可。尺寸越大出图越慢,小尺寸的图,后面也可以用魔法变大变高清。
- 7 - 出图数量,数量越大,需要的显存就越大。
- 8 - 提示词相关性,控制提示词与出图相关性的一个数值,一般为5~15;
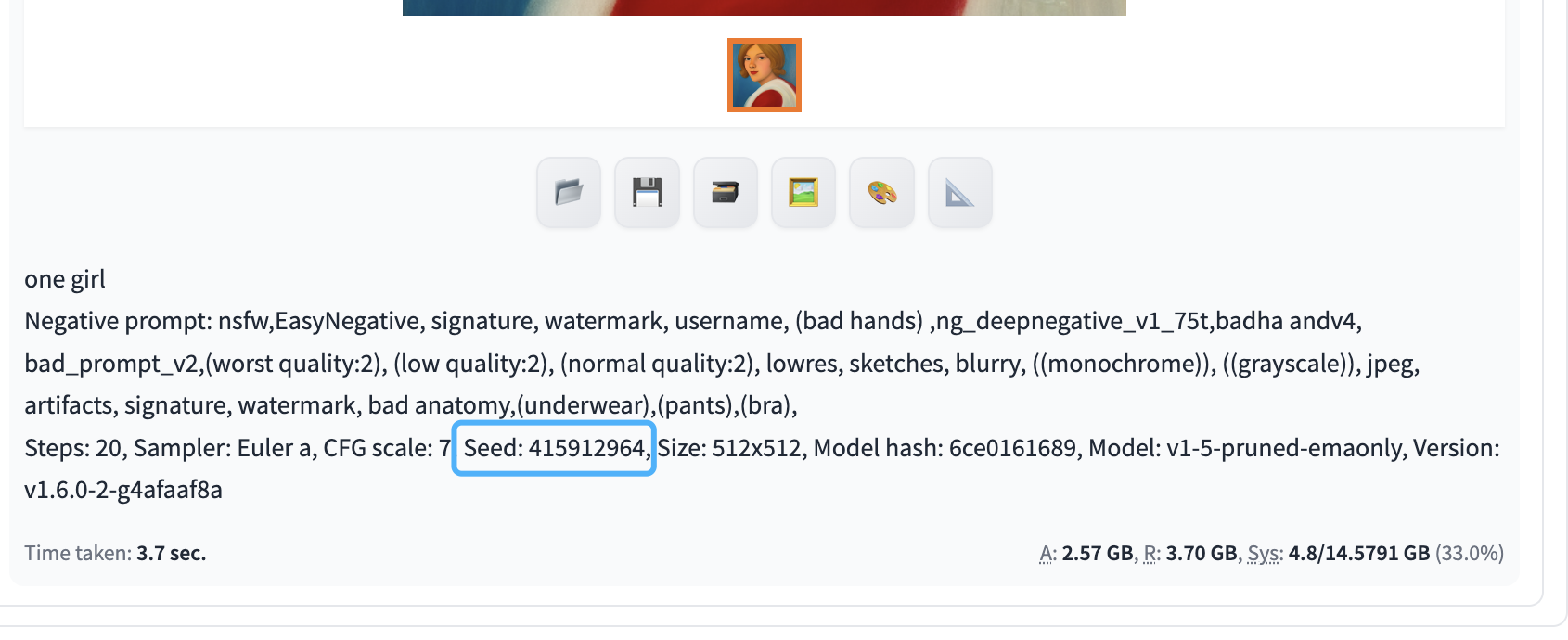
- 9 - seed, 随机种子,-1 表示每次种子都是随机的,如果想记住,可以将seed值填写为固定值。
摩拳擦掌,热身准备
安装插件
中文化插件

url 以及github 地址:https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN github repo中也有详细的安装方法 安装后如果webui访问不了,就进入jupyter的终端界面,执行如下命令,手动启动下。原因:有时候安装完成插件后 没有等系统重启完成就操作 可能会有一定的错误 导致服务没起来
cd /root/stable-diffusion-webui
python webui.py --enable-insecure-extension-access --listen --port 6889c站模型下载插件
- url以及github: https://github.com/tzwm/sd-webui-model-downloader-cn/
- 同样使用install from url的方式进行安装, 安装后重启web ui
- 会看到sd webui导航栏里多了个模型下载

如何正确的输入提示词Prompt
输入Prompt提示词,点击右侧"生成"按钮,可以看到进度条在生成一张图片。
我们通过修改Prompt, 给图片增加一些细节:
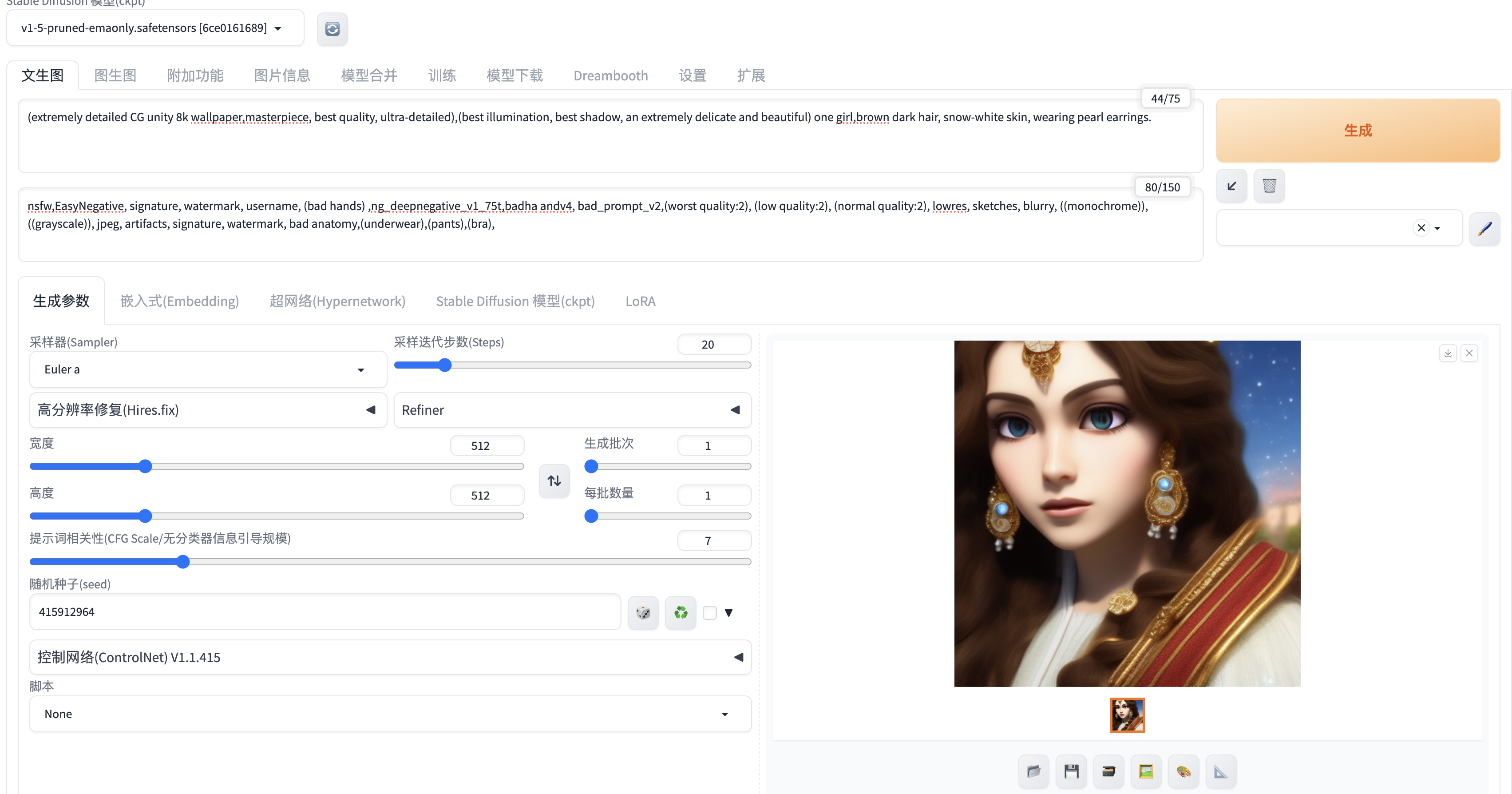
Prompt: (extremely detailed CG unity 8k wallpaper,masterpiece, best quality, ultra-detailed),(best illumination, best shadow, an extremely delicate and beautiful) one girl,,brown dark hair, snow-white skin, wearing pearl earrings.
极其详细的CG Unity 8K壁纸,杰作,最佳质量,超级细致),(最佳照明,最佳阴影,极其精致和美丽)一个女孩,棕黑色的头发,雪白的皮肤,戴着珍珠耳环。
图片的细节丰富了,质量也提升了。关于Prompt的2个点可以注意下:
- 质量提示词:提示词中的重要组成部分,描述图片的生成质量和细节丰富程度,比不可少
- 提示词权重:可以用(),[]调整权重,()增加1.1倍权重,[]减弱为0.91,多次嵌套效果相乘。
切换模型,体验差异化风格
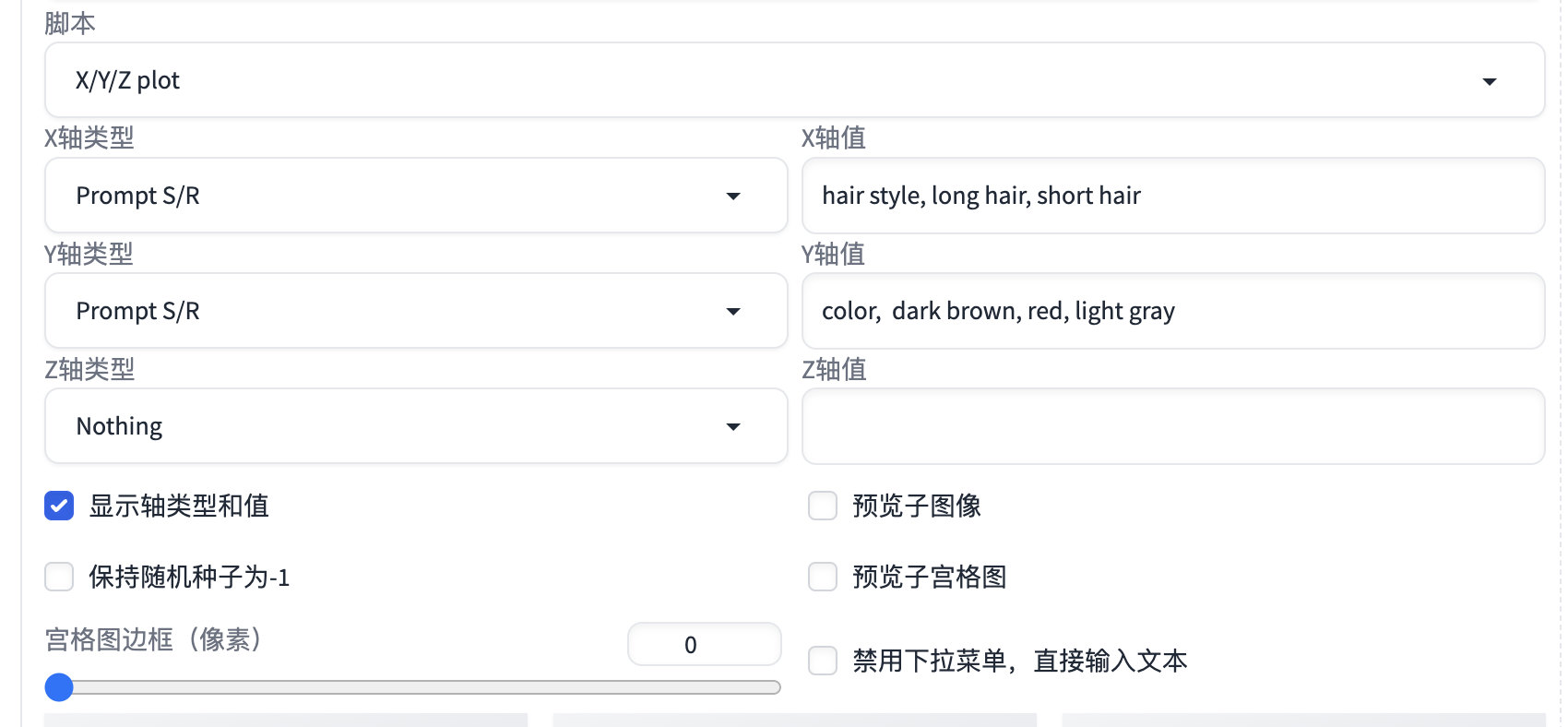
快速对比不同参数的效果-xyz plot插件
sd webui是非常优秀的开源项目,拥有丰富的扩展插件和脚本。其中较为常用的脚本为"xyz图表",通过配置不同的参数可以得到不同的效果输出,比如想改变发型和头发的颜色。
one girl,hair style,color, snow-white skin, wearing pearl earrings.

下载大模型
下载模型前,需要先安装curl
apt-get update
apt-get install curl安装完成curl后,就可以去c站找模型下载了。
从c站找了一个人像写实风格的checkpoint大模型,复制下载地址:
https://civitai.com/models/43331?modelVersionId=176425
现在webui上没有展示下载进度,其实点击下载后,在后台是默默的在下载了,可以在jupyter终端中查看:

大模型下载成功后,点击顶部的Stable Diffusion 模型(ckpt) 旁边的刷新按钮,并选则最新下载的checkpoint模型,等加载成功后就可以使用了。
大模型-底模型,属于基础模型,也叫预调模型,size都比较大,不同的基础模型,其擅长的领域和画风也不同。
来看下对比效果


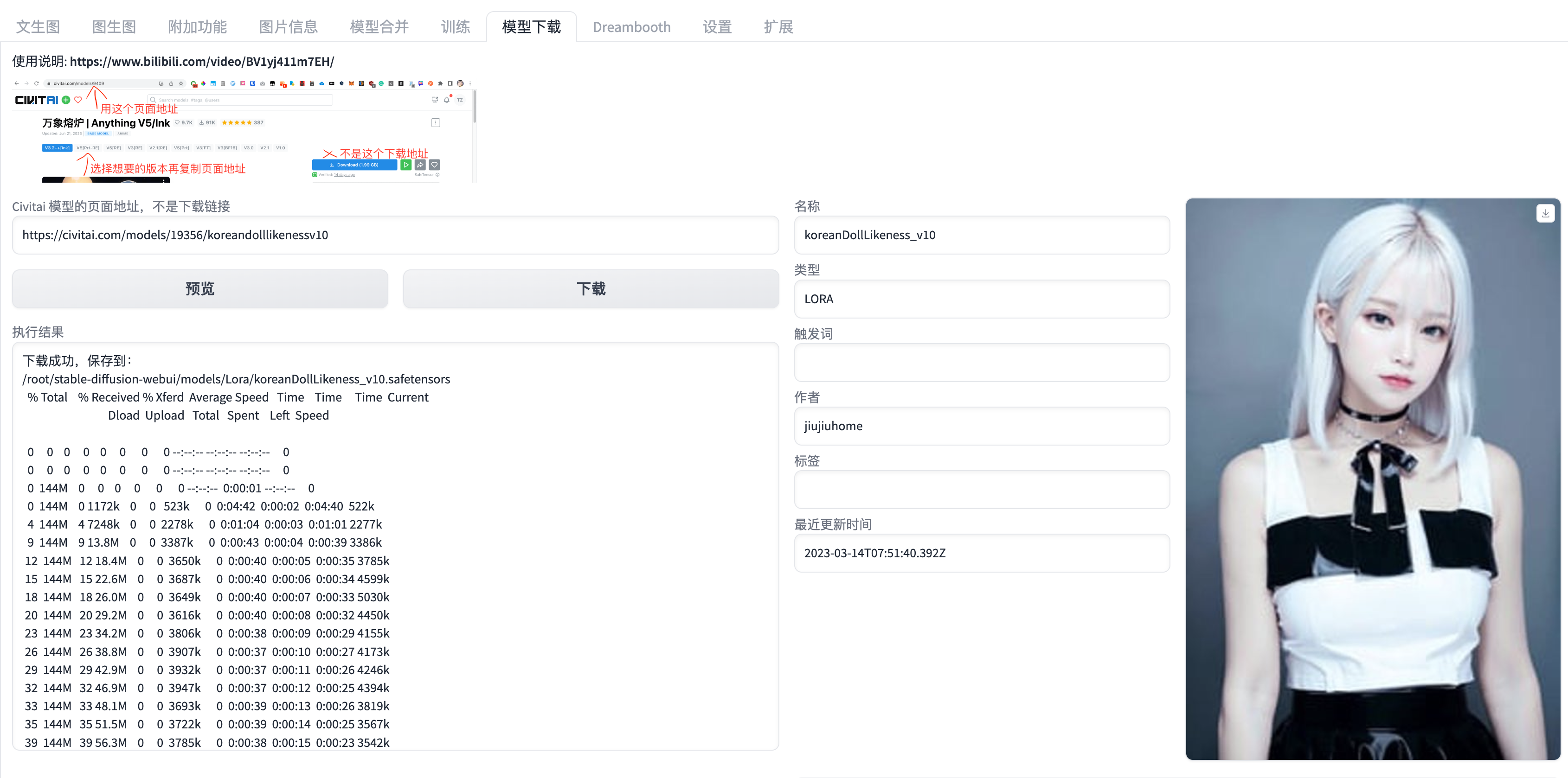
下载lora模型
大模型定了之后,就可以从c站找基于你选择的大模型训练的各种lora模型。lora模型一般比较小,也就几十M,主要是风格方面。
这样我们就可以通过下载各种各样的lora模型,在一个大模型的基础上,来修改它的一些局部。这就是现实意义中的大模型+lora模型的配合使用。
选择一个合适的lora模型文件,比如:
https://civitai.com/models/19356/koreandolllikenessv10下载成功后,可以在jupyter终端看到

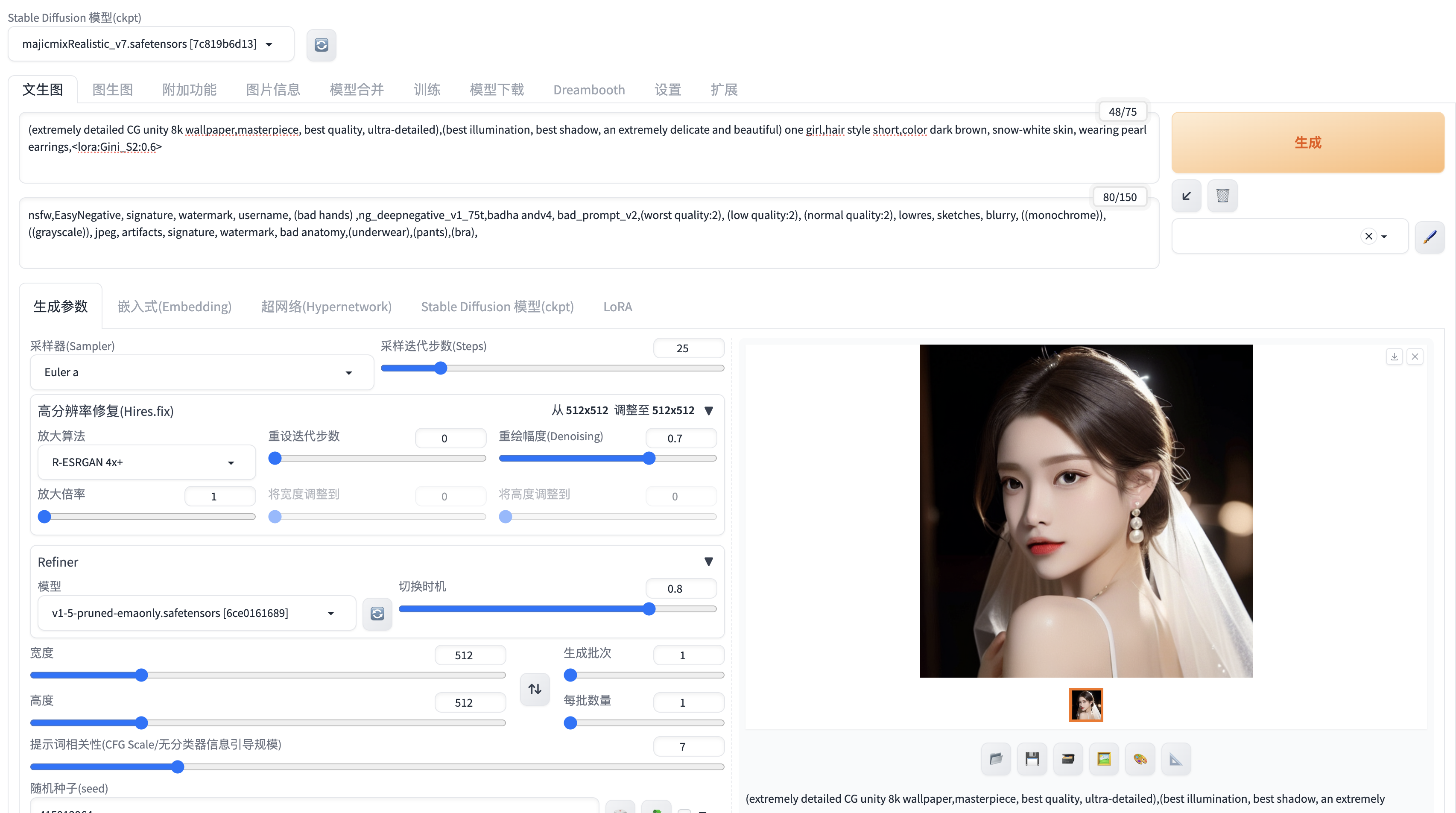
在webui界面中点击lora,可以在prompt中看到多了一个lora的标签,规则是:
<lora:xxx:1>, 1代表借用lora的权重到底有多大,范围是0-1,一般不宜过大,经验值是0.6

更多的探索和思考
如何获得高清图
可以使用webui 的附加功能
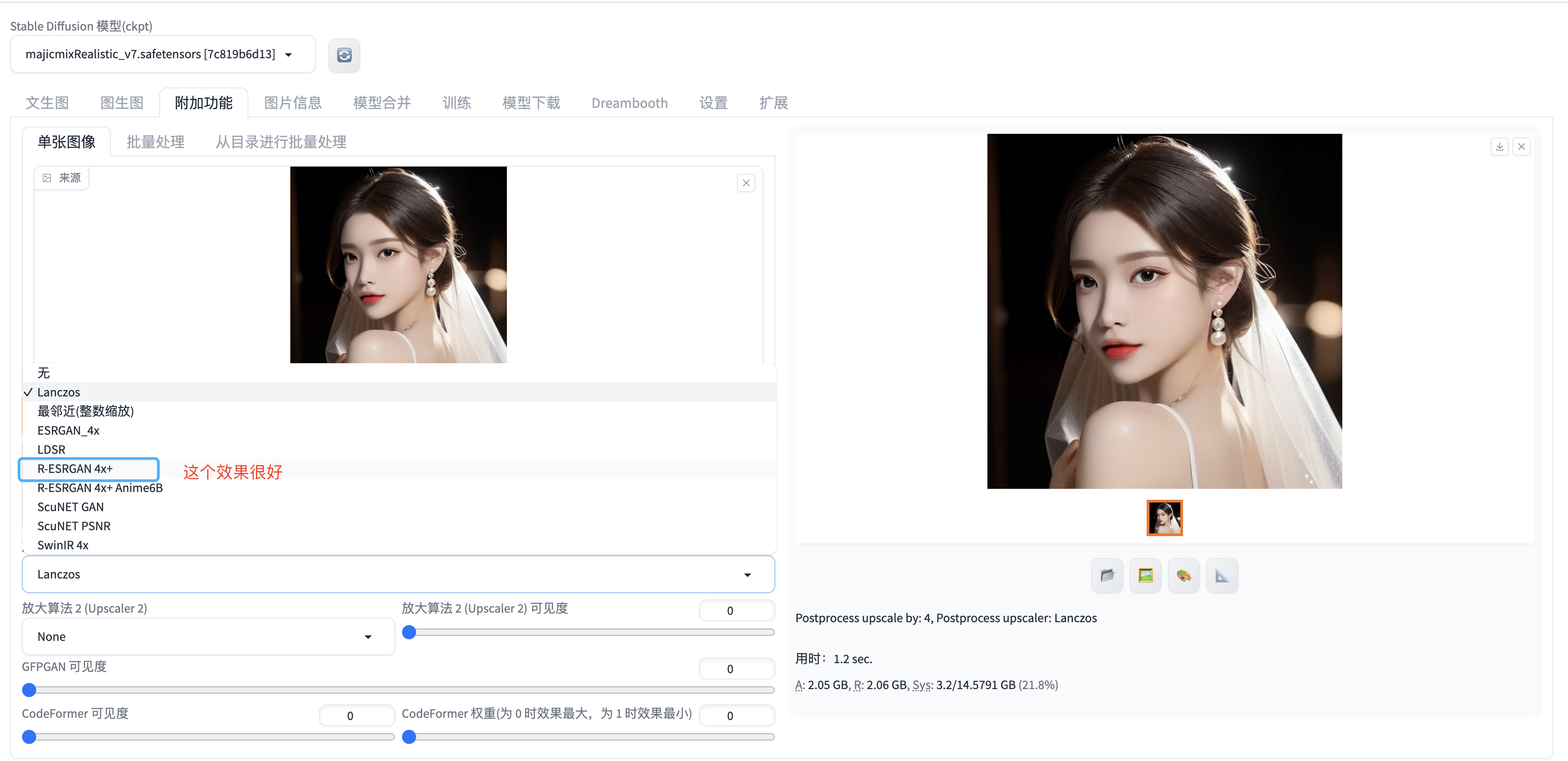
lanczos, 又叫兰索思,速度很快,效果一般。
R 4x+: https://github.com/xinntao/Real-ESRGAN/ 也是一个非常优秀的开源项目,就是有点大,不好下载,效果是真的好,很多老片修复用的它。
如何获得lora一模一样的图,哪里姿势不对呢?
点击c站lora中某个图片的进去,会看到生成这个样图的详细参数,样例:
(masterpiece, best quality, excellent quality), (fantasy landscape, fictional landscape)
Negative prompt: EasyNegative, fat, moss, phone, man, pedestrians, extras, border, outside border, white border, watermark, logo, signature
Steps: 24, Size: 768x512, Seed: 2351000243, Model: FantaStel_Pruned_FP16, Sampler: DPM++ 2M Karras, CFG scale: 9.5, Clip skip: 2, Model hash: 99a868d210, Hires upscale: 2, Hires upscaler: Latent (nearest), Denoising strength: 0.6我们需要一一对照这些详细参数设置到自己的sd webui中,才能得到预期的图片,然后就可以自由真正的发挥了。
参考
stable diffusion webui 官方: https://github.com/AUTOMATIC1111/stable-diffusion-webui